

//Роберт Седжвік, Фундаментальні алгоритми; Корман, Лейзерсон, Рівест, Штайн, Алгоритми, побудова і аналіз; Ахо, Хопкрофт, Ульман, Побудова і аналіз обчислювальних виразів; Фрідл, Регулярні вирази; Ноултон, Шилдт; Еккель, Філософія жаби; Монахов, жаба// Структури даних
Тип даних – це множина значень і набір операцій з ними.
Набір даних – це сукупність простих типів даних, що використовуються для опису об’єктів.
Структура даних – це згруповані певним чином типи даних, що використовуються для опису набору даних.
Елементарні структури даних
Лінійні: масив (індексований набір даних), список.
Нелінійні: дерево, хеш-таблиця.
Масив – це фіксованого розміру набір даних однорідного типу, що зберігається у вигляді неперервної послідовності значень.
<Тип> ідентифікатор [] або <тип> [] ідентифікатор – оголошення
Опис – <ідентифікатор> = new <тип > [R-вираз]
Ініціалізація
при описі - <тип> <ідентифікатор>
[] = {<літерал>,{<літерал>}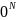 };
};
Приклад
Package lek_1_prim;
…
Бажано при написанні програми створювати окремий метод виведення.
Список – це набір елементів, кожен з яких складається з двох частин: набору даних і посилання на інший елемент.
Одно- і двонаправлений списки
import java.util.*;
class element {
int data;
element prev;
element(int x, element s) { data=x; prev = s;}
}
class stack {
element last;
public void form() {
Scanner nIn = new Scanner(System.in);
while(true) {
System.out.print("\nEnter the elememt? Yes - press key 'y', No - press key 'n' ");
if (nIn.next().equals("y")) {
System.out.print("Enter value -> ");
int x = nIn.nextInt();
if (last == null)
last = new element(x, null);
last = new element(x, last);
}
else {
System.out.print("\nAll element add!\n");
break;
}
}
}
public void prin() {
System.out.print("\nStack -> ");
element current = last;
while (current != null) {
System.out.print(current.data +"\t");
current = current.prev;
}
}
}
public class SpisokDemo {
public static void main(String [] args) {
stack spisok = new stack();
spisok.form();
spisok.prin();
}
}
Дерево – це набір елементів (вузлів), кожен з яких має посилання на множину інших елементів (вузлів), пов’язаних з ним певними вимогами (правилами).
Типи: вільне дерево (невпорядковане дерево з багатьма (множинними) зв’язками); дерево з коренем (один вузол називається коренем і не має інших вузлів під собою); впорядковане дерево (кожен вузол має довільну кількість посилань); М-арне дерево (кожен вузол має однакову кількість посилань); бінарне дерево (кожен вузол пов’язаний тільки з парою дерев, що називаються лівим і правим).
(Менше значення – ліва гілка, більше – права; порівнюємо лише з вершиною, бо маємо лише її адресу – якшо є шось менше - аналогічно).
class Node {
int data;
Node left;
Node right;
Node(int x) { data=x; }
}
class Tree {
Node root;
public void prin() {
prinElem(root);
}
private void prinElem(Node el) {
if (el != null) {
prinElem(el.left);
System.out.print(el.data +" ");
prinElem(el.right);
}
}
public void form() {
Node new_elem = null;
Scanner nIn = new Scanner(System.in);
while(true) {
System.out.print("\nAdd the node? Yes - press key 'y', No - press key 'n' ");
if (nIn.next().equals("y")) {
System.out.print("Enter value -> ");
new_elem = new Node(nIn.nextInt());
if (root == null)
root = new_elem;
ins(root, new_elem);
}
else {
System.out.print("\nTree form!!!!\n");
break;
}
}
}
private void ins(Node cur, Node el) {
while(true) {
if (cur.data > el.data)
if (cur.left == null) {
cur.left = el; break;
}
else cur = cur.left;
else if (cur.data < el.data)
if (cur.right == null) {
cur.right = el; break;
}
else cur = cur.right;
else break;
}
}
}
public class TreeDemo {
public static void main(String [] args) {
Tree first = new Tree();
first.form();
System.out.println("\nTree -> ");
first.prin();
}
}
Алгоритми
Алгоритм – це набір дій (система правил), що визначають послідовність виконання кроків при рішенні поставленої задачі.
