

Классификация ЭВМ по принципу действия.
Электронная вычислительная машина, компьютер - комплекс технических средств, предназначенных для автоматической обработки информации в процессе решения вычислительных и информационных задач (6).
По принципу действия вычислительные машины делятся на три больших класса: аналоговые (АВМ), цифровые (ЦВМ) и гибридные (ГВМ).
Критерием деления вычислительных машин на эти три класса является форма представления информации, с которой они работают:
а - аналоговая; б - цифровая импульсная.
Цифровые вычислительные машины (ЦВМ) - вычислительные машины дискретного действия, работают с информацией, представленной в дискретной, а точнее, в цифровой форме.
Аналоговые вычислительные машины (АВМ) - вычислительные машины непрерывного действия, работают с информацией, представленной в непрерывной (аналоговой) форме, т.е. в виде непрерывного ряда значений какой-либо физической величины (чаще всего электрического напряжения).
Аналогичные вычислительные машины весьма просты и удобны в эксплуатации; программирование задач для решения на них, как правило, нетрудоемкое ;скорость решения задач изменяется по желанию оператора и может быть сделана сколь угодно большой (больше ,чем у ЦВМ), но точность решения задач очень низкая (относительная погрешность 2-5%).На АВМ наиболее эффективно решать математические задачи, содержащие дифференциальные уравнения, не требующие сложной логики.
Наиболее широкое применение получили ЦВМ с электрическим представлением дискретной информации - электронные цифровые вычислительные машины, обычно называемые просто электронными вычислительными машинами (ЭВМ), без упоминания об их цифровом характере.
Классификация ЭВМ по этапам создания
По этапам создания и используемой элементной базе ЭВМ условно делятся на поколения:
1-е поколение, 50-е гг.: ЭВМ на электронно-вакуумных лампах;
2-е поколение, 60-е гг.: ЭВМ на дискретных полупроводниковых приборах (транзисторах);
3-е поколение, 70-е гг.: ЭВМ на полупроводниковых интегральных микросхемах с малой и средней степенью интеграции (сотни, тысячи транзисторов в одном корпусе);
4-е поколение, 80-е гг.: ЭВМ на больших и сверхбольших интегральных схемах-микропроцессорах (десятки тысяч- миллионы транзисторов в одном кристалле);
5-е поколение, 90-е гг.: ЭВМ с многими десятками параллельно работающих микропроцессоров, позволяющих строить эффективные системы обработки знаний; ЭВМ на сверхсложных микропроцессорах с параллельно-векторной структурой, одновременно выполняющих десятки последовательных команд программы;
6-е и последующие поколения: оптоэлектронных ЭВМ с массовым параллелизмом и нейронной структурой - с распределенной сетью большого числа (десятки тысяч) несложных микропроцессоров, моделирующих архитектуру нейронных биологических систем.
Каждое следующие поколение ЭВМ имеет по сравнению с предшествующим существенно лучшие характеристики. Так, производительность ЭВМ и емкость всех запоминающих устройств увеличиваются, как правило, больше чем на порядок.
Классификация ЭВМ по назначению.
По назначению ЭВМ можно разделить на три группы: универсальные (общего назначения), проблемно-ориентированные и специализированные.
Универсальные ЭВМ предназначены для решения самых различных технических задач: экономических, математических, информационных и других задач, отличающихся сложностью алгоритмов и большим объемом обрабатываемых данных. Они широко используются в вычислительных центрах коллективного пользования и в других мощных вычислительных комплексах.
Характерными чертами универсальных ЭВМ являются:
высокая производительность;
разнообразие форм обрабатываемых данных: двоичных, десятичных, символьных, при большом диапазоне их изменения и высокой точности их представления;
обширная номенклатура выполняемых операций, как арифметических, логических, так и специальных;
большая емкость оперативной памяти;
развитая организация системы ввода-вывода информации, обеспечивающая подключение разнообразных видов внешних устройств.
Проблемно-ориентированные ЭВМ служат для решения более узкого круга задач, связанных, как правило, с управлением технологическими объектами; регистрацией, накоплением и обработкой относительно небольших объемов данных; выполнением расчетов по относительно несложным алгоритмам; они обладают ограниченными по сравнению с универсальными ЭВМ аппаратными и программными ресурсами.
К проблемно-ориентированным ЭВМ можно отнести, в частности, всевозможные управляющие вычислительные комплексы.
Специализированные ЭВМ используются для решения узкого крута задач или реализации строго определенной группы функций. Такая узкая ориентация ЭВМ позволяет четко специализировать их структуру, существенно снизить их сложность и стоимость при сохранении высокой производительности и надежности их работы.
К специализированным ЭВМ можно отнести, например, программируемые микропроцессоры специального назначения; адаптеры и контроллеры, выполняющие логические функции управления отдельными несложными техническими устройствами, агрегатами и процессами, устройства согласования и сопряжения работы узлов вычислительных систем.
Классификация ЭВМ по размерам и функциональным возможностям.
По размерам и функциональным возможностям ЭВМ можно разделить на сверхбольшие (суперЭВМ), большие, малые, сверхмалые (микроЭВМ).Функциональные возможности ЭВМ обуславливают важнейшие технико-эксплуатационные характеристики:
быстродействие, измеряемое усредненным количеством операций, выполняемых машиной за единицу времени;
разрядность и формы представления чисел, с которыми оперирует ЭВМ;
номенклатура, емкость и быстродействие всех запоминающих устройств;
номенклатура и технико-экономические характеристики внешних устройств хранения, обмена и ввода-вывода информации;
типы и пропускная способность устройств связи и сопряжения узлов ЭВМ между собой (внутримашинного интерфейса);
способность ЭВМ одновременно работать с несколькими пользователями и выполнять одновременно несколько программ (многопрограммность);
типы и технико-эксплуатационные характеристики операционных систем, используемых в машине;
наличие и функциональные возможности программного обеспечения;
способность выполнять программы, написанные для других типов ЭВМ (программная совместимость с другими типами ЭВМ);
система и структура машинных команд;
возможность подключения к каналам связи и к вычислительной сети;
эксплуатационная надежность ЭВМ;
коэффициент полезного использования ЭВМ во времени, определяемый соотношением времени полезной работы и времени профилактики.
Тенденции развития вычислительных систем.
Параметр |
Этапы развития компьютеров |
||||
50-е гг. |
60-е гг. |
70-е гг. |
80-е гг. |
90-е гг. |
|
Цель использования ЭВМ (преимуществен- но) |
Научно-технические расчеты |
Технические и экономические расчеты |
Управление и экономические расчеты |
Управление; предоставление информации |
Телекоммуникации, информационное обслуживание и управление |
Режим работы ЭВМ |
Однопрограммный |
Пакетная обработка |
Разделение времени |
Персональная работа |
Сетевая обработка |
Интеграция данных |
Низкая |
Средняя |
Высокая |
Очень высокая |
Сверхвысокая |
Расположение пользователя |
Машинный зал |
Отдельное помещение |
Терминальный зал |
Рабочий стол |
Произвольное мобильное |
Тип пользователя |
Инженеры- программисты |
Профессиональные программисты |
Программисты- пользователи |
Пользователи с общей компьютерной подготовкой |
Слабообученные пользователи |
Тип диалога |
Работа за пультом ЭВМ |
Обмен перфоносителями и машинограммами |
Интерактивный (через клавиатуру и экран) |
Интерактивный по жесткому меню |
Интерактивный экранный типа "вопрос-ответ" |
Таблица 5.4. Совершенствование технологии использования компьютеров.
Главной тенденцией развития вычислительной техники в настоящее время является дальнейшее расширение сфер применения ЭВМ и, как следствие, переход от отдельных машин к их система - вычислительным системам и комплексам разнообразных конфигураций с широким диапазоном функциональных возможностей и характеристик.
Наиболее перспективные, создаваемые на основе персональных ЭВМ, территориально распределенные многомашинные вычислительные системы - вычислительные сети - ориентируются не столько на вычислительную обработку информации, сколько на коммуникационные информационные услуги: электронную почту, системы телеконференций и информационно справочные системы.
Уже сегодня пользователям глобальной вычислительной сети Internet стала доступной практически любая находящаяся в хранилищах знаний этой сети не конфиденциальная информация. Можно почитать или посмотреть, например, любую из нескольких сотен религиозных книг, рукописей, или картин в библиотеке Ватикана, оформленных в виде файлов, послушать музыку в Карнеги Холл, "заглянуть" в галереи Лувра или в кабинет президента США в Белом доме; пользователи этой суперсети могут получить для изучения интересующую их статью или подборку статей по нужной тематике, "опубликовать" в сети свою новую работу, обсудить ее с заинтересованными специалистами.
В сети Internet реализован принцип "гипертекста", согласно которому абонент, выбирая встречающиеся в читаемом тексте ключевые слова, может получить необходимые, дополнительные пояснения и материалы для углубления в изучаемую проблему. Используя этот принцип, абонент может прочитать электронную газету, персонифицированную на любую интересующую его тематику, с любой степенью подробности и достоверности Электронная почта Internet позволяет получить почтовое отправление из любой точки земного шара (где есть терминалы этой сети) через 5 с, а не через неделю или месяц, как это имеет место при использовании обычной почты.
В Массачусетском университете (США) создана электронная книга, куда можно записывать любую информацию из сети; читать эту книгу можно, отключившись от сети, автономно, в любом месте. Сама книга в твердом переплете, содержит тонкие жидкокристаллические индикаторы - страницы с бумагообразной синтетической поверхностью и высоким качеством "печати".
При разработке и создании собственно ЭВМ существенный и устойчивый приоритет в последние годы имеют сверхмощные компьютеры - суперЭВМ и миниатюрные, и сверхминиатюрные ПК. Ведутся, как уже указывалось, поисковые работы по созданию ЭВМ 6-го поколения, базирующихся на распределенной нейронной архитектуре, - нейрокомпьютеров. В частности, в нейрокомпьютерах могут использоваться уже имеющиеся специализированные сетевые МП - транспьютеры.
Транспьютер - микропроцессор сети со встроенными средствами связи.
Пример:Транспьютер IMS Т800 при тактовой частоте 30 МГц имеет быстродействие 15 млн. оп/с, а транспьютер Intel WARP при тактовой частоте 20 МГц - 20 млн. оп/с (оба транспьютера 32-разрядные).
Ближайшие прогнозы по созданию отдельных устройств ЭВМ:
микропроцессоры с быстродействием 1000 MIPS и встроенной памятью 16 Мбайт;
встроенные сетевые и видео интерфейсы;
плоские (толщиной 3 -5 мм) крупноформатные дисплеи с разрешающей способностью 1000х800 пикселей и более;
портативные, размером со спичечный коробок, магнитные диски емкостью, более 100 Гбайт. Терабайтные дисковые массивы на их основе сделают практически ненужным стирание старой информации.
Повсеместное использование мультиканальных широкополосных радио-, волоконно- оптических, а в пределах прямой видимости и инфракрасных каналов обмена информацией между компьютерами обеспечит практически неограниченную пропускную способность (трансфер до сотен миллионов байт в секунду).
Широкое внедрение средств мультимедиа, в первую очередь аудио- и видеосредств ввода и вывода информации, позволит общаться с компьютером на естественном языке. Мультимедиа нельзя трактовать узко, только как мультимедиа на ПК. Можно говорить о бытовом (домашнем) мультимедиа, включающем в себя и ПК, и целую группу потребительских устройств, доводящих потоки информации до потребителя и активно забирающих информацию у него.
Этому уже сейчас способствуют:
зарождающиеся технологии медиа-серверов, способных собирать и хранить огромнейшие объемы информации и выдавать ее в реальном времени по множеству одновременно приходящих запросов;
системы сверхскоростных широкополосных информационных магистралей, связывающие воедино все потребительские системы.
Названные ожидаемые технологии и характеристики устройств ЭВМ совместно с их общей миниатюризацией могут сделать всевозможные вычислительные средства и системы вездесущими (вспомните альтернативное название компьютера-блокнота: Omni Book), привычными, обыденными, естественно насыщающими нашу повседневную жизнь.
Специалисты [2] предсказывают в ближайшие годы возможность создания компьютерной модели реального мира, такой виртуальной (кажущейся, воображаемой) системы, в которой мы можем активно жить и манипулировать виртуальными предметами. Простейший прообраз такого кажущегося мира уже сейчас существует в сложных компьютерных играх. Но в будущем можно говорить не об играх, а о виртуальной реальности в нашей повседневной жизни, когда нас в комнате, например, будут окружать сотни активных компьютерных устройств, автоматически включающихся и выключающихся по мере надобности, активно отслеживающих наше местоположение, постоянно снабжающих нас ситуационно необходимой информацией, активно воспринимающих нашу информацию и управляющих многими бытовыми приборами и устройствами.
Информационная революция затронет все стороны жизнедеятельности, появятся системы, создающие виртуальную реальность:
компьютерные системы - при работе на ЭВМ с "дружественным интерфейсом" абоненты по видеоканалу будут видеть виртуального собеседника, активно общаться с ним на естественном речевом уровне с аудио- и видео разъяснениями, советами, подсказками. "Компьютерное одиночество", так вредно влияющее на психику активных пользователей ЭВМ, исчезнет;
системы автоматизированного обучения - при наличии обратной видеосвязи абонент будет общаться с персональным виртуальным учителем, учитывающим психологию, подготовленность, восприимчивость ученика;
торговля - любой товар будет сопровождаться не магнитным кодом, нанесенным на торговый ярлык, а активной компьютерной табличкой, дистанционно общающейся с потенциальным покупателем и сообщающей всю необходимую ему информацию - что, где, когда, как, сколько и почем.
Техническое обеспечение, необходимое для создания таких виртуальных систем:
дешевые, простые, портативные компьютеры со средствами мультимедиа;
программное обеспечение для ''вездесущих" приложений;
миниатюрные приемопередающие радиоустройства (трансиверы) для связи компьютеров друг с другом и с сетью;
распределенные широкополосные каналы связи и сети.
Многие предпосылки для создания указанных компонентов, да и простейшие их прообразы уже существуют.Но есть и проблемы. Важнейшая из них - обеспечение прав интеллектуальной собственности и конфиденциальности информации, чтобы личная жизнь каждого из нас не стала всеобщим достоянием.
Билет 2:
ОСНОВНЫЕ ПРИНЦИПЫ УСТРОЙСТВА ЭВМ БЫЛИ ПРЕДЛОЖЕНЫ ДЖОНОМ ФОН НЕЙМАНОМ - выдающимся американским математиком венгерского происхождения в 1945 году. В соответствии с ними в любой ЭВМ должны иметься четыре основных функциональных части. Взаимодействие между ними можно упрощенно изобразить в виде схемы:

На схеме двойные стрелки соответствуют движению данных (информация в ЭВМ называется данными). Человек вводит данные в компьютер через устройства ввода-вывода, эти данные могут храниться в устройствах хранения информации и обрабатываться в устройствах обработки информации. Полученные результаты также могут запоминаться в устройствах хранения информации и выдаваться человеку с помощью устройств ввода-вывода. Управляющие устройства управляют всем этим процессом, что изображено на схеме одинарными стрелками.
Так, в общих чертах, работают все ЭВМ, начиная с простейших калькуляторов и кончая суперкомпьютерами.
Функциональная организация:
Архитектура компьютера обычно определяется совокупностью ее свойств, существенных для пользователя. Основное внимание при этом уделяется структуре и функциональным возможностям машины, которые можно разделить на основные и дополнительные.
Основные функции определяют назначение ЭВМ: обработка и хранение информации, обмен информацией с внешними объектами. Дополнительные функции повышают эффективность выполнения основных функций: обеспечивают эффективные режимы ее работы, диалог с пользователем, высокую надежность и др. Названные функции ЭВМ реализуются с помощью ее компонентов: аппаратных и программных средств.
Микропроцессор (МП). Это центральный блок ПК, предназначенный для управление работой всех блоковмашины и для выполнения арифметических и логических операции над информацией.
В состав микропроцессора входят:
устройство управления (УУ) - формирует и подает во все блоки машины в нужные моменты времени определенные сигналы управления (управляющие импульсы), обусловленные спецификой выполняемой операции и результатами предыдущих операций; формирует адресаячеекпамяти, используемых выполняемой операцией, и передает эти адреса в соответствующие блоки ЭВМ; опорную последовательность импульсов устройство управления получает от генератора тактовых импульсов;
арифметико-логическое устройство (АЛУ) - предназначено длявыполнения всех арифметических и логических операций над числовой и символьной информацией (в некоторых моделях ПК для ускорения выполнения операций к АЛУ подключается дополнительныйматематический сопроцессор);
микропроцессорная память (МПП) - служит для кратковременного хранения, записи и выдачи информации, непосредственно используемой в вычислениях в ближайшие такты работы машины. МПП строится на регистрах и используется для обеспечения высокого быстродействия машины, ибо основная память (ОП) не всегда обеспечивает скорость записи, поиска и считывания информации, необходимую для эффективной работы быстродействующего микропроцессора. Регистры - быстродействующие ячейки памяти различной длины (в отличие от ячеек ОП, имеющих стандартную длину 1 байт и более низкое быстродействие);
интерфейсная система микропроцессора - реализует сопряжение и связь с другими устройствами ПК; включает в себя внутренний интерфейс МП, буферные запоминающие регистры и схемы управления портами ввода-вывода (ПВВ) и системной шиной. Интерфейс (interface) - совокупность средств сопряжения и связи устройств компьютера, обеспечивающая их эффективное взаимодействие. Порт ввода-вывода (I/O — Input/Output port) - аппаратура сопряжения, позволяющая подключить к микропроцессору другое устройство ПК.
Генератор тактовых импульсов. Он генерирует последовательность электрических импульсов; частота генерируемых импульсов определяет тактовую частоту машины. Промежуток времени между соседними импульсами определяет время одного такта работы машины или просто такт работы машины.
Частота генератора тактовых импульсов является одной из основных характеристик персонального компьютера и во многом определяет скорость его работы, ибо каждая операция в машине выполняется за определенное количество тактов.
Системная шина. Это основная интерфейсная система компьютера, обеспечивающая сопряжение и связь всех его устройств между собой.
Системная шина включает в себя:
кодовую шину данных (КШД), содержащую провода и схемы сопряжения для параллельной передачи всех разрядов числового кода (машинного слова) операнда;
кодовую шину адреса (КША), включающую провода и схемы сопряжения для параллельной передачи всех разрядов кода адреса ячейки основной памяти или порта ввода-вывода внешнего устройства;
кодовую шину инструкций (КШИ), содержащую провода и схемы сопряжения для передачи инструкций (управляющих сигналов, импульсов) во все блоки машины;
шину питания, имеющую провода и схемы сопряжения для подключения блоков ПК к системе энергопитания.
Системная шина обеспечивает три направления передачи информации:
1) между микропроцессором и основной памятью;
2) между микропроцессором и портами ввода-вывода внешних устройств;
3) между основной памятью и портами ввода-вывода внешних устройств (в режиме прямого доступа к памяти).
Все блоки, а точнее их порты ввода-вывода, через соответствующие унифицированные разъемы (стыки) подключаются к шине единообразно: непосредственно или через контроллеры (адаптеры). Управление системной шиной осуществляется микропроцессором либо непосредственно, либо, что чаще, через дополнительную микросхему - контроллер шины, формирующий основные сигналы управления. Обмен информацией между внешними устройствами и системной шиной выполняется с использованием ASCII-кодов.
Основная память (ОП). Она предназначена для хранения и оперативного обмена информацией с прочими блоками машины. ОП содержит два вида запоминающих устройств: постоянноезапоминающее устройство (ПЗУ) и оперативное запоминающее устройство (ОЗУ).
ПЗУ служит для хранения неизменяемой (постоянной) программной и справочной информации, позволяет оперативно только считывать хранящуюся в нем информацию (изменить информацию в ПЗУ нельзя).
ОЗУ предназначено для оперативной записи, хранения и считывания информации (программ и данных), непосредственно участвующей в информационно-вычислительном процессе, выполняемом ПК в текущий период времени. Главными достоинствами оперативной памяти являются ее высокое быстродействие и возможность обращения к каждой ячейке памяти отдельно (прямой адресный доступ к ячейке), В качестве недостатка ОЗУ следует отметить невозможность сохранения информации в ней после выключения питания машины (энергозависимость).
Внешняя память. Она относится к внешним устройствам ПК и используется для долговременного хранения любой информации, которая может когда-либо потребоваться для решения задач. В частности, во внешней памяти хранится все программное обеспечение компьютера. Внешняя память содержит разнообразные виды запоминающих устройств, но наиболее распространенными, имеющимися практически на любом компьютере, являются накопители на жестких (НЖМД) и гибких (НГМД) магнитных дисках.
Назначение этих накопителей - хранение больших объемов информации, запись и выдача хранимой информации по запросу в оперативное запоминающее устройство. Различаются НЖМД и НГМД лишь конструктивно, объемами хранимой информации и временем поиска, записи и считывания информации.
В качестве устройств внешней памяти используются также запоминающие устройства на кассетной магнитной ленте (стримеры), накопители на оптических дисках (CD-ROM - Compact Disk Read Only Memory - компакт-диск с памятью, только читаемой) и др. (см. подразд. 4.4).
Источник питания. Это блок, содержащий системы автономного и сетевого энергопитания ПК.
Таймер. Это внутримашинные электронные часы, обеспечивающие при необходимости автоматический съем текущего момента времени (год, месяц, часы, минуты, секунды и доли секунд). Таймер подключается к автономному источнику питания - аккумулятору и при отключении машины от сети продолжает работать.
Внешние устройства (ВУ). Это важнейшая составная часть любого вычислительного комплекса. Достаточно сказать, что по стоимости ВУ иногда составляют 50 - 80% всего ПК, От состава и характеристик ВУ во многом зависят возможность и эффективность применения ПК в системах управления и в народном хозяйстве в целом.
ВУ ПК обеспечивают взаимодействие машины с окружающей средой; пользователями, объектами управления и другими ЭВМ. ВУ весьма разнообразны и могут быть классифицированы по ряду признаков. Так, по назначению можно выделить следующие виды ВУ:
внешние запоминающие устройства (ВЗУ) или внешняя память ПК;
диалоговые средства пользователя;
устройства ввода информации;
устройства вывода информации;
средства связи и телекоммуникации.
Диалоговые средства пользователя включают в свой состав видеомониторы (дисплеи), реже пультовые пишущие машинки (принтеры с клавиатурой) и устройства речевого ввода-вывода информации.
Видеомонитор (дисплей) - устройство для отображения вводимой и выводимой из ПК информации (см подразд. 4.5).
Устройства речевого ввода-вывода относятся к быстроразвивающимся средствам мультимедиа. Устройства речевого ввода - это различные микрофонные акустические системы, "звуковые мыши", например, со сложным программным обеспечением, позволяющим распознавать произносимые человеком буквы и слова, идентифицировать их и закодировать.
Устройства речевого вывода - это различные синтезаторы звука, выполняющие преобразование цифровых кодов в буквы и слова, воспроизводимые через громкоговорители (динамики) или звуковые колонки, подсоединенные к компьютеру.
К устройствам ввода информации относятся:
клавиатура - устройство для ручного ввода числовой, текстовой и управляющей информации в ПК (см. подразд. 4.5);
графические планшеты (диджитайзеры) - для ручного ввода графической информации, изображений путем перемещения по планшету специального указателя (пера); при перемещении пера автоматически выполняются считывание координат его местоположения и ввод этих координат в ПК;
сканеры (читающие автоматы) - для автоматического считывания с бумажных носителей и ввода в ПК машинописных текстов, графиков, рисунков, чертежей; в устройстве кодирования сканера в текстовом режиме считанные символы после сравнения с эталонными контурами специальными программами преобразуются в коды ASCII, а в графическом режиме считанные графики и чертежи преобразуются в последовательности двухмерных координат (см. подразд. 4.5);
манипуляторы (устройства указания): джойстик - рычаг, мышь, трекбол - шар в оправе, световое перо и др. - для ввода графической информации на экран дисплея путем управления движением курсора по экрану с последующим кодированием координат курсора и вводом их в ПК;
сенсорные экраны - для ввода отдельных элементов изображения, программ или команд с полиэкрана дисплея в ПК.
К устройствам вывода информации относятся:
принтеры - печатающие устройства для регистрации информации на бумажный носитель (см. подразд. 4.5);
графопостроители (плоттеры) - для вывода графической информации (графиков, чертежей, рисунков) из ПК на бумажный носитель; плоттеры бывают векторные с вычерчиванием изображения с помощью пера и растровые: термографические, электростатические, струйные и лазерные. По конструкции плоттеры подразделяются на планшетные и барабанные. Основные характеристики всех плоттеров примерно одинаковые: скорость вычерчивания - 100 - 1000 мм/с, у лучших моделей возможны цветное изображение и передача полутонов; наибольшая разрешающая способность и четкость изображения у лазерных плоттеров, но они самые дорогие.
Устройства связи и телекоммуникации используются для связи с приборами и другими средствами автоматизации (согласователи интерфейсов, адаптеры, цифро-аналоговые и аналого-цифровые преобразователи и т.п.) и для подключения ПК к каналам связи, к другим ЭВМ и вычислительным сетям (сетевые интерфейсные платы, "стыки", мультиплексоры передачи данных, модемы).
В частности, показанный на рис. 4.2 сетевой адаптер является внешним интерфейсом ПК и служит для подключения его к каналу связи для обмена информацией с другими ЭВМ, для работы в составе вычислительной сети. В глобальных сетях функции сетевого адаптера выполняет модулятор-демодулятор (модем, см. гл. 7).
Многие из названных выше устройств относятся к условно выделенной группе - средствам мультимедиа.
Средства мультимедиа (multimedia - многосредовость) - это комплекс аппаратных и программных средств, позволяющих человеку общаться с компьютером, используя самые разные, естественные для себя среды: звук, видео, графику, тексты, анимацию и др.
К средствам мультимедиа относятся устройства речевого ввода и вывода информации; широко распространенные уже сейчас сканеры (поскольку они позволяют автоматически вводить в компьютер печатные тексты и рисунки); высококачественные видео- (video-) и звуковые (sound-) платы, платы видеозахвата (videograbber), снимающие изображение с видеомагнитофона или видеокамеры и вводящие его в ПК; высококачественные акустические и видеовоспроизводящие системы с усилителями, звуковыми колонками, большими видеоэкранами. Но, пожалуй, еще с большим основанием к средствам мультимедиа относят внешние запоминающие устройства большой емкости на оптических дисках, часто используемые для записи звуковой и видеоинформации.
Стоимость компактных дисков (CD) при их массовом тиражировании невысокая, а учитывая их большую емкость (650 Мбайт, а новых типов - 1Гбайт и выше), высокие надежность и долговечность, стоимость хранения информации на CD для пользователя оказывается несравнимо меньшей, нежели на магнитных дисках. Это уже привело к тому, что большинство программных средств самого разного назначения поставляется на CD. На компакт-дисках за рубежом организуются обширные базы данных, целые библиотеки; на СD представлены словари, справочники, энциклопедии; обучающие и развивающие программы по общеобразовательным и специальным предметам.
CD широко используются, например, при изучении иностранных языков, правил дорожного движения, бухгалтерского учета, законодательства вообще и налогового законодательства в частности. И все это сопровождается текстами и рисунками, речевой информацией и мультипликацией, музыкой и видео. В чисто бытовом аспекте CD можно использовать для хранения аудио- и видеозаписей, т.е. использовать вместо плейерных аудиокассет и видеокассет. Следует упомянуть, конечно, и о большом количестве программ, компьютерных игр, хранимых на CD.
Таким образом, CD-ROM открывает доступ к огромным объемам разнообразной и по функциональному назначению, и по среде воспроизведения информации, записанной на компакт-дисках.
Дополнительные схемы. К системной шине и к МП ПК наряду с типовым внешними устройствами могут быть подключены и некоторые дополнительные платы с интегральными микросхемами, расширяющие и улучшающие функциональные возможности микропроцессора: математический сопроцессор, контроллер прямого доступа к памяти, сопроцессор ввода-вывода, контроллер прерываний и др.
Математический сопроцессор широко используется для ускоренного выполнения операций над двоичными числами с плавающей запятой, над двоично-кодированными десятичными числами, для вычисления некоторых трансцендентных, в том числе тригонометрических, функций. Математический сопроцессор имеет свою систему команд и работает параллельно (совмещенно во времени) с основным МП, но под управлением последнего. Ускорение операций происходит в десятки раз. Последние модели МП, начиная с МП 80486 DX, включают сопроцессор в свою структуру.
Контроллер прямого доступа к памяти освобождает МП от прямого управления накопителями на магнитных дисках, что существенно повышает эффективное быстродействие ПК. Без этого контроллера обмен данными между ВЗУ и ОЗУ осуществляется через регистр МП, а при его наличии данные непосредственно передаются между ВЗУ и ОЗУ, минуя МП.
Сопроцессор ввода-вывода за счет параллельной работы с МП значительно ускоряет выполнение процедур ввода-вывода при обслуживании нескольких внешних устройств (дисплей, принтер, НЖМД, НГМД и др.); освобождает МП от обработки процедур ввода-вывода, в том числе реализует и режим прямого доступа к памяти.
Важнейшую роль играет в ПК контроллер прерываний.
Прерывание - временный останов выполнения одной программы в целях оперативного выполнения другой, в данный момент более важной (приоритетной) программы.
Прерывания возникают при работе компьютера постоянно [4]. Достаточно сказать, что все процедуры ввода-вывода информации выполняются по прерываниям, например, прерывания от таймера возникают и обслуживаются контроллером прерываний 18 раз в секунду (естественно, пользователь их не замечает).
