

Практические подходы к изучению показателей уровня жизни
Анализ уровня жизни в Мурманской области, построение модели.
Для построения эконометрической модели уровня жизни используется интегральный показатель – Индекс развития человеческого потенциала (ИРЧП). Индекс публикуется ООН в ежегодном отчёте о развитии человеческого потенциала с 1990 года. При его подсчёте учитываются 3 показателя:
ожидаемая продолжительность жизни — оценивает долголетие;
уровень грамотности населения страны (среднее количество лет, потраченных на обучение и ожидаемая продолжительность обучения);
уровень жизни, оценённый через ВНД на душу населения по паритету покупательной способности (ППС) в долларах США.
В связи с этим возникает задача исследовать зависимость ИРЧП (y) от этих объясняющих переменных:
y – Индекс развития человеческого потенциала;
x1 – ожидаемая продолжительность жизни;
x2 – среднее количество лет, потраченных на обучение;
x3 – ожидаемая продолжительность обучения;
x4 - уровень жизни, оцененный через ВНД на душу населения по ППС в долларах США.
Эта задача решается с помощью множественного регрессионного анализа. Множественная регрессия представляет собой регрессию результативного признака с двумя и большим числом факторов, т. е. модель вида:
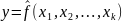 (1)
(1)
Любое эконометрическое исследование начинается со спецификации модели, т. е. с формулировки вида модели, исходя из соответствующей теории связи между переменными. Иными словами, исследование начинается с теории, устанавливающей связь между явлениями.
Прежде всего, из всего круга факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы. Для достижения этой цели воспользуемся методом главных компонент. Его суть – сократить число объясняющих переменных до наиболее существенно влияющих факторов. Метод главных компонент наиболее распространенный метод факторного анализа, являющегося в свою очередь одним из методов многомерного статистического анализа.
Факторный анализ позволяет производить свертку пространства. Таким образом, проведем свертку пространства отношению к факторам, влияющим на изменение ИРЧП с помощью программного комплекса SPSS (версия 17.0) для Windows. Исходные данные за период с 2000 года 2009 год представлены в таблице «Показатели Индекса развития человеческого потенциала в Мурманской области» (Таблица 2.1).
Таблица 2.1
Показатели Индекса развития человеческого потенциала в Мурманской области
Показатели
Годы |
Ожидаемая продолжительность жизни |
Уровень грамотности населения |
Уровень жизни, оцененный через ВНД на душу населения по ППС в долл. США |
Индекс развития человеческого потенциала |
|
Среднее количество лет, потраченных на обучение |
Ожидаемая продолжительность обучения |
||||
2000 |
65,34 |
16 |
16 |
15258 |
0,763 |
2001 |
65,23 |
16 |
18 |
14356 |
0,778 |
2002 |
64,95 |
17 |
19 |
14567 |
0,756 |
2003 |
64,85 |
16 |
16 |
13589 |
0,790 |
2004 |
65,27 |
17 |
16 |
15607 |
0,794 |
2005 |
65,3 |
18 |
16 |
16301 |
0,796 |
2006 |
66,6 |
16 |
16 |
16709 |
0,798 |
2007 |
67,51 |
17 |
17 |
17908 |
0,799 |
2008 |
67,88 |
16 |
16 |
17867 |
0,800 |
2009 |
68,67 |
16 |
16 |
17890 |
0,830 |
После того как программа произведет все необходимые расчеты, откроется окно с результатами построения факторной модели.
В первой таблице, выводимой на экран компьютера, содержатся результаты тестов «КМО» и «Бартлетта» (Таблица 2.2).
Таблица 2.2
Мера адекватности и критерий Бартлетта |
||
Мера выборочной адекватности Кайзера-Мейера-Олкина. |
,465 |
|
Критерий сферичности Бартлетта |
Прибл. хи-квадрат |
46,401 |
ст.св. |
15 |
|
Знч. |
,000 |
|
Источник: Расчеты программы SPSS 17.0
Результаты теста «КМО» позволяют сделать вывод относительно общей пригодности имеющихся данных для факторного анализа. Результаты данного теста варьируются в интервале от 0 (факторная модель абсолютно неприменима) до 1 (факторная модель идеально описывает структуру данных). Факторный анализ следует считать пригодным, если «КМО» находится в пределах от 0,5 до 1. В нашем случае этот показатель равен 0,5, что является нормальным результатом.