Властивості:
Завершенність, вхід, вихід, визначеність, ефективність.
Завершеність (кінечність ?): алгоритм має закінчуватися після кінцевого числа кроків. Наприклад, алгоритм Евкліда (знаходження найбільшого спільного дільника двох цілих чисел): знайти остачу від ділення, перевірити її на рівність нулю, якщо не рівно замінити. Вхід: алгоритм має деяку кількість початкових даних (величин), які беруться із конкретної множини об’єктів.
Вихід: алгоритм має одну чи кілька вихідних величин, які мають цілком визначене відношення до вхідних величин.
Визначеність: кожен крок алгоритму має бути строго визначений (дії повинні бути строгими і однозначними) Наприклад:
Якщо остача рівна нулю, то В найбільше; якщо ні – то проводимо заміну і повторюємо перший крок.
Існують формальні мови опису алгоритмів для уникнення неточного розуміння дій.
Ефективність: всі дії , які необхідно виконати, мають бути достатньо простими, щоб їх в принципі можна було б виконати точно і за певний відрізок (кінцевий) часу на папері.
Застосування алгоритмів:
Задачі обробки (опрацювання) даних (сортування і пошук інформації);
Задачі оптимізації (оптимальний маршрут);
Задачі захисту інформації (криптографія);
Обчислювальні задачі (матриці, інтеграли, диференціальні рівняння);
Задачі лінійного програмування (передвиборна кампанія, знаходження мінімальної вартості авіа білетів для зменшення кількості вільних місць).
Рекурсія
Рекурсивний алгоритм – це алгоритм, який вирішує задачу шляхом вирішення декількох більш вузьких варіантів тієї ж задачі.
Рекурсивні функції – це функції, що викликають самі себе.
Будь-яке обчислення, яке передбачає виконання циклів, можна реалізувати посередництвом рекурсивних функцій і навпаки.
Рекурсія використовується для вираження складних алгоритмів в компактній формі без втрати ефективності.
Особливості:
Рекурсивна функція не може викликати себе до безкінечності, тобто повинна мати деяку кінцеву кількість викликів.
Завжди повинна мати умову закінчення.
Кожен наступний виклик виконується із зменшенням значення параметра функції.
(Наприклад, ви числення факторіалу).
//Малюночок: усе = адресний простір програми; з низу = купа, вершина стеку, стек, дані, код функції, код програми; рекурсія (з кожним викликом її у стек програми записується те місце в пам’яті, в яке потрібно повернутись; дійшли до кінця – пішли в іншу сторону – куди ми маємо повернутися, на початок).//
Принцип «розділяй та пануй»
Коли ми говоримо про рекурсивні алгоритми, то вони використовують цей принцип. Задача розбивається на під-задачі (ділення виконується до декотрої неподільної складової) і рішення під-задачі приводить до отримання рішення всієї задачі.
(пошук елементу у масиві).
Здача «Ханойські вежі»
Дано: три стержні і ен дисків… (правила)
Динамічне програмування - це методика розробки алгоритмів, які використовують принцип «Р і П» для задач з завданнями, що перекриваються.
Види:
Висхідне («восходящее») – для отримання деякого значення на і-му кроці треба попереднє обчислення необхідних значень на попередніх кроках;
Низхідне («нисходящее») – значення, що були обчисленні на попередніх кроках і необхідні для отримання значення на і-му кроці, зберігаються та оцінюються.
//Фібоначчі!!!!!!//
Алгоритми обходу дерева
Послідовний (прямий) – зліва направо, опрацьовується ліве під-дерево, потім вузол, а потім праве під-дерево;
Паралельний (оборотній) – знизу вверх, опрацьовується ліве під-дерево, потім праве, після цього вузол;
В ширину – зверху донизу, опрацьовується вузол, потім ліве під-дерево, і праве.