Контроллер прерываний обслуживает процедуры прерывания, принимает запрос на прерывание от внешних устройств, определяет уровень приоритета этого запроса и выдает сигнал прерывания в МП. МП, получив этот сигнал, приостанавливает выполнение текущей программы и переходит к выполнению специальной программы обслуживания того прерывания, которое запросило внешнее устройство. После завершения программы обслуживания восстанавливается выполнение прерванной программы. Контроллер прерываний является программируемым.
ФУНКЦИОНАЛЬНЫЕ ХАРАКТЕРИСТИКИ ПК
Основными характеристиками ПК являются:
1. Быстродействие, производительность, тактовая частота.
Оценка производительности ЭВМ всегда приблизительная, ибо при этом ориентируются на некоторые усредненные или, наоборот, на конкретные виды операций. Реально при решении различных задач используются и различные наборы операций. Поэтому для характеристики ПК вместо производительности обычно указывают тактовую частоту, более объективно определяющую быстродействие машины, так как каждая операция требует для своего выполнения вполне определенного количества тактов. Зная тактовую частоту, можно достаточно точно определить время выполнения любой машинной операции.
2. Разрядность машины и кодовых шин интерфейса.
Разрядность — это максимальное количество разрядов двоичного числа, над которым одновременно может выполняться машинная операция, в том числе и операция передачи информации; чем больше разрядность, тем, при прочих равных условиях, будет больше и производительность ПК.
3. Типы системного и локальных интерфейсов.
Разные типы интерфейсов обеспечивают разные скорости передачи информации между узлами машины, позволяют подключать разное количество внешних устройств и различные их виды.
4. Емкость оперативной памяти.
Емкость оперативной памяти измеряется чаще всего в мегабайтах (Мбайт), реже в килобайтах (Кбайт). Напоминаем: 1 Мбайт = 1024 Кбайта = 10242 байт.
Многие современные прикладные программы при оперативной памяти емкостью меньше 8 Мбайт просто не работают либо работают, но очень медленно.
Следует иметь в виду, что увеличение емкости основной памяти в 2 раза, помимо всего прочего, дает повышение эффективной производительности ЭВМ при решении сложных задач примерно в 1,7 раза.
5. Емкость накопителя на жестких магнитных дисках (винчестера). Емкость винчестера измеряется обычно в мегабайтах или гигабайтах (1 Гбайт = 1024 Мбайта).
По прогнозам специалистов, многие программные продукты 1997 г. будут требовать для работы до 1 Гбайта внешней памяти.
6. Тип и емкость накопителей на гибких магнитных дисках.
Сейчас применяются в основном накопители на гибких магнитных дисках, использующие дискеты диаметром 3,5 и 5,25 дюйма (1 дюйм = 25,4 мм). Первые имеют стандартную емкость 1,44 Мбайта, вторые - 1,2 Мбайта.
7. Виды и емкость КЭШ-памяти.
КЭШ-память - это буферная, не доступная для пользователя быстродействующая память, автоматически используемая компьютером для ускорения операций с информацией, хранящейся в более медленно действующих запоминающих устройствах. Например, для ускорения операций с основной памятью организуется регистровая КЭШ-память внутри микропроцессора (КЭШ-память первого уровня) или вне микропроцессора на материнской плате (КЭШ-память второго уровня); для ускорения операций с дисковой памятью организуется КЭШ-память на ячейках электронной памяти.
Следует иметь в виду, что наличие КЭШ-памяти емкостью 256 Кбайт увеличивает производительность ПК примерно на 20%.
8. Тип видеомонитора (дисплея) и видеоадаптера.
9. Тип принтера.
10. Наличие математического сопроцессора.
Математический сопроцессор позволяет в десятки раз ускорить выполнениеопераций над двоичными числами с плавающей запятой и над двоично-кодированными десятичными числами.
11. Имеющееся программное обеспечение и вид операционной системы (см. гл. 8 - 12).
12. Аппаратная и программная совместимость с другими типами ЭВМ.
Аппаратная и программная совместимость с другими типами ЭВМ означает возможность использования на компьютере соответственнотех же технических элементов и программного обеспечения, что и на других типах машин.
13. Возможность работы в вычислительной сети (см. гл. 6).
14. Возможность работы в многозадачном режиме.
Многозадачный режим позволяет выполнять вычисления одновременно по нескольким программам (многопрограммный режим) или для нескольких пользователей (многопользовательский режим). Совмещение во времени работы нескольких устройств машины, возможное в такомрежиме, позволяет значительно увеличить эффективное быстродействие ЭВМ.
15. Надежность.
Надежность - это способность системы выполнять полностью и правильно все заданные ей функции. Надежность ПК измеряется обычно средним временем наработки на отказ.
16. Стоимость.
17. Габариты и масса.
Представление информации в ЭВМ:
Информация в ЭВМ кодируется, как правило, в двоичной или в двоично-десятичной системе счисления.Система счисления - это способ наименования и изображения чисел с помощью символов, имеющих определенные количественные значения.В зависимости от способа изображения чисел системы счисления делятся на позиционные и непозиционные.
В позиционной системе счисления количественное значение каждой цифры зависит от ее места (позиции) в числе. В непозиционной системе счисления цифры не меняют своего количественного значения при изменении их расположения в числе. Количество (Р) различных цифр, используемых для изображения числа в позиционной системе счисления, называется основанием системы счисления. Значения цифр лежат в пределах от 0 до Р-1. В общем случае запись любого смешанного числа в системе счисления с основанием Р будет представлять собой ряд вида:
am-1Pm-1+am-2Pm-2+...+a1P1+a0PO+a-1P-1+a-2P-2+...+a-sP-s, (1)
где нижние индексы определяют местоположение цифры в числе (разряд):
положительные значения индексов - для целой части числа (m разрядов);
отрицательные значения - для дробной (s разрядов).
Пример 4.1. Позиционная система счисления - арабская десятичная система, в которой:основание P=10, для изображения чисел используются 10 цифр (от 0 до 9). Непозиционная система счисления - римская, в которой для каждого числа используется специфическое сочетание символов (XIV, CXXVII и т.п.).
Двоичная система счисления имеет основание Р=2 и использует для представления информации всего две цифры: 0 и 1. Существуют правила перевода чисел из одной системы счисления в другую, основанные в том числе и на соотношении (1).
Пример 4.2.
101110,101(2) =1*25+0*24+1*23+l*22+1*21+0*20+l*2-1+0*2-2+l*2-3=46,625(10) ,
т.е. двоичное число 101110,101 равно десятичному числу 46,625.
В вычислительных машинах применяются две формы представления двоичных чисел:
естественная форма или форма с фиксированной запятой (точкой);
нормальная форма или форма с плавающей запятой (точкой).
С фиксированной запятой все числа изображаются в виде последовательности цифр с постоянным для всех чисел положением запятой, отделяющей целую часть от дробной.
Пример 4.3. В десятичной системе счисления имеются 5 разрядов в целой части числа (до запятой) и 5 разрядов в дробной части числа (после запятой); числа, записанные в такую разрядную сетку, имеют вид:
+00721,35500; +00000,00328; -10301,20260.
Эта форма наиболее проста, естественна, но имеет небольшой диапазон представления чисел и поэтому не всегда приемлема при вычислениях.
С плавающей запятой каждое число изображается в виде двух групп цифр. Первая группа цифр называется мантиссой, вторая- порядком, причем абсолютная величина мантиссы должна быть меньше 1, а порядок - целым числом. В общем виде число в форме с плавающей запятой может быть представлено так:
N=±MP±r,
где М-мантисса числа (|М| < 1);
r- порядок числа (r- целое число);
Р- основание системы счисления.
Пример 4.5. Приведенные в примере 4.3 числа в нормальной форме запишутся так:
+0,721355*103; +0,328* 10-3; -0,103012026*105.
Нормальная форма представления имеет огромный диапазон отображения чисел и является основной в современных ЭВМ.
Примечание. Для алгебраического представления чисел (т.е. для представления положительных и отрицательных чисел) в машинах используются специальные коды: прямой, обратный и дополнительный. Причем два последних позволяют заменить неудобную для ЭВМ операцию вычитания на операцию сложения с отрицательным числом, дополнительный код обеспечивает более быстрое выполнение операций, поэтому в ЭВМ применяется чаще именно он.
Двоично-десятичная система счисления получила большое распространение в современных ЭВМ ввиду легкости перевода в десятичную систему и обратно. Она используется там, где основное внимание уделяется не простоте технического построения машины, а удобству работы пользователя. В этой системе счисления все десятичные цифры отдельно кодируются четырьмя двоичными цифрами (табл. 4.1) и в таком виде записываются последовательно друг за другом.
Пример 4.7. Десятичное число 9703 в двоично-десятичной системе выглядит так:
1001011100000011.
При программировании иногда используется шестнадцатеричная система счисления, перевод чисел из которой в двоичную систему счисления весьма прост - выполняется поразрядно (полностью аналогично переводу из двоично-десятичной системы).
Для изображения цифр, больших 9, в шестнадцатеричной системе счисления применяются буквы А=10, В=11, С=12, D=13, Е=14, F=15.
Пример 4.8. Шестнадцатеричное число F17B в двоичной системе выглядит так:
1111000101111011.
Билет 3:
Представление команд:
Проектирование системы команд оказывает влияние на структуру ЭВМ. Оптимальную систему команд иногда определяют как совокупность команд, которая удовлетворяет требованиям проблемно-ориентированных применений таким образом, что избыточность аппаратных и аппаратно-программных средств на реализацию редко используемых команд оказывается минимальной. В различных программах ЭВМ частота появления команд различна; например, по данным фирмы DEC в программах для ЭВМ семейства PDP-11 наиболее часто встречается команда передачи MOV(B), на ее долю приходится приблизительно 32% всех команд в типичных программах. Систему команд следует выбирать таким образом, чтобы затраты на редко используемые команды были минимальными.
При наличии статистических данных можно разработать (выбрать) ЭВМ с эффективной системой команд. Одним из подходов к достижению данной цели является разработка команд длиной в одно слово и кодирование их таким образом, чтобы разряды таких коротких команд использовать оптимально, что позволит сократить время реализации программы и ее длину.
Другим подходом к оптимизации системы команд является использование микроинструкций. В этом случае отдельные биты или группы бит команды используются для кодирования нескольких элементарных операций, которые выполняются в одном командном цикле. Эти элементарные операции не требуют обращения к памяти, а последовательность их реализации определяется аппаратной логикой.
Сокращение времени выполнения программ и емкости памяти достигается за счет увеличения сложности логики управления.
Важной характеристикой команды является ее формат, определяющий структурные элементы команды, каждый из которых интерпретируется определенные образом при ее выполнении. Среди таких элементов (полей) команды выделяют следующие: код операции, определяющий выполняемое действие; адрес ячейки памяти, регистра процессора, внешнего устройства; режим адресации; операнд при использовании непосредственной адресации; код анализируемых признаков для команд условного перехода.
Классификация команд по основным признакам представлена на рис. 2.4. Важнейшим структурным элементом формата любой команды является код операции (КОП), определяющей действие, которое должно быть выполнено. Большое число КОП в процессоре очень важно, так как аппаратная реализация команд экономит память и время. Но при выборе ЭВМ необходимо концентрировать внимание на полноте операций с конкретными типами данных, а не только на числе команд, на доступных режимах адресации. Число бит, отводимое под КОП, является функцией полного набора реализуемых команд.
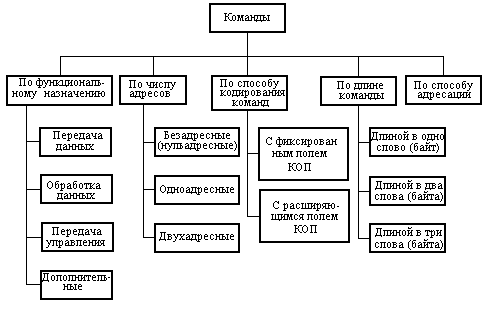
Рис. 2.4. Классификация команд.
При использовании фиксированного числа бит под КОП для кодирования всех m команд необходимо в поле КОП выделить двоичных разрядов. Однако, учитывая ограниченную длину слова мини- и микроЭВМ, различное функциональное назначение команд, источники и приемники результатов операций, а также то, что не все команды содержат адресную часть для обращения к памяти и периферийным устройствам, в малых ЭВМ для кодирования команд широко используется принцип кодирования с переменным числом бит под поле КОП для различных групп команд.
В некоторых командах необходим только один операнд и они называются однооперандными (или одноадресными) командами в отличие от двухоперандных (или двухадресных), в которых требуются два операнда. При наличии двух операндов командой обычно изменяется только один из них. Так как информация берется только из одной ячейки, эту ячейку называются источником; ячейка, содержимое которой изменяется, называется приемником.
Ниже приведен формат двухадресной (двухоперандной) команды процессоров СМ.
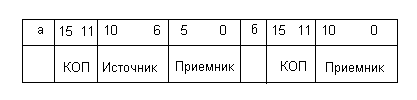
Формат команд процессоров СМ: а) двухадресная команда; б) одноадресная команда.
Примеры кодирования двухадресных команд в процессорах СМ
КОП |
Мнемоника команды |
Комментарий |
0001 0010 0110 1110 |
MOV CMP ADD SUB |
Передача данных Сравнение Сложение Вычитание |
0000 1000 |
- - |
Кодирование группы одноадресных команд |
Четырехбитный КОП (биты 15-12) кодирует ряд двухоперандных операций, приведенных в таблице 1. Биты (11-6) и (5-0) для команд данного типа определяют адреса источника и приемника данных. Как видно из таблицы, комбинации 0000 и 1000 поля КОП определяют группы одноадресных команд (рис 1,б). КОП 1 (биты 15-12), соответствующий кодам 0000 и 1000, определяет группу одноадресных команд, а КОП 2 (биты 11-6) кодирует конкретную операцию команд данной группы. Таким образом, команды, использующие один операнд, кодируются 10-битным КОП (биты 15-6).
Наиболее гибкая команда требует до четырех операндов. Например, команда сложения может указывать адреса слагаемых, адрес результата и адрес следующей команды. Если для задания адреса требуется 16 бит, то четырехоперандная команда займет 8 байт памяти, не учитывая код операции. Следовательно, получится медленнодействующая ЭВМ с огромной памятью. Поэтому в большинстве микроЭВМ любой команде требуется не более двух операндов. Это достигается следующими приемами: 1. Адрес следующей команды указывается только в командах переходов; в остальных случаях очередная команда выбирается из ячеек памяти, следующих за выполненной командой. 2. Использование ячейки, в которой находится один из операндов, для запоминания результата (например, сумма запоминается в ячейки первого операнда).
Локализацию и обращение к операндам обеспечивают режимы адресации. При введении нескольких режимов адресации необходимо отвести в команде биты, указывающие режимы адресации для каждого операнда. Если предусмотрено восемь режимов адресации, то для задания каждого из них нужно три бита.
Почти во всех форматах команд первые биты отводятся для кода операции, но далее форматы команд разных ЭВМ сильно отличаются друг от друга. Остальные биты должны определять операнды или их адреса, и поэтому они используются для комбинации режимов, адресов регистров, адресов памяти, относительных адресов и непосредственных операндов. Обычно длина команды варьируется от 1 до 3 и даже 6 байт.
СТРУКТУРА И ФОРМАТ КОМАНД. КОДИРОВАНИЕ КОМАНД.
Все возможные преобразования дискретной информации могут быть сведены к четырем основным видам:
1) передача информации в пространстиве;
2) хранение информации;
3) логические операции;
4) арифметические операции.
ЭВМ, являющаяся универсальным преобразователем дискретной информации, выполняет все указанные виды преобразований.
Обработка информации в ЭВМ осуществляется автоматически путем программного управления. Программа представляет собой алгоритм обработки информации, записанный в виде последовательности команд, которые должны быть выполнены машиной для получения решения задачи.
Команда представляет собой код, определяющий операцию вычислительной машины и данные, участвующие в операции. Команда содержит также в явной или неявной форме информацию об адресе, по которому помещается результат операции, и об адресе следующей команды.
Процесс выполнения программы состоит из отдельных машинных операций. В данном случае под операцией понимается преобразование информации, выполняемое машиной под воздействием одной команды. Содержанием машинной операции могут быть запоминание в памяти, передача, арифметическое или логическое преобразование машинных слов, а также некоторые вспомогательные процедуры.
По характеру выполняемых операций различают следующие основные группы команд:
1) команды арифметических операций для чисел с фиксированной и плавающей запятой;
2) команды десятичной арифметики;
3) команды логических операций;
4) команды передачи кодов;
5) команды ввода-вывода;
6) команды передачи управления;
7) команды задания режима работы машины.
В команде, как правило, содержатся не сами операнды, а информация об адресах ячеек памяти или регистрах, в которых они находятся.
Код команды можно представить состоящим из нескольких частей или полей, имеющих определенное функциональное назначение при кодировании командной информации. Команда в общем случае состоит из операционной и адресной частей. В свою очередь, эти части могут состоять из нескольких полей.
Операционная часть содержит код операции, который задает вид операции. Адресная часть команды содержит информацию об адресах операндов и результата операции, а в некоторых случаях информацию об адресе следующей команды.
Структура команды определяется составом, назначением и расположением полей в команде. Форматом команды называют ее структуру с разметкой номеров разрядов (бит), определяющих границы отдельных полей команды, или с указанием числа бит в определенных полях.
Способы адресации:
Режимы адресации Для взаимодействия с различными модулями в ЭВМ должны быть средства идентификации ячеек внешней памяти, ячеек внутренней памяти, регистров МП и регистров устройств ввода/вывода. Поэтому каждой из запоминающих ячеек присваивается адрес, т.е. однозначная комбинация бит. Количество бит определяет число идентифицируемых ячеек. Обычно ЭВМ имеет различные адресные пространства памяти и регистров МП, а иногда - отдельные адресные пространства регистров устройств ввода/вывода и внутренней памяти. Кроме того, память хранит как данные, так и команды. Поэтому для ЭВМ разработано множество способов обращения к памяти, называемых режимами адресации. Режим адресации памяти - это процедура или схема преобразования адресной информации об операнде в его исполнительный адрес. Все способы адресации памяти можно разделить на:
1) прямой, когда исполнительный адрес берется непосредственно из команды или вычисляется с использованием значения, указанного в команде, и содержимого какого-либо регистра (прямая адресация, регистровая, базовая, индексная и т.д.);
2) косвенный, который предполагает, что в команде содержится значение косвенного адреса, т.е. адреса ячейки памяти, в которой находится окончательный исполнительный адрес (косвенная адресация). В каждой микроЭВМ реализованы только некоторые режимы адресации, использование которых, как правило, определяется архитектурой МП.
И еще чуток:
СПОСОБЫ АДРЕСАЦИИ
Адресный код - это информация об адресе операнда, содержащаяся в команде. Исполнительный адрес - это номер ячейки памяти, к которой производится фактическое обращение. В современных ЭВМ адресный код, как правило, не совпадает с исполнительным адресом.
Выбор способов адресации, формирования исполнительного адреса и преобразования адресов является одним из важнейших вопросов разработки ЭВМ.
Рассмотрим способы адресации, используемые в современных ЭВМ:
1) Подразумеваемый операнд.
В команде может не содержаться явных указаний об операнде; в этом случае операнд подразумевается и фактически задается кодом операции команды.
2) Подразумеваемый адрес.
В команде может не содержаться явных указаний об адресе участвующего в операции операнда или адресе, по которому должен быть размещен результат операции, но этот адрес подразумевается.
3) Непосредственная адресация.
В команде содержится не адрес операнда, а непосредственно сам операнд. При непосредственной адресации не требуется обращения к памяти для выборки операнда и ячейки памяти для его хранения. Это способствует уменьшению времени выполнения программы и занимаемого ею объема памяти. Непосредственная адресация удобна для хранения различного рода констант.
4) Прямая адресация.
В адресной части команды может быть непосредственно указан исполнительный адрес.
5) Относительная (базовая) адресация.
При этом способе адресации исполнительный адрес определяется как сумма адресного кода команды и базового адреса, как правило хранящегося в специальном регистре - регистре базы.
Относительная адресация позволяет при меньшей длине адресного кода команды обеспечить доступ к любой ячейке памяти. Для этого число разрядов в базовом регистре выбирают таким, чтобы можно было адресовать любую ячейку оперативной памяти, а адресный код команды используют для представления лишь сравнительно короткого "смещения". Смещение определяет положение операнда относительно начала массива, задаваемого базовым адресом.
6) Укороченная адресация.
Для уменьшения длины кода команды часто применяется так называемая укороченная адресация. Суть ее сводится к тому, что в команде задаются только младшие разряды адресов, а старшие разряды при этом подразумеваются нулевыми. Такая адресация позволяет использовать только небольшую часть фиксированных ячеек в начале всей адресуемой области памяти, и поэтому применяется лишь совместно с другими способами адресации.
Регистровая адресация является частным случаем укороченной, когда в качестве фиксированных ячеек с короткими адресами используются регистры (ячейки сверхоперативной или местной памяти) процессора. Например, если таких регистров 16, то для адреса достаточно четырех двоичных разрядов. Регистровая адресация наряду с сокращением длины адресов операндов позволяет увеличить скорость выполнения операций, так как уменьшается число обрашений к оперативной памяти.
7) Косвенная адресация.
Адресный код команды в этом случае указывает адрес ячейки памяти, в которой находится адрес операнда или команды. Косвенная адресация широко используется в малых и микроЭВМ, имеющих короткое машинное слово, для преодоления ограничений короткого формата команды (совместно используются регистровая и косвенная адресация).
8) Адресация слов переменной длины.
Эффективность вычислительных систем, предназначенных для обработки данных, повышается, если имеется возможность выполнять операции со словами переменной длины. В этом случае в машине может быть предусмотрена адресация слов переменной длины, которая обычно реализуется путем указания в команде местоположения в памяти начала слова и его длины.
9) Стековая адресация.
Стековая память, реализующая безадресное задание операндов, особенно широко используется в микропроцессорах и миниЭВМ.
Стек представляет собой группу последовательно пронумерованных регистров или ячеек памяти, снабженных указателем стека, в котором автоматически при записи и считывании устанавливается номер (адрес) последней занятой ячейки стека (вершины стека). При операции записи заносимое в стек слово помещается в следующую по порядку свободную ячейку стека, а при считывании из стека извлекается последнее поступившее в него слово.
10) Автоинкрементная и автодекрементная адресаци.
Поскольку регистровая косвенная адресация требует предварительной загрузки регистра косвенным адресом из оперативной памяти, что связано с потерей времени, такой тип адресации особенно эффективен при обработке массива данных, если имеется механизм автоматического приращения или уменьшения содержимого регистра при каждом обращении к нему. Такой механизм называется соответственно автоинкрементной и автодекрементной адресацией. В этом случае достаточно один раз загрузить в регистр адрес первого обрабатываемого элемента массива, а затем при каждом обращении к регистру в нем будет формироваться адрес следующего элемента массива.
При автоинкрементной адресации сначала содержимое регистра используется как адрес операнда, а затем получает приращение, равное числу байт в элементе массива. При автодекрементной адресации сначала содержимое указанного в команде регистра уменьшается на число байт в элементе массива, а затем используется как адрес операнда.
Автоинкрементная и автодекрементная адресации могут рассматриваться как упращенный вариант индексации - весьма важного механизма преобразования адресных частей команд и организации вычислительных циклов, поэтому их часто называют автоиндексацией.
11) Индексация.
Для реализуемых на ЭВМ методов решения математических задач и обработки данных характерна цикличность вычислительных процессов, когда одни и те же процедуры выполняются над различными операндами, упорядоченно расположенными в памяти. Поскольку операнды, обрабатываемые при повторениях цикла, имеют разные адреса, без использования индексации требовалось бы для каждого повторения составлять свою последовательность команд, отличающихся адресными частями.
Программирование циклов существенно упрощается, если после каждого выполнения цикла обеспечено автоматическое изменение в соответствующих командах их адресных частей согласно расположению в памяти обрабатываемых операндов. Такой процесс называется модификацией команд, и основан на возможности выполнения над кодами команд арифметических и логических операций.
Управление вычислительным циклом должно обеспечивать повторение цикла нужное число раз, а затем выход из него.
Автоматическая модификация команд и управление вычислительными циклами в современных ЭВМ обеспечиваются механизмом индексации. Это понятие включает в себя специальный способ кодирования команд, командные и аппаратурные средства задания и выполнения модификации команд и управления вычислительными циклами. Упомянутые средства часто называют индексной арифметикой.
Для выполнения индексации в машину вводятся так называемые индексные регистры. Исполнительный адрес при индексации формируется путем сложения адресного кода команды (смещения) с содержимым индексного регистра (индексом), а при наличии базирования - и с базовым адресом.
Для управления индексацией используются команды, задающие операции над содержимым индексных регистров - команды индексной арифметики. Можно отметить основные виды индексных операций:
- засылка в соответствующий индексный регистр начального значения индекса;
- изменение индекса;
- проверка окончания циклических вычислений.
Билет 7:
Структура компьютера - это некоторая модель, устанавливающая состав, порядок и принципы взаимодействия входящих в нее компонентов.
Персональный компьютер - это настольная или переносная ЭВМ, удовлетворяющая требованиям общедоступности и универсальности применения.
Достоинствами ПК являются:
малая стоимость, находящаяся в пределах доступности для индивидуального покупателя;
автономность эксплуатации без специальных требований к условиям окружающей среды;
гибкость архитектуры, обеспечивающая ее адаптивность к разнообразным применениям в сфере управления, науки, образования, в быту;
"дружественность" операционной системы и прочего программного обеспечения, обусловливающая возможность работы с ней пользователя без специальной профессиональной подготовки;
высокая надежность работы (более 5 тыс. ч наработки на отказ).
Рассмотрим состав и назначение основных блоков ПК (рис. 4.2).
Примечание. Здесь и далее организация ПК рассматривается применительно к самымраспространенным в настоящее время IBM PC – подобным компьютерам (см. гл. 5)

ВНУТРИМАШИННЫЙ СИСТЕМНЫЙ ИНТЕРФЕЙС
Характеристика внутримашинного системного интерфейса
Внутримашинный системный интерфейс - система связи и сопряжения узлов и блоков ЭВМ между собой - представляет собой совокупность электрических линий связи (проводов), схем сопряжения с компонентами компьютера, протоколов (алгоритмов) передачи и преобразования сигналов.
Существуют два варианта организации внутримашинного интерфейса.
1. Многосвязный интерфейс: каждый блок ПК связан с прочими блоками своими локальными проводами; многосвязный интерфейс применяется, как правило, только в простейших бытовых ПК.
2. Односвязный интерфейс: все блоки ПК связаны друг с другом через общую или системную шину.
В подавляющем большинстве современных ПК в качестве системного интерфейса используется системная шина. Структура и состав системной шины были рассмотрены ранее. Важнейшими функциональными характеристиками системной шины являются: количество обслуживаемых ею устройств и ее пропускная способность, т.е. максимально возможная скорость передачи информации. Пропускная способность шинызависит от ее разрядности (есть шины 8-, 16-, 32- и 64-разрядные) и тактовой частоты, на которой шина работает.
В качестве системной шины в разных ПК использовались и могут использоваться:
шины расширений - шины общего назначения, позволяющие подключать большое число самых разнообразных устройств,
локальные шины, специализирующиеся на обслуживании небольшого количества устройств определенного класса.
Шины расширений
Шина Multibus1 имеет две модификации: PC/XT bus (Persona) Computer eXtended Technology - ПК с расширенной технологией) и PC/AT bus (PC Advanced Technology - ПК с усовершенствованной технологией).
Шина PC/XT bus - 8-разрядная шина данных и 20-разрядная шина адреса, рассчитанная на тактовую частоту 4,77 МГц; имеет 4 линии для аппаратных прерываний и 4 канала для прямого доступа в память (каналы DMA - Direct Memory Access). Шина адреса ограничивала адресное пространство микропроцессора величиной 1 Мбайт. Используется с МП 8086,8088.
Шина PC/AT bus -16-разрядная шина данных и 24-разрядная шина адреса, рабочая тактовая частота до 8 МГц, но может использоваться и МП с тактовой частотой 16 МГц, так как контроллер шины может делить частоту пополам; имеет 7 линий для аппаратных прерываний и 4 канала DMA. Используется с МП 80286.
Шине ISA (Industry Standard Architecture - архитектура промышленного стандарта) - 16-разрядная шина данных и 24-разрядная шина адреса, рабочая тактовая частота 8 МГц, но может использоваться и МП с тактовой частотой 50 МГц (коэффициент деления увеличен); по сравнению с шинами PC/XT и PC/AT увеличено количество линий аппаратных прерываний с 7 до 15 и каналов прямого доступа к памяти DMA с 7 до 11. Благодаря 24-разрядной шине адреса адресное пространство увеличилось с 1 до 16 Мбайт. Теоретическая пропускная способность шины данных равна 16 Мбайт/с, но реально она ниже, около 4-5 Мбайт/с, ввиду ряда особенностей ее использования. С появлением 32-разрядных высокоскоростных МП шина ISA стала существенным препятствием увеличения быстродействия ПК.
Шина EISA (Extended ISA) - 32-разрядная шина данных и 32-разрядная шина адреса, создана в 1989 г. Адресное пространство шины 4 Гбайта, пропускная способность 33 Мбайт/с, причем скорость обмена по каналу МП - КЭШ - ОП определяется параметрами микросхем памяти, увеличено число разъемов расширений (теоретически может подключаться до 15 устройств, практически - до 10). Улучшена система прерываний, шина EISA обеспечивает автоматическое конфигурирование системы и управление DMA; полностью совместима с шиной ISA (есть разъем для подключения ISA), шина поддерживает многопроцессорную архитектуру вычислительных систем. Шина EISA весьма дорогая и применяется в скоростных ПК. сетевых серверах и рабочих станциях.