Тест «Бартлетта» проверяет гипотезу о том, что переменные, участвующие в факторном анализе, некоррелированы между собой. Если данный тест дает положительный результат (переменные некоррелированы), факторный анализ следует признать непригодным использовать другие статистические методы. Статистикой, определяющей пригодность факторного анализа по тесту «Бартлетта», является значимость (строка Знч.). При приемлемом уровне значимости (ниже 0,05) факторный анализ считается пригодным для анализа исследуемой выборочной совокупности. В нашем случае рассматриваемый тест показывает весьма низкую значимость (менее 0,001), из чего следует вывод о применимости факторного анализа. Итак, на основании тестов «КМО» и «Бартлетта» мы пришли к выводу, что имеющиеся у нас данные практически идеально подходят для исследования при помощи факторного анализа.
Следующим шагом в интерпретации результатов факторного анализа является рассмотрение результирующей ротированной матрицы факторных коэффициентов – таблицы «Матрица повернутых компонент» (Таблица 2.3). Данная таблица является основным результатом факторного анализа. В ней отражаются результаты классификации переменных по факторам. В нашем случае при помощи автоматического метода определения количества факторов (на основании характеристических чисел больше 1) была построена практически приемлемая факторная модель, в которой 5 из 6 переменных удалось однозначно классифицировать по небольшому числу факторов. Данный результат может считаться хорошим.
Таблица 2.3
Матрица повернутых компонентa |
||
|
Компонента |
|
|
1 |
2 |
дата |
,967 |
|
х4 |
,927 |
|
х1 |
,908 |
|
у |
,903 |
|
х3 |
-,532 |
|
х2 |
|
,971 |
Метод выделения: Анализ методом главных компонент. Метод вращения: Варимакс с нормализацией Кайзера. |
||
a. Вращение сошлось за 3 итераций. |
||
Источник: Расчеты программы SPSS 17.0
Следующим шагом в представлении результатов факторного анализа является таблица «Полная объясненная дисперсия» (Таблица 2.4).
Таблица 2.4
Полная объясненная дисперсия |
|||||||
Компонента |
Начальные собственные значения |
Суммы квадратов нагрузок вращения |
|||||
Итого |
% Дисперсии |
Кумулятивный % |
Итого |
% Дисперсии |
Кумулятивный % |
||
1 |
3,757 |
62,618 |
62,618 |
3,718 |
61,973 |
61,973 |
|
2 |
1,088 |
18,141 |
80,759 |
1,127 |
18,786 |
80,759 |
|
3 |
,817 |
13,623 |
94,382 |
|
|
|
|
4 |
,272 |
4,535 |
98,918 |
|
|
|
|
5 |
,054 |
,899 |
99,817 |
|
|
|
|
6 |
,011 |
,183 |
100,000 |
|
|
|
|
Метод выделения: Анализ главных компонент. Источник: Расчеты программы SPSS 17.0
|
|||||||
По таблице «Полная объясненная дисперсия» можно увидеть, что два собственных фактора имеют значения превосходящие единицу. Следовательно, для анализа отобрано только два фактора. Первый фактор объясняет 62,618% суммарной дисперсии, второй фактор – 18,141%.
После выделения наиболее существенно влияющих факторов на результативный признак построим уравнение множественной регрессии также с помощью программного комплекса SPSS (версия 17. 0) для Windows.
Первое, на что следует обратить внимание, — это таблица «Дисперсионный анализ» (Таблица 2.5). Статистическая значимость (столбец Знч.) должна быть меньше или равна 0,05.