(Рекурсія)
class Node {
int data;
Node left;
Node right;
Node(int x) { data=x; }
}
class Tree {
Node root;
public void prin() {
prinElem(root, 0);
}
private void prinElem(Node elem, int h) {
if (elem != null) {
for(int i=0; i<h; i++)
System.out.print(" ");
System.out.println(elem.data);
prinElem(elem.left, h+1);
prinElem(elem.right, h+1);
}
}
private Node find(Node cur, Node n_el) {
if (cur.data > n_el.data)
if (cur.left == null)
cur.left = n_el;
else cur.left = find(cur.left, n_el);
else if (cur.data < n_el.data)
if (cur.right == null)
cur.right = n_el;
else cur.right = find(cur.right, n_el);
return cur;
}
public void ins(int d) {
Node n_el = new Node(d);
if (root == null)
root = n_el;
else
root = find(root, n_el);
}
}
public class DemoTreeRecur {
public static void main(String [] args) {
Tree ddd = new Tree();
for(int i=0; i<10; i++)
ddd.ins((int)(Math.random()*100));
System.out.println("Tree:");
ddd.prin();
}
}
Алгоритм видалення елемента дерева
Знайти вузол для видалення.
Оцінити чи має знайдений вузол ліве і праве під-дерево:
Якщо не має – посиланню надається нульове значення;
Має або ліве, або праве дерево – посилання перевизначається у відповідне під-дерево;
Має обидва під-дерева – виконується пошук вузла, що стоїть на самому низькому рівні для заміни того, що видаляється.
Існує два варіанти пошуку такого вузла:
А) самий крайній правий вузол в лівому під-дереві;
Б) самий крайній лівий вузол у правому під-дереві.
Void del(int delet) { root=find2(root, delet); }
Private Node find2(Node cur, int data){
If (cur!=null){
If (cur.data==data){
If (cur.left==null){cur=cur.rigt; return cur; }
Else if (cur.right==null){
Cur=cur.left; return cur;….
Private Node zam (Node dd, Node cur){
If (cur.left!=null)
Cur.left=zam(dd, cur.left);
Else {
dd.data=cur.data;
cur=cur.right;
}
….
Множина - це набір унікальних об’єктів (наприклад, словники), для представлення яких використовується хеш-таблиця, основана на масивах.
Хеш-таблиця – це масив асоціативного типу, в якому елементи зберігаються (розподіляються) по методу хешування.
Хешування – процес кодування (перетворення) об’єктів індексуванням по ключу.
У залежності від того яким чином використовуються ключі об’єктів виділяють:
Таблиці з прямою адресацією
Хеш-таблиці (динамічні хеш-таблиці)
Хеш-таблиці з відкритою адресацією
Перше:
Для представлення множини об’єктів, що ідентифікуються ключем, використовується масив, в якому індекс відповідає значенню ключа.
Друге:
Для розрахунку індексу елемента у масиві використовується хеш-функція. Колізія – ситуація, коли два ключі можуть бути хешовані у елемент масиву з однаковим індексом. (для розв’язку такої проблеми створюються списки елементів по тому індексу; максимум – прив’язка списку з 3 елементів)
(розмірність хеш-таблиці повинна бути більша чи рівна кількості об’єктів, які потрібно розмістити; заповнення хеш-таблиці – 75 % максимум).
Методи хешування
Метод ділення:
Значення ключа – ціле додатне число (або ключ можна легко представити таким числом);
Дільник – просте число далеке від степені двійки.
Індекс вичислюється шляхом застосування операції отримання залишку від ділення значення ключа на розмірність хеш-таблиці.
Метод множення:
Значення ключа – дійсне число з діапазону від 0 до 1;
Множник – значення рівне степені двійки.
Індекс розраховується за наступним алгоритмом:
А) ключ множиться на константу з діапазону від 0 до 1 для виділення дрібної частини (0,6180339887);
Б) отримане значення множиться на розмірність хеш-таблиці і округляється до найменшого цілого.
3. Метод універсального хешування:
Індекс обчислюється з використанням хеш-функції, що випадково обирається з деякого відібраного класу функцій.
Третє:
Всі об’єкти зберігаються безпосередньо у хеш-таблиці.
Для розрахунку індексу використовуються хеш-функції.