Шина МСА (Micro Channel Architecture) -32-разрядная шина, созданная фирмой IBM в 1987 г. для машин PS/2, пропускная способность 76 Мбайт/с, рабочая частота 10-20 МГц. По своим прочим характеристикам близка к шине EISA, но не совместима ни с ISA, ни с EISA. Поскольку ЭВМ PS/2 не получили широкого распространения, в первую очередь ввиду отсутствия наработанного обилия прикладных программ, шина МСА также используется не очень широко.
Локальные шины
Современные вычислительные системы характеризуются:
стремительным ростом быстродействия микропроцессоров (например, МП Pentium может выдавать данные со скоростью 528 Мбайт/с по 64-разрядной шине данных) и некоторых внешних устройств (так, для отображения цифрового полноэкранного видео с высоким качеством необходима пропускная способность 22 Мбайт/с);
появлением программ, требующих выполнения большого количества интерфейсных операций (например, появлением программ, требующих выполнения большого количества интерфейсных операций (например, программы обработки графики в Windows, работа в среде Multimedia).
В этих условиях пропускной способности шин расширения, обслуживающих одновременно несколько устройств, оказалось недостаточно для комфортной работы пользователей, ибо компьютеры стали подолгу "задумываться".
Разработчики интерфейсов пошли по пути создания локальных шин, подключаемых непосредственно к шине МП, работающих на тактовой частоте МП (но не на внутренней рабочей его частоте) и обеспечивающих связь с некоторыми скоростными внешними по отношению к МП устройствами: основной и внешней памятью, видеосистемами и др. Сейчас существуют два основных стандарта универсальных локальных шин: VLB и PCI
Билет 8:
Основная задача системы реального масштаба времени (RT) - получение правильных результатов за определенный крайний срок. Следовательно, вычислительная правильность системы зависит от двух составляющих: логической правильности результатов, и правильности выбора времени, то есть способности выполнения вычислений за крайние сроки.
О жестких системах реального масштабе времени (HRT) можно думать как о специфическом подклассе RT систем, в котором неспособность удовлетворять вышеупомянутым крайним срокам может окончиться катастрофическим отказом системы. В дальнейшем мы будем использовать фразу "мягкая система реального масштаба времени (SRTT)" для определения тех RT систем, в которых способность встречать крайние сроки действительно требуется; однако, отказ выполнения не приводит к отказу системы.
Для проектов HRT и SRT систем могут встретиться такие сложности, как выбор времени применения и требования к ресурсам, и пригодность ресурсов системы. В частности в проекте HRT системы, которая поддерживает критические процессы ( например система управления полетами, система управления атомной электростанции, железнодорожные системы управления ), эта сложность может быть усилена такими противоречивыми прикладными требованиями, как требованием на высоко надежные и высоко доступные услуги, и потребностью обеспечить эти услуги при удовлетворении строгих ограничений выбора времени.
В частности, поскольку HRT система должна обеспечить услуги, которые, должны быть и своевременными и высоко доступными, проект любой такой системы требует, чтобы соответствующие методы разрешения ошибок, способные к встрече с жесткими требованиями в реальном масштабе времени, были развернуты в пределах этой системы.
Текущая технология позволяет проектировщику системы HRT осуществлять рентабельные методы разрешения ошибок, основанные на использовании избыточных компонентов системы. Однако, развитию политики управления избыточности, которая выполняет требования в реальном масштабе времени, может препятствовать дальнейшее усложнение проекта системы. Таким образом, в сущности, проект HRT системы нуждается в тщательной оценке требований выполнения / надежности. И HRT и SRT системы могут быть построены из географически рассеянных ресурсов, связанных некоторой сетью, чтобы формировать распределенную RT систему.(распределенные HRT системы могут классифицироваться как отзывчивые системы, то есть распределеные, ошибко- устойчивые,в реальном масштабе времени [8, 29, 36])
В этом руководстве, мы сосредоточимся на проблемах выполнения распределенных RT систем, и опишем пять эксплуатационных примеров этих систем, а именно [52, 17, 33, 56, 47]. В частности мы обсудим ключевые парадигмы для разработки своевременных и доступ ных RT услуг системы, и исследуем методы планирования процесса, управления временем, и взаимодействия по локальным и глобальным сетям.
Это руководство структурировано следующим образом. В последующей секции, мы обсуждаем основные проблемы, возникающие при проектировании RT систем. В секции 3, мы исследуем возможные политики планирования, которые обычно развертывается в этих системах. Секция 4 рассказывает о распределенных RTOS, упомянутых выше. Наконец, Секция 5 предлагает некоторые замечания и выводы.

Любая система реального масштаба времени может быть описана как состоящая из трех основных подсистем [23], как изображено на рисунке 1.
Управляемая подсистема (например индустриальный завод, управляемое компьютером транспортное средство), диктует требования в реальном масштабе времени; подсистема контроля управляет некоторыми вычислениями и связью с оборудованием для использования от управляемой подсистемы; подсистема оператора контролирует полную деятельность системы. Интерфейс между управляемыми и подсистемами контроля состоит из таких устройств как датчики и приводы. Интерфейс между управляющей подсистемой, и оператором связывает человека с машинной.
Управляемая подсистема представлена задачами (в дальнейшем называемыми прикладными задачами) которые используют оборудование, управляемое подсистемой контроля. Эта последняя подсистема может быть построена из очень большого количества процессоров, управляющими такими местными ресурсами, как память и устройства хранения, и доступ к локальной сети в реальном масштабе времени (то есть локальная сеть, которая обеспечивает ограничение на максимальную задержку обмена сообщениями - смотри подраздел 2.4). Эти процессоры и ресурсы управляются системой программного обеспечения, так мы называем операционную систему реального масштаба времени (RTOS).
Развертывание RTOS в критической окружающей среде (например, руководство и навигационные системы) налагает серьезные требования надежности на проект и функционирование этих RTOS [10]. Как обсуждается в [26], эти требования могут быть определены из соображений максимальной приемлемой вероятности отказа системы. Таким образом, например, системы управления полетом, типа используемого в Аэробусе A-320, требуют вероятности отказа в полете 10^(-10) за час. В системах управления транспортными средствами, в которых стоимость отказа может быть определенный количество в терминах экономического штрафа (например системы для спутникового руководства, беспилотные подводные навигационные системы), требуют вероятности отказа порядка 10^(-6) - 10^(-7) в час.
Методы разрешения ошибок, основанные на управлении избыточными аппаратными средствами ЭВМ и компонентов системы программного обеспечения, обычно используются, чтобы выполнить эти требования надежности. Однако, выполнение этих методов, действительно оп ределяющих надежность системы, требуют, чтобы частью ресурсов системы были отданы для обеспечения надежности.
Билет 9:
РЕГИСТРОВАЯ КЭШ-ПАМЯТЬ
Регистровая КЭШ-память - высокоскоростная память сравнительно большой емкости, являющаяся буфером между ОП и МП и позволяющая увеличить скорость выполнения операций. Создавать ее целесообразно в ПК с тактовой частотой задающего генератора 40 МГц и более. Регистры КЭШ-памяти недоступны для пользователя, отсюда и название КЭШ (Cache), в переводе с английского означает "тайник".
В КЭШ-памяти хранятся данные, которые МП получил и будет использовать в ближайшие такты своей работы. Быстрый доступ к этим данным и позволяет сократить время выполнения очередных команд программы. При выполнении программы данные, считанные из ОП с небольшим опережением, записываются в КЭШ-память.
По принципу записи результатов различают два типа КЭШ-памяти:
КЭШ-память "с обратной записью" - результаты операций прежде, чем их записать в ОП, фиксируются в КЭШ-памяти, а затем контроллер КЭШ-памяти самостоятельно перезаписывает эти данные в ОП;
КЭШ-память "со сквозной записью" - результаты операций одновременно, параллельно записываются и в КЭШ-память, и в ОП.
Микропроцессоры начиная от МП 80486 имеют свою встроенную КЭШ-память (или КЭШ-память 1-го уровня), чем, в частности, и обусловливается их высокая производительность. Микропроцессоры Pentium и Pentium Pro имеют КЭШ-память отдельно для данных и отдельно для команд, причем если у Pentium емкость этой памяти небольшая - по 8 Кбайт, то у Pentium Pro она достигает 256 - 512 Кбайт.
Следует иметь в виду, что для всех МП может использоваться дополнительная КЭШ-память(КЭШ-память 2-го уровня), размещаемая на материнской плате вне МП, емкость которой может достигать нескольких мегабайтов.
Примечание. Оперативная память может строитьсяна микросхемах динамического (Dinamic Random Access Memory - DRAM) или статического (Static Random Access Memory - SRAM) типа. Статический тип памяти обладает существенно более высокимбыстродействием, но значительно дороже динамического, Для регистровой памяти(МПП и КЭШ-память) используются SRAM, а ОЗУ основной памяти строится на базе DRAM-микросхем.
ОСНОВНАЯ ПАМЯТЬ
Физическая структура
Основная память содержит оперативное (RAM - Random Access Memory - память с произвольным доступом) и постоянное (ROM - Read-Only Memory) запоминающие устройства.
Оперативное запоминающее устройство предназначено для хранения информации (программ и данных), непосредственно участвующей в вычислительном процессе на текущем этапе функционирования ПК.
ОЗУ - энергозависимая память: при отключении напряжения питания информация, хранящаяся в ней, теряется. Основу ОЗУ составляют большие интегральные схемы, содержащие матрицы полупроводниковых запоминающих элементов (триггеров). Запоминающие элементы расположены на пересечении вертикальных и горизонтальных шин матрицы; запись и считывание информации осуществляются подачей электрических импульсов по тем шинам матрицы, которые соединены с элементами, принадлежащими выбранной ячейке памяти.
Конструктивно элементы оперативной памяти выполняются в виде отдельных микросхем типа DIP (Dual In-line Package - двухрядное расположение выводов) или в виде модулей памяти типа SIP (Single In-line Package - однорядное расположение выводов), или, что чаще, SIMM (Single In line Memory Module - модуль памяти с одноразрядным расположением выводов). Модули SIMM имеют емкость 256Кбайт, 1, 4, 8, 16 или 32 Мбайта, с контролем и без контроля четности хранимых битов; могут иметь 30- ("короткие") и 72-("длинные") контактные разъемы, соответствующие разъемам на материнской плате компьютера. На материнскую плату можно установить несколько (четыре и более) модулей SIMM.
Постоянное запоминающее устройство также строится на основе установленных на материнской плате модулей (кассет) и используется для хранения неизменяемой информации: загрузочных программ операционной системы, программ тестирования устройств компьютера и некоторых драйверов базовой системы ввода-вывода (BIOS - Base Input-Output System) и др. Из ПЗУ можно только считывать информацию, запись информации в ПЗУ выполняется вне ЭВМ в лабораторных условиях. Модули и кассеты ПЗУ имеют емкость, как правило, не превышающую нескольких сот килобайт. ПЗУ - энергонезависимое запоминающее устройство.
Примечание. В последние годы в некоторых ПК стали использоваться полупостоянные. перепрограммируемые запоминающие устройства - FLASH-память. Модули или карты FLASH-памяти могут устанавливаться прямо в разъемы материнской платы и имеют следующие параметры: емкость от 32 Кбайт до 4 Мбайт, время доступа по считыванию 0.06 мкс, время записи одного байта примерно 10 мкс: FLASH-память - энергонезависимое запоминающее устройство.
Для перезаписи информации необходимо подать на специальный вход FLASH-памяти напряжение программирования (12В), что исключает возможность случайного стирания информации. Перепрограммирование FLASH- памяти может выполняться непосредственно с дискетыили с клавиатуры ПК при наличии; специального контроллера либо с внешнего программатора, подключаемого к ПК.
FLASH-память может быть полезной как для создания весьма быстродействующих компактных, альтернативных НЖМД запоминающих устройств - "твердотельных дисков", так и для замены ПЗУ, хранящего программы BIOS, позволяя "прямо с дискеты" обновлять и заменять эти программы на более новыеверсии при модернизации ПК.
Структурно основная память состоит из миллионов отдельных ячеек памяти емкостью 1 байт каждая. Общая емкость основной памяти современных ПК обычно лежит в пределах от 1 до 32 Мбайт. Емкость ОЗУ на один-два порядка превышает емкость ПЗУ: ПЗУ занимает 128 (реже 256) Кбайт, остальной объем - это ОЗУ.
Логическая структура основной памяти
Каждая ячейка памяти имеет свой уникальный (отличный от всех других) адрес. Основная память имеет для ОЗУ и ПЗУ единое адресное пространство.
Адресное пространство определяет максимально возможное количество непосредственно адресуемых ячеек основной памяти.
Адресное пространство зависит от разрядности адресных шин, ибо максимальное количество разных адресов определяется разнообразием двоичных чисел, которые можно отобразить в n разрядах, т.е. адресное пространство равно 2n, где n - разрядность адреса.
Прежде всего основная память компьютера делится на две логические области: непосредственно адресуемую память, занимающую первые 1024 Кбайта ячеек с адресами от 0 до 1024 Кбайт-1, расширенную память, доступ к ячейкам которой возможен при использовании специальных программ-драйверов.
Стандартной памятью (СМА - Conventional Memory Area) называется непосредственно адресуемая память в диапазоне от 0 до 640 Кбайт.
Непосредственно адресуемая память в диапазоне адресов от 640 до 1024 Кбайт называется верхней памятью (UMA - Upper Memory Area). Верхняя память зарезервирована для памяти дисплея (видеопамяти) и постоянного запоминающего устройства. Однако обычно в ней остаются свободные участки - "окна", которые могут быть использованы при помощи диспетчера памяти в качестве оперативной памяти общего назначения.
Расширенная память - это память с адресами 1024 Кбайта и выше.
Непосредственный доступ к этой памяти возможен только в защищенном режиме работы микропроцессора.
В реальном режиме имеются два способа доступа к этой памяти, но только при использовании драйверов:
по спецификации XMS (эту память называют тогда ХМА - eXtended Memory Area);
по спецификации EMS (память называют ЕМ -Expanded Memory).
Доступ к расширенной памяти согласно спецификации XMS (eXtended Memory Specification) организуется при использовании драйверов ХММ (extended Memory Manager). Часто эту память называют дополнительной, учитывая, что в первых моделях персональных компьютеров эта память размещалась на отдельных дополнительных платах, хотя термин Extended почти идентичен, термину Expanded и более точно переводится как расширенный, увеличенный.
Спецификация EMS (Expanded Memory Specification) является более ранней. Coгласно этой спецификации доступ реализуется путем отображения по мере необходимости отдельных полей Expanded Memory в определенную область верхней памяти. При этом хранится не обрабатываемая информация, а лишь адреса, обеспечивающие доступ к этой информации. Память, организуемая по спецификации EMS, носит название отображаемой, поэтому и сочетание слов Expanded Memory (EM) часто переводят как отображаемая память. Для организации отображаемой памяти необходимо воспользоваться драйвером EMM386.EXE (Expanded Memory Manager) или пакетом управления памятью QEMM.
Расширенная память может быть использована главным образом для хранения дат и некоторых программ ОС. Часто расширенную память используют для организации виртуальных (электронных) дисков.
Исключение составляет небольшая 64-Кбайтная область памяти с адресами от 1024 до 1088 Кбайт (так называемая высокая память, иногда ее называют старшая: НМА - High Memory Area), которая может адресоваться и непосредственно при использовании драйвера HIMEM.SYS (High Memory Manager) в соответствии со спецификацией XMS. НМА обычно используется для хранения программ и данных операционной системы.
Примечание. В современных ПК существует режим виртуальной адресации (virtual - кажущийся, воображаемый). Виртуальная адресация используется для увеличения предоставляемой программам оперативной памяти за счет отображения в части адресного пространства фрагмента внешней памяти.
ВНЕШНЯЯ ПАМЯТЬ
Устройства внешней памяти или, иначе, внешние запоминающие устройства весьма разнообразны. Их можно классифицировать по целому ряду признаков: по виду носителя, типу конструкции, по принципу записи и считывания информации, методу доступа и т.д.
В зависимости от типа носителя все ВЗУ можно подразделить на накопители на магнитной ленте и дисковые накопители.
Накопители на магнитной ленте, в свою очередь, бывают двух видов: накопители на бобинной магнитной ленте (НБМЛ) и накопители на кассетной магнитной ленте (НКМ- стриммеры). В ПК используются только стриммеры.
Диски относятся к машинным носителям информации с прямым доступом. Понятие прямой доступ означает, что ПК может "обратиться" к дорожке, на которой начинается участок с искомой информацией или куда нужно записать новую информацию, непосредственно, где бы ни находилась головка записи/чтения накопителя.
Накопители на дисках более разнообразны:
накопители на гибких магнитных дисках (НГМД), иначе, на флоппи-дисках или на дискетах;
накопители на жестких магнитных дисках (НЖМД) типа "винчестер";
накопители на сменных жестких магнитных дисках, использующие эффект Бернулли;
накопители на флоптических дисках, иначе, floptical-накопители;
накопители сверхвысокой плотности записи, иначе, VHD-накопители;
накопители на оптических компакт-дисках CD-ROM (Compact Disk ROM);
накопители на оптических дисках типа СС WORM (Continuous Composite Write Once Read Many - однократная запись - многократное чтение);
накопители на магнитооптических дисках (НМОД) и др.
Билет 10:
Сегментная и страничная виртуальная память
В системах с сегментной и страничной адресацией виртуальный адрес имеет сложную структуру. Он разбит на два битовых поля: номер страницы (сегмента) и смещение в нем. Соответственно, адресное пространство оказывается состоящим из дискретных блоков. Если все эти блоки имеют фиксированную длину и образуют вместе непрерывное пространство, они называются страницами. Если длина каждого блока может задаваться произвольно, а неиспользуемым частям блоков соответствуют ``дыры'' в виртуальном адресном пространстве, они называются сегментами. Как правило, один сегмент соответствует коду или данным одного модуля программы. Со страницей или сегментом могут быть ассоциированы права чтения, записи и исполнения.
Такая адресация реализуется аппаратно. Процессор, как правило, имеет специальное устройство, называемое диспетчером памяти. В некоторых процессорах, например в MC68020 или MC68030 или в некоторых RISC- системах, это устройство реализовано на отдельном кристалле; в других, таких как i386 или Alpha, диспетчер памяти интегрирован в процессор.
Диспетчер памяти содержит регистр - указатель на таблицу трансляции. Эта таблица размещается где-то в физической памяти. Ее элементами являются дескрипторы каждой страницы/сегмента. Такой дескриптор содержит права доступа к странице, признак присутствия этой страницы в памяти и физический адрес страницы/ сегмента. Для сегментов в дескрипторе также хранится длина сегмента.
Как правило, диспетчер памяти имеет также кэш (cache) дескрипторов - быструю память с ассоциативным доступом. В этой памяти хранятся дескрипторы часто используемых страниц.
Алгоритм доступа к памяти по виртуальному адресу page:offset получается следующим:
Проверить, существует ли страница page вообще. Например, у машин семейства VAX адресное пространство может состоять из 8М страниц, что соответствует 4 Гбайтам, но реальные программы используют намного меньше памяти, и размеры их таблиц трансляции соответственно уменьшаются. Естественно, про страницу, для которой нет соответствующего элемента таблицы, можно сказать, что ее не существует. Такая проверка осуществляется простым сравнением номера страницы с длиной таблицы трансляции. Если страницы не существует, возникает особая ситуация ошибки сегментации (segmentation violation)
Попытаться найти дескриптор страницы в кэше.
Если его нет в кэше, загрузить дескриптор из таблицы в памяти.
Проверить, имеет ли процесс соответствующее право доступа к странице. Иначе также возникает ошибка сегментации.
Проверить, находится ли страница в оперативной памяти. Если ее там нет, возникает особая ситуация отсутствия страницы или стpаничный отказ (page fault). Как правило, реакция на нее состоит в том, что вызывается специальная программа-обработчик (trap - ловушка), которая подкачивает требуемую страницу с диска. В многозадачных системах во время такой подкачки может исполняться другой процесс.
Если страница есть в памяти, взять из ее дескриптора физический адрес phys_addr.
Если мы имеем дело с сегментной адресацией, сравнить смещение в сегменте с длиной этого сегмента. Если смещение оказалось больше, также возникает ошибка сегментации.
Произвести доступ к памяти по адресу phys_addr[offset].
Видно, что такая схема адресации довольно сложна. Однако в современных процессорах все это реализовано в аппаратуре и, благодаря кэшу дескрипторов и другим ухищрениям, скорость доступа к памяти получается почти такой же, как и при прямой адресации. Кроме того, эта схема имеет неоценимые преимущества при реализации многозадачных ОС.
Во-первых, мы можем связать с каждой задачей свою таблицу трансляции, а значит и свое виртуальное адресное пространство. Благодаря этому даже в многозадачных ОС мы можем пользоваться абсолютным загрузчиком. Кроме того, программы оказываются изолированными друг от друга, и мы можем обеспечить их безопасность.
Во-вторых, мы можем сбрасывать на диск редко используемые области виртуальной памяти программ - не всю программу целиком, а только ее часть. Кроме того, в отличие от оверлеев, программа вообще не обязана знать, какая ее часть может быть сброшена.
В-третьих, программа не обязана занимать непрерывную область физической памяти. При этом она вполне может видеть непрерывное виртуальное адресное пространство. Это резко упрощает борьбу с фрагментацией памяти, а в системах со страничной адресацией проблема фрагментации физической памяти вообще снимается.
В-четвертых, система может обеспечивать не только защиту программ друг от друга, но и защиту программы от самой себя - например, от ошибочной записи данных на место кода.
В-пятых, различные задачи могут использовать общие области памяти для взаимодействия или, скажем, просто для того, чтобы работать с одной копией библиотеки подпрограмм.
Перечисленные преимущества настолько серьезны, что считается невозможным реализовать многозадачную систему общего назначения, такую как UNIX или VMS (Virtual Memory System) на машинах без диспетчера памяти.
Отдельной проблемой при разработке системы со страничной или сегментной адресацией является выбор размера страницы или максимального размера сегмента. Этот размер определяется шириной соответствующего битового поля адреса и поэтому должен быть степенью двойки.
С одной стороны, страницы не должны быть слишком большими, так как это может привести к неэффективному использованию памяти и перекачке слишком больших объемов данных при сбросе страниц на диск. С другой стороны, страницы не должны быть слишком маленькими, так как это приведет к чрезмерному увеличению таблиц трансляции, требуемого объема кэша дескрипторов и т.д.
Что будет считаться ``слишком'' большим или, наоборот, маленьким, в действительности зависит от среднего количества памяти, используемого программой. Так, если вы работаете со старой UNIX-системой и пользуетесь только программами типа ls, grep или sed, а редактор vi считается чем-то почти сверхъестественным, то средний размер ваших программ будет измеряться десятками килобайт и редко выходить за сотню. Если же вы используете современные графические оконные интерфейсы, систему X Windows, emacs и прочие красоты, то типичная программа требует около мегабайта памяти, а некоторые и по несколько десятков. Казалось бы, размер страницы при этом также должен измениться на два-три порядка. На самом деле, здесь в игру вступает еще один параметр - размер сектора на диске, с которого осуществляется подкачка...\
В реальных системах размер страницы меняется от 512 байт у машин семейства VAX до нескольких килобайт. Например, i3/486 имеет страницу размером 4 К. Некоторые диспетчеры памяти, например у MC6801/2/30, имеют переменный размер страницы - в том смысле, что система при запуске программирует диспетчер и устанавливает, помимо прочего, этот размер, и дальше работает со страницами выбранного размера. У процессора i860 размер страницы переключается между 4 К и 4 Мбайтами.
С сегментными диспетчерами памяти ситуация сложнее. С одной стороны, хочется, чтобы один программный модуль влезал в сегмент, поэтому сегменты обычно делают большими, от 32К и более. С другой стороны, хочется, чтобы в адресном пространстве можно было сделать много сегментов. Кроме того, может возникнуть проблема: как быть с большими неразделимыми объектами, например хэш-таблицами компиляторов, под которые часто выделяются сотни килобайт. С третьей стороны, при подкачке сегментов с диска не хочется качать за один раз много данных.
Третье обстоятельство вынуждает многих разработчиков идти на двухступенчатую виртуальную память - сегментную адресацию, в которой каждый сегмент, в свою очередь, разбит на страницы. Это дает ряд мелких преимуществ, например, позволяет раздавать права доступа сегментам, а подкачку с диска осуществлять постранично. Таким образом организована виртуальная память в IBM System 370 и ряде других больших компьютеров, а также в i3/486. Правда, в последнем виртуальная память используется несколько странным образом.
Вообще говоря, i386 может работать с двумя типами адресов:
32-разрядным адресом, в котором 16 бит задают смещение в сегменте, 14 бит - номер сегмента, и 2 бита используются для разных загадочных целей. При этом размер сегмента не более 64К, а общий объем виртуальной памяти не превышает 1 Гбайта.
48-разрядным адресом, в котором смещение в сегменте занимает 32 бита. В этом случае размер сегмента может быть до 4 Гбайт, а общий объем виртуальной памяти до байт.
В обоих случаях сегмент может быть разбит на страницы по 4 К. При этом сегментная часть адреса и его смещение лежат в разных регистрах, и с ними можно работать раздельно. В реальном режиме возможность такой работы порождает весь зоопарк ``моделей памяти'', с которыми знакомы те, кто писал на C для MS DOS. В случае i386 большинство систем программирования выделяют программе один сегмент с 32-разрядным смещением, и программа живет там так, будто это обычная машина с 32-разрядным линейным адресным пространством. Так поступают все известные авторам реализации Unix для i386, ряд так называемых расширителей ДОС (DOS extenders), Oberon/386, Novell Netware и т.д.
С другой стороны, MS Windows в enhanced режиме используют i386 именно как машину с двухслойной сегментно-страничной адресацией, то есть загружают программу по сегментам, и права доступа ей выдают на сегменты, а подкачку с диска делают постранично. Это обусловлено не столько настоящей потребностью в сегментации, сколько требованием совместимости со standard режимом, в котором MS Windows работают на процессоре 80286
Билет 11:
Ассоциативная память:
К числу систем класса ОКМД относятся ассоциативные системы. Эти системы, как и матричные, характеризуются большим числом операционных устройств, способных одновременно, по командам одного управляющего устройства вести обработку нескольких потоков данных. Но эти системы существенно отличаются от матричных способами формирования потоков данных. В матричных системах данные поступают на обработку от общих или раздельных запоминающих устройств с адресной выработкой информации либо непосредственно от устройств – источников данных. В ассоциативных системах информация на обработку поступает от ассоциативных запоминающих устройств (АЗУ), характеризующихся тем, что информация из них выбирается не по определенному адресу, а по ее содержанию.
Рис 38 Ассоциативное запоминающее устройство
Принцип работы АЗУ поясняет схема, представленная на рис. 3.8. Запоминающий массив, как и в адресных ЗУ, разделен на m-разрядные ячейки, число которых п. Практически для любого типа АЗУ характерно наличие следующих элементов: запоминающего массива; регистра ассоциативных признаков (РгАП); регистра маски (РгМ); регистра индикаторов адреса со схемами сравнения на входе. В АЗУ могут быть и другие элементы, наличие и функции которых определяются способом использования АЗУ.
Выборка информации из АЗУ происходит следующим образом. В РгАП из устройства управления передается код признака искомой информации (иногда его называют компарандом). Код может иметь произвольное число разрядов – от 1 до m. Если код признаков используется полностью, то он без изменения поступает на схему сравнения, если же необходимо использовать только часть кода, тогда ненужные разряды маскируются с помощью РгМ. Перед началом поиска информации в АЗУ все разряды регистра индикаторов адреса устанавливаются в состояние 1. После этого производится опрос первого разряда всех ячеек ЗМ и содержимое сравнивается с первым разрядом РгАП. Если содержимое первого разряда i-й ячейки не совпадает с содержимым первого разряда РгАП, то соответствующий этой ячейке разряд регистра индикаторов адреса Тi сбрасывается в состояние 0, если совпадает, – на Тi остается 1. Затем эта операция повторяется со вторым, третьим и последующими разрядами до тех пор, пока не будет произведено сравнение со всеми разрядами РгАП. После поразрядного опроса и сравнения в состоянии 1 останутся те разряды регистра индикаторов адреса, которые соответствуют ячейкам, содержащим информацию, совпадающую с записанной в РгАП. Эта информация может быть считана в той последовательности, которая определяется устройством управления.
Заметим, что время поиска информации в ЗМ по ассоциативному признаку зависит только от числа разрядов признака и от скорости опроса разрядов, но совершенно не зависит от числа ячеек ЗМ. Этим и определяется главное преимущество АЗУ перед адресными ЗУ: в адресных ЗУ при операции поиска необходим перебор всех ячеек запоминающего массива.
Запись новой информации в ЗМ производится без указания номера ячейки. Обычно один из разрядов каждой ячейки используется для указания ее занятости, т. е. если ячейка свободна для записи, то в этом разряде записан 0, а если занята, – 1. Тогда при записи в АЗУ новой информации устанавливается признак 0 в соответствующем разряде РгАП и определяются все ячейки ЗМ, которые свободны для записи. В одну из них устройство управления помещает новую информацию.
Нередко АЗУ строятся таким образом, что кроме ассоциативной допускается и прямая адресация данных, что представляет определенные удобства при работе с периферийными устройствами.