Таблица 2.5
Дисперсионный анализb |
|||||||
Модель |
Сумма квадратов |
ст.св. |
Средний квадрат |
Щ |
Знч. |
||
1 |
Регрессия |
,002 |
1 |
,002 |
10,858 |
,011a |
|
Остаток |
,002 |
8 |
,000 |
|
|
||
Всего |
,004 |
9 |
|
|
|
||
a. Предикторы: (конст) x1 |
|||||||
b. Зависимая переменная: y Источник: Расчеты программы SPSS 17.0
|
|||||||
Затем следует рассмотреть таблицу «Сводка для модели», содержащую важные сведения о построенной модели (Таблица 2.6). Коэффициент детерминации R является характеристикой силы общей линейной связи между переменными в регрессионной модели. Он показывает, насколько хорошо выбранные независимые переменные способны определять поведение зависимой переменной. Чем выше коэффициент детерминации (изменяющийся в пределах от 0 до 1), тем лучше выбранные независимые переменные подходят для определения поведения зависимой переменной. Требования к коэффициенту R такие же, как к коэффициенту корреляции: в общем случае он должен превышать хотя бы 0,5. В нашем примере R = 0,759, что является приемлемым показателем.
Таблица 2.6
Сводка для моделиb |
||||
Модель |
R |
R-квадрат |
Скорректированный R-квадрат |
Стд. ошибка оценки |
1 |
,759a |
,576 |
,523 |
,01443 |
a. Предикторы: (конст) x1 |
||||
b. Зависимая переменная: y Источник: Расчеты программы SPSS 17.0
|
||||
Также важной характеристикой регрессионной модели является коэффициент R2, показывающий, какая доля совокупной вариации в зависимой переменной описывается выбранным набором независимых переменных. Величина R2 изменяется от 0 до 1. Как правило, данный показатель должен превышать 0,5 (чем он выше, тем показательнее построенная регрессионная модель). В нашем примере R2 = 0,576 — это значит, что регрессионной моделью описано 57,6 % случаев. Таким образом, при интерпретации результатов регрессионного анализа следует постоянно иметь в виду существенное ограничение: построенная модель справедлива только для 57,6 % случаев.
Третьим практически значимым показателем, определяющим качество регрессионной модели, является величина стандартной ошибки расчетов (столбец Стд. ошибка оценки). Данный показатель варьируется в пределах от 0 до 1. Чем он меньше, тем надежнее модель (в общем случае показатель должен быть меньше 0,5). В нашем примере ошибка составляет 0,1443, что является приемлемым результатом.
На основании таблиц «Дисперсионный анализ» и «Сводка для модели» можно судить о практической пригодности построенной регрессионной модели. Учитывая, что «Дисперсионный анализ» показывает весьма высокую значимость (0,01), коэффициент детерминации превышает 0,6, а стандартная ошибка расчетов меньше 0,5, можно сделать вывод о том, что с учетом ограничения модель описывает 57,6 % совокупной дисперсии, то есть построенная регрессионная модель является статистически значимой и практически приемлемой.
После того как мы констатировали приемлемый уровень качества регрессионной модели, можно приступать к интерпретации ее результатов. Основные практические результаты регрессии содержатся в таблице «Коэффициенты» (Таблица 2.7). В этой таблице практически значимыми являются четыре показателя: «Бета», «В» и «Стд. Ошибка». Рассмотрим последовательно, как их следует интерпретировать.
Таблица 2.7
Коэффициентыa |
||||||||
Модель |
Нестандартизованные коэффициенты |
Стандартизованные коэффициенты |
t |
Знч. |
||||
B |
Стд. Ошибка |
Бета |
||||||
1 |
(Константа) |
,039 |
,228 |
|
,172 |
,868 |
||
x1 |
,011 |
,003 |
,759 |
3,295 |
,011 |
|||
Источник: Расчеты программы SPSS 17.0
|
||||||||
В первом столбце таблицы «Коэффициенты» содержатся независимые переменные, составляющие регрессионное уравнение (удовлетворяющие требованию статистической значимости). В нашем случае в регрессионную модель входит одна переменная (x1). Исключенные переменные содержатся в таблице «Исключенные переменные» (Таблица 2.8). Итак, мы можем сделать первый вывод о том, что на Индекс развития человеческого потенциала оказывает влияние один параметр: ожидаемая продолжительность жизни.