Для розв’язку колізій визначається послідовність елементів, серед яких знаходиться пустий елемент.
class Obj {
int x;
int y;
Obj next;
Obj(int a, int b) { x=a; y=b; }
public int hashCode() { return ((x<<1) + y); }
public boolean equals(Object o) {
return (x == ((Obj)o).x)&&(y == ((Obj)o).y); }
public String toString() {
return (String.valueOf(x) + " " + String.valueOf(y)); }
}
class Table {
Obj mas[];
Table(int r) {mas = new Obj [r]; }
private int Code(Obj o) {
return (o.hashCode() % mas.length); }
private void Col(Obj cur, Obj n_ob) {
while ((cur != null) && (!cur.equals(n_ob)))
if (cur.next == null) {
cur.next = n_ob; break;
}
else cur = cur.next;
}
public void ins(Obj new_ob) {
int h = Code(new_ob);
if (mas[h] == null) mas[h] = new_ob;
else Col(mas[h], new_ob);
}
public void prin() {
for(int i=0; i<mas.length; i++) {
Obj temp = mas[i];
System.out.print(i +") ");
while (temp != null) {
System.out.print(temp + "; ");
temp = temp.next;
}
System.out.println();
}
}
}
public class HashDemo {
public static void main(String [] args) {
Scanner in = new Scanner(System.in);
int a, b;
System.out.print("Enter size HashTable -> ");
Table hash = new Table(in.nextInt());
while(true) {
System.out.print("\nAdd the object? Yes - press key 'y', No - press any key ");
if (in.next().equals("y")) {
System.out.print("Enter value elememt -> a and b ");
a = in.nextInt();
b = in.nextInt();
hash.ins(new Obj(a, b));
}else break;
}
System.out.println("\nHashTable");
hash.prin();
}
}
Способи:
Лінійне зондування: М[i+p], де р=1,2,3… ; послідовно проглядаються усі наступні комірки з переходом з останньої на першу;
Квадратичне зондування: М[i+p^2], де р=1,2,3… ; послідовно проглядаються усі елементи з квадратичним зміщенням і з переходом з останньої на першу;
Подвійне зондування: М[i+f(p)], p=1,2,3… f(p)=p*hl(key) ; зміщення від знайденого елементу вираховується за допомогою хеш-функції;
Ідеальне зондування: М[i][hl(key)] двовимірний масив і дві хеш-функції.
Сортування – це процес упорядкування деяких даних у відповідності деяким визначеним критеріям (правилам)
Випадки сортування:
У використанні до самих даних
У використанні до кроків, асоційованих з даними (до ключів)
Група методів сортування:
Елементарне сортування
Методи швидкого сортування
Методи злиття і сортування злиттям
Методи пірамідального сортування
Методи порозрядного сортування
Елементарні методи сортування
Сортування методом вибору
Методи вставки
Методи бульбашки
Метод Шелла
По індексам вказівника
Метод розподіленого підрахунку
Метод вибору (вибірки)
Суть – в наборі даних, які відрізняються елементом з найменшим (чи найбільшим) значенням, що міняється місцями з першим, потім знаходиться другий найменший (найбільший) і елементи міняються місцями з другим, і це продовжується до впорядкування даних.
Недоліки – на час виконання степінь упорядкування до сортування показує малий вплив.
public static void sort(double m[]) {
double temp;
int max;
for(int k=0; k<m.length; k++) {
max = k;
for(int i=k+1; i<m.length; i++)
if (m[i] > m[max])
max = i;
temp = m[k];
m[k] = m[max];
m[max] = temp;
}
}
Сортування методом вставки
Суть – кожний елемент набору даних аналізується, визначається місце його розміщення серед вже відсортованих даних; потім усі дані, які повинні стояти після нього, зміщуються вправо, а дальній елемент поміщається у вільну комірку пам'яті.
На відміну від сортування методом вибірки час виконання залежить від початкового порядку даних.
public static void sort(double m[]) {
double temp;
for(int k=m.length-1; k>0; k--)
if (m[k] < m[k-1]) {
temp = m[k];
m[k] = m[k-1];
m[k-1] = temp;
}
for(int i=2; i<m.length; i++) {
int j=i; temp=m[i];
while (temp < m[j-1]) {
m[j] = m[j-1]; j--;
}
m[j] = temp;
}
}
2-ий варіант:
public class Sort_4 {
public static void sort(double m[]) {
double temp;
for(int k=1; k<m.length; k++)
for(int i=k; i>0; i--)
if (m[i] < m[i-1]) {
temp = m[i];
m[i] = m[i-1];
m[i-1] = temp;
}
}
Сортування методом бульбашки
Суть – виконується циклічний прохід по набору даних.
public static void sort(double m[]) {
double temp;
for(int k=0; k<m.length; k++)
for(int i=m.length-1; i>k; i--)
if (m[i] < m[i-1]) {
temp = m[i];
m[i] = m[i-1];
m[i-1] = temp;
}
}
Метод Шелла – розширений метод сортування вставкою , в якому відбувається обмін не тільки сусідніми даними, а і тих що знаходяться далеко один від одного
Набір даних розбивається на незалежні під-набори, які пересікаються, і в кожному під-наборі сортування ведеться методом вставки.