Необходимо отметить, что запоминающие элементы АЗУ в отличие от элементов адресуемых ЗУ должны не только хранить информацию, но и выполнять определенные логические функции, поэтому позволяют осуществить поиск не только по равенству содержимого ячейки заданному признаку, но и по другим условиям: содержимое ячейки больше (меньше) признака РгАП, а также больше или равно (меньше или равно).
Отмеченные выше свойства АЗУ характеризуют преимущества АЗУ для обработки информации. Формирование нескольких потоков идентичной информации с помощью АЗУ осуществляется быстро и просто, а с большим числом операционных элементов можно создавать высокопроизводительные системы. Надо учитывать еще и то, что на основе ассоциативной памяти легко реализуется изменение места и порядка расположения информации. Благодаря этому АЗУ является эффективным средством формирования наборов данных.
Исследования показывают, что целый ряд задач, таких, как обработка радиолокационной информации, распознавание образов, обработка различных снимков и других задач с матричной структурой данных, эффективно решается ассоциативными системами. К тому же программирование таких задач для ассоциативных систем гораздо проще, чем для традиционных.
И еще об ассоциативной памяти:
В составе вычислительных машин содержатся различные по техническим характеристикам ЗУ, образующие память ЭВМ с иерархической структурой. Это определяется тем, что в одном типе ЗУ не удается совместить противоречивые требования, связанные, например, с необходимостью обеспечить большую емкость и высокое быстродействие памяти. В иерархической системе ЗУ можно выделить внутреннюю (оперативную) и внешнюю память. Оперативная память предназначена для размещения информации, непосредственно используемой в вычислительном процессе. Внешняя память обычно имеет значительно большую емкость и меньшее быстродействие, и для использования хранимой в ней информации необходимо предварительно переместить эту информацию в оперативную память. В настоящее время почти все ЗУ строятся по адресному принципу, т. е. каждой ячейке присваивается определенный номер (адрес), по которому производится обращение, к содержимому ячейки. С физической точки зрения адрес запоминающей ячейки, как правило, определяет ее положение. С логической точки зрения адрес представляет собой не более чем добавку к хранимому в ячейке слову, необходимую для его нахождения. Применение адресного принципа организации памяти диктуется особенностями используемых элементов вычислительной техники и, вообще говоря, не является ни наиболее естественным, ни наиболее удобным. Первоначальные соображения по поводу построения ЗУ с неадресным обращением типа каталога появились в 1956 году в связи с начавшейся разработкой сверхпроводниковых элементов — криотронов. Логические и математические вопросы организации ЗУ, в которых за счет усложнения их структуры достигается возможность производить обращение к словам по содержанию некоторой их части, были разработаны в 1960 году Г. Г. Стецюрой. Такого рода ЗУ вне зависимости от их специфических особенностей называют ассоциативными запоминающими устройствами (АЗУ). Термин "ассоциативный", взятый из физиологии, характеризует известное свойство человеческой памяти, позволяющее устанавливать взаимосвязи между различными информационными объектами. На исследования и разработки в области ассоциативных ЗУ были затрачены значительные усилия. Имеется много сотен работ, посвященных этой проблеме, и в настоящее время число публикаций по данному вопросу составляет несколько десятков в год. Наиболее общим случаем устройства, допускающего обращение к информации по содержанию, является так называемое полностью ассоциативное устройство, в котором признак поиска может быть произвольно расположенным во всех разрядах хранящегося слова. Можно выделить также три наиболее характерных типа частично-ассоциативных ЗУ, в которых поиск проводится по некоторой ограниченной части слова:
память, обладающая свойствами полностью ассоциативного устройства, но в пределах ограниченной по длине части слова;
память с несколькими ассоциативными признаками, любая комбинация которых может участвовать в опросе;
память с одним признаком фиксированной длины, все разряды которого одновременно используются для опроса (при этом искомой информацией является остальная часть слова).
Эта классификация, будучи связанной с проблемами технической реализации ассоциативных ЗУ, отражает также различные функциональные требования к ассоциативной памяти со стороны информационных систем. Информационную структуру объектов можно представлять в виде многомерной точечной решетки, на которой задается функция какой-либо природы. Компонентой такой структуры n-мерного объекта является значение функции, снабженное n независимыми индексами. Свойства памяти, касающиеся проблем информационного поиска, удобно трактовать в терминах адекватности отображения размерности информационных структур. Для случая биологических систем указанные структуры в пределе можно рассматривать и как непрерывные. Размерность, как известно, представляет собой топологический инвариант, и для того чтобы этот инвариант при отображении в памяти электронно-вычислительной машины или живого организма сохранялся, такое отображение должно быть "непрерывным" в том смысле, что "близкие" элементы объекта должны оставаться «близкими» в устройстве хранения информации. При этом элементами, "близкими" в устройстве хранения информации, следует считать такие, связь между которыми может быть осуществлена за достаточно малое время, так что в этом смысле близость оказывается характеристикой, вообще говоря, логического, а не физического отношения. Малость промежутка времени, отводимого на установление связей, следует понимать в сопоставлении с некоторым характерным временем, затрачиваемым на определенные процедуры обработки информационного содержания объекта. Например, в случае рассмотрения технических устройств памяти в составе информационно-справочных систем имеет смысл говорить, что в них адекватно отображается размерность информационной структуры объекта, когда время перехода между соседними элементами структуры может быть сделано сопоставимым с требуемым временем реакции системы. В терминах уменьшения степени адекватности отображения размерности информационной структуры объектов можно трактовать, в частности, также такие известные факты, как замедление переработки информации при моделировании вычислительной среды на некоторой решетке посредством такой же среды на решетке меньшей размерности. В случае биологической памяти при рассмотрении вопроса об адекватном отображении размерности объекта следует сопоставлять время, в течение которого должно быть обеспечено установление связей между элементами информационной структуры и минимальный разрешающий интервал между различными возбуждающими воздействиями. Следует подчеркнуть, что рассмотрение ограничения времени для установления связей является важным принципиальным моментом, поскольку без учета временного фактора любые структурные взаимоотношения элементов независимо от их расположения могут быть установлены посредством медленной операции последовательного просмотра содержимого памяти. В случае биологической памяти время установления связей между элементами объекта не должно сколько-нибудь заметно превышать минимальный разрешающий интервал между возбуждающими воздействиями, ибо тогда восприятие этих связей, а следовательно, восприятие размерности образа будет нарушено. Таким образом, ограничения на величину размерности адекватно отображаемых объектов представляются следствием ограничения на скорость процессов обработки информации. Исходя из изложенной трактовки, можно показать, каким образом на основе голографической модели функционирования биологической памяти можно развить известную гипотезу Пуанкаре о физиологической обусловленности свойства трехмерности пространства восприятия. Обычно адресное запоминающее устройство по своей природе приспособлено для отображения одномерных объектов, элементы которых размещаются в соответствии с упорядочением по одному параметру. Для установления связей между элементами при отображении многомерных объектов нужно применять специальную программную организацию на основе так называемых списковых структур. В ассоциативной памяти использование значений индексов в качестве признака поиска позволяет удобно представить объект произвольной размерности, конечно, если отвлечься от технических деталей, касающихся ограниченной разрядности машинного слова. В этом случае при одном обращении к памяти можно сразу выделить подмножество элементов объекта в произвольном разрезе; извлечение же отдельных элементов осуществляется весьма быстро при использовании эффективных процедур так называемого разделения многозначного ответа.
Билет 12:
Программно-управляемый ввод/вывод
Д анный
режим характеризуется тем, что все
действия по вводу/выводу реализуются
командами прикладной программы. Наиболее
простыми эти действия оказываются для
"всегда готовых" внешних устройств,
например индикатора на светодиодах.
При необходимости ВВ в соответствующем
месте программы используются команды
IN или OUT. Такая передача данных называется
синхронным или безусловным ВВ. Однако
для большинства ВУ до выполнения операций
ВВ надо убедиться в их готовности к
обмену, т.е. ВВ является асинхронным.
Общее состояние устройства характеризуется
флагом готовности READY, называемым также
флагом готовности/занятости (READY/BUSY).
Иногда состояния готовности и занятости
идентифицируются отдельными флагами
READY и BUSY, входящими в слово состояния
устройства. Процессор проверяет флаг
готовности с помощью одной или нескольких
команд. Если флаг установлен, то
инициируются собственно ввод или вывод
одного или нескольких слов данных. Когда
же флаг сброшен, процессор выполняет
цикл из 2-3 команд с повторной проверкой
флага READY до тех пор, пока устройство не
будет готово к операциям ВВ (рис. 3.10).
Данный цикл называется циклом ожидания
готовности ВУ и реализуется в различных
процессорах по-разному.
анный
режим характеризуется тем, что все
действия по вводу/выводу реализуются
командами прикладной программы. Наиболее
простыми эти действия оказываются для
"всегда готовых" внешних устройств,
например индикатора на светодиодах.
При необходимости ВВ в соответствующем
месте программы используются команды
IN или OUT. Такая передача данных называется
синхронным или безусловным ВВ. Однако
для большинства ВУ до выполнения операций
ВВ надо убедиться в их готовности к
обмену, т.е. ВВ является асинхронным.
Общее состояние устройства характеризуется
флагом готовности READY, называемым также
флагом готовности/занятости (READY/BUSY).
Иногда состояния готовности и занятости
идентифицируются отдельными флагами
READY и BUSY, входящими в слово состояния
устройства. Процессор проверяет флаг
готовности с помощью одной или нескольких
команд. Если флаг установлен, то
инициируются собственно ввод или вывод
одного или нескольких слов данных. Когда
же флаг сброшен, процессор выполняет
цикл из 2-3 команд с повторной проверкой
флага READY до тех пор, пока устройство не
будет готово к операциям ВВ (рис. 3.10).
Данный цикл называется циклом ожидания
готовности ВУ и реализуется в различных
процессорах по-разному.
Рис. 3.10. Цикл программного ожидания готовности внешнего устройства
Основной недостаток программного ВВ связан с непроизводительными потерями времени процессора в циклах ожидания. К достоинствам следует отнести простоту его реализации, не требующей дополнительных аппаратных средств.
ПРИНЦИПЫ ОРГАНИЗАЦИИ СИСТЕМ ВВОДА-ВЫВОДА ЭВМ
Передача информации с периферийного устройства в ядро ЭВМ называется операцией ввода, а передача из ядра ЭВМ в периферийное устройство - операцией вывода.
Связь устройств ЭВМ друг с другом осуществляется с помощью средств сопряжения - интерфейсов.
Интерфейс представляет собой совокупность линий и шин, сигналов, электронных схем и алгоритмов, предназначенную для осуществления обмена информацией между устройствами. От характеристик интерфейсов во многом зависят производительность и надежность вычислительной машины.
При разработке систем ввода-вывода должны быть решены следующие проблемы:
1) Должна быть обеспечена возможность реализации машин с переменным составом оборудования.
2) Для эффективного использования оборудования ЭВМ должны реализовываться параллельная во времени работа процессора над программой и выполнение периферийными устройствами процедур ввода-вывода.
3) Необходимо стандартизировать программирование операций ввода-вывода для обеспечения их независимости от особенностей периферийного устройства.
4) Необходимо обеспечить автоматическое распознавание и реакцию ядра ЭВМ на многообразие ситуаций, возникающих в ПУ (готовность устройства, различные неисправности и т.п.).
При конструировании ЭВМ широко применяются различные средства унификации.Средства вычислительной техники проектируются на основе модульного принципа, который заключается в том, что отдельные устройства выполняются в виде конструктивно законченных модулей, из которых можно собирать ЭВМ в различных конфигурациях.При обмене межд ПУ и ЭВМ используются унифицированные форматы данных. Преобразование унифицированных форматов данных в индивидуальные, приспособленные для отдельных ПУ, производится в самих ПУ.Унификации также подвергают все компоненты интерфейса, а также формат и набор команд процессора для операций ввода-вывода.Унификация распространяется на семейство моделей ЭВМ.Для обеспечения параллельной работы процессора и периферийных устройств схемы управления вводом-выводом отделяют от процессора.Выполнение общих функций возлагают на общие для групп периферийного оборудования унифицированные устройства - контроллеры прямого доступа к памяти, процессоры ввода- вывода.
ПРЯМОЙ ДОСТУП К ПАМЯТИ
В системах ввода-вывода ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно-управляемая передача и прямой доступ к памяти.
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора, который при этом выполняет специальную подпрограмму процедуры ввода-вывода. Данные между памятью и периферийным устройством пересылаются через процессор. Операция ввода - вывода инициируется текущей командой программы или запросом прерывания от периферийного устройства. При этом процессор на все время выполнения операции ввода-вывода отвлекается от выполнения основной программы.
Кроме того при пересылке блока данных процессору приходится для каждой единицы передаваемых данных выполнять несколько команд, чтобы обеспечить буферизацию, преобразование форматов данных, подсчет количества переданных данных, формирование адресов в памяти и т.п. Это сильно снижает скорость передачи данных (не выше 100 Кб/сек), что недопустимо при работе с высокоскоростными ПУ.
Между тем потенциально возможная скорость обмена данными при вводе-выводе определяется пропускной способностью памяти. Для быстрого ввода-вывода блоков данных используется прямой доступ к памяти.
Прямым доступом к памяти называется способ обмена данными, обеспечивающий независимую от процессора передачу данных между памятью и периферийным устройством.
Прямым доступом к памяти управляет контроллер ПДП, который выполняет следующие функции:
1) управление инициируемой процессором или ПУ передачей данных между ОП и ПУ;
2) задание размера блока данных, который подлежит передаче, и области памяти, используемой при передаче;
3) формирование адресов ячеек ОП, участвующих в передаче;
4) подсчет числа переданных единиц данных (байт или слов) и определение момента завершения операции ввода-вывода.
Указанные функции реализуются контроллером ПДП с помощью одного или нескольких буферных регистров, регистра - счетчика текущего адреса данных и регистра-счетчика подлежащих передаче данныхПри инициировании операции ввода-вывода в счетчик подлежащих передаче данных заносится размер передаваемого блока (число байт или слов), а в счетчик текущего адреса - начальный адрес области памяти, используемой при передаче. При передаче каждого байта содержимое счетчика адреса увеличивается на 1, при этом формируется адрес очередной ячейки памяти, участвующей в передаче. Одновременно уменьшается на 1 содержимое счетчика подлежащих передаче данных; обнуление этого счетчика указывает на завершение передачи.Контроллер ПДП обычно имеет более высокий приоритет в занятии цикла обращения к памяти по сравнению с процессором. Управление памятью переходит к контроллеру ПДП, как только завершается цикл обращения к памяти для текущей команды процессора.Прямой доступ к памяти обеспечивает высокую скорость обмена данными за счет того, что управление обменом производится не программными, а аппаратными средствами.
ОСНОВНЫЕ ПРИНЦИПЫ ПОСТРОЕНИЯ СИСТЕМ ВВОДА-ВЫВОДА
Можно выделить два характерных принципа построения систем ввода-вывода: ЭВМ с одним общим интерфейсом и ЭВМ с множеством интерфейсов и процессорами (каналами) ввода- вывода.
Структура с одним общим интерфейсом
Структура с одним общим интерфейсом предполагает наличие общей шины, к которой подсоединяются все модули, в совокупности образующие ЭВМ: процессор, оперативная и постоянная память и периферийные устройства. В каждый данный момент через общую шину может происходить обмен данными только между одной парой присоединенных к ней модулей. Таким образом, модули ЭВМ разделяют во времени один общий интерфейс, причем процессор выступает как один из модулей системы.
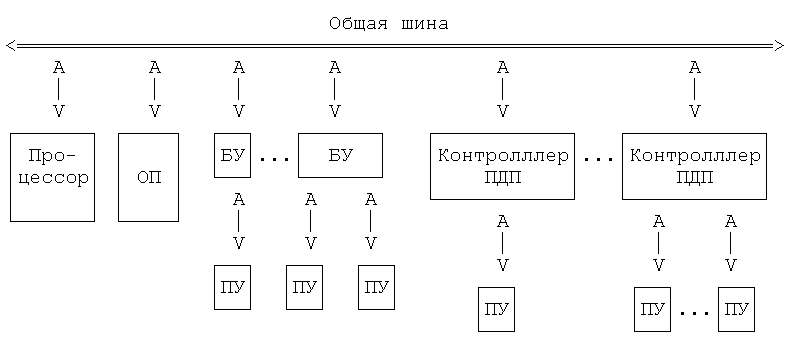
Периферийные устройства подсоединяются к общей шине с помощью блоков управления периферийными устройствами (контроллеров), осуществляющих согласование форматов данных периферийных устройств с форматом, принятым для передачи по общей шине.
Если в периферийном устройстве операции ввода - вывода производятся для отдельных байт или слов, то используется программно-управляемая передача данных через процессор и под его управлением. Конструкция контроллера при этом сильно упрощается.
Для перифериийных устройств с поблочной передачей данных (ЗУ на дисках, лентах и др.) применяется прямой доступ к памяти и контроллеры ПДП.
При общем интерфейсе аппаратура управления вводом-выводом рассредоточена по отдельным модулям ЭВМ. Процессор при этом не полностью освобождается от управления операциями ввода-вывода. Более того, на все время операции передачи данных интерфейс оказывается занятым, а связь процессора с памятью блокированной.
Интерфейс с общей шиной применяется только в малых и микро-ЭВМ, которые имеют короткое машинное слово, небольшой объем периферийного оборудования и от которых не требуется высокой производительности.
Структура с каналами ввода-вывода
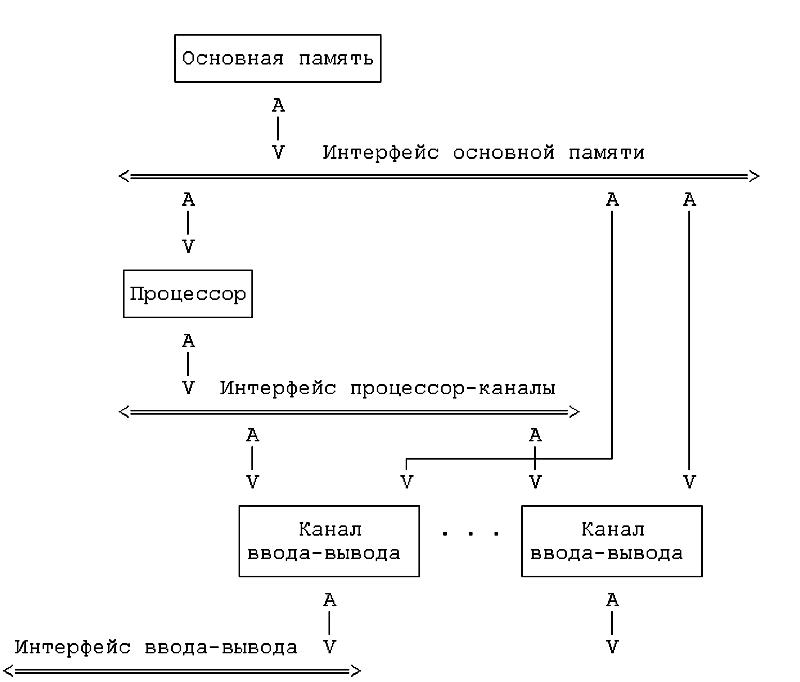
Структура системы с процессорами (каналами) ввода-вывода применяется в высокопроизводительных ЭВМ. В таких ЭВМ система ввода-вывода строится путем централизации аппаратуры управления вводом-выводом на основе применения программно- управляемых процессоров (каналов) ввода-вывода. Обмен информацией между памятью и периферийным устройством осуществляется через канал ввода-вывода.
Каналы ввода - вывода полностью освобождают процессор от управления операциями ввода- вывода.
В вычислительной машине с каналами ввода-вывода форматы передаваемых данных неоднородны, поэтому неоходимо использовать в ЭВМ несколько специализированных интерфейсов.Можно выделить 4 типа интерфейсов: интерфейс основной памяти, интерфейс процессор- каналы, интерфейсы ввода-вывода, интерфейсы периферийных устройств (малые интерфейсы).Через интерфейс основной памяти производится обмен информацией между памятью, с одной стороны, и процессором и каналами - с другой.Интерфейс процессор-каналы предназначается для передачи информации между процессорами и каналами ввода-вывода.Через интерфейс ввода-вывода происходит обмен информацией между каналами и блоками управления периферийных устройств.Интерфейс периферийного устройства служат для обмена данными между периферийным устройством и его блоком управления. Унификации малые интерфейсы не поддаются, так как ПУ весьма разнообразны по принципу действия, используемым форматам данных и сигналам.
ОСНОВНЫЕ ПАРАМЕТРЫ ИНТЕРФЕЙСОВ
Интерфейсы характеризуются следующими параметрами:
1) Пропускная способность интерфейса - это количество информации, которое может быть передано через интерфейс в единицу времени (имеет диапазон от десятков байт до сотен мегабайт).
2) Максимальная частота передачи информационных сигналов через интерфейс (от десятков герц до сотен мегагерц).
3) Максимально допустимое расстояние между соединяемыми устройствами (имеет диапазон от десятков сантиметров до нескольких километров при использовании оптоволоконных линий).
4) Динамические параметры интерфейса: время передачи отдельного слова и блока данных с учетом продолжительности процедур подготовки и завершения передачи. Эти параметры особенно важны для систем реального времени.
5) Общее число линий (проводов) в интерфейсе.
6) Информационная ширина интерфейса - число бит данных, передаваемых параллельно через интерфейс. Различные интерфейсы имеют ширину 1, 8, 16, 32, 64, 128 или 256 бит.
7) Связность интерфейса: интерфейс может быть односвязным, когда существует лишь единственный путь передачи информации между парой устройств машины, и многосвязным, позволяющим устройствам обмениваться информацией по нескольким независимым путям. Многосвязность интерфейсов требует дополнительной аппаратуры, но повышает надежность и живучесть вычислительной машины, обеспечивает возможность автоматической реконфигурации вычислительного комплекса при выходе из строя отдельных устройств.
В состав компьютеров часто входят специальные устройства, называемые дисковыми контроллерами. К каждому дисковому контроллеру может подключаться несколько дисковых накопителей. Между дисковым контроллером и основной памятью может быть целая иерархия контроллеров и магистралей данных, сложность которой определяется главным образом стоимостью компьютера. Поскольку время передачи часто составляет очень небольшую часть общего времени доступа к диску, контроллер в высокопроизводительной системе разъединяет магистрали данных от диска на время позиционирования так, что другие диски, подсоединенные к контроллеру, могут передавать свои данные в основную память. Поэтому время доступа к диску может увеличиваться на время, связанное с накладными расходами контроллера на организацию операции ввода/вывода.
//Так, чиста интересно:
Рассмотрим теперь основные составляющие времени доступа к диску в типичной подсистеме SCSI. Такая подсистема включает в себя четыре основных компонента: основной компьютер, главный адаптер SCSI, встроенный в дисковое устройство контроллер и собственно накопитель на магнитных дисках. Когда операционная система получает запрос от пользователя на выполнение операции ввода/вывода, она превращает этот запрос в набор команд SCSI. Запрашивающий процесс при этом блокируется и откладывается до завершения операции ввода/вывода (если только это был не запрос асинхронной передачи данных). Затем команды пересылаются по системе шин в главный адаптер SCSI, к которому подключен необходимый дисковый накопитель. После этого ответственность за выполнение взаимодействия с целевыми контроллерами и их устройствами ложится на главный адаптер.
Затем главный адаптер выбирает целевое устройство, устанавливая сигнал на линии управления шины SCSI (эта операция называется фазой выбора). Естественно, шина SCSI должна быть доступна для этой операции. Если целевое устройство возвращает ответ, то главный адаптер пересылает ему команду (это называется фазой команды). Если целевой контроллер может выполнить команду немедленно, то он пересылает в главный адаптер запрошенные данные или состояние. Команда может быть обслужена немедленно, только если это запрос состояния, или команда запрашивает данные, которые уже находятся в кэш-памяти целевого контроллера. Обычно же данные не доступны, и целевой контроллер выполняет разъединение, освобождая шину SCSI для других операций. Если выполняется операция записи, то за фазой команды на шине немедленно следует фаза данных, и данные помещаются в кэш-память целевого контроллера. Подтверждение записи обычно не происходит до тех пор, пока данные действительно не запишутся на поверхность диска.
После разъединения, целевой контроллер продолжает свою собственную работу. Если в нем не предусмотрены возможности буферизации команд (создание очереди команд), ему надо только выполнить одну команду. Однако, если создание очереди команд разрешено, то команда планируется в очереди работ целевого контроллера, при этом обрабатывается команда, обладающая наивысшим приоритетом в очереди. Когда запрос станет обладать наивысшим приоритетом, целевой контроллер должен вычислить физический адрес (или адреса), необходимый для обслуживания операции ввода/вывода. После этого становится доступным дисковый механизм: позиционируется каретка, подготавливается соответствующая головка записи/считывания и вычисляется момент появления данных под головкой. Наконец, данные физически считываются или записываются на дорожку. Считанные данные запоминаются в кэш-памяти целевого контроллера. Иногда целевой контроллер может выполнить считывание с просмотром вперед.
После завершения операции ввода/вывода целевой контроллер в случае свободы шины соединяется с главным адаптером, вслед за чем выполняется фаза данных (при передаче данных из целевого контроллера в главный адаптер) и фаза состояния для указания результата операции. Когда главный адаптер получает фазу состояния, он проверяет корректность завершения физической операции в целевом контроллере и соответствующим образом информирует операционную систему.
Одной из характеристик процесса ввода/вывода SCSI является большое количество шагов, которые обычно не видны пользователю. Обычно на шине SCSI происходит смена семи фаз (выбор, команда, разъединение, повторное соединение, данные, состояние, разъединение). Естественно каждая фаза выполняется за некоторое время, расходуемое на использование шины. Многие целевые контроллеры (особенно медленные устройства подобные магнитным лентам и компакт-дискам) потребляют значительную часть времени на реализацию фаз выбора, разъединения и повторного соединения.
Варианты применения высокопроизводительных подсистем ввода/вывода широко варьируются в зависимости от требований, которые к ним предъявляются. Они охватывают диапазон от обработки малого числа больших массивов данных, которые необходимо реализовать с минимальной задержкой (ввод/вывод суперкомпьютера), до большого числа простых заданий, которые оперируют с малыми объемами данных (обработка транзакций).
Запросы на ввод/вывод заданной рабочей нагрузки можно характеризовать в терминах трех метрик: производительность, время ожидания и пропускная способность. Производительность определяется числом запросов на обслуживание, получаемых в единицу времени. Время ожидания определяет время, необходимое на обслуживание индивидуального запроса. Пропускная способность определяет количество данных, передаваемых между устройствами, требующими обслуживания, и устройствами, выполняющими обслуживание.
Ввод/вывод суперкомпьютера почти полностью определяется последовательным механизмом. Обычно данные передаются с диска в память большими блоками, а результаты записываются обратно на диск. В таких применениях требуется высокая пропускная способность и минимальное время ожидания, однако они характеризуются низкой производительностью. В отличие от этого обработка транзакций характеризуется огромным числом случайных обращений, относительно небольшими отрезками работы и требует умеренного времени ожидания при очень высокой производительности.
Билет 13:
МЕТОДЫ ПЕРЕДАЧИ ИНФОРМАЦИИ МЕЖДУ УСТРОЙСТВАМИ ЭВМ
Используются два метода передачи дискретных сигналов: синхронный и асинхронный. При синхронном методе передающее устройство устанавливает одно из двух возможнных состояний сигнала (0 или 1) и поддерживает его в течение строго определенного интервала времени, после истечения которого состояние сигнала на передающей стороне может быть изменено.
Время передачи сигнала, которое складывается из времени передачи сигнала по линии и времени распознавания и фиксации сигнала в регистре приемного устройства, зависит от параметров линии связи и характеристик приемного и передающего устройств. Период синхронной передачи информации должен превышать максимальное время передачи сигнала. Он задается специальными тактовыми импульсами, как правило поступающими от тактового генератора с кварцевым резонатором.
При асинхронной передаче передающее устройство устанавливает соответствующее передаваемому коду состояние сигнала на информационной линии, а принимающее устройство после приема сигнала информирует об этом передающее устройство изменением состояния сигнала на линии подтверждения приема. Передающее устройство, получив сигнал подтверждения, снимает передаваемый сигнал.
Обычно при передаче сигналов на короткие расстояния (десятки сантиметров) более быстрым оказывается синхронный метод, а при передаче на большие расстояния - асинхронный.
При передаче параллельного кода по параллельным линиям сигналы поступят в приемное устройство в разное время из-за разброса параметров цепей, формирующих сигналы, и линий интерфейса (так называемая проблема состязаний).
Используется два метода передачи параллельного кода по нескольким линиям: со стробированием, использующим синхронную передачу, и с квитированием, в котором используется асинхронная передача.
При передаче со стробировением кроме N информационных линий используется линия "готовность данных": вначале устанавливаются значения передаваемых сигналов на информационных линиях, затем на линии готовности устанавливается уровень 1. Через строго определенный период времени (превышающий максимальное время передачи) сигнал готовности сбрасывается в 0, процесс передачи завершается, после чего можно изменить сигналы на информационных линиях и передавать следующую порцию данных.
При передаче с квитированием кроме N информационных линий и линии готовности данных используется линия подтверждения приема: вначале устанавливаются значения передаваемых сигналов на информационных линиях, затем на линии готовности устанавливается уровень 1. Приняв фронт сигнала готовности, приемное устройство считывает сигналы с информационных линий и посылает передатчику сигнал подтверждения приема. Приняв фронт сигнала подтверждения передатчик снимает сигнал готовности, после чего может приступать к передаче новой порции данных.