Таблица 2.8
Исключенные переменныеb |
||||||
Модель |
Бета включения |
t |
Знч. |
Частная корреляция |
Статистики коллинеарности |
|
Толерантность |
||||||
1 |
x2 |
,139a |
,554 |
,597 |
,205 |
,923 |
x3 |
-,396a |
-1,874 |
,103 |
-,578 |
,906 |
|
x4 |
,033a |
,058 |
,955 |
,022 |
,184 |
|
a. Предикторы в модели: (конст) x1 |
||||||
b. Зависимая переменная: y |
||||||
Источниик: Расчеты программы SPSS 17.0
После того, как мы определили состав параметров, влияющих на Индекс развития человеческого потенциала, можно определить направление и силу влияния на него каждого частного параметра. Это позволяет сделать столбец «Бета», содержащий стандартизированные β-коэффициенты регрессии. Данные коэффициенты также дают возможность сравнить силу влияния параметров между собой. Знак (+ или -) перед β-коэффициентом показывает направление связи между независимой и зависимой переменными. Положительные β-коэффициенты свидетельствуют о том, что возрастание величины данного частного параметра увеличивает зависимую переменную (в нашем случае независимые переменные ведут себя подобным образом). Отрицательные коэффициенты означают, что при возрастании данного частного параметра общая оценка снижается. Как правило, при определении связи между оценками параметров это свидетельствует об ошибке и означает, например, что выборка слишком мала.
Столбец «В» таблицы «Коэффициенты» содержит коэффициенты регрессии (нестандартизированные). Они служат для формирования собственно регрессионного уравнения, по которому можно рассчитать величину зависимой переменной при разных значениях независимых.
Особая строка «Константа» содержит важную информацию о полученной регрессионной модели: значение зависимой переменной при нулевых значениях независимых переменных. Чем выше значение константы, тем хуже подходит выбранный перечень независимых переменных для описания поведения зависимой переменной. В общем случае считается, что константа не должна быть наибольшим коэффициентом в регрессионном уравнении (коэффициент хотя бы при одной переменой должен быть больше константы). Однако в практике часто свободный член оказывается больше всех коэффициентов вместе взятых. Это связано в основном с относительно малыми размерами выборок. В нашем случае величина константы меньше 1, что является весьма хорошим результатом.
Итак, в результате построения регрессионной модели можно сформировать следующее регрессионное уравнение:
y=0,039+0,011x1, где (2)
y – Индекс развития человеческого потенциала;
x1 – ожидаемая продолжительность жизни.
Коэффициент регрессии при переменной х1, свидетельствует о том, что с увеличением ожидаемой продолжительности жизни, ИРЧП увеличивается на 0,011 при постоянном уровне среднего количества лет, потраченного на обучение, ожидаемой продолжительности обучения и уровня жизни, оцененного через ВНД на душу населения по ППС в долларах США.
Последний показатель, на который целесообразно обращать внимание при интерпретации результатов регрессионного анализа, — это стандартная ошибка, рассчитываемая для каждого коэффициента в регрессионном уравнении (столбец Стд. ошибка). При 95%-ном доверительном уровне каждый коэффициент может отклоняться от величины В на (±2 * Стд. ошибка). Это означает, что, например, коэффициент при параметре Ожидаемая продолжительность жизни (равный 0,011) в 95 % случаев может отклоняться от данного значения на (±2 * 0,03) или на (±0,06). Минимальное значение коэффициента будет равно 0,011 - 0,06 = -0,049, а максимальное – 0,011 + 0,06 = 0,071. Таким образом, в 95 % случаев коэффициент при параметре «ожидаемая продолжительность жизни» варьируется в пределах от -0,049 до 0,071 (при среднем значении 0,011). На этом интерпретация результатов регрессионного анализа может считаться завершенной.