

Математические методы формализации информационных процессов: обмена информацией.
Идея кодирования возникла давно и преследовала в основном быстроту и секретность передачи информации. В современных условиях кодирование используется и для создания условий, обеспечивающих надежную и экономичную передачу сообщений по каналам связи.
Под кодированием понимают процедуру сопоставления дискретному сообщению вида: ai (i=1, 2, 3, …,к) определенной последовательности кодовых символов, выбираемых из конечного множества различных элементарных кодовых символов: bi (i=1, 2, 3, …,m).
В кодировании используются различные системы счисления.
Из всех систем счисления практическое назначение имеют: двоичная (R=2), троичная (R=3), четверичная (R=4), восьмеричная (R=8) и десятичная (R=10). Кроме этих систем, человек издавна пользуется двенадцатиричной системой, отсчитывая время, и шестидесятиричной для отсчета углов. Во всех системах используется различное количество цифр. Например: в двоичной используется две цифры: 0 и 1 (011001). Представление машинных кодов производится в шестнадцатеричной системе счисления, где для кодирования информации используется сочетание цифр (0, 1, 2, …9) и букв (A, B, C, D, E, F).
В кодировании используются различные типы кодов: равномерный, неравномерный, избыточный, безизбыточный, помехоустойчивый, оптимальный.
Повышение коэффициента использования канала достигается за счет создания оптимального кода, т.е. вероятность встречаемости элементов одинакова.
Базовыми являются коды Морзе и Шеннона - Фанно.
Код Морзе: наиболее часто встречающимся знакам присваиваются наименее короткие и наоборот.
Код Шеннона – Фанно: принцип кодирования состоит в следующем: множество кодируемых знаков разбиваются на две группы, так, чтобы вероятности их встречаемости были одинаковыми (рис.3).
0. 1
0 00 01 1 0 1
0 1 0 110
1
111
Рис.3 0 1 0 1
1000 1001 1010 1011
2.2. Модуляция
Модуляцией называется процесс управления одним или несколькими параметрами несущей (переносчика информации) в соответствии с изменением параметров первичного сигнала. Модулируемый параметр носителя называется информационным. Различают три вида модуляции: амплитудную (АМ), частотную (ЧМ) и фазовую (ФМ).
В качестве несущей используется не только гармонические, но и импульсные колебания. При этом выбор способов модуляции расширяется до семи видов:
АИМ – амплитудно – импульсная модуляция заключается в том, что амплитуда импульсной несущей изменяется по закону изменения мгновенных значений первичного сигнала.
ЧИМ – частотно – импульсная модуляция. По закону изменения мгновенных значений первичного сигнала изменяется частота следования импульсов несущей.
ВИМ – время – импульсная модуляция, при которой информационным параметром является временной интервал между синхронизирующим импульсом и информационным.
ШИМ – широтно – импульсная модуляция. Заключается в том, что по закону изменения мгновенных значений модулирующего сигнала меняется длительность импульсов несущей.
ФИМ – фазо – импульсная модуляция, отличается от ВИМ методом синхронизации. Сдвиг фазы импульса несущей изменяется не относительно синхронизирующего импульса, а относительно некоторой условной фазы.
ИКМ – импульсно – кодовая модуляция. Ее нельзя рассматривать как отдельный вид модуляции, так как значение модулирующего напряжения представляется в виде кодовых слов.
СИМ – счетно – импульсная модуляция. Является частным случаем ИКМ, при котором информационным параметром является число импульсов в кодовой группе.
Математические методы формализации информационных процессов: обработки информации.
Предположим, что с каждым конкретным потребителем информации связано некоторое множество I, элементами которого являются пары смысл-значение. Существует множество X сообщений, элементами которого могут быть символы, слова, фразы, значения физических величин и процессов – словом, любые знаки. Чтобы из сообщения X могла быть извлечена информация I, должно существовать некоторое отображение фи (X переходит в I,над стрелкой пишем фи) (3.1), являющееся результатом действия по крайней мере трех факторов:
1) договоренности между отправителем и потребителем, что позволяет "осмысливать" сообщение;
2) наличием конкретной цели у адресата;
3) той ситуацией, в которой находится адресат.
Последние два фактора определяют значение сообщения. Отображение фи называется правилом интерпретации сообщении. Оно может быть общим, понятным для многих потребителей информации, либо известным лишь паре отправитель—потребитель, а для других потребителей информации незнание правила фи приводит к тому, что даже воспринятое сообщение не поддается интерпретации или ведет к ложной интерпретации.