Параллельная передача данных
Параллельная передача данных между контроллером и ВУ является по своей организации наиболее простым способом обмена. Для организации параллельной передачи данных помимо шины данных, количество линий в которой равно числу одновременно передаваемых битов данных, используется минимальное количество управляющих сигналов.
В простом контроллере ВУ, обеспечивающем побайтную передачу данных на внешнее, в шине связи с ВУ используются всего два управляющих сигнала: "Выходные данные готовы" и "Данные приняты".
Для формирования управляющего сигнала "Выходные данные готовы" и приема из ВУ управляющего сигнала "Данные приняты" в контроллере используется одноразрядный адресуемый регистр состояния и управления А2 (обычно используются раздельные регистр состояния и регистр управления). Одновременно с записью очередного байта данных с шины данных системного интерфейса в адресуемый регистр данных контроллера (порт вывода А1) в регистр состояния и управления записывается логическая единица. Тем самым формируется управляющий сигнал "Выходные данные готовы" в шине связи с ВУ.
ВУ, приняв байт данных, управляющим сигналом "Данные приняты" обнуляет регистр состояния контроллера. При этом формируются управляющий сигнал системного интерфейса "Готовность ВУ" и признак готовности ВУ к обмену, передаваемый в процессор по одной из линий шины данных системного интерфейса посредством стандартной операции ввода при реализации программы асинхронного обмена.
Логика управления контроллера обеспечивает селекцию адресов регистров контроллера, прием управляющих сигналов системного интерфейса и формирование на их основе внутренних управляющих сигналов контроллера, формирование управляющего сигнала системного интерфейса "Готовность ВУ". Для сопряжения регистров контроллера с шинами адреса и данных системного интерфейса в контроллере используются соответственно приемники шины адреса и приемопередатчики шины данных.
Рассмотрим на примере, каким образом контроллер ВУ обеспечивает параллельную передачу данных в ВУ под управлением программы асинхронного обмена. Алгоритм асинхронного обмена в данном случае передачи прост.
1. Процессор микроЭВМ проверяет готовность ВУ к приему данных.
2. Если ВУ готово к приему данных (в данном случае это логический 0 в нулевом разряде регистра А2), то данные передаются с шины данных системного интерфейса в регистр данных А1 контроллера и далее в ВУ. Иначе повторяется п. 1.
Блок-схема простого контроллера ВУ, обеспечивающего побайтный прием данных из ВУ, приведена на рис. 3.6. В этом контроллере при взаимодействии с внешним устройством также используются два управляющих сигнала: "Данные от ВУ готовы" и "Данные приняты".

Рис. 3.6. Простой параллельный контроллер ввода
Для формирования управляющего сигнала "Данные приняты" и приема из ВУ управляющего сигнала " Данные от ВУ готовы" используется одноразрядный адресуемый регистр состояния и управления А2.
Внешнее устройство записывает в регистр данных контроллера А1 очередной байт данных и управляющим сигналом "Данные от ВУ готовы" устанавливает в единицу регистр состояния и управления А2.
При этом формируются: управляющий сигнал системного интерфейса "Готовность ВУ"; признак готовности ВУ к обмену, передаваемый в процессор по одной из линий шины данных системного интерфейса посредством операции ввода при реализации программы асинхронного обмена.
Тем самым контроллер извещает процессор о готовности данных в регистре А1. Процессор, выполняя программу асинхронного обмена, читает байт данных из регистра данных контроллера и обнуляет регистр состояния и управления А2. При этом формируется управляющий сигнал "Данные приняты" в шине связи с внешним устройством.
Логика управления контроллера и приемопередатчики шин системного интерфейса выполняют те же функции, что и в контроллере вывода.
Рассмотрим работу параллельного интерфейса ввода при реализации программы асинхронного обмена. Алгоритм асинхронного ввода так же прост, как и асинхронного вывода.
1. Процессор проверяет наличие данных в регистре данных контроллера А1.
2. Если данные готовы (логическая 1 в регистре А2), то они передаются из регистра данных А1 на шину данных системного интерфейса и далее в регистр процессора или ячейку памяти микрокомпьютера. Иначе повторяется п. 1.
Как видно из рассмотренных примеров, для приема или передачи одного байта данных процессору необходимо выполнить всего несколько команд, время выполнения которых и определяет максимально достижимую скорость обмена данными при параллельной передаче. Таким образом, при параллельной передаче обеспечивается довольно высокая скорость обмена данными, которая ограничивается только быстродействием ВУ.
Последовательная передача данных
Использование последовательных линий связи для обмена данными с внешними устройствами возлагает на контроллеры ВУ дополнительные по сравнению с контроллерами для параллельного обмена функции. Во-первых, возникает необходимость преобразования формата данных: из параллельного формата, в котором они поступают в контроллер ВУ из системного интерфейса микроЭВМ, в последовательный при передаче в ВУ и из последовательного в параллельный при приеме данных из ВУ. Во-вторых, требуется реализовать соответствующий режиму работы внешнего устройства способ обмена данными: синхронный или асинхронный.
Синхронный последовательный интерфейс
Простой контроллер для синхронной передачи данных в ВУ по последовательной линии связи (последовательный интерфейс) представлен на рис. 3.7.
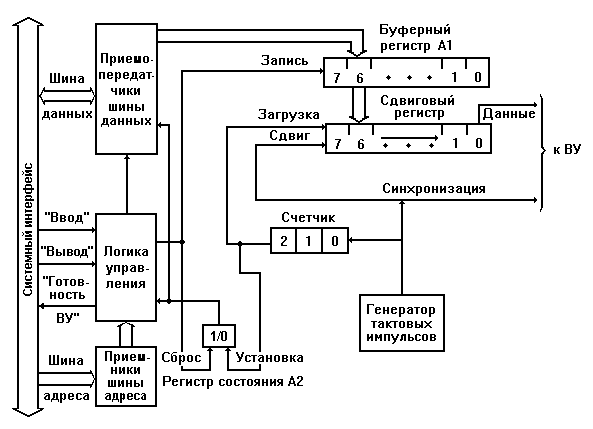
Восьмиразрядный адресуемый буферный регистр контроллера А1 служит для временного хранения байта данных до его загрузки в сдвиговый регистр. Запись байта данных в буферный регистр с шины данных системного интерфейса производится так же, как и в параллельном интерфейсе (см. Параллельная передача данных и рис. 3.5), только при наличии единицы в одноразрядном адресуемом регистре состояния контроллера А2. Единица в регистре состояния указывает на готовность контроллера принять очередной байт в буферный регистр. Содержимое регистра А2 передается в процессор по одной из линий шины данных системного интерфейса и используется для формирования управляющего сигнала системного интерфейса "Готовность ВУ". При записи очередного байта в буферный регистр A1 обнуляется регистр состояния А2. Программа записи байта данных в буферный регистр аналогична программе из примера 2.1 за исключением команды перехода: вместо команды JNZ m1 (переход, если не ноль) необходимо использовать команду JZ m1 (переход, если ноль). Преобразование данных из параллельного формата, в котором они поступили в буферный регистр контроллера из системного интерфейса, в последовательный и передача их на линию связи производятся в сдвиговом регистре с помощью генератора тактовых импульсов и двоичного трехразрядного счетчика импульсов следующим образом. Последовательная линия связи контроллера с ВУ подключается к выходу младшего разряда сдвигового регистра. По очередному тактовому импульсу содержимое сдвигового регистра сдвигается на один разряд вправо и в линию связи "Данные" выдается значение очередного разряда. Одновременно со сдвигом в ВУ передается по отдельной линии "Синхронизация" тактовый импульс. Таким образом, каждый передаваемый по линии "Данные" бит информации сопровождается синхронизирующим сигналом по линии "Синхронизация", что обеспечивает его однозначное восприятие на приемном конце последовательной линии связи. Количество переданных в линию тактовых сигналов, а следовательно, и переданных бит информации подсчитывается счетчиком тактовых импульсов. Как только содержимое счетчика становится равным 7, т. е. в линию переданы 8 бит (1 байт) информации, формируется управляющий сигнал "Загрузка", обеспечивающий запись в сдвиговый регистр очередного байта из буферного регистра. Этим же управляющим сигналом устанавливается в "1" регистр состояния. Очередным тактовым импульсом счетчик будет сброшен в "0", и начнется очередной цикл выдачи восьми битов информации из сдвигового регистра в линию связи. Синхронная последовательная передача отдельных битов данных на линию связи должна производиться без какого-либо перерыва, и следующий байт данных должен быть загружен в буферный регистр из системного интерфейса за время, не превышающее времени передачи восьми битов в последовательную линию связи. При записи байта данных в буферный регистр обнуляется регистр состояния контроллера. Нуль в этом регистре указывает, что в линию связи передается байт данных из сдвигового регистра, а следующий передаваемый байт данных загружен в сдвиговый регистр. Контроллер для последовательного синхронного приема данных из ВУ состоит из тех же компонентов, что и контроллер для синхронной последовательной передачи, за исключением генератора тактовых импульсов.
Асинхронный последовательный интерфейс
Организация асинхронного последовательного обмена данными с внешним устройством осложняется тем, что на передающей и приемной стороне последовательной линии связи используются настроенные на одну частоту, но физически разные генераторы тактовых импульсов и, следовательно, общая синхронизация отсутствует.
Обмен данными с ВУ по последовательным линиям связи широко используется в микроЭВМ, особенно в тех случаях, когда не требуется высокой скорости обмена. Вместе с тем применение в них последовательных линий связи с ВУ обусловлено двумя важными причинами. Во-первых, последовательные линии связи просты по своей организации: два провода при симплексной и полудуплексной передаче и максимум четыре - при дуплексной. Во-вторых, в микроЭВМ используются внешние устройства, обмен с которыми необходимо вести в последовательном коде. В современных микроЭВМ применяют, как правило, универсальные контроллеры для последовательного ВВ, обеспечивающие как синхронный, так и асинхронный режим обмена данными с ВУ.
Билет 14:
Прерывания:
Весьма важной частью ВС, обеспечивающей многопрограммность ее работы, является система прерывания программы. Система прерываний реализуется программно и аппаратно. Ее программные блоки в основном входят в ОС. Назначение системы прерывания состоит в том, что если по ходу работы ВС возникает необходимость выполнить срочную работу, не входящую в выполняемую в этот момент программу, то выполнение программы приостанавливается, включается подпрограмма требуемой работы и после ее выполнения вновь восстанавливается работа прерванной программы. Для этого при прерывании основной программы состояние всех основных регистров, в том числе и следующей команды основной программы, запоминается. После этого управление передается подпрограмме ОС, обрабатывающей прерывание. В конце подпрограммы ОС помещены команды, восстанавливающие состояние ВС перед прерыванием, и последней командой управление вновь передается основной программе. По сути, организация взаимодействия основной программы и подпрограммы обработки прерывания не отличается от организации обращения к библиотечной подпрограмме и выхода из нее. Только в случае библиотечной подпрограммы инициатива исходит от основной программы, а при прерывании - от аппаратно (или программно) выставляемого сигнала прерывания.
Прерывания делятся на внутренние и внешние. Внешние прерывания поступают от периферийных устройств, периферийных процессоров, таймера и пультовой машины на внешний регистр прерывания и, как правило, фиксируют статус внешнего устройства, например, завершение обмена с ВУ. Внутренние сигналы прерывания вырабатываются при возникновении аппаратных сбоев внутри процессора, при программных ошибках и в ряде специальных случаев. К конкретным причинам внутренних прерываний относятся: запрещенные команды в различных режимах, некомандный тег на РК, экстракод, переполнение сумматора АУ, ошибки памяти, совпадение адреса записи или чтения в Р+А с заданным и т.д. и т.п. Сигналы внутреннего прерывания имеют приоритет перед сигналами внешнего прерывания и блокируют дальнейшее выполнение программы Схемы, фиксирующие сбой/ошибку/статус устанавливают соответствующие разряды регистра внутренних или внешних прерываний в состояние "1".
Собственно обработка прерывания заключается в прерывании выполнения текущей команды, запоминании признаков режимов работы программы (состояние процессора) в специальных регистрах процессора и переходу на программу анализа причины прерывания (анализ регистра прерывания) и дальнейшей обработки прерывания. Операция прерывания начинается при довыполнении команд на всех уровнях конвейера ниже того уровня, где образуется прерывание. В зависимости от типа прерывания аппаратная передача управления (занесение кода на СчК) происходит по различным адресам. А уж в ячейках по этим адресам памяти находятся опять команды передачи управления, но на нужные программы последующей обработки прерывания. Этим достигается независимость аппаратных средств от типа устанавливаемой операционной системы. В большинстве вычислительных систем имеется также программно доступный регистр маски прерываний. Он позволяет блокировать формирование некоторых сигналов прерываний и используется для программного способа установления приоритетами прерываний, особенно важного для вычислительных систем, работающих в реальном времени.
Способы обмена информацией в микропроцессорной системе
В ЭВМ применяются три режима ввода/вывода: программно-управляемый ВВ (называемый также программным или нефорсированным ВВ), ВВ по прерываниям (форсированный ВВ) и прямой доступ к памяти. Первый из них характеризуется тем, что инициирование и управление ВВ осуществляется программой, выполняемой процессором, а внешние устройства играют сравнительно пассивную роль и сигнализируют только о своем состоянии, в частности, о готовности к операциям ввода/вывода. Во втором режиме ВВ инициируется не процессором, а внешним устройством, генерирующим специальный сигнал прерывания. Реагируя на этот сигнал готовности устройства к передаче данных, процессор передает управление подпрограмме обслуживания устройства, вызвавшего прерывание. Действия, выполняемые этой подпрограммой, определяются пользователем, а непосредственными операциями ВВ управляет процессор. Наконец, в режиме прямого доступа к памяти, который используется, когда пропускной способности процессора недостаточно, действия процессора приостанавливаются, он отключается от системной шины и не участвует в передачах данных между основной памятью и быстродействующим ВУ. Заметим, что во всех вышеуказанных случаях основные действия, выполняемые на системной магистрали ЭВМ, подчиняются двум основным принципам.
1. В процессе взаимодействия любых двух устройств ЭВМ одно из них обязательно выполняет активную, управляющую роль и является задатчиком, второе оказывается управляемым, исполнителем. Чаще всего задатчиком является процессор.
2. Другим важным принципом, заложенным в структуру интерфейса, является принцип квитирования (запроса - ответа): каждый управляющий сигнал, посланный задатчиком, подтверждается сигналом исполнителя. При отсутствии ответного сигнала исполнителя в течение заданного интервала времени формируется так называемый тайм-аут, задатчик фиксирует ошибку обмена и прекращает данную операцию.
+ Еще можно заглянуть в билет 12…
Билет 15:
Классификация систем параллельной обработки данных
На протяжении всей истории развития вычислительной техники делались попытки найти какую-то общую классификацию, под которую подпадали бы все возможные направления развития компьютерных архитектур. Ни одна из таких классификаций не могла охватить все разнообразие разрабатываемых архитектурных решений и не выдерживала испытания временем. Тем не менее в научный оборот попали и широко используются ряд терминов, которые полезно знать не только разработчикам, но и пользователям компьютеров.
Любая вычислительная система (будь то супер-ЭВМ или персональный компьютер) достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы (работы с перекрытием) является основой ускорения основных операций.
Параллельные ЭВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных). Как и любая другая, приведенная выше классификация несовершенна: существуют машины прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. В частности, к машинам типа SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма - конвейерной организации машины. Многопроцессорные векторные системы, типа Cray Y-MP, состоят из нескольких векторных процессоров и поэтому могут быть названы MSIMD (Multiple SIMD).
Состав процессора:
Устройство управления является функционально наиболее сложным устройством ПК. Оно вырабатывает управляющие сигналы, поступающие по кодовым шинам инструкций во все блоки машины.
Постоянное запоминающее устройство микропрограмм - хранит в своих ячейках управляющие сигналы (импульсы), необходимые для выполнения в блоках ПК операций обработки информации. Импульс по выбранному дешифратором операций в соответствии с кодом операции считывает из ПЗУ микропрограмм необходимую последовательность управляющих сигналов.
Узел формирования адреса (находится в интерфейсной части МП) - устройство, вычисляющее полный адрес ячейки памяти (регистра) по реквизитам, поступающим из регистра команд и регистров МПП.
Кодовые шины данных, адреса и инструкций - часть внутренней интерфейсной шины микропроцессора. В общем случае УУ формирует управляющие сигналы для выполнения следующих основных процедур:
выборки из регистра-счетчика адреса команды МПП адреса ячейки ОЗУ, где хранится очередная команда программы;
выборки из ячеек ОЗУ кода очередной команды и приема считанной команды в регистр команд;
расшифровки кода операции и признаков выбранной команды;
считывания из соответствующих расшифрованному коду операции ячеек ПЗУ микропрограмм управляющих сигналов (импульсов), определяющих во всех блоках машины процедуры выполнения заданной операции, и пересылки управляющих сигналов в эти блоки;
считывания из регистра команд и регистров МПП отдельных составляющих адресов операндов (чисел), участвующих в вычислениях, и формирования полных адресов операндов;
выборки операндов (по сформированным адресам) и выполнения заданной операции обработки этих операндов;
записи результатов операции в память;
формирования адреса следующей команды программы.
Арифметико-логическое устройство
Арифметико-логическое устройство предназначено для выполнения арифметических и логических операций преобразования информации.
Функционально АЛУ состоит обычно из двух регистров, сумматора и схем управления (местного устройства управления).
Сумматор - вычислительная схема, выполняющая процедуру сложения поступающих на ее вход двоичных кодов; сумматор имеет разрядность двойного машинного слова.
Регистры - быстродействующие ячейки памяти различной длины: регистр 1 (Рг1) имеет разрядность двойного слова, а регистр 2 (Рг2) - разрядность слова.
При выполнении операций в Рг1 помещается первое число, участвующее в операции, а по завершении операции - результат; в Рг2 - второе число, участвующее в операции (по завершении операции информация в нем не изменяется). Регистр 1 может и принимать информацию с кодовых шин данных, н выдавать информацию на них, регистр 2 только получает информацию с этих шин.
Схемы управления принимают по кодовым шинам инструкций управляющие сигналы от устройства управления и преобразуют их в сигналы для управления работой регистров и сумматора АЛУ.
АЛУ выполняет арифметические операции (+, -, *,:) только над двоичной информацией с запятой, фиксированной после последнего разряда, т.е. только над целыми двоичными числами.
Выполнение операций над двоичными числами с плавающей запятой и над двоично-кодированными десятичными числами осуществляется или с привлечением математического сопроцессора, или по специально составленным программам.
Микропроцессорная память
Микропроцессорная память - память небольшой емкости, но чрезвычайно высокого быстродействия (время обращения к МПП, т.е. время, необходимое на поиск, запись или считывание информации из этой памяти, измеряется наносекундами - тысячными долями микросекунды).
Она предназначена для кратковременного хранения, записи и выдачи информации, непосредственно в ближайшие такты работы машины участвующей в вычислениях, МПП используется для обеспечения высокого быстродействия машины, ибо основная память не всегда обеспечивает скорость записи, поиска и считывания информации, необходимую для эффективной работы быстродействующего микропроцессора.
Микропроцессорная память состоит из быстродействующих регистров с разрядностью не менее машинного слова. Количество и разрядность регистров в разных микропроцессорах различны: от 14 двухбайтных регистров у МП 8086 до нескольких десятков регистров разной длины у МП Pentium.
Регистры микропроцессора делятся на регистры общего назначения и специальные.
Специальные регистры применяются для хранения различных адресов (адреса команды, например), признаков результатов выполнения операций и режимов работы ПК (регистр флагов, например) и др.
Регистры общего назначения являются универсальными и могут использоваться для хранения любой информации, но некоторые из них тоже должны быть обязательно задействованы при выполнении ряда процедур.
Интерфейсная часть микропроцессора
Интерфейсная часть МП предназначена для связи и согласования МП с системной шиной ПК, а также для приема, предварительного анализа команд выполняемой программы и формирования полных адресов операндов и команд.
Интерфейсная часть включает в свой состав адресные регистры МПП, узел формирования адреса, блок регистров команд, являющийся буфером команд в МП, внутреннюю интерфейсную шину МП и схемы управления шиной и портами ввода-вывода.
Порты ввода-вывода - это пункты системного интерфейса ПК, через которые - это пункты системного интерфейса ПК, через которые МП обменивается информацией с другими устройствами. Всего портов у МП может быть 65536. Каждый порт имеет адрес - номер порта, соответствующий адресу ячейки памяти, являющейся частью устройства ввода-вывода, использующего этот порт, а не частью основной памяти компьютера.
Порт устройства содержит аппаратуру сопряжения и два регистра памяти - для обмена данными и обмена управляющей информацией. Некоторые внешние устройства используют и основную память для хранения больших объемов информации, подлежащей обмену. Многие стандартные устройства (НЖМД, НГМД, клавиатура, принтер, сопроцессор и др.) имеют постоянно закрепленные за ними порты ввода-вывода.
Схема управления шиной и портами выполняет следующие функции:
формирование адреса порта и управляющей информации для него (переключение порта на прием или передачу и др.);
прием управляющей информации от порта, информации о готовности порта и его состоянии;
организацию сквозного канала в системном интерфейсе для передачи данных между портом устройства ввода-вывода и МП.
ПОСЛЕДОВАТЕЛЬНОСТЬ РАБОТЫ БЛОКОВ ПК
Программа хранится во внешней памяти ПК. При запуске программы в работу пользователь выдает запрос на ее исполнение в дисковую операционную систему (DOS - Disk Operation System) компьютера. Запрос пользователя - это ввод имени исполняемой программы в командную строку на экране дисплея. Главная программа DOS - Command.com (см. гл. 9) обеспечивает перезапись машинной (исполняемой) программы из внешней памяти в ОЗУ и устанавливает в регистре-счетчике адреса команд микропроцессорной памяти адрес ячейки ОЗУ, в которой находится начало (первая команда) этой программы.
После этого автоматически начинается выполнение команд программы друг за другом. Каждая команда требует для своего исполнения нескольких тактов работы машины (такты определяются периодом следования импульсов от генератора тактовых импульсов) В первом такте выполнения любой команды производятся считывание кода самой команды из ОЗУ по адресу, установленному в регистре-счетчике адреса, и запись этого кода в блок регистров команд устройства управления. Содержание второго и последующих тактов исполнения определяется результатами анализа команды, записанной в блок регистров команд, т.е. зависит уже от конкретной команды.
Пример 4.15. При выполнении ранее рассмотренной машинной команды
СЛ |
0103 |
5102 |
будут выполнены следующие действия:
• второй такт: считывание из ячейки 0103 ОЗУ первого слагаемого и перемещение его в AЛV;
• третий такт: считывание из ячейки 5102 ОЗУ второго слагаемого и перемещение его в АЛУ;
• четвертый такт: сложение в АЛУ переданных чуда чисел и формирование суммы;
• пятый такт: считывание из АЛУ суммы чисел и запись ее в ячейку 0103 ОЗУ.
В конце последнего (в данном случае пятого) такта выполнения команды в регистр-счетчик адреса команд МПП будет добавлено число, равное количеству байтов, занимаемых кодом выполненной команды программы. Поскольку емкость одной ячейки памяти ОЗУ равна 1 байту и команды программы в ОЗУ размещены последовательно друг за другом, в регистре-счетчике адреса команд будет сформирован адрес следующей команды машинной программы, и машина приступит к ее исполнению и т.д. Команды будут выполняться последовательно одни за другой, пока не завершится вся программа. После завершения программы управление будет передано обратно в программу Command.com операционной системы.
Билет 16:
Суперскалярный процессор представляет собой нечто большее, чем обычный последовательный (скалярный) процессор. В отличие от последнего, он может выполнять несколько операций за один такт. Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств. В исполняющих устройствах могут быть конвейеры. Суперскалярные процессоры реализуют параллелизм на уровне команд.
Примером компьютера с суперскалярным процессором является IBM RISC/6000. Тактовая частота процессора у ЭВМ была 62.5 МГц, а быстродействие системы на вычислительных тестах достигало 104 Mflop (Mflop - единица измерения быстродействия процессора - миллион операций с плавающей точкой в секунду). Суперскалярный процессор не требует специальных векторизующих компиляторов, хотя компилятор должен в этом случае учитывать особенности архитектуры.
Методы минимизации приостановок работы конвейера из-за наличия в программах логических зависимостей по данным и по управлению, рассмотренные в предыдущих разделах, были нацелены на достижение идеального CPI (среднего количества тактов на выполнение команды в конвейере), равного 1. Чтобы еще больше повысить производительность процессора необходимо сделать CPI меньшим, чем 1. Однако этого нельзя добиться, если в одном такте выдается на выполнение только одна команда. Следовательно необходима параллельная выдача нескольких команд в каждом такте. Существуют два типа подобного рода машин: суперскалярные машины и VLIW-машины (машины с очень длинным командным словом). Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором.
Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. Возросшая сложность, реализуемая этими механизмами, создает также проблемы реализации точного прерывания.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до восьми команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Предположим, что машина может выдавать на выполнение две команды в одном такте. Одной из таких команд может быть команда загрузки регистров из памяти, записи регистров в память, команда переходов, операции целочисленного АЛУ, а другой может быть любая операция плавающей точки. Параллельная выдача целочисленной операции и операции с плавающей точкой намного проще, чем выдача двух произвольных команд. В реальных системах (например, в микропроцессорах PA7100, hyperSPARC, Pentium и др.) применяется именно такой подход. В более мощных микропроцессорах (например, MIPS R10000, UltraSPARC, PowerPC 620 и др.) реализована выдача до четырех команд в одном такте.
Выдача двух команд в каждом такте требует одновременной выборки и декодирования по крайней мере 64 бит. Чтобы упростить декодирование можно потребовать, чтобы команды располагались в памяти парами и были выровнены по 64-битовым границам. В противном случае необходимо анализировать команды в процессе выборки и, возможно, менять их местами в момент пересылки в целочисленное устройство и в устройство ПТ. При этом возникают дополнительные требования к схемам обнаружения конфликтов. В любом случае вторая команда может выдаваться, только если может быть выдана на выполнение первая команда. Аппаратура принимает такие решения в динамике, обеспечивая выдачу только первой команды, если условия для одновременной выдачи двух команд не соблюдаются. На рисунке 3.18 представлена диаграмма работы подобного конвейера в идеальном случае, когда в каждом такте на выполнение выдается пара команд.
Такой конвейер позволяет существенно увеличить скорость выдачи команд. Однако чтобы он смог так работать, необходимо иметь либо полностью конвейеризованные устройства плавающей точки, либо соответствующее число независимых функциональных устройств. В противном случае устройство плавающей точки станет узким горлом и эффект, достигнутый за счет выдачи в каждом такте пары команд, сведется к минимуму.
Рис. 3.18. Работа суперскалярного конвейера
При параллельной выдаче двух операций (одной целочисленной команды и одной команды ПТ) потребность в дополнительной аппаратуре, помимо обычной логики обнаружения конфликтов, минимальна: целочисленные операции и операции ПТ используют разные наборы регистров и разные функциональные устройства. Более того, усиление ограничений на выдачу команд, которые можно рассматривать как специфические структурные конфликты (поскольку выдаваться на выполнение могут только определенные пары команд), обнаружение которых требует только анализа кодов операций. Единственная сложность возникает, только если команды представляют собой команды загрузки, записи и пересылки чисел с плавающей точкой. Эти команды создают конфликты по портам регистров ПТ, а также могут приводить к новым конфликтам типа RAW, когда операция ПТ, которая могла бы быть выдана в том же такте, является зависимой от первой команды в паре.
Проблема регистровых портов может быть решена, например, путем реализации отдельной выдачи команд загрузки, записи и пересылки с ПТ. В случае составления ими пары с обычной операцией ПТ ситуацию можно рассматривать как структурный конфликт. Такую схему легко реализовать, но она будет иметь существенное воздействие на общую производительность. Конфликт подобного типа может быть устранен посредством реализации в регистровом файле двух дополнительных портов (для выборки и записи).
Если пара команд состоит из одной команды загрузки с ПТ и одной операции с ПТ, которая от нее зависит, необходимо обнаруживать подобный конфликт и блокировать выдачу операции с ПТ. За исключением этого случая, все другие конфликты естественно могут возникать, как и в обычной машине, обеспечивающей выдачу одной команды в каждом такте. Для предотвращения ненужных приостановок могут, правда потребоваться дополнительные цепи обхода.
Другой проблемой, которая может ограничить эффективность суперскалярной обработки, является задержка загрузки данных из памяти. В нашем примере простого конвейера команды загрузки имели задержку в один такт, что не позволяло следующей команде воспользоваться результатом команды загрузки без приостановки. В суперскалярном конвейере результат команды загрузки не может быть использован в том же самом и в следующем такте. Это означает, что следующие три команды не могут использовать результат команды загрузки без приостановки. Задержка перехода также становится длиною в три команды, поскольку команда перехода должна быть первой в паре команд. Чтобы эффективно использовать параллелизм, доступный на суперскалярной машине, нужны более сложные методы планирования потока команд, используемые компилятором или аппаратными средствами, а также более сложные схемы декодирования команд.
В лучшем случае суперскалярный конвейер позволит выбирать две команды и выдавать их на выполнение, если первая из них является целочисленной, а вторая - с плавающей точкой. Если это условие не соблюдается, что легко проверить, то команды выдаются последовательно. Это показывает два главных преимущества суперскалярной машины по сравнению с WLIW-машиной. Во-первых, малое воздействие на плотность кода, поскольку машина сама определяет, может ли быть выдана следующая команда, и нам не надо следить за тем, чтобы команды соответствовали возможностям выдачи. Во-вторых, на таких машинах могут работать неоптимизированные программы, или программы, откомпилированные в расчете на более старую реализацию. Конечно такие программы не могут работать очень хорошо. Один из способов улучшить ситуацию заключается в использовании аппаратных средств динамической оптимизации.
