

Алгоритм Хаффмана
Слабое место метода упаковки заключается в том, что символы кодируются битовыми последовательностями одинаковой длины. Например, любой текст, состоящий только из двух букв «А» и «В», сжимается методом упаковки в восемь раз. Однако если к такому тексту добавить всего лишь одну букву, например «С», то степень сжатия сразу уменьшится вдвое, причем независимо от длины текста и количества добавленных символов «С»!
Улучшения степени сжатия можно достичь, кодируя часто встречающиеся символы короткими кодами, а редко встречающиеся — более длинными. Именно такова идея метода, опубликованного Д. Хаффманом (Huffman) в 1952 г.
Идея кодирования символов кодами переменной длины была высказана и теоретически проработана американскими учеными К. Шенноном и Р. М. Фано. Ими был предложен алгоритм построения эффективных сжимающих кодов переменной длины (алгоритм Шеннона—Фано), однако он в некоторых случаях строил неоптимальные коды. Алгоритм Хаффмана оказался простым, быстрым и оптимальным: среди алгоритмов, кодирующих каждый символ по отдельности и целым количеством бит, он обеспечивает наилучшее сжатие.
Алгоритм Хаффмана сжимает данные за два прохода: на первом проходе читаются все входные данные и подсчитываются частоты встречаемости всех символов. Затем по этим данным строится дерево кодирования Хаффмана, а по нему — коды символов. После этого, на втором проходе, входные данные читаются еще раз и при этом генерируется выходной массив данных.
Вычисление частот встречаемости — тривиальная задача. Разберем построение дерева кодирования Хаффмана.
Алгоритм построения дерева Хаффмана
Символы входного алфавита образуют список свободных узлов. Каждый узел имеет вес, равный количеству вхождений символа в исходное сообщение.
В списке выбираются два свободных узла с наименьшими весами
Создается их узел-«родитель» с весом, равным сумме их весов, он соединяется с «детьми» дугами.
Одной дуге, выходящей из «родителя», ставится в соответствие бит 1, другой — бит 0.
«Родитель» добавляется в список свободных узлов, а двое его «детей» удаляются из этого списка.
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева
Пример. Построение дерева Хаффмана и префиксных кодов для текста «KOJI_OKOJIO_KOJIOKOJIA»:
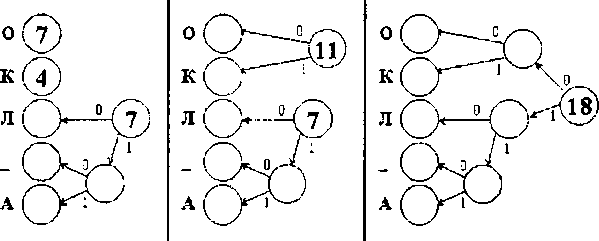
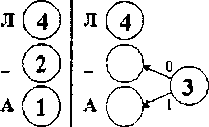
Пусть у нас имеется список частот встречаемости всех символов исходного текста. Выпишем их вертикально в ряд в виде вершин будущего графа. Выберем две вершины с наименьшими весами (они соответствуют символам с наименьшим количеством повторений). Объединим эти вершины — создадим новую вершину, от которой проведем ребра к выбранным вершинам с наименьшими весами, а вес новой вершины зададим равным сумме их весов. Расставим на ребрах графа числа 0 и 1, например на каждом верхнем ребре 0, а на каждом нижнем — 1. Чтобы выбранные вершины более не просматривались, мы сотрем их веса (это аналог удаления вершин из списка). Продолжим выполнять объединение вершин, каждый раз выбирая пару вершин с наименьшими весами, до тех пор пока не останется одна вершина. Очевидно, что вес этой вершины будет равен длине сжимаемого массива данных.
Теперь для определения кода каждой конкретной буквы необходимо просто пройти от вершины дерева до этой буквы, выписывая нули и единицы по маршруту следования. В нашем примере символы получат следующие коды:
«О» - 00, «К» - 01 «Л» - 10 «_» - 110 «А» - 111
После того как коды символов построены, остается сгенерировать сжатый массив данных, для чего надо снова прочесть входные данные и каждый символ заменить на соответствующий код. В нашем случае непосредственно код текста будет занимать 39 бит, или 5 байт. Коэффициент сжатия равен 18/5 = 3,6. Для восстановления сжатых данных необходимо снова воспользоваться деревом Хаффмана, так как код каждого символа представляет собой путь в дереве Хаффмана от вершины до конечного узда дерева, соответствующего данному символу. Общая схема процесса восстановления такова: специальный маркер устанавливается в вершину дерева Хаффмана, и сжатый массив данных читается побитово. Если читаемый бит равен О, то маркер перемещается из вершины по верхнему ребру, если 1, то по нижнему. Затем читается следующий бит, и маркер снова перемещается, и т. д., пока маркер не попадет в один из конечных узлов дерева. В восстанавливаемый массив записывается символ, которому соответствует этот конечный узел, маркер снова помещается в вершину дерева, и процесс повторяется.
Код Хаффмана является префиксным. Это означает, что код каждого символа не является началом кода какого-либо другого символа. Код Хаффмана однозначно восстановим, даже если не сообщается длина кода каждого переданного символа.