Обработка информации не может быть осуществлена вне обработки содержащих ее сообщений.
Можно представить следующую формализованную модель обработки. Пусть X – множество возможных сообщений, фигурирующих в некоторой системе коммуникации. Под обработкой сообщений понимается некоторое отображение Q (X переходит в Y, сверху Q) (3.2), где Y – множество, элементы которого назовем обработанными сообщениями. В общем случае для интерпретации сообщений Y может служить правило, отличное от фи, например, правило y. Тогда отображение пси (Y переходит в J, сверху пси) (3.3) следует рассматривать как интерпретацию обработанных сообщений Y. Здесь множество J есть также множество пар смысл-значение.
Представление обработки в форме (3.2), хотя и не охватывает всех видов обработки сообщений, тем не менее является достаточно общим, чтобы рассматривать многие виды обработки сообщений в технических системах.
Принимая во внимание правило обработки (3.2) и правила интерпретации (3.1) и (3.3), получаем следующую зависимость отображений фи, y и q:
(3.4) |
И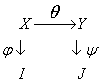 з
диаграммы видно, что каждому сообщению
xОX поставлен в соответствие ровно один
образ j(x)ОI и ровно один образ y(q(x))ОJ.
Действительно:
з
диаграммы видно, что каждому сообщению
xОX поставлен в соответствие ровно один
образ j(x)ОI и ровно один образ y(q(x))ОJ.
Действительно:
yОY имеет образ y(y)ОJ;
xОX имеет образ q(x)ОY, [q(x)=y];
xОX имеет образ y(q(x)).
Учитывая это, на множествах I, J можно определить отношение h, которое может выражать такой смысл: иметь общий прообраз во множестве X. Данное отношение h не обязательно является отображением. Так, если отображение j не биективно, то элемент множества I может иметь более одного прообраза во множестве X. Каждый прообраз как элемент множества X имеет по одному образу в множестве J, и, следовательно, рассматриваемый элемент из множества I находится в отношении h с числом элементов из множества J, равным числу его прообразов в множестве X. В силу этого отношение h не является отображением.
Правило обработки j сообщения X называется сохраняющим информацию, если отношение h является отображением, а диаграмма (3.4) принимает вид
(3.5) |
И з
диаграммы следует, что произведение
отношения jh равно произведению qy, т. е.
диаграмма (3.4) является коммутативной.
Определяющим отображением в диаграмме
(3.4) является отображение h – правило
обработки информации. Поэтому названия
различных видов обработки сообщений
происходят из смысла и имени правила
h. Обычно при выборе вида обработки
сообщений исходят из правила h с учетом
правил интерпретации сообщений j и y.
з
диаграммы следует, что произведение
отношения jh равно произведению qy, т. е.
диаграмма (3.4) является коммутативной.
Определяющим отображением в диаграмме
(3.4) является отображение h – правило
обработки информации. Поэтому названия
различных видов обработки сообщений
происходят из смысла и имени правила
h. Обычно при выборе вида обработки
сообщений исходят из правила h с учетом
правил интерпретации сообщений j и y.
Пусть q и h – взаимно однозначные отображения. Это относится к случаю, когда к правилу q предъявляется требование не терять информацию в процессе обработки, например при перемене носителя информации, переходе от одного вида модуляции к другому и т. и.
Рассмотрим пример из области сообщений на естественном языке. Очевидно, сообщение «ЭВМ облад. сп-стью обр-ки инф-ии», благодаря избыточности текста на естественном языке однозначно восстанавливается как «ЭВМ обладает способностью обработки информации».
В рассмотренных примерах существует обратное преобразование q-1, которое является однозначным, – позволяет восстановить исходный элемент xОX по известному yОY, т. е. исходное сообщение по обработанному.
Рассмотрим теперь случай, когда h является взаимно однозначным отображением, т.е. интерпретация исходного сообщения может быть произведена точно, а q взаимно однозначным отображением не является. Это значит, что множество X имеет большее число элементов, чем множество Y. Тогда q есть сжимающее отображение. В этом случае правило преобразования называется сжатием информации, хотя правильнее говорить о сжатии сообщения или сжатии сигнала.
Наконец, если отображение h не инъективно, то отображение q также не является взаимно однозначным. При этом происходит потеря части информации в обработанном сообщении yОY по сравнению с той, которая содержится в исходном сообщении xОX.