В общем случае в суперскалярной системе команды могут выполняться параллельно и возможно не в порядке, предписанном программой. Если не предпринимать никаких мер, такое неупорядоченное выполнение команд и наличие множества функциональных устройств с разными временами выполнения операций могут приводить к дополнительным трудностям. Например, при выполнении некоторой длинной команды с плавающей точкой (команды деления или вычисления квадратного корня) может возникнуть исключительная ситуация уже после того, как завершилось выполнение более быстрой операции, выданной после этой длинной команды. Для того, чтобы поддерживать модель точных прерываний, аппаратура должна гарантировать корректное состояние процессора при прерывании для организации последующего возврата.
Обычно в машинах с неупорядоченным выполнением команд предусматриваются дополнительные буферные схемы, гарантирующие завершение выполнения команд в строгом порядке, предписанном программой. Такие схемы представляют собой некоторый буфер "истории", т.е. аппаратную очередь, в которую при выдаче попадают команды и текущие значения регистров результата этих команд в заданном программой порядке.
В момент выдачи команды на выполнение она помещается в конец этой очереди, организованной в виде буфера FIFO (первый вошел - первый вышел). Единственный способ для команды достичь головы этой очереди - завершение выполнения всех предшествующих ей операций. При неупорядоченном выполнении некоторая команда может завершить свое выполнение, но все еще будет находиться в середине очереди. Команда покидает очередь, когда она достигает головы очереди и ее выполнение завершается в соответствующем функциональном устройстве. Если команда находится в голове очереди, но ее выполнение в функциональном устройстве не закончено, она очередь не покидает. Такой механизм может поддерживать модель точных прерываний, поскольку вся необходимая информация хранится в буфере и позволяет скорректировать состояние процессора в любой момент времени.
Этот же буфер "истории" позволяет реализовать и условное (speculative) выполнение команд (выполнение по предположению), следующих за командами условного перехода. Это особенно важно для повышения производительности суперскалярных архитектур. Статистика показывает, что на каждые шесть обычных команд в программах приходится в среднем одна команда перехода. Если задерживать выполнение следующих за командой перехода команд, потери на конвейеризацию могут оказаться просто неприемлемыми. Например, при выдаче четырех команд в одном такте в среднем в каждом втором такте выполняется команда перехода. Механизм условного выполнения команд, следующих за командой перехода, позволяет решить эту проблему. Это условное выполнение обычно связано с последовательным выполнением команд из заранее предсказанной ветви команды перехода. Устройство управления выдает команду условного перехода, прогнозирует направление перехода и продолжает выдавать команды из этой предсказанной ветви программы.
Если прогноз оказался верным, выдача команд так и будет продолжаться без приостановок. Однако если прогноз был ошибочным, устройство управления приостанавливает выполнение условно выданных команд и, если необходимо, использует информацию из буфера истории для ликвидации всех последствий выполнения условно выданных команд. Затем начинается выборка команд из правильной ветви программы. Таким образом, аппаратура, подобная буферу, истории позволяет не только решить проблемы с реализацией точного прерывания, но и обеспечивает увеличение производительности суперскалярных архитектур.
Архитектура машин с длинным командным словом
Архитектура машин с очень длинным командным словом (VLIW - Very Long Instruction Word) позволяет сократить объем оборудования, требуемого для реализации параллельной выдачи нескольких команд, и потенциально чем большее количество команд выдается параллельно, тем больше эта экономия. Например, суперскалярная машина, обеспечивающая параллельную выдачу двух команд, требует параллельного анализа двух кодов операций, шести полей номеров регистров, а также того, чтобы динамически анализировалась возможность выдачи одной или двух команд и выполнялось распределение этих команд по функциональным устройствам. Хотя требования по объему аппаратуры для параллельной выдачи двух команд остаются достаточно умеренными, и можно даже увеличить степень распараллеливания до четырех (что применяется в современных микропроцессорах), дальнейшее увеличение количества выдаваемых параллельно для выполнения команд приводит к нарастанию сложности реализации из-за необходимости определения порядка следования команд и существующих между ними зависимостей.
Архитектура VLIW базируется на множестве независимых функциональных устройств. Вместо того, чтобы пытаться параллельно выдавать в эти устройства независимые команды, в таких машинах несколько операций упаковываются в одну очень длинную команду. При этом ответственность за выбор параллельно выдаваемых для выполнения операций полностью ложится на компилятор, а аппаратные средства, необходимые для реализации суперскалярной обработки, просто отсутствуют.
WLIW-команда может включать, например, две целочисленные операции, две операции с плавающей точкой, две операции обращения к памяти и операцию перехода. Такая команда будет иметь набор полей для каждого функционального устройства, возможно от 16 до 24 бит на устройство, что приводит к команде длиною от 112 до 168 бит.
Для машин с VLIW-архитектурой был разработан новый метод планирования выдачи команд, названный "трассировочным планированием". При использовании этого метода из последовательности исходной программы генерируются длинные команды путем просмотра программы за пределами базовых блоков. Как уже отмечалось, базовый блок - это линейный участок программы без ветвлений.
С точки зрения архитектурных идей машину с очень длинным командным словом можно рассматривать как расширение RISC-архитектуры. Как и в RISC-архитектуре аппаратные ресурсы VLIW-машины предоставлены компилятору, и ресурсы планируются статически. В машинах с очень длинным командным словом к этим ресурсам относятся конвейерные функциональные устройства, шины и банки памяти. Для поддержки высокой пропускной способности между функциональными устройствами и регистрами необходимо использовать несколько наборов регистров. Аппаратное разрешение конфликтов исключается и предпочтение отдается простой логике управления. В отличие от традиционных машин регистры и шины не резервируются, а их использование полностью определяется во время компиляции.
В машинах типа VLIW, кроме того, этот принцип замены управления во время выполнения программы планированием во время компиляции распространен на системы памяти. Для поддержания занятости конвейерных функциональных устройств должна быть обеспечена высокая пропускная способность памяти. Одним из современных подходов к увеличению пропускной способности памяти является использование расслоения памяти. Однако в системе с расслоенной памятью возникает конфликт банка, если банк занят предыдущим обращением. В обычных машинах состояние занятости банков памяти отслеживается аппаратно и проверяется, когда выдается команда, выполнение которой связано с обращением к памяти. В машине типа VLIW эта функция передана программным средствам. Возможные конфликты банков определяет специальный модуль компилятора - модуль предотвращения конфликтов.
Обнаружение конфликтов не является задачей оптимизации, это скорее функция контроля корректности выполнения операций. Компилятор должен быть способен определять, что конфликты невозможны или, в противном случае, допускать, что может возникнуть наихудшая ситуация. В определенных ситуациях, например, в том случае, когда производится обращение к массиву, а индекс вычисляется во время выполнения программы, простого решения здесь нет. Если компилятор не может определить, что конфликт не произойдет, операции не могут планироваться для параллельного выполнения, а это ведет к снижению производительности.
Компилятор с трассировочным планированием определяет участок программы без обратных дуг (переходов назад), которая становится кандидатом для составления расписания. Обратные дуги обычно имеются в программах с циклами. Для увеличения размера тела цикла широко используется методика раскрутки циклов, что приводит к образованию больших фрагментов программы, не содержащих обратных дуг. Если дана программа, содержащая только переходы вперед, компилятор делает эвристическое предсказание выбора условных ветвей. Путь, имеющий наибольшую вероятность выполнения (его называют трассой), используется для оптимизации, проводимой с учетом зависимостей по данным между командами и ограничений аппаратных ресурсов. Во время планирования генерируется длинное командное слово. Все операции длинного командного слова выдаются одновременно и выполняются параллельно.
После обработки первой трассы планируется следующий путь, имеющий наибольшую вероятность выполнения (предыдущая трасса больше не рассматривается). Процесс упаковки команд последовательной программы в длинные командные слова продолжается до тех пор, пока не будет оптимизирована вся программа.
Ключевым условием достижения эффективной работы VLIW-машины является корректное предсказание выбора условных ветвей. Отмечено, например, что прогноз условных ветвей для научных программ часто оказывается точным. Возвраты назад имеются во всех итерациях цикла, за исключением последней. Таким образом, "прогноз", который уже дается самими переходами назад, будет корректен в большинстве случаев. Другие условные ветви, например ветвь обработки переполнения и проверки граничных условий (выход за границы массива), также надежно предсказуемы.
Аппаратные средства поддержки большой степени распараллеливания
Методы, подобные разворачиванию циклов и планированию трасс, могут использоваться для увеличения степени доступного параллелизма, когда поведение условных переходов достаточно предсказуемо во время компиляции. Если же поведение переходов не известно, одной техники компиляторов может оказаться не достаточно для выявления большей степени параллелизма уровня команд. Существуют два метода, которые могут помочь преодолеть подобные ограничения. Первый метод заключается в расширении набора команд условными или предикатными командами. Такие команды могут использоваться для ликвидации условных переходов и помогают компилятору перемещать команды через точки условных переходов. Условные команды увеличивают степень параллелизма уровня команд, но имеют существенные ограничения. Для использования большей степени параллелизма разработчики исследовали идею, которая называется "выполнением по предположению" (speculation), и позволяет выполнить команду еще до того, как процессор узнает, что она должна выполняться (т.е. этот метод позволяет избежать приостановок конвейера, связанных с зависимостями по управлению).
Билет 17:
Машины типа SIMD. Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
SIMD компьютеры
SIMD компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами. Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах. Каждый процессорный элемент имеет свою собственную память для хранения данных. Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD компьютере управление выполняется контроллером, а "арифметика" отдана процессорным элементам.
Векторные компьютеры представляют собой пример архитектуры SIMD.
Векторная обработка данных
Векторный процессор "умеет" обрабатывать одной командой не одно единственное значение, а сразу массив (вектор) значений. Пусть A1, A2 и P - это три массива, имеющие одинаковую размерность и одинаковую длину, и имеется оператор P=A1+A2. Векторный процессор за один цикл выполнения команды выполнит попарное сложение элементов массивов A1 и A2 и присвоит полученные значения соответствующим элементам массива P. Каждый операнд при этом хранится в особом, векторном регистре. Обычному, последовательному процессору пришлось бы несколько раз выполнять операцию сложения элементов двух массивов. Векторный процессор выполняет лишь одну команду! Разумеется, реализация такой команды будет более сложной, более подробное обсуждение этой проблемы содержится в третьей главе настоящего учебника. Очевидно, за счет векторизации можно надеяться (мы не случайно делаем здесь эту оговорку) получить высокую производительность. Кроме того, векторным ЭВМ присущи и другие интересные особенности. Количество команд, необходимых для выполнения одной и той же программы, использующей векторизуемые операции, меньше в случае векторного процессора, чем обычного, скалярного. Уменьшение потока команд позволяет снизить требования к устройствам коммуникации, в том числе между процессором и оперативной памятью компьютера. Другой момент заключается в том, что при соответствующей организации оперативной памяти данные в процессор будут передаваться на каждом такте, что дает значительный выигрыш в производительности компьютера.
Следует заметить, что именно векторные ЭВМ были первыми высокопроизводительными компьютерами (мы упоминали уже векторный компьютер С.Крэя) и традиционно именно ЭВМ с векторной архитектурой называются суперкомпьютерами.
Билет 18:
MISD компьютеры
Вычислительных машин такого класса практически нет и трудно привести пример их успешной реализации. Один из немногих - систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки, роль ребер которой играют межпроцессорные соединения. Все процессорные элементы управляются общим тактовым генератором. В каждом цикле работы каждый процессорный элемент получает данные от своих соседей, выполняет одну команду и передает результат соседям.
Билет 19:
Машины типа MIMD. Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов. Процессорные элементы, конечно, должны как-то связываться друг с другом, что делает необходимым более подробную классификацию машин типа MIMD. В мультипроцессорах с общей памятью (сильносвязанных мультипроцессорах) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ждет своих входных данных (операндов), которые должны быть переданы ей другими процессами. По их получении операция выполняется, и полученное значение передается тем процессам, которые в нем нуждаются. В потоковых моделях вычислений с большим и средним уровнем гранулярности, процессы содержат большое число операций и выполняются в потоковой манере.
MIMD компьютеры: Эта категория архитектур вычислительных машин наиболее богата, если иметь в виду примеры ее успешных реализаций. В нее попадают симметричные параллельные вычислительные системы, рабочие станции с несколькими процессорами, кластеры рабочих станций и т.д. Уже довольно давно появились компьютеры с несколькими независимыми процессорами, но вначале на таких компьютерах был реализован только параллелизм заданий, то есть на разных процессорах одновременно выполнялись разные и независимые программы. Разработке первых компьютеров для параллельных вычислений были посвящены проекты под условным названием CM* и C.MMP в университете Карнеги (США). Технической базой для этих проектов были процессоры DEC PDP-11. В начале 90-х годов именно MIMD компьютеры выходят в лидеры на рынке высокопроизводительных вычислительных систем.
Идея параллелизма, как средства увеличения быстродействия ЭВМ, возникла очень давно - еще в 19-м веке. Принято выделять четыре уровня параллелизма:
Параллелизм заданий - каждый процессор загружается своей собственной независимой от других вычислительной задачей. Параллелизм такого типа представляет интерес скорее для системных администраторов, чем рядовых пользователей;
Параллелизм на уровне программы - вычислительная программа разбивается на части, которые могут выполняться одновременно на различных процессорах;
Параллелизм команд - обычно реализован на низком уровне, это, например, конвейеры и т.д.;
Параллелизм на уровне машинных слов и арифметических операций - в некоторых ситуациях, например, сложение двух операндов выполняется одновременным сложением всех их двоичных разрядов.
Транспьютер - микропроцессор сети со встроенными средствами связи.
Линии связи транспьютера
Транспьютер включает в себя 4 быстродействующих двунаправленных последовательных линии связи. Каждая линия состоит из входного и выходного каналов. Обмен данными может идти одновременно по всем четырем линиям связи параллельно с работой процессора. Связь между двумя транспьютерами реализуется соединением интерфейса связи одного транспьютера с интерфейсом связи другого транспьютера.
Сообщения пересылаются в виде последовательности байт. Для каждого байта формируется и передается следующий пакет данных:
1 |
1 |
бит 0 |
бит 1 |
бит 2 |
бит 3 |
бит 4 |
бит 5 |
бит 6 |
бит 7 |
0 |
После передачи пакета передающий транспьютер ожидает подтверждения приема данных. Сигнал подтверждения приема представляет собой двух битовый пакет, указывающий на то, что принимающий транспьютер готов к получению очередного байта:
1 |
0 |
Принимающий транспьютер посылает сигнал подтверждения приема одновременно с началом приема пакета данных.
Линии связи транспьютера IMS T805 поддерживают стандартную для фирмы INMOS скорость коммуникации в 10 Мбит/с. Кроме этого они могут работать при скорости 5 и 20 Мбит/с. Скорости линий устанавливаются с помощью 3-х линий Выбора Скорости Каналов (LinkSpecial, Link0Special, LinkSpecial123). Скорость линии 0 может устанавливаться независимо от скоростей линий 1,2,3. В следующей таблице показаны скорости передачи данных из внутренней памяти по линиям связи в одном и двух направлениях.
Скорость линии связи (Мбит/с) |
Скорость передачи данных в одном направлении (Кбайт/с) |
Скорость передачи данных в двух направлениях (Кбайт/с) |
5 |
450 |
670 |
10 |
910 |
1250 |
20 |
1740 |
2350 |
Память транспьютера
Транспьютер IMS T805 имеет 4К быстрой внутренней памяти для высокоскоростной работы с данными. Время доступа к ней занимает один цикл процессора. Кроме этого транспьютер может адресовать до 4 Гбайта внешней памяти. Внутренняя и внешняя памяти располагаются в одном и том же адресном пространстве. Память имеет байтовую адресацию. Машинное слово состоит из 4-х байт и имеет адрес кратный четырем. Младший байт слова (0-й байт) имеет наименьший адрес. Адрес - это знаковое целое число с областью значений от наименьшего отрицательного целого числа (#80000000) до наибольшего положительного числа (#7FFFFFFF).
Мультиплексируемый Интерфейс Внешней Памяти (External memory interface - EMI) обеспечивает доступ к 32-разрядному адресному пространству, поддерживает динамическое и статическое ОЗУ, ПЗУ, СППЗУ (стираемое, программируемое ПЗУ). Временные соотношения интерфейса памяти можно установить по сигналу Инициализация так, чтобы удовлетворить большинство типов памяти и скоростей обмена с памятью. Можно выбрать 13 конфигураций интерфейса памяти как аппаратно, так и программно. Конфигурации различаются длительностью состояний интерфейса памяти, типом и длительностью циклов записи/чтения памяти (от 3 до 12 циклов процессора).
Билет 20:
Многомашинные системы:
Существуют два различных способа построения крупномасштабных систем с распределенной памятью. Простейший способ заключается в том, чтобы исключить аппаратные механизмы, обеспечивающие когерентность кэш-памяти, и сосредоточить внимание на создании масштабируемой системы памяти. Несколько компаний разработали такого типа машины. Наиболее известным примером такой системы является компьютер T3D компании Cray Research. В этих машинах память распределяется между узлами (процессорными элементами) и все узлы соединяются между собой посредством того или иного типа сети. Доступ к памяти может быть локальным или удаленным. Специальные контроллеры, размещаемые в узлах сети, могут на основе анализа адреса обращения принять решение о том, находятся ли требуемые данные в локальной памяти данного узла, или размещаются в памяти удаленного узла. В последнем случае контроллеру удаленной памяти посылается сообщение для обращения к требуемым данным.
Чтобы обойти проблемы когерентности, разделяемые (общие) данные не кэшируются. Конечно, с помощью программного обеспечения можно реализовать некоторую схему кэширования разделяемых данных путем их копирования из общего адресного пространства в локальную память конкретного узла. В этом случае когерентностью памяти также будет управлять программное обеспечение. Преимуществом такого подхода является практически минимальная необходимая поддержка со стороны аппаратуры, хотя наличие, например, таких возможностей как блочное (групповое) копирование данных было бы весьма полезным. Недостатком такой организации является то, что механизмы программной поддержки когерентности подобного рода кэш-памяти компилятором весьма ограничены. Существующая в настоящее время методика в основном подходит для программ с хорошо структурированным параллелизмом на уровне программного цикла.
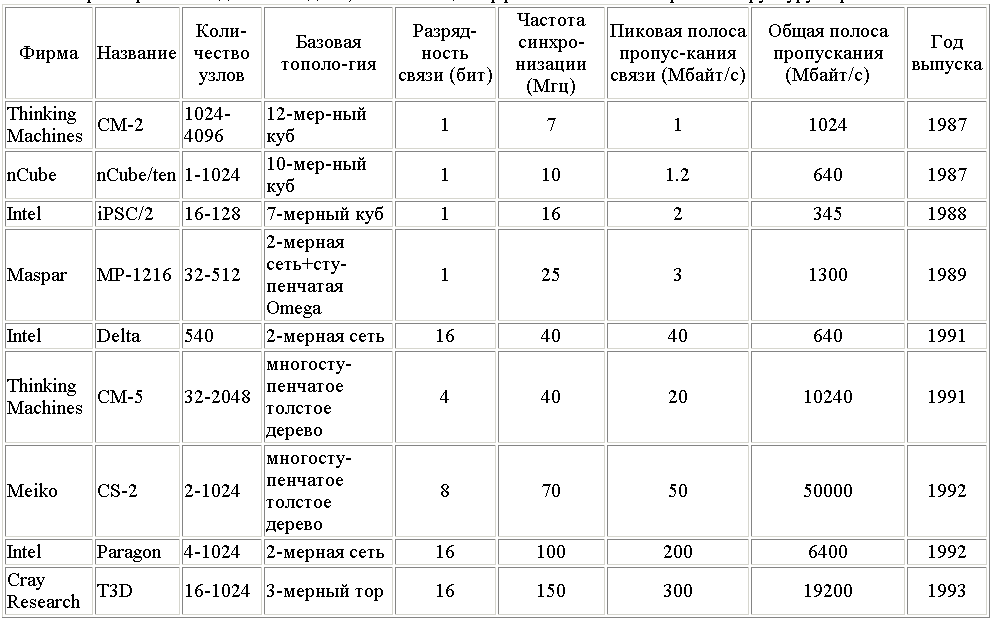
Машины с архитектурой, подобной Cray T3D, называют процессорами (машинами) с массовым параллелизмом (MPP Massively Parallel Processor). К машинам с массовым параллелизмом предъявляются взаимно исключающие требования. Чем больше объем устройства, тем большее число процессоров можно расположить в нем, тем длиннее каналы передачи управления и данных, а значит и меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а повышением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети обмена между процессорами в такого рода системах может быть различной.
Для построения крупномасштабных систем альтернативой рассмотренному в предыдущем разделе протоколу наблюдения может служить протокол на основе справочника, который отслеживает состояние кэшей. Такой подход предполагает, что логически единый справочник хранит состояние каждого блока памяти, который может кэшироваться. В справочнике обычно содержится информация о том, в каких кэшах имеются копии данного блока, модифицировался ли данный блок и т.д. В существующих реализациях этого направления справочник размещается рядом с памятью. Имеются также протоколы, в которых часть информации размещается в кэш-памяти. Положительной стороной хранения всей информации в едином справочнике является простота протокола, связанная с тем, что вся необходимая информация сосредоточена в одном месте. Недостатком такого рода справочников является его размер, который пропорционален общему объему памяти, а не размеру кэш-памяти. Это не составляет проблемы для машин, состоящих, например, из нескольких сотен процессоров, поскольку связанные с реализацией такого справочника накладные расходы можно преодолеть. Но для машин большего размера необходима методика, позволяющая эффективно масштабировать структуру справочника.
Многомашинные и многопроцессорные вычислительные комплексы. Определение, типы связей и структурная организация.
Вычислительная техника в своем развитии по пути повышения быстродействия ЭВМ приблизилась к физическим пределам. Время переключения электронных схем достигло долей наносекунды, а скорость распространения сигналов в линиях, связывающих элементы и узлы машины, ограничена значением 30 см/нс (скоростью света). Поэтому дальнейшее уменьшение времени переключения электронных схем не позволит существенно повысить производительность ЭВМ. В этих условиях требования практики (сложные физико-технические расчеты, многомерные экономико-математические модели и другие задачи) по дальнейшему повышению быстродействия ЭВМ могут быть удовлетворены только путем распространения принципа параллелизма на сами устройства обработки информации и создания многомашинных и многопроцессорных (мультипроцессорных) вычислительных систем. Такие системы позволяют производить распараллеливание во времени выполнения программы или параллельное выполнение нескольких программ.
В настоящее время исключительно важное значение приобрела проблема обеспечения высокой надежности и готовности вычислительных систем, работающих в составе различных АСУ и АСУ ТП, особенно при работе, в режиме реального времени. Эта проблема решается на основе использования принципа избыточности, который ориентирует также на построение многомашинных или многопроцессорных систем (комплексов). Появление дешевых и небольших по размерам микропроцессоров и микро-ЭВМ облегчило построение и расширило область применения многопроцессорных и многомашинных ВС разного назначения
Различие понятий многомашинной и многопроцессорной ВС поясняет рис.6.1. Многомашинная ВС (ММС) содержит несколько ЭВМ, каждая из которых имеет свою ОП и работает под управлением своей операционной системы, а также средства обмена информацией между машинами. Реализация обмена информацией происходит, в конечном счете, путем взаимодействия операционных систем машин между собой. Это ухудшает динамические характеристики процессов межмашинного обмена данными. Применение многомашинных систем позволяет повысить надежность вычислительных комплексов. При отказе в одной машине обработку данных может продолжать другая машина комплекса. Однако можно заметить, что при этом оборудование комплекса недостаточно эффективно используется для этой цели. Достаточно в системе, изображенной на рис.6.1,а в каждой ЭВМ выйти из строя по одному устройству (даже разных типов), как вся система становится неработоспособной.
Этих недостатков лишены многопроцессорные системы (МПС). В таких системах (рис. 6.1,б) процессоры обретают статус рядовых агрегатов вычислительной системы, которые подобно другим агрегатам, таким, как модули памяти, каналы, периферийные устройства, включаются в состав системы в нужном количестве.
Вычислительная система называется многопроцессорной, если она содержит несколько процессоров, работающих с общей ОП (общее поле оперативной памяти) и управляется одной общей операционной системой. Часто в МПС организуется общее поле внешней памяти.
Под общим полем понимается равнодоступность устройств. Так, общее поле памяти означает, что все модули ОП доступны всем процессорам и каналам ввода-вывода (или всем периферийным устройствам в случае наличия общего интерфейса); общее поле ВЗУ означает, что образующие его устройства доступны любому процессору и каналу.
В МПС по сравнению с ММС достигается более быстрый обмен информацией между процессорами и поэтому может быть получена более высокая производительность, более быстрая реакция на ситуации, возникающие внутри системы и в ее внешней среде, и более высокие надежность и живучесть, так как система сохраняет работоспособность, пока работоспособны хотя бы по одному модулю каждого типа устройств.
Многопроцессорные системы представляют собой основной путь построения ВС сверхвысокой производительности. При создании таких ВС возникает много сложных проблем, к которым в первую очередь следует отнести распараллеливание вычислительного процесса (программ) для эффективной загрузки процессоров системы, преодоление конфликтов при попытках нескольких процессоров использовать один и тот же ресурс системы (например, некоторый модуль памяти) и уменьшение влияния конфликтов на производительность системы, осуществление быстродействующих экономичных по аппаратурным затратам межмодульных связей. Указанные вопросы необходимо учитывать при выборе структуры МПС.
На основе многопроцессорности и модульного принципа построения других устройств системы возможно создание отказоустойчивых систем, или, другими словами, систем повышенной живучести.
Однако построение многомашинных систем из серийно выпускаемых ЭВМ с их стандартными операционными системами значительно проще, чем построение МПС, требующих преодоления определенных трудностей, возникающих при реализации общего поля памяти, и, главное, трудоемкой разработки специальной операционной системы.
Многомашинные и многопроцессорные системы могут быть однородными и неоднородными. Однородные системы содержат однотипные ЭВМ или процессоры. Неоднородные ММС состоят из ЭВМ различного типа, а в неоднородных МПС используются различные специализированные процессоры, например процессоры для операций с плавающей запятой, для обработки десятичных чисел, процессор, реализующий функции операционной системы, процессор для матричных задач и др.
Многопроцессорные системы и ММС могут иметь одноуровневую или иерархическую (многоуровневую) структуру. Обычно менее мощная машина (машина-сателлит) берет на себя ввод информации с различных терминалов и ее предварительную обработку, разгружая от этих сравнительно простых процедур основную, более мощную ЭВМ, чем достигается увеличение общей производительности (пропускной способности) комплекса. В качестве машин-сателлитов используют малые или микро-ЭВМ.
Важной структурной особенностью рассматриваемых ВС является способ организации связей между устройствами (модулями) системы. Он непосредственно влияет на быстроту обмена информацией между модулями, а следовательно, на производительность системы, быстроту ее реакции на поступающие запросы, приспособленность к изменениям конфигурации и, наконец, размеры аппаратурных затрат на осуществление межмодульных связей. В частности, от организации межмодульных связей зависят частота возникновения конфликтов при обращении процессоров к одним и тем же ресурсам (в первую очередь модулям памяти) и потери производительности из-за конфликтов.
Используются следующие способы организации межмодульных (межустройственных) связей:
регулярные связи между модулями;
многоуровневые связи, соответствующие иерархии интерфейсов ЭВМ;
многовходовые модули (в частности, модули памяти);
коммутатор межмодульных связей (“Эльбрус” Рис.6.2);
общая шина (“СМ ЭВМ” Рис.6.3).
Принципы организации МПС и ММС существенно отличаются в зависимости от их назначения. Поэтому целесообразно различать:
ВС, ориентированные в первую очередь на достижение сверхвысокой производительности;
ВС, ориентированные в первую очередь на повышение надежности и живучести.
Кластеры:
По мере развития компьютерной техники и ее интеграции в бизнес-процесс предприятий проблема увеличения времени, в течение которого доступны вычислительные ресурсы, приобретает все большую актуальность. Надежность серверов становится одним из ключевых факторов успешной работы компаний с развитой сетевой инфраструктурой, например, электронных магазинов, ведущих продажи через Интернет, крупных предприятий, в которых специальные системы осуществляют поддержку производственных процессов в реальном времени, банков с разветвленной филиальной сетью или центров обслуживания телефонного оператора, использующих систему поддержки принятия решений. Всем таким предприятиям жизненно необходимы серверы, которые работают и предоставляют информацию 24 часа в день семь дней в неделю (24х7х365).
Стоимость поломок и простоя оборудования постоянно растет. Она складывается из стоимости потерянной информации, потерянной прибыли, стоимости технической поддержки и восстановления, неудовлетворенности клиентов и т. д. Имеются методики, позволяющие вычислить стоимость минуты простоя и затем на основе этого показателя выбрать наиболее выгодное решение с наилучшим соотношением функциональности и цены.