На практиці використовується низхідна послідовність в геометричній послідовності.
Кнут запропонував наступний набір кроків:
1 4 13 40 121 164 1093 3280 (b=b*3+1)
public static void sort(double m[]) {
double temp; int h;
for(h=1; h<=m.length/9; h=3*h+1) ;
for (; h>0; h/=3)
for(int i=1+h; i<m.length; i++) {
int j=i; temp=m[i];
while ((j>=h) && (temp < m[j-h])) {
m[j] = m[j-h];
j-=h;
}
m[j] = temp;
}
}
Сортування за індексами і вказівниками
Використовується для непростих типів даних
Суть – сортуванню належить не сам набір даних , а масив посилань (вказівників на елементи набору даних ) або індексний масив (елементи – це індекси елементів набору даних).
Сортування методом розподіленого обчислення
Використовується для наборів даних, елементи яких ідентифікуються ключами, що визначаються цілими значеннями із діапазону [0, М](ключі можна використовувати в якості індексів елементів). Суть – спочатку підкреслюється кількість ключів для кожного значення ключа в масиві індексів, далі вичислюється часткові суми (для кожного значення ключа підраховується кількість ключів з маленькими значеннями), потім в додатковий масив.
class Ob {
String name;
int nomer;
double ball;
void set(String n, int m, double b) {
name = n; nomer = m; ball = b;
}
void prin() {
System.out.println("name="+name+"\tnomer="+nomer+"\tball="+ball+";");
}
}
public class Sort_6 {
final static int count = 7;
public static void sort(Ob m[], int a[]) {
int i, j, t=0, t1,
key[] = {0,0,0,0},
dop[] = new int [count];
for (i=0; i<count; i++)
if (!(m[a[i]].nomer%4==3)) key[m[a[i]].nomer+1] ++;
for(j=1; j<key.length; j++) key[j] += key[j-1];
for(i=0; i<count; i++) dop[key[m[a[i]].nomer]++] = a[i];
for(i=0; i<count; i++) a[i] = dop[i];
}
Кишенькове (ги-ги-гииии…) сортування (тут писала Таня :)))))
(вещественное значение ключа/равномерное распредиление. Значение ключа в диапазоне [0:1]
Диапазон значений набора данных делится на одинаковые интервалы (части). Каждый интервал представляет собой карманы (яму) В которой будут вклад. в виде списка однонаправленного списка элементы набора данных.
Диапазон значений разбивается на интервалы и по их к-ству создается одномерный массив
Элементы набора данных распределяют по интервалам в виде списка.
Каждый карман сортируется любым способом.
Последовательно все элементы вынимаются и переписываються в набор данных.
Порозрядне сортування
Ґрунтується на обробці ключа по одній порції за крок; алгоритм побудований на сортуванні об’єктів з ключами, де ключі розглядаються як числа, представлені в деякій системі числення, і обробка чисел виконується порціями (цифрами) за один крок. Для більш ефективної роботи можливе додавання сортування вставками, коли кількість цифр ключів, що лишилися, менше деякого встановленого значення.
Існує два базових підходи:
За старшою цифрою;
За молодшою цифрою.
В залежності від контексту ключем може бути рядок (послідовність розрядів змінної довжини) чи слово (послідовність розрядів фіксованої довжини). Кожен ключ представляється у двійковому вигляді. Замість того, щоб порівнювати 2 ключа, провіряється чи рівні або 0, або ж 1 окремі розряди ключа.
Часткова сума являє собою позицію (індекс) у масиві ключів, з якої…
Алгоритми «швидкого» сортування
Базується на принципі «розділяй і пануй» і операції вибірки. Залежно від способу поділу набору даних на частини, виділяють декілька видів швидкого сортування: