

Реструктуризация Хеш-таблицы
При использовании открытой хеш-таблицы среднее время выполнения операторов возрастает с ростом параметров N/В, аналогично для закрытых хеш-таблиц. Чтобы сохранить постоянное время выполнения операторов, теоретически возможное для хеш-таблиц, необходимо создать новую хеш-таблицу с удвоенным числом сегментов.
N>=0.9B для закрытых хеш-таблиц
N>=2B для открытых хеш-таблиц
Перезапись текущих элементов в новую хеш-таблицу в среднем займет меньше времени чем их вставка в старую таблицу меньшего размера. Затрачиваемое время на перезапись компенсируется более быстрым выполнением операторов.
Индексированные файлы
Еще одним распространенным способом организации файла записи является поддержание файла в отсортированном по значению ключей порядке. Чтобы облегчить операции связанные с поиском создается второй файл, называемый разреженным индексом, который состоит из пары (х,b), где х-значение ключа, а b- это физический адрес блока в котором значение ключа первой записи равно х.


Отыскивается наибольшее z, такое, что z<=x и находится пара (z,b) в индексном файле. В этом случае ключ х оказывается в блоке В, если такой ключ вообще существует в основном файле. Разработано несколько стратегий просмотра индексного файла, рассмотрим несколько из них:
Линейный поиск. Индексный файл читается с самого начала, пока не встретится пара (х ,b) или (у,b), причем у>x. В последнем случае у предыдущей пары (z,b|) z<х, и если запись с ключом х существует, то она находится в блоке b|. линейный поиск применим только для небольших индексных файлов.
Двоичный поиск. Допустим, что индексный файл хранится в блоках b1 , b2 … bn . чтобы найти ключ х берется средний блок bn/2 и х сравнивается со значением ключа у в первой паре первого блока. Если x
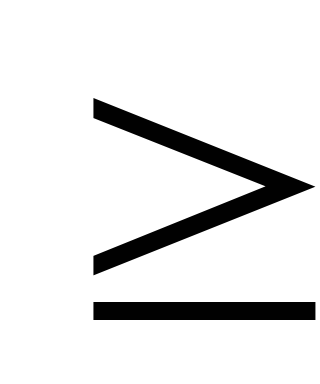 y,
но х меньше чем ключ блока bn/2+1
, то используется линейный поиск. Чтобы
проверить, совпадает ли х с первым
компонентом индексной пары блока bn/2
. в противном
случае повторяется поиск в блоках
bn/2+1
до bn
. При использовании двоичного
поиска нужно проверитьlog2
(n+1).
y,
но х меньше чем ключ блока bn/2+1
, то используется линейный поиск. Чтобы
проверить, совпадает ли х с первым
компонентом индексной пары блока bn/2
. в противном
случае повторяется поиск в блоках
bn/2+1
до bn
. При использовании двоичного
поиска нужно проверитьlog2
(n+1).
Чтобы создать индексированный файл, записи сортируются по значению ключей, а затем распределяются по блокам в возрастающем порядке ключей.
На каждом блоке можно оставлять место для дополнительных записей, которые могут вставляться впоследствии.
Допустим есть отсортированный файл записей, хранящихся в блоках В1 , В2 … Вn. Чтобы вставить в этот файл новую запись, с помощью индексного файла определяется, какой блок В должен содержать новую запись. Если новая запись помещается в этот блок, то она вставляется туда в правильной последовательности. Если новая запись становится первой записью в блоке Вi , то выполняется корректировка индексного файла. Если новая запись не умещается в блок Вi , можно применить следующую стратегию. Необходимо перейти на блок Вi+1 и проверить, можно ли последнюю запись Вi блока поместить в начало Вi+1, если можно, то новая запись вставляется в подходящее место блока Вi . В этом случае необходимо также скорректировать индексный файл.
Если блок Вi+1 заполнен или блок Вi является последним, из файловой системы необходимо получить новый блок. В этот (новый) блок вставляется новая запись, и сам блок размешается вслед за Вi , затем корректируется индексный файл.
Несортированный файл с плотным индексом
В этом случае файл записей сохраняет произвольный порядок самих записей и создается другой файл называемый плотным индексом, он состоит из пар (x,p), где p- это указатель с ключом х в основном файле. Эти пары отсортированы по значению ключа. Для поиска ключей в плотном индексе можно использовать структуру, подобную разряженному индексу.
Если необходимо вставить новую запись, находится последний блок основного файла и производится вставка. Если последний блок полностью заполнен, то из файловой системы получают новый блок, одновременно вставляется указатель на соответствующую запись в файле плотного индекса. Чтобы удалить запись, в ней устанавливается бит удаления и удаляется соответствующий вход в индексном файле.
Вторичный индекс
Если необходим поиск записей, для которых задано значение неключевых полей, необходимо использовать вторичные индексы.
Вторичные индексы- это файлы состоящие из пар (v , p), где v-это список значений по одному для каждого из полей F1 , F2 … Fn , а p-это указатель на v.
Сам факт вторичного индекса может быть организован любым способом из перечисленных выше.
Рассмотрим частный случай, когда задано только два значения для полей вторичного индекса. При поиске данных в случае хеширования все сегменты, за исключением двух, были бы пустыми и таблицы хеширования независимо от общего количества сегментов ускоряли бы выполнение операций всего в два раза. Для случая организации в виде разряженного индекса, в основном файле может оказаться два и более блоков, содержащих одинаковые наименьшие значения ключа, и когда необходимо будет найти записи с этим значением, потребуется рассмотреть все такие блоки.
В случае создания дополнительных вторичных индексов для индексов неключевых полей возникает следующие сложности:
1. Для хранения вторичного индекса требуется место на диске.
2. Каждый создаваемый вторичный индекс замедляет выполнение всех операций вставки и удалений.