Существует немало средств для построения надежной системы. Дисковые массивы RAID, например, позволяют не прерывать обработку запросов к информации, хранящейся на дисках, при выходе из строя одного или нескольких элементов массива. Резервные блоки питания в ряде случаев позволят в какой-то степени застраховаться на случай отказа других компонентов. Источники бесперебойного питания поддержат работоспособность системы в случае сбоев в сети энергоснабжения. Многопроцессорные системные платы обеспечат функционирование сервера в случае отказа одного процессора. Однако ни один из этих вариантов не спасет, если из строя выйдет вся вычислительная система целиком. Вот тут на помощь приходит кластеризация. Пожалуй, первым шагом к созданию кластеров можно считать широко распространенные в пору расцвета мини-компьютеров системы "горячего" резерва. Одна или две такие системы, входящие в сеть из нескольких серверов, не выполняют никакой полезной работы, но готовы начать функционировать, как только выйдет из строя какая-либо из основных систем. Таким образом, серверы дублируют друг друга на случай отказа или поломки одного из них. Но при объединении компьютеров желательно, чтобы они не просто дублировали друг друга, но и выполняли другую полезную работу, распределяя нагрузку между собой. Для этого во многих случаях как нельзя лучше подходят кластеры.
Изначально кластеры использовались для мощных вычислений и поддержки распределенных баз данных, особенно таких, для которых требуется повышенная надежность. В дальнейшем их стали применять для сервиса Web. Однако снижение цен на кластеры привело к тому, что подобные решения все активнее используют и для других нужд. Кластерные технологии наконец-то стали доступны рядовым организациям - в частности, благодаря использованию в кластерах начального уровня недорогих серверов Intel, стандартных средств коммуникации и распространенных ОС.
Кластерные решения на платформах Microsoft ориентированы прежде всего на борьбу с отказами оборудования и ПО. Статистика отказов подобных систем хорошо известна: только 20% из них непосредственно вызвано отказами оборудования, ОС, питания сервера и т. п. Для исключения этих факторов применяются различные технологии повышения отказоустойчивости серверов (резервируемые и заменяемые в горячем режиме диски, источники питания, платы в разъемах PCI и т. д.). Однако 80% оставшихся инцидентов вызваны обычно отказами приложений и ошибками оператора. Кластерные решения - действенное средство для решения этой проблемы.
В ряде случаев привлекательность кластера во многом определяется возможностью построить уникальную архитектуру, обладающую достаточной производительностью, устойчивостью к отказам аппаратуры и ПО. Такая система к тому же должна легко масштабироваться и модернизироваться универсальными средствами, на основе стандартных компонентов и за умеренную цену (несравненно меньшую, чем цена уникального отказоустойчивого компьютера или системы с массовым параллелизмом).
Термин "кластер" имеет множество определений. Одни во главу угла ставят отказоустойчивость, другие - масштабируемость, третьи - управляемость. Классическое определение кластера звучит примерно так: "кластер - параллельная или распределенная система, состоящая из нескольких связанных между собой компьютеров и при этом используемая как единый, унифицированный компьютерный ресурс". Таким образом, кластер представляет собой объединение нескольких компьютеров, которые на определенном уровне абстракции управляются и используются как единое целое. На каждом узле кластера (по сути, узел в данном случае - компьютер, входящий в состав кластера) находится своя собственная копия ОС. Напомним, что системы с архитектурой SMP и NUMA, имеющие одну общую копию ОС, нельзя считать кластерами. Впрочем, узлом кластера может быть как однопроцессорный, так и многопроцессорный компьютер, причем в пределах одного кластера компьютеры могут иметь различную конфигурацию (разное количество процессоров, разные объемы ОЗУ и дисков). Узлы кластера соединяются между собой либо с помощью обычных сетевых соединений (Ethernet, FDDI, Fibre Channel), либо посредством нестандартных специальных технологий. Такие внутрикластерные, или межузловые соединения позволяют узлам взаимодействовать между собой независимо от внешней сетевой среды. По внутрикластерным каналам узлы не только обмениваются информацией, но и контролируют работоспособность друг друга.
Более широкое определение кластера предложили эксперты Aberdeen Group (http://www.aberdeen.com): кластер в их понимании - это система, действующая как одно целое, гарантирующая высокую надежность, имеющая централизованное управление всеми ресурсами и общую файловую систему и, кроме того, обеспечивающая гибкость конфигурации и легкость в наращивании ресурсов.
Преимущества кластеризации
Как уже отмечалось, основное назначение кластера состоит в обеспечении высокого - по сравнению с разрозненным набором компьютеров или серверов - уровня доступности (High Availability, HA), иначе называемого уровнем готовности, а также высокой степени масштабируемости и удобства администрирования. Повышение готовности системы обеспечивает работу критических для бизнеса приложений на протяжении максимально продолжительного промежутка времени. К критическим можно отнести все приложения, от которых напрямую зависит способность компании получать прибыль, предоставлять сервис или обеспечивать иные жизненно важные функции. Как правило, использование кластера позволяет гарантировать, что в случае, если сервер или какое-либо приложение перестает нормально функционировать, другой сервер в кластере, продолжая выполнять свои задачи, возьмет на себя роль неисправного сервера (или запустит у себя копию неисправного приложения) с целью минимизации простоя пользователей из- за неисправности в системе.
Готовность обычно измеряется в процентах времени, проведенном системой в работоспособном состоянии, от общего времени работы. Естественно, различные приложения требуют различной готовности. Готовность системы может быть увеличена различными методами. Какой из них выбрать, решается в зависимости от стоимости системы и стоимости времени простоя. Как правило, более дешевые решения фокусируются в основном на снижении времени простоя после возникновения неисправности. Более дорогие позволяют системе продолжать функционировать и предоставлять сервис пользователям даже в том случае, когда один или несколько ее компонентов вышли из строя. Говорят, что по мере роста готовности системы ее цена увеличивается нелинейно; точно так же, нелинейно увеличивается и стоимость ее поддержки. Относительно низкая стоимость оборачивается не самым высоким уровнем отказоустойчивости - не более 99%. Это означает, что около четырех дней в году информационная структура предприятия будет неработоспособна. На первый взгляд, это не так уж много, если учесть, что сюда входят и плановые простои, связанные с проведением профилактических работ или реконфигурацией. Но клиенту, например, пользователю системы оплаты по кредитным карточкам, безразлично, по какой причине он будет лишен обслуживания. Он останется неудовлетворенным и будет искать другого оператора. Высокая доступность (готовность) подразумевает решение, способное продолжать функционировать либо восстанавливать функционирование после возникновения большинства ошибок без вмешательства оператора. Дорогие отказоустойчивые решения способны обеспечить заветные "пять девяток" - 99,999% надежности системы, что означает не более 5 минут простоев в год.
Золотую середину между едиными серверными системами с зеркалированными дисковыми подсистемами (или дисковыми массивами RAID) и отказоустойчивыми системами обеспечивают кластерные решения. По уровню доступности они приближаются к отказоустойчивым системам при несоизмеримо меньшей стоимости. Такие решения идеальны для случаев, когда можно допустить лишь очень незначительные незапланированные простои.
В случае сбоя кластерной системы восстановлением управляет специальное программное и аппаратное обеспечение. В частности, кластерное ПО позволяет автоматически определить единичный аппаратный или программный сбой, изолировать его и восстановить систему. Специально разработанные подпрограммы способны выбрать самый быстрый способ восстановления и за минимальное время обеспечить работоспособность служб. При помощи встроенного инструментального средства разработки и программного интерфейса можно создавать специальные программы, выявляющие, изолирующие и устраняющие сбои, которые возникают в приложениях, разработанных пользователем.
Другое достоинство кластеризации - обеспечение масштабируемости. Кластер позволяет гибко увеличивать вычислительную мощность системы, добавляя в него новые узлы и не прерывая при этом работы пользователей. Современные кластерные решения предусматривают автоматическое распределение нагрузки между узлами кластера, в результате чего одно приложение может работать на нескольких серверах и использовать их вычислительные ресурсы.
Типичные приложения, эксплуатируемые на кластерах, это:
базы данных;
системы управления ресурсами предприятия (ERP);
средства обработки сообщений и почтовые системы;
средства обработки транзакций через Web и Web- серверы;
системы взаимодействия с клиентами (CRM);
системы разделения файлов и печати.
Билет 21:
Состав:
Ядро. Сердце современного процессора - исполняющий модуль. Позволяет читать, интерпретировать, выполнять и отправлять команды.
Блок вычислений с плавающей точкой, FPU (Floating Point Unit). Второй выполняющий модуль внутри современного процессора, выполняющий вычисления с вещественными числами. Содержит блоки сложения, умножения, деления.
Кэш-память. Внутренняя кэш-память, с которой процессор может работать в несколько раз быстрее, чем с оперативной памятью, впервые появилась на 486-х процессорах и по сей день является одним из эффективных методов увеличения производительности.
Отметим, что особенностью современных процессоров является раздельное хранение данных и команд - в кэше команд 1-го уровня и кэше данных 1-го уровня. Подобный метод раздельного хранения более гибок, так как позволяет динамично распределять память между данными и кодом, хотя это сказывается на некоторой сложности реализации.
Блок интерфейса шины принимает смесь кода и данных в процессор, разделяет их до готовности к использованию, или вновь соединяет, отправляя результаты вычислений по шине.
Со всеми компонентами, внешними по отношению к процессору (оперативной памятью, тактовым генератором и т.д.) он связан посредством системной шины, по которой процессор принимает и отправляет электрические сигналы. Системная шина, в свою очередь, делится на шину управления, по которой передаются управляющие сигналы, шину адреса, по которой передаются адреса ячеек памяти, откуда необходимо взять требуемые для расчетов данные или записать результат операции, и шину данных, по которой передаются непосредственно эти данные.
Все элементы процессора синхронизируются с использованием тактового генератора, то есть устройства на основе кварцевого кристалла, генерирующее электрические импульсы, которые синхронизируют работу не только центрального процессора, но также и всех других систем компьютера, подключенных к системной шине, заставляя их слаженно работать, совсем как хорошо сыграный симфонический оркестр.
Причем отметим, что современные процессоры всегда работают на частоте, в несколько раз превышающей частоту работы системной шины. Для этого существует так называемый умножитель частоты, который для различных процессоров может принимать разные значения. Если шина работает на частоте 100MHz, а умножитель частоты с помощью перемычек установлен пользователем равным 2, то процессор будет работать на частоте 200MHz.
Самые первые процессоры для IBM PC работали на частоте 4MHz, сегодня же рядовая частота процессора колеблется от 450MHz до 800MHz.
Итак, с чего начинается работа процессора? Самый первый этап - это начальная инициализация. При включении питания или при сбросе компьютера все регистры процессора (ячейки памяти для хранения данных, участвующих непосредственно в операциях) очищаются, а также сбрасывает в ноль свой программный счетчик, указывающий положение текущей выполняемой команды в памяти. Затем, после выполнения программы самотестирования, процессор приступает к работе.
Установив программный счетчик на ячейку памяти, содержащую первую команду программы, процессор по шине получает эту команду и с помощью дешифратора команд, расшифровывает смысл команды, сравнивая ее с тем набором команд, которые он может выполнять, а затем раскладывает ее на элементарные микрокоманды и операнды.
Как уже было отмечено, все данные (команды, адреса памяти и т.д.), которыми оперирует процессор, он хранит в регистрах. После того, как процессор расшифровал операнд, ему необходимо получить те данные, которые хранятся по указанному адресу. Он делает это с помощью блока генерации адреса считывания, определяя ячейку с необходимым адресом памяти, и загружает данные из этой ячейки в свои регистры. Если, например, выполняемая операция - сложение двух чисел, то этой информацией будут два складываемых числа.
Далее, загрузив в одни регистры команды, а в другие - данные, которыми оперируют эти команды, процессор начинает их обрабатывать.
На последнем этапе выполнения команды процессор удаляет отработавшие команды из дешифратора и записывает результаты выполнения команд в регистры и в память.
Выполнив одну команду, процессор изменяет программный счетчик, переключая его либо на команду, следующую непосредственно за последней выполненной, либо, если команда содержала указание типа "перейти к инструкции, находящейся по такому-то адресу", к этому адресу.
Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным. Теперь коснемся архитектурных решений, повышающих производительность процессора иначе, чем просто повышением тактовой частоты.
Предсказатель ветвлений. Модуль предсказания ветвлений, являющийся сегодня необходимым атрибутом центрального процессора, пытается угадать, какая последовательность будет выполняться каждый раз когда программа содержит условный переход, так чтобы устройства предварительной выборки и декодирования получали бы инструкции готовыми предварительно.
Конвейер. Традиционно выполнение одной инструкции занимало пять тактов - один для загрузки инструкции, другой для ее декодирования, один для получения данных, один для выполнения и один для записи результата. В этом случае очевидно 100MHz процессор мог выполнить только 20 миллионов инструкций в секунду.
Современные процессоры сегодня применяют конвейерную обработку, которая больше похожа на фабричный конвейер. Одна стадия потока выделена под каждый шаг, необходимый для выполнения команды, и каждая стадия передает команду следующей, когда она выполнила свою часть. Это значит, что в любой момент времени одна команда загружается, другая декодируется, доставляются данные для третьей, четвертая исполняется, и записывается результат для пятой.
Более того, современные процессоры сейчас имеют суперскалярную архитектуру. Это значит, что схема каждой стадии потока дублируется, так что много команд могут передаваться и исполняться параллельно.
Любая команда процессору, например, "сложить два числа", состоит из так называемых микрокоманд, которые непосредственно управляют аппаратными средствами процессора. Команду сложения можно разложить на микрокоманды типа записи складываемых чисел в регистры, пересылки в АЛУ и т.д. Все зависит от конкретной архитектуры процессора.
Команды процессора обычно состоят из двух частей: кода команды и операнда. Код команды говорит процессору, какие действия нужно выполнить. Операнд - указание на адрес памяти, где хранится подлежащая обработке информация. В некоторых случаях это адрес другой команды (например, в командах перехода).
Основные концепции архитектуры высокопроизводительных вычислительных систем.
Архитектура традиционных последовательных компьютеров основана на идеях Джона фон Неймана и включает в себя центральный процессор, оперативную память - адресное пространство с линейной адресацией и блок управления. Последовательность команд применяется к последовательности данных. Быстродействие такого традиционного компьютера определяется быстродействием его центрального процессора и временем доступа к оперативной памяти. Быстродействие центрального процессора может быть увеличено за счет увеличения тактовой частоты, величина которой зависит от плотности элементов в интегральной схеме, способа их "упаковки" и быстродействия микросхем оперативной памяти.
Другие методы повышения быстродействия последовательного компьютера основаны на расширении традиционной неймановской архитектуры, а именно:
-применении RISC процессоров, то есть процессоров с сокращенным набором команд. В RISC процессорах большая часть команд выполняется за 1-2 такта;
-применении суперскалярных процессоров;
- применении конвейеров.
В высокопроизводительных вычислительных системах используются как традиционные элементы архитектуры, так и ее расширения, а также новые элементы, такие, например, как векторные процессоры.
Типы микропроцессоров
Микропроцессор, иначе, центральный процессор - Central Processing Unit (CPU) - функционально законченное программно-управляемое устройство обработки информации, выполненное в виде одной или нескольких больших (БИС) или сверхбольших (СБИС) интегральных схем.
Для МП на БИС или СБИС характерны:
простота производства (по единой технологии);
низкая стоимость (при массовомпроизводстве);
малые габариты (пластина площадью несколько квадратных сантиметров или кубик со стороной несколько миллиметров);
высокая надежность;
малое потребление энергии.
Микропроцессор выполняет следующие функции:
чтение и дешифрацию команд из основной памяти;
чтение данных из ОП и регистров адаптеров внешних устройств;
прием и обработку запросов и команд от адаптеров на обслуживание ВУ;
обработку данных и их запись в ОП и регистры адаптеров ВУ;
выработку управляющих сигналов для всех прочих узлов и блоков ПК.
Разрядность шины данных микропроцессора определяет разрядность ПК в целом; разрядность шины адреса МП - его адресное пространство.
Адресное пространство - это максимальное количество ячеек основной памяти, которое может быть непосредственно адресовано микропроцессором.
Первый микропроцессор был выпущен в 1971 г. фирмой Intel (США) - МП 4004. В настоящее время выпускается несколько сотен различных микропроцессоров, но наиболее популярными и распространенными являются микропроцессоры фирмы Intel и Intel-подобные.
Все микропроцессоры можно разделить на три группы:
МП типа CISC (Complex Instruction Set Computing) с полным набором команд;
МП типа RISC (Reduced Instruction Set Computing) с сокращенным набором команд;
МП типа MISC (Minimum Instruction Set Computing) с минимальным набором команд и весьма высоким быстродействием (в настоящее время зги модели находятся в стадии разработки).
Микропроцессоры типа CISC
Большинство современных ПК типа IBM PC (International Business Machine) используют МП типа CISC, характеристики наиболее распространенныхиз них приведены в табл. 4.5.
Таблица 4.5. Характеристики наиболее распространенных CISC МП
Модель МП |
Разрядность, бит |
Тактовая частота, МГц |
Адресное пространство, байт |
Число команд |
Число элементов |
Год выпуска |
|
данных |
Адреса |
||||||
4004 |
4 |
4 |
4,77 |
4*103 |
45 |
2300 |
1971 |
8080 |
8 |
8 |
4,77 |
64*103 |
|
10000 |
1974 |
8086 |
16 |
16 |
4,77 и 8 |
106" |
134 |
70000 |
1982 |
8088 |
8, 16 |
16 |
4,77 и 8 |
106 |
134 |
70000 |
1981 |
80186 |
16 |
20 |
8 и 10 |
106 |
|
140000 |
1984 |
80286 |
16 |
24 |
10-33 |
4*106 (виртуальное 109) |
|
180000 |
1985 |
80386 |
32 |
32 |
25-50 |
16*106 (виртуальное 4*109) |
240 |
275000 |
1987 |
80486 |
32 |
32 |
33-100 |
16*106 (виртуальное 4*109) |
240 |
1,2х106 |
1989 |
Pentium |
64 |
32 |
50-150 |
4*109 |
240 |
3,1*106 |
1993 |
Pentium Pro |
64 |
32 |
66-200 |
4*109 |
240 |
5,5*106 |
1995 |
Отметим некоторые характеристики МП:
начиная с МП 80386 используется конвейерное выполнение команд - одновременное выполнение разных тактов последовательных команд в разных частях МП при непосредственной передаче результатов из одной части МП в другую. Конвейерное выполнение команд увеличивает эффективное быстродействие ПК в 2 - 3 раза;
начиная с МП 80286 предусматривается возможность работы в вычислительной сети;
начиная с МП 80286 имеется возможность многозадачной работы (многопрограммность) и сопутствующая ей защита памяти;
начиная с МП 80386 обеспечивается поддержка режима системы виртуальных машин, т.е. такого режима многозадачной работы, при котором в одном МП моделируется как бы несколько компьютеров, работающих параллельно и имеющих разные операционные системы;
начиная с МП 80286 микропроцессоры могут работать в двух режимах: реальном (Real mode) и защищенном (Protected mode). В реальном режиме имитируется (эмулируется) работа МП 8086, естественно, однозадачная. В защищенном режиме возможна многозадачная работа с непосредственным доступом к расширенной памяти (см подразд. 4.5) и с защитой памяти, отведенной задачам, от посторонних обращений.
Микропроцессоры 80586 (Р 5) более известны по их товарной марке Pentium, которая запатентована фирмой Intel (МП 80586 других фирм имеют иные обозначения: К5 у фирмы AMD, M 1 у фирмы Cyrix и др.).
Эти микропроцессоры имеют пятиступенную конвейерную структуру, обеспечивающую многократное совмещение тактов выполнения последовательных команд, и КЭШ-буфер для команд условной передачи управления, позволяющий предсказывать направление ветвления программ; по эффективному быстродействию они приближаются к RISC МП, выполняющим каждую команду как бы за один такт. Pentium имеют 32-разрядную адресную шину и 64-разрядную шину данных. Обмен данными с системой может выполняться со скоростью 1 Гбайт/с.
У всех МП Pentium имеется встроенная КЭШ-память, отдельно для команд, отдельно для данных; имеются специализированные конвейерные аппаратные блоки сложения, умножения и деления, значительно ускоряющие выполнение операций с плавающей запятой.
Микропроцессоры Pentium Pro. В сентябре 1995 г. прошли презентацию и выпущены МП 80686 (Р6), торговая марка Pentium Pro. Благодаря новым схемотехническим решениям они обеспечивают для ПК более высокую производительность Часть этих новшеств может быть объединена понятием динамическое исполнение (dynamic execution), что в первую очередь означает наличие 14-ступенной суперконвейерной структуры (superpipelining), предсказания ветвлений программы при условных передачах управления (branch prediction) и исполнение команд по предполагаемому пути ветвления (speculative execution).
Примечание. В программах решения многих задач, особенно экономических, содержится большое число условных передач управления. Если процессор может заранее предсказывать направление перехода (ветвления), то производительность его работы значительно повысится за счет оптимизации загрузки вычислительных конвейеров. В процессоре Pentium Pro вероятность правильного предсказания 90 % против 80 % у МП Pentium.
КЭШ-память емкостью 256 - 512 Кбайт - обязательный атрибут высокопроизводительных системна процессорах Pentium. Однако у них встроенная КЭШ-память имеет небольшую емкость (16 Кбайт), а основная ее часть находится вне процессора на материнской плате. Поэтому обмен данными с ней происходит не на внутренней частоте МП, а на частоте тактового генератора, которая обычно в 2 -3 раза ниже, что снижает общее быстродействие компьютера.В МП Pentium Pro КЭШ-память емкостью 256-512 Кбайт находится в самом микропроцессоре.
Микропроцессоры типа RISC
Микропроцессоры типа RISC содержат набор только простых, чаше всего встречающихся в программах команд. При необходимости выполнения более сложных команд в микропроцессоре производится их автоматическая сборка из простых. В этих МП на выполнение каждой простой команды за счет их наложения и параллельного выполнения тратится 1 машинный такт (на выполнение даже самой короткой команды из системы CISC обычно тратится 4 такта).
Некоторые микропроцессоры типа RISC: один из первых МП - ARM (на его основе выпускались ПК IBM PC RT) - 32-разрядный МП, имеющий 118 различных команд. Современные RISC МП (80860, 80960, 80870, Power PC) являются 64-разрядными при быстродействии до 150 млн. оп./с. Микропроцессоры Power PC (Performance Optimized With Enhanced RISC PC) весьма перспективны и уже сейчас широко применяются в машинах-серверах и в ПК типа Macintosh.
Микропроцессоры типа RISC имеют очень высокое быстродействие, но программно не совместимы с CISC-процессорами: при выполнении программ, разработанных для ПК типа IBM PC, они могут лишь эмулировать (моделировать, имитировать) МП типа CISC на программном уровне, что приводит к резкому уменьшению их эффективной производительности.
Все новые МП создаются на основе технологий, обеспечивающих формирование элементов с линейным размером порядка 0,5 мкм (традиционные МП 80486 и Pentium-66 использовали 0,8-мкм элементы).
Уменьшение размеров элементов обеспечивает возможность:
увеличения тактовой частоты МП до 100 МГц и выше, поскольку тормозом в увеличении быстродействия уже является недостаточная (!) скорость распространения "света" (300 000 км/с);
уменьшения перегрева МП, позволяя использовать пониженное напряжение питания 3,3 В (вместо стандартных 5 В).
Функционально МП состоит из двух частей:
операционной, содержащей устройство управления, арифметико-логическое устройство и микропроцессорную память (за исключением нескольких адресных регистров);
интерфейсной, содержащей адресные регистры МПП, блок регистров команд, схемы управления шиной и портами.
Работают обе части параллельно, причем интерфейсная часть опережает операционную, так что выборка очередной команды из памяти (ее запись в блок регистров команд и предварительный анализ) производится во время выполнения операционной частью предыдущей команды. Современные микропроцессоры имеют несколько групп регистров в микропроцессорной части, работающих с различной степенью опережения, что позволяет выполнять операции в конвейерном режиме. Такая организация МП дает возможность значительно повысить его эффективное быстродействие.
Билет 26:
МИКРОПРОЦЕССОР INTEL 8086
Структуру команд и методы адресации мы далее будем рассматривать на примере широко распространенного микропроцессора Intel 8086. Рассмотрим аппаратную модель этого микропроцессора.
АППАРАТНАЯ МОДЕЛЬ ПРОЦЕССОРА 8086
Выполнение программы в ЭВМ представляет собой циклическую последовательность приведенных ниже действий, образующих цикл команды:
1) выборка команды из памяти и формирование адреса следующей по порядку команды;
2) считывание операнда из памяти, если это требуется по смыслу команды;
3) собственно выполнение команды;
4) запись результата в память, если это указано в команде, и переход к новому циклу команды.
Обычно в микропроцессоре эти действия выполняются последовательно во времени. В процессоре 8086 основные этапы сохранены, но они распределены внутри процессора по двум сравнительно независимым устройствам. Операционное устройство выполняет команды, а устройство шинного интерфейса выбирает команды, считывает операнды и записывает результаты. Оба устройства могут работать параллельно и в большинстве случаев обеспечивают значительное совмещение выборки и выполнения команд. В результате этого время выборки команды как-бы "исчезает" из цикла команды, так как операционное устройство выполняет команды, уже выбранные шинным интерфейсом.
Операционное устройство содержит группу общих регистров, арифметико-логическое устройство (АЛУ), основу которого составляет комбинированный 16-разрядный сумматор с последовательно-параллельным переносом, регистр флажков и несколько регистров для временного хранения операндов и результата операции. Оно выполняет команды, обменивается данными и адресами с шинным интерфейсом, оперирует общими регистрами и флажками. В его составе имеется блок микропрограммного управления, который дешифрует команды и формирует необходимые управляющие сигналы. Операционное устройство изолированно от внешней шины, за исключением нескольких внешних сигналов.
Шинный интерфейс выполняет для операционного устройства все операции обмена. Данные передаются между процессором и памятью или портами ввода-вывода по запросам операционного устройства. Когда операционное устройство занято выполнением команды, шинный интерфейс самостоятельно инициирует опережающую выборку из памяти очередных команд. Команды хранятся во внутренней регистровой памяти, называемой очередью (буфером) команд. Очередь команд выполняет по существу функции регистра команды процессора. Длина очереди составляет 6 байт. Очередь команд работает по принципу FIFO ("первым пришел, первым вышел"), который сохраняет на выходе порядок поступления команд.
Шинный интерфейс инициирует выборку из памяти следующего командного слова, когда в очереди оказываются два свободных (пустых) байта.
В большинстве случаев очередь команд содержит минимум один байт потока команд, и операционное устройство не ожидает выборки команды. Конечно, очередь обеспечивает положительный эффект при естественном порядке выполнения команд. Когда операционное устройство выполняет команду передачи управления, шинный интерфейс сбрасывает очередь, выбирает команду по новому адресу, передает ее в операционное устройство, а затем начинает заполнение очереди из следующихячеек. Эти действия выполняются при условных и безусловных переходах, вызовах подпрограмм, возвратах из подпрограмм и при обработке прерываний. Шинный интерфейс приостанавливает выборку команд, когда операционное устройство запрашивает операцию считывания или записи в память или порт ввода-вывода.
В состав шинного интерфейса входят несколько регистров и сумматор, которые формируют 20- разрядный физический адрес памяти из двух 16-разрядных логических адресов: сегмента (базы) и смещения.
При готовности операционного устройства выполнять команду оно считывает из очереди байт, а затем выполняет предписанную командой операцию. При многобайтных командах из очереди считываются и другие байты команды. Когда операционное устройство готово считать командный байт, а очередь команд пуста, оно ожидает выборки командного слова из памяти программ, которую производит шинный интерфейс. Если команда требует обращения к памяти или порту ввода-вывода, операционное устройство запрашивает шинный интерфейс на выполнение необходимого цикла шины. Когда шинный интерфейс не занят выборкой команды, он удовлетворяет запрос немедленно; в противном случае операционное устройство ожидает завершения текущего цикла шины.
ПРОГРАММНАЯ МОДЕЛЬ ПРОЦЕССОРА 8086
Программная модель процессора - это функциональная модель, используемая программистом при разработке программ в кодах ЭВМ или на языке ассемблера. В такой модели игнорируются многие аппаратные особенности в работе процессора.
В процессоре 8086 имеется несколько быстрых элементов памяти, которые называются регистрами. Каждый из регистров имеет уникальную природу и предоставляет определенные возможности, которые другими регистрами или ячейками памяти не поддерживаются.
Регистры разбиваются на четыре категории: регистры общего назначения, регистр флагов, указатель команд и сегментные регистры. Все регистры 16-разрядные.

Формат регистра флагов:

Указатель команд:

Формат сегментных регистров:

РЕГИСТР ФЛАГОВ

Этот 16-разрядный регистр содержит всю необходимую информацию о состоянии процессора 8086 и результатах выполнения последней команды.
Битовые флаги:
OF - флаг переполнения;
DF - флаг направления;
IF - флаг прерывания;
TF - флаг трассировки;
SF - флаг знака;
ZF - флаг нуля;
AF - флаг дополнительного переноса;
PF - флаг четности;
CF - флаг переноса;
** - бит не используется, состояние не определено.
Флаг переполнения OF сигнализирует о потере старшего бита результата сложения или вычитания. Имеется специальная команда прерывания при переполнении, которая генерирует программное прерывание.
Флаг направления DF определяет порядок сканирования цепочек байт или слов в соответствующих командах: от меньших адресов к большим (DF = 0) или наоборот (DF = 1).
Флаг прерывания IF определяет реакцию процессора на запросы внешних прерываний по входу INT. Если IF = 0, запросы прерываний игнорируются (говорят также, что прерывания запрещены или замаскированы), а если IF = 1, процессор распознает запросы на прерывания и реагирует на них соответствующим образом. Состояние флага IF не влияет на восприятие внешних немаскируемых прерываний по входу NMI, а также внутренних (программных) прерываний.
