

1.4. Нейронні мережі, що самонавчаються
1.4.1. Базова модель
Принципи побудови НМ, що самонавчаються розглянемо на основі моделі Ліппмана-Хеммінга. Відзначимо, що в якості основи можливо застосувати і інші моделі. Однак розгляд моделі Ліппмана-Хеммінга рекомендований [68] по причині її простоти та можливості розгляду всіх основних аспектів процесу самонавчання. В НМ, що базуються на вказаній моделі, кожен з образів однозначно описується відповідним K-вимірним вектором з бінарними компонентами, а критерієм класифікації є відстань Хеммінга від до бібліотечних образів. Класифікація полягає в пошуку найближчого до бібліотечного образу. Відстань між векторами розраховується відповідно правилу Хеммінга, як кількість неоднакових компонент образів:
|
(1.49) |
 ,
,де
![]()
відстань від бібліотечного образу хк
до піддослідного образу ,
відстань від бібліотечного образу хк
до піддослідного образу ,
![]()
відстань між і-ми
компонентами бібліотечного образу хк
та піддослідного образу ,
К
кількість компонент.
відстань між і-ми
компонентами бібліотечного образу хк
та піддослідного образу ,
К
кількість компонент.
На рис. 1.8 показана структура НМ Ліппмана-Хеммінга для розпізнавання образу, що описуються двома параметрами, як одного із трьох бібліотечних класів. Структурно модель складається із вхідного шару нейронів та шару образів. В задачу вхідних нейронів входить лише розподіл вхідної інформації між нейронами шару образів. Кількість вхідних нейронів дорівнює кількості компонент в образі, тобто кількості параметрів, що характеризують образ.
Р ис.
1.8 Приклад структури НМ Ліппмана-Хеммінга
ис.
1.8 Приклад структури НМ Ліппмана-Хеммінга
Кожен вхідний нейрон пов'язаний з кожним нейроном шару образів, кількість яких дорівнює кількості кластерів. Нейронам шару образів відповідає функція порогова активації виду:
|
(1.50) |
де NET вхід нейрону, що в загальному випадку розраховується за формулою (1.3).
Процес навчання НМ Ліппмана-Хемінга полягає в тому, що вагові коефіцієнти нейронів шару образів встановлюються рівними нормованим компонентам бібліотечних образів:
|
(1.51) |
 ,
,
де
![]()
ваговий коефіцієнт n-го
входу для m-го
нейрону шару образів,
ваговий коефіцієнт n-го
входу для m-го
нейрону шару образів,
![]()
n-та
компонента для m-го
нейрону (образу), К
кількість компонент.
n-та
компонента для m-го
нейрону (образу), К
кількість компонент.
Компоненти невідомого образу також нормуються:
|
(1.52) |
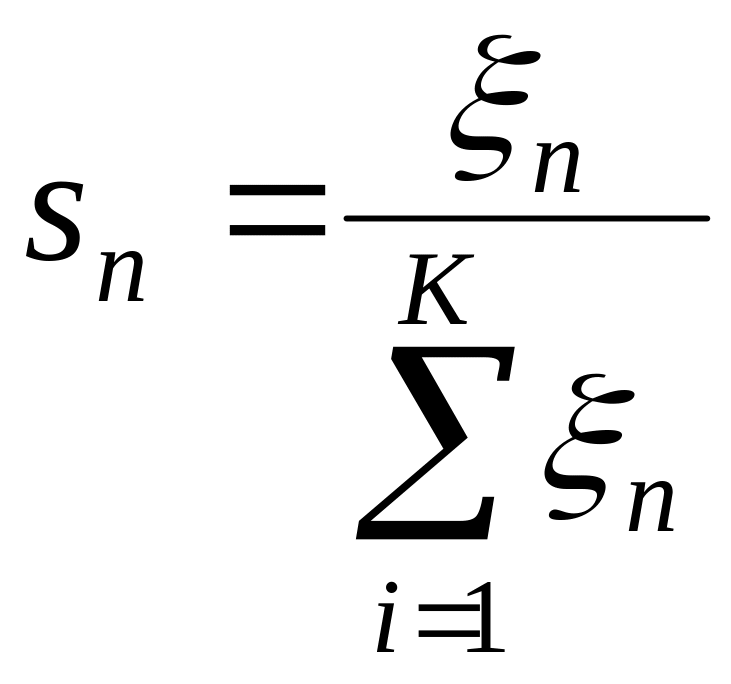 ,
,де
![]()
нормована n-та компонента вхідного
вектору .
нормована n-та компонента вхідного
вектору .
Подача невідомого образу призводить до того, що нейрони шару образів приймають початкові рівні активації:
|
(1.53) |
 ,
,де
![]()
початковий рівень активації m-го
нейрону, М
кількість бібліотечних образів, f
функція активації нейрону шару образів
виду (1.50).
початковий рівень активації m-го
нейрону, М
кількість бібліотечних образів, f
функція активації нейрону шару образів
виду (1.50).
Після цього відбувається ітераційний процес вибору нейрону, який є найближчим до невідомого образу. Вибір реалізується за рахунок того, що по гальмуючим зв'язкам кожен з нейронів отримує негативне збудження від всіх інших нейронів. Величина негативного збудження від будь-якого нейрону пропорційна величині активації цього нейрону. Водночас кожен з нейронів отримує позитивне збудження від самого себе. Розрахунок рівня активації m-го нейрону шару образів на t-ій ітерації можливо здійснити так:
|
(1.54) |

Після деякої кількості ітерацій зостається єдиний активний нейрон-переможець, що вказує на клас до якого належить піддослідний образ. Такий механізм вибору нейрону, отримав назву “переможець забирає все”( Winner Take All - WTA ) [17, 24, 29, 34, 68]. При цьому базовим методом навчання нейрону-переможця є метод Хебба [17, 24, 68].
НМ Ліппмана-Хеммінга є моделлю з прямою структурою пам'яті. Інформація, що міститься з бібліотечних образах не узагальнюється а безпосередньо запам'ятовується в синоптичних зв'язках. За рахунок цього навчання НМ такого типу відбувається набагато швидше ніж навчання БШП. Принциповим недоліком розглянутого варіанту НМ є жорстко апріорно задана кількість кластерів, що відповідає кількості нейронів в шарі образів. В багатьох практичних задачах апріорно визначити кількість кластерів не можливо. Тому, було б краще, якби НМ сама розраховувала кількість кластерів, виходячи із реальних навчальних даних. Для вирішення цієї проблеми застосовують модифіковані алгоритми, наприклад “зростаючий нейронний газ”. Зміст цих алгоритмів полягає в послідовному збільшенні кількості кластерів до тих пір доки помилка розпізнавання не досягне наперед заданої величини. В класичному вигляді НМ Ліппмана-Хеммінга практично не застосовується, але вона є базовим компонентом інших архітектур НМ які можуть знайти своє застосування в задачах ЗІ, наприклад НМ Кохонена. Необхідно зазначити, що НМ в основу яких покладена модель Ліппмана-Хеммінга багато чому еквівалентні добре вивченим методам статистичного аналізу головних компонент. Однак, НМ можливо використовувати вже під час збору статистичної інформації. Тобто межі кластерів можливо оперативно адаптувати до зміни вхідного потоку інформації. Крім того, така НМ має переваги в при нелінійнму характері задачі, коли явні рішення знайти не можливо.