Установка в состояние 1 флага трассировки TF переводит процессор в одношаговый (покомандный) режим работы, который применяется при отладке программ. В этом режиме процессор автоматически генерирует внутреннее прерывание после выполнения каждой команды с переходом к соответствующей подпрограмме обработки, которая может, например, демонстрировать содержимое регистров процессора на зкране дисплея.
Флаг знака SF повторяет значение старшего бита результата, который при использовании дополнительного кода соответствует знаку числа.
Флаг нуля ZF сигнализирует о получении нулевого результата операции.
Флаг вспомогательного переноса AF фиксирует перенос (заем) из младшей тетрады в старшую 8- или 16-битного результата. Он необходим только для команд десятичной арифметики.
Флаг четности (паритета) PF фиксирует наличие четного числа единиц в младших 8 разрядах результата операции. Этот флаг предназначен для контроля правильности передачи данных.
Флаг CF фиксирует значение переноса (заема), возникающего при сложении или вычитании байт или слов, а также значение выдвигаемого бита при сдвиге операнда.
Регистр флагов не считывается и не модифицируется непосредственно. Вместо этого в системе команд микропроцессора предусмотрены специальные команды, с помощью которых программист может задать необходимое ему состояние любого из флагов (кроме TF).
Содержимое регистра флагов используется микропроцессором при выполнении команд условного перехода, циклических сдвигов, операций с цепочками байт или слов.
РЕГИСТРЫ ОБЩЕГО НАЗНАЧЕНИЯ
Восемь регистров общего назначения процессора 8086 (каждый разрядностью 16 бит) используются в операциях большинства инструкций в качестве источника или приемника при перемещении данных и вычислениях, указателей на ячейки памяти и счетчиков. Каждый регистр общего назначения может использоваться для хранения 16-битового значения, в арифметических и логических операциях, может выполняться обмен между регистром и памятью (запись из регистра в память и наоборот).
Кроме этих общих свойств, каждый регистр общего назначения имеет свои особенности. Поэтому рассмотрим далее каждый из них отдельно.
Регистр AX называют также накопителем (аккумулятором). Этот регистр всегда используется в операциях умножения или деления и является также одним из тех регистров, который можно использовать для наиболее эффективных операций (арифметических, логических или операций перемещения данных).
Младшие 8 битов регистра AX называются также регистром AL, а старшие 8 битов - регистром AH. Это может оказаться удобным при работе с данными размером в байт. Таким образом, регистр AX можно использовать, как два отдельных регистра.
Регистр BX может использоваться для ссылки на ячейку памяти (указатель), т.е. 16-битовое значение, записанное в BX, может использоваться в качестве части адреса ячейки памяти, к которой производится обращение. По умолчанию, когда BX используется в качестве указателя на ячейку памяти, он ссылается на нее относительно сегментного регистра DS.
Как и регистры AX, CX и DX, регистр BX может интерпретироваться, как два восьмибитовых регистра - BH и BL.
Специализация регистра CX - использование в качестве счетчика при выполнении циклов.
Уменьшение значения счетчика и цикл - это часто используемый элемент программы, поэтому в процессоре 8086 используется специальная команда для того, чтобы циклы выполнялись быстрее и были более компактными. Эта команда называется LOOP. Инструкция LOOP вычитает 1 из CX и выполняет переход, если содержимое регистра CX не равно 0.
Регистр CX можно интерпретировать, как два 8-разрядных регистра - CH и CL.
Регистр DX - это единственный регистр, которые может использоваться в качестве указателя адреса ввода-вывода в командах IN и OUT. Фактически, кроме использования регистра DX нет другого способа адресоваться к портам ввода-вывода с 256 по 65535.
Другие уникальные качества регистра DX относятся к операциям деления и умножения. Когда вы делите 32-битовое делимое на 16-битовый делитель, старшие 16 битов делимого должны быть помещены в регистр DX (младшие 16 битов делимого должны быть помещены в регистр AX). После выполнения деления остаток также сохраняется в регистре DX (частное от деления будет записано в AX). Аналогично, когда вы перемножаете два 16-битовых сомножителя, старшие 16 битов произведения сохраняются в DX (младшие 16 битов записываются в регистр AX).
Регистр DX можно интерпретировать, как два 8-разрядных регистра - DH и DL.
Как и регистр BX, регистр SI может использоваться, как указатель на ячейку памяти. Особенно полезно использовать регистр SI для ссылки на память в строковых командах процессора 8086, которые не только изменяют содержимое по адресу памяти, на который указывает SI, но к SI также добавляется или вычитается 1. Это может оказаться очень эффективным при организации доступа к последовательным ячейкам памяти (например, к строке текста). Кроме того, можно сделать так, что строковые команды будут автоматически определенное число раз повторять свои действия, так что отдельная команда может выполнить сотни, а иногда и тысячи действий.
Регистр DI очень похож на регистр SI в том плане, что его можно использовать в качестве указателя ячейки памяти. При использовании его в строковых командах регистр DI несколько отличается от регистра SI. В то время как SI всегда используется в строковых командах, как указатель на исходную ячейку памяти (источник), DI всегда служит указателем на целевую ячейку памяти (приемник). Кроме того, в строковых командах регистр SI обычно адресуется к памяти относительно сегментного регистра DS, в то время как DI всегда адресуется к памяти относительно сегментного регистра ES. Когда SI и DI используются в качестве указателей на ячейки памяти в других командах (не строковых), то они всегда адресуются к памяти относительно регистра DS.
Как и регистры BX, SI и DI, регистр BP также может использоваться в качестве указателя на ячейку памяти, но здесь есть некоторые отличия. Регистры BX, SI и DI обычно ссылаются на память относительно сегментного регистра DS (или, в случае использования в строковых командах регистра DI, относительно сегментного регистра ES), а регистр BP адресуется к памяти относительно регистра SS (сегментный регистр стека). Регистр BP создан для обеспечения работы с параметрами процедур, локальными переменными и других случаев, когда требуется адресация к памяти с использованием стека.
Регистр SP называется также указателем стека. Это "наименее общий" из регистров общего назначения, поскольку он практически всегда используется для специальной цели - обеспечения стека. Стек - это область памяти, в которой можно сохранять значения и из которой они могут затем извлекаться по дисциплине "последний- пришел-первый-ушел" (LIFO). То есть последнее сохраненное в стеке значение будет первым значением, которое вы получите при чтении из стека.
Регистр SP в каждый момент времени указывает на вершину стека. Вершина стека - это то место, в котором в стеке сохраняется следующее помещенное туда значение. Действие, состоящее в занесении значений в стек, называют также "заталкиванием" (pushing) в стек (для этого используется команда PUSH). Аналогично, действие, состоящее в извлечении (выборке) значений из стека, называют также "выталкиванием" (popping) из стека (для этого используется команда POP).
Хотя процессор 8086 и позволяет записывать значения в SP или складывать и вычитать хранящиеся в регистре SP значения (как это можно делать с обычными регистрами общего назначения), вам не следует к этому прибегать, если вы в точности не знаете, что делаете. Если вы изменяете SP, то изменяется расположение вершины стека, что быстро может привести к неприятностям, так как занесение данных в стек и извлечение их из него не является единственным способом использования стека. Стек используется всякий раз, когда вы вызываете или возвращаетесь из подпрограммы (процедуры или функции). Кроме того, стек используют некоторые системные программы (такие, как драйвер клавиатуры или системный таймер), когда они прерывают процессор 8086, чтобы выполнить свои функции. Все это означает, что стек может в любой момент потребоваться. Если вы измените SP, то правильное значение стека может оказаться недоступным, когда он потребуется системным программам. Можно свободно выполнять операции занесения в стек и извлечения из него, вызовы и возвраты управления, но не изменяйте значения регистра SP непосредственно. Любой из других семи регистров общего назначения можно спокойно изменять в любой момент.
УКАЗАТЕЛЬ КОМАНД
Указатель команд (регистр IP) всегда содержит смещение в памяти, по которому хранится следующая выполняемая команда. Когда выполняется одна команда, указатель команд перемещается таким образом, чтобы указывать на адрес памяти, по которому хранится следующая команда. Обычно следующей выполняемой командой является команда, хранимая по следующему адресу памяти, но некоторые команды, такие, как вызовы или переходы, могут привести к тому, что в указатель команд будет загружено новое значение. Таким образом, будет выполнен переход на другой участок программы.
Значение счетчика команд нельзя прочитать или записать непосредственно. Загрузить в указатель команд новое значение может только специальная команда перехода.
Указатель команд сам по себе не определяет адрес, по которому находится следующая выполняемая команда. Картину здесь опять усложняет сегментная организация памяти процессора 8086. Для извлечения команды предусмотрен регистр CS, где хранится базовый адрес, при этом указатель команд задает смещение относительно этого базового адреса.
СЕГМЕНТНЫЕ РЕГИСТРЫ
Теперь мы подошли к наиболее необычному аспекту процессора 8086 - сегментации памяти. Основной предпосылкой сегментации является следующее: процессор 8086 может адресоваться к 1 мегабайту памяти. Для адресации ко всем ячейкам адресного пространства в 1 мегабайт необходимы 20-разрядные сегментные регистры. Однако процессор 8086 использует только 16-разрядные указатели на ячейки памяти. Как же тогда согласовать 16-разрядные указатели процессора 8086 и 20-разрядные адреса?
Ответ состоит в том, что процессор 8086 использует двухступенчатую схему адресации. Да, используются 16-разрядные указатели, но эта форма представляет собой только часть полной схемы адресации. Каждый 16-разрядный указатель памяти или смещение комбинируется с содержимым 16-разрядного сегментного регистра для формирования 20-разрядного адреса памяти.
Сегменты и смещения комбинируются следующим образом: значение сегмента сдвигается влево на 4 (то есть умножается на 16), а затем складывается со смещением. Фактически, для доступа к памяти процессор всегда использует пару "сегмент:смещение". Все команды и режимы адресации процессора 8086 по умолчанию работают относительно того или иного сегментного регистра, хотя в некоторых командах можно явно указать, что нужно использовать желаемый сегментный регистр.
Вам редко потребуется загружать значение непосредственно в сегментный регистр. Вместо этого вы будете загружать в сегментные регистры имена сегментов, которые в ходе ассемблирования, компоновки и выполнения превращаются в числа. Это необходимо, поскольку нет способа сказать заранее, где в памяти будет находиться данный сегмент: это зависит от версии DOS, числа и размера резидентных в памяти программ, а также потребности в памяти остальной части программы. Использование имен сегментов позволяет ассемблеру и операционной системе DOS выполнять подобные вычисления.
Использование сегментов процессора 8086 приводит к некоторым интересным моментам. Один из них состоит в том, что только блок памяти размером в 64К в любой момент может адресоваться через сегментный регистр, так как 64К - это максимальный объем памяти, к которой можно адресоваться с помощью 16-битового смещения. Это может оказаться неприятным при работе с большим (более 64К) объемом памяти, так как и значение сегментного регистра, и смещение, придется часто изменять.
Адресация к большим блокам памяти в процессоре 8086 может представлять еще большую трудность, поскольку, в отличие от регистров общего назначения, сегментные регистры не могут использоваться в качестве источников или приемников в арифметических и логических команд. Фактически, единственная операция, которую можно выполнять с сегментными регистрами, состоит в копировании значений между сегментными регистрами и другими общими регистрами или памятью.
Вторая особенность использования сегментов состоит в том, что каждая ячейка памяти адресуется через многие возможные сочетания "сегмент:смещение". Например, адрес памяти 100h адресуется с помощью следующих значений "сегмент:смещение": 0:100h, 1:F0h, 2:E0h и т.д., так как при вычислении всех этих пар "сегмент:смещение" получается значение адреса 100h.
Аналогично регистрам общего назначения каждый сегментный регистр играет свою, конкретную роль. Регистр CS указывает на код программы, DS указывает на данные, SS - на стек. Сегментный регистр ES - это дополнительный сегмент, который может использоваться так, как это необходимо. Рассмотрим сегментные регистры более подробно.
Регистр CS указывает на начало блока памяти объемом 64К, или сегмент кода, в котором находится следующая выполняемая команда. Следующая команда, которую нужно выполнить, находится по смещению, определяемому в сегменте кода регистром IP, то есть на нее указывает адрес (в форме "сегмент:смещение") CS:IP. Процессор 8086 никогда не может извлечь команду из сегмента, отличного от того, который определяется регистром CS.
Регистр CS можно изменять с помощью многих команд, включая отдельные команды перехода, вызовы и возвраты управления. Ни при каких обстоятельствах регистр CS нельзя загрузить непосредственно. Никакие другие режимы адресации или указатели памяти, отличные от IP, не могут нормально работать относительно регистра CS.
Регистр DS указывает на начало сегмента данных, которые представляет собой блок памяти объемом 64К, в котором находится большинство размещенных в памяти операндов. Обычно для ссылки на адреса памяти используются смещения, предполагающие использование регистров BX, SI или DI. В основном сегмент данных представляет собой то, о чем говорит его название: как правило это сегмент, в котором находится текущий набор данных.
Регистр ES указывает на начало блока памяти объемом 64К, который называется дополнительным сегментом. Как и подразумевает его название, дополнительный сегмент не служит для какой-то конкретной цели, но доступен тогда, когда в нем возникает необходимость. Иногда сегмент ES используется для выделения дополнительного блока памяти объемом 64К для данных. Однако доступ к памяти в дополнительном сегменте менее эффективен, чем доступ к памяти в сегменте данных.
Особенно полезен дополнительный сегмент, когда используются строковые команды. Все строковые команды, которые выполняют запись в память, используют в качестве адреса, по которому нужно выполнить запись, пару регистров ES:DI. Это означает, что регистр ES особенно полезен при использовании его в качестве целевого сегмента при копировании блоков, сравнении строк, просмотре памяти и очистке блоков памяти.
Билет 31:
ФУНКЦИОНАЛЬНЫЕ БЛОКИ МИКРО-ЭВМ
Микропроцессорные интегральные схемы (МП ИС) и микро-ЭВМ, построенные на их основе, явились следствием бурного развития микроэлектроники, позволившего в одном кристалле полупроводника размещать сложные вычислительные структуры, содержащие десятки тысяч транзисторов. Изготовление больших интегральных схем (БИС) сопряжено с трудоемкой работой по разработке схем, фотошаблонов и подготовкой производства и служб контроля технологических параметров и характеристик БИС. Снижение себестоимости БИС возможно лишь при максимальной автоматизации этапов, предшествующих их изготовлению, и массовости производства.
Массовое производство БИС предполагает широкий спрос потребителя, а следовательно, возможность ее использования для большого круга решаемых задач. Микропроцессорные БИС (МП БИС) представляют тот класс интегральных схем, который сочетает в себе высокую степень интеграции, обеспечивающую огромные функциональные возможности, с большой универсальностью по применению [б].
Д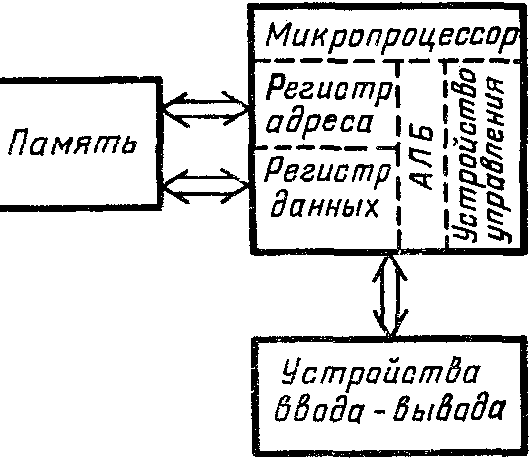 остигается
универсальность тем, что в МП БИС
реализованы сложные устройства,
позволяющие выполнять над исходными
числами логические и арифметические
функции, при этом управление процессом
вычисления ведется программно. Изменение
программы вычисления позволяет
осуществить вычисление любой сложной
функции.
остигается
универсальность тем, что в МП БИС
реализованы сложные устройства,
позволяющие выполнять над исходными
числами логические и арифметические
функции, при этом управление процессом
вычисления ведется программно. Изменение
программы вычисления позволяет
осуществить вычисление любой сложной
функции.
Если рассмотреть схему микро-ЭВМ (рис. 6.1), то можно прийти к выводу, что в ней содержатся те же блоки, на которых строились вычислительные машины предыдущих поколений. Однако микро-ЭВМ имеет некоторое архитектурное отличие от предшествующих ЦВМ, обусловленное стремлением объединить в БИС, на которых строится микро-ЭВМ, узлы и блоки, способные проводить сложные преобразования информации при минимальном количестве внешних проводников. Эта особенность обусловлена возможностью построения в БИС сложных электронных схем при ограничении по числу внешних проводников, не превышающих, как правило, 50 или 100контактов.
С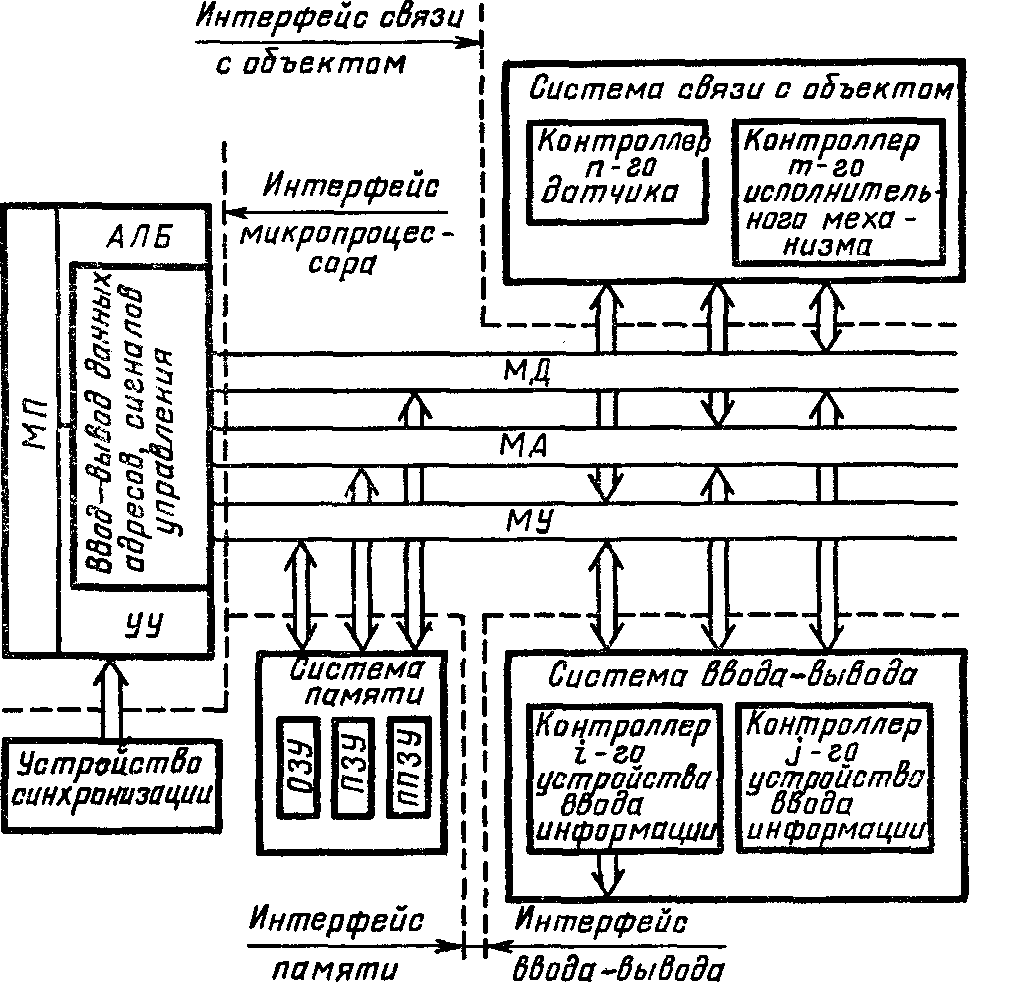 труктура
процессора микро-ЭВМ строится с учетом
этих особенностей БИС. Наиболее
распространенной является схема
микро-ЭВМ, имеющая две или три общие
магистрали, к которым под воздействием
устройства управления могут поочередно
подключаться входящие в микропроцессор
узлы. Такая структура требует ограниченного
числа внешних контактов, но обмен
информацией между узлами и блоками
должен осуществляться в определенной
последовательности.
труктура
процессора микро-ЭВМ строится с учетом
этих особенностей БИС. Наиболее
распространенной является схема
микро-ЭВМ, имеющая две или три общие
магистрали, к которым под воздействием
устройства управления могут поочередно
подключаться входящие в микропроцессор
узлы. Такая структура требует ограниченного
числа внешних контактов, но обмен
информацией между узлами и блоками
должен осуществляться в определенной
последовательности.
В микро-ЭВМ процессор строится на БИС, образующих базовый МП-комплект. Процессор микро-ЭВМ может быть реализован в виде одной (однокристальный микропроцессор) или нескольких БИС (многокристальный микропроцессор). Для построения остальных блоков микро-ЭВМ используются специализированные БИС или ИС средней степени интеграции. Основные типы ИС, применяемых в микроЭВМ, могут быть отнесены к одной из четырех групп: базовый микропроцессорный комплект (МПК) ИС; ИС запоминающих устройств; ИС устройств ввода — вывода информации в микропроцессор; ИС для связи микро-ЭВМ с объектами управления.
В соответствии с разработкой специализированных ИС для различных блоков микро-ЭВМ структурная схема ее может быть представлена как совокупность функциональных блоков (рис. 6.2), соединенных между собой в соответствии с требованиями интерфейсов. В приведенной схеме обработку информации осуществляет микропроцессор, синхронизируемый тактовыми импульсами устройства синхронизации. Обмен информацией между микропроцессором и остальными блоками микро-ЭВМ осуществляется по трем магистралям: адресной, данных и управляющей.
Магистраль адреса (МА) служит для передачи кода адреса, по которому проводится обращение к устройствам памяти, ввода — вывода или другим внешним устройствам, подключенным к микропроцессору. Обрабатываемая информация и результаты вычислений передаются по магистрали данных (МД).
Магистраль управления (МУ) передает управляющие сигналы на все блоки микро-ЭВМ, настраивая на нужный режим устройства, участвующие в выполняемой команде.
Использование в микро-ЭВМ большого числа магистралей, в данном примере трех типов, обеспечивает высокое быстродействие и упрощает процесс вычисления. Возможно построение микро-ЭВМ с одной или двумя магистралями, по которым последовательно передаются код адреса и обрабатываемая информация, при этом увеличивается время выполнения команды и усложняется организация обмена информацией между узлами.
Структура микро-ЭВМ определяется архитектурой микропроцессора, составом входящих в МП БИС функциональных узлов, количеством внешних магистралей и организацией обмена информацией [6].
Микропроцессоры на одном кристалле — однокристальныеМП — отличаются фиксированной разрядностью и фиксированной системой команд. Функциональная законченность однокристальных МП требует разместить в одном кристалле блоки дешифратора команд и устройства управления, арифметическо-логический блок, устройства управления внешним обменом, каскады согласования внутренних и внешних сигналов. хМногокристальные МП строятся на основе совокупности БИС, представляющих собой МПК. Каждая БИС, входящая в МПК, позволяет реализовать узел или функциональный блок узла МП.
Наиболее характерными узлами МП являются арифметическо-логический блок (АЛБ), составляющий основу операционного устройства, и устройство управления (УУ). Арифметическо-логический блок предназначен для обработки информации в соответствии с поступающим на него управляющим кодом. Выполняемые в АЛБ операции могут быть разделены на т-ри группы: арифметические, сдвига, логические и пересылок.
В качестве арифметических операций обычно используются операции: сложения и вычитания двух кодов; сложения и вычитания единицы; сложения и вычитания с содержимым признака операции. К операциям сдвига относятся операции арифметического, логического и циклического сдвигов вправо и влево содержимого регистров АЛБ. Логические операции и операции пересылок обеспечивают выполнение основных логических функций (сложение, умножение) над содержимым регистров и пересылки содержимого между регистрами и между регистрами и внешними магистралями.
Устройство управления формирует управляющие сигналы на все блоки микро-ЭВМ, синхронизируя их работу, и обеспечивает выборку команд из памяти в соответствии с заложенным алгоритмом.
Билет 33:
ДЕШИФРАТОРЫ
Дешифратором называтся комбинационная схема с несколькими входами и выходами, преобразующая код, подаваемый на входы, в сигнал на одном из выходов.
В общем случае дешифратор с n входами имеет 2 5n 0 выходов, так как n-разрядный код входного слова может принимать 2 5n 0 различных значений.
Рассмотрим в качестве примера следующую схему:
Условное обозначение дешифратора:
МУЛЬТИПЛЕКСОРЫ
Мультиплексором называется схема, осуществляющая передачу сигналов с одной из входных линий на выходную. Выбор входной (информационной) линии производится с помощью кода, подаваемого на управляющие входы мультиплексора. Мультиплексор с k управляющими входами имеет 2 5k 0 информационными входов.

Условное обозначение мультиплексора:
ОСНОВНЫЕ ПРИНЦИПЫ ПОСТРОЕНИЯ УСТРОЙСТВ ОБРАБОТКИ ЦИФРОВОЙ ИНФОРМАЦИИ
Принцип академика В.М. Глушкова гласит, что в любом устройстве обработки цифровой информации можно выделить операционный и управляющий блоки. Такой подход упрощает проектирование, а также облегчает понимание процесса функционирования вычислительного устройства.
Операционный блок состоит из регистров, сумматоров и других узлов, производящих прием из внешней среды и хранение кодов, их преобразование и выдачу результатов работы во внешнюю среду, а также выдачу в управляющий блок и внешнюю среду оповещающих сигналов.
Процесс функционирования во времени устройства обработки состоит из последовательности тактовых интервалов, в которых операционный блок производит элементарные преобразования кодов (передачу кода из одного регистра в другой, взятие обратного кода, сдвиг и т.д.).
Элементарная функциональная операция, выполняемая за один тактовый интервал и приводимая в действие одним управляющим сигналом называется микрооперацией.
Управляющий блок вырабатывает распределенную во времени последовательность управляющих сигналов, порождающих в операционном блоке нужную последовательность микроопераций.
Последовательность управляющих сигналов (микрокоманд) опеделяется кодом операции, поступающим извне, состоянием операндов и промежуточными результатами преобразований.
Существует два основных типа управляющих автоматов:
1) Управляющий автомат с жесткой логикой. Для каждой операции, задаваемой кодом операции команды, строится набор комбинационных схем, которые в нужных тактах возбуждают соответствующие управляющие сигналы.
2) Управляющий автомат с хранимой в памяти логикой. Каждой выполняемой в операционном устройстве операции ставится в соответствие совокупность хранимых в памяти слов - микрокоманд, содержащих информацию о микрооперациях, подлежащих выполнению в течение одного машинного такта, и указание, какая микрокоманда должна выполняться следующей.
Последовательность микрокоманд, обеспечивающая выполнение некоторой операции (например, умножения), называется микропрограммой данной операции.
Функционирование вычислительного устройства может быть описано совокупностью реализуемых в нем микропрограмм. Это в ряде случаев удобный, хотя и не единственно возможный способ описания цифровых устройств.
ПРИНЦИПЫ ОРГАНИЗАЦИИ АРИФМЕТИКО-ЛОГИЧЕСКИХ УСТРОЙСТВ
Арифметико-логические устройства (АЛУ) служат для выполнения арифметических и логических преобразований над словами, называемыми в этом случае операндами. АЛУ служит основной частью операционного блока ЭВМ.
Выполняемые АЛУ операции можно разделить на следующие группы:
операции двоичной арифметики для чисел с фиксированной запятой;
операции двоичной арифметики для чисел с плавающей запятой;
операции десятичной арифметики;
операции индексной арифметики;
операции специальной арифметики;
операции над логическими кодами;
операции над алфавитно-цифровыми полями.
Современные ЭВМ общего назначения обычно реализуют операции всех приведенных выше групп, а малые и микроЭВМ часто не имеют аппаратуры арифметики чисел с плавающей запятой, десятичной арифметики и операций над алфавитно-цифровыми полями. В этом случае недостающие операции реализуются специальными программами.
К арифметическим операциям относятся сложение, вычитание, взятие модулей ("короткие операции"), и умножение и деление ("длинные операции").
Группу логических операций составляют операции дизъюнкция (логическое ИЛИ) и конъюнкция (логическое И) над многоразрядными двоичными словами, а также операция сравнения кодов на равенство.
Специальные арифметические операции включают в себя нормализацию, арифметический сдвиг (сдвигаются только цифровые разряды, а знаковый остается на месте), логический сдвиг (знаковый разряд сдвигается вместе с цифровыми).
Классификация АЛУ
По способу действия над операндами АЛУ делятся на последовательные и параллельные. В последовательных АЛУ операнды представляются в последовательном коде, а операции производятся последовательно во времени над их отдельными разрядами. В настоящее время АЛУ этого типа нигде не применяются. В параллельных АЛУ операнды представляются параллельным кодом и операции совершаются параллельно во времени над всеми разрядами операндов.
По способу представления чисел различают АЛУ:
1) для чисел с фиксированной запятой;
2) для чисел с плавающей запятой;
3) для десятичных чисел.
По характеру использования элементов и узлов АЛУ делятся на блочные и многофункциональные. В блочном АЛУ операции над числами с фиксированной и плавающей запятой, десятичными числами и алфавитно-цифровыми полями выполняются в отдельных блоках, при этом повышается скорость работы, так как блоки могут параллельно выполнять соответствующие операции, но значительно возрастают затраты оборудования. В многофункциональных АЛУ операции для всех форм представления чисел выполняются одними и теми же схемами, которые коммутируются нужным образом в зависимости от требуемого режима работы.
Билет 36:
Виды и типы памяти