

7 Системы обработки многопользовательских баз данных
7.1 Эволюция концепций обработки данных
Обработка данных – это совокупность методов и средств, осуществляющих преобразование данных. Она включает в себя ввод данных в компьютер, преобразование и отбор данных по каким-либо критериям и вывод данных в удобном для пользователя виде. Одновременно с развитием вычислительной техники развивались и следующие концепции обработки данных:
1 Обработка на мэйнфреймах в пакетном режиме. Для обработки данных в этом режиме пользователь составлял задания на выполнение определенных операций над исходной программой и/или счет по программе. Исходная программа – это программа, написанная на алгоритмическом языке.
Задания, записанные на специальном языке описания заданий, а также текст программы и исходные данные наносились на бумажный носитель – перфокарты, которые формировались в пакет заданий. Пользователи передавали свои пакеты заданий в вычислительный центр на обработку на мэйнфрейме. Распечатанные результаты пользователи получали обычно только на следующий день. Отсутствие непосредственного контакта пользователя с компьютером и использование перфокарт увеличивали время получения результата обработки.
2 Обработка в многотерминальных системах. Такие системы появились по мере удешевления компьютеров в начале 1960-х гг. и позволили пользователям непосредственно общаться с компьютером. К мэйнфрейму, расположенному на вычислительном центре, были подключены терминалы, рассредоточенные по всему предприятию. Терминал – это устройство, предназначенное для взаимодействия с вычислительной системой или сетью ЭВМ. Первоначально терминалы были неинтеллектуальным, не имели собственных вычислительных ресурсов, а осуществляли только операции ввода-вывода.
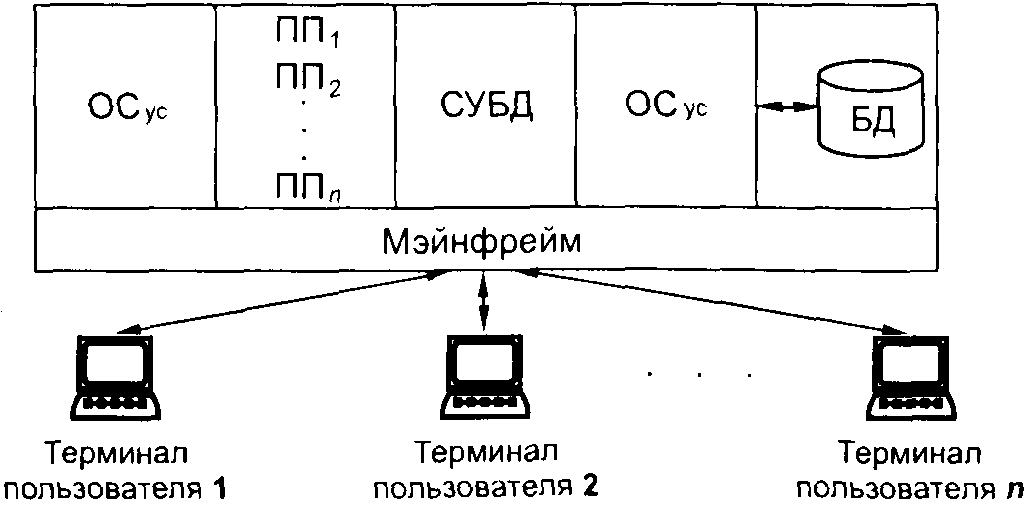
Пользователи с помощью терминалов передавали запросы к базе данных. Часть операционной системы, отвечающая за управление связью (ОСус), принимала их и передавала соответствующим прикладным программам (ПП), которые обращались к СУБД, а она выполняла операции с базой данных, используя часть операционной системы, отвечающую за управление данными (ОСуд). Результаты запросов возвращались пользователям, находящимся у терминалов, подсистемой управления связью. Многотерминальные системы называют еще системами удаленной обработки данных.
Пользовательские запросы обрабатывались в режиме разделения времени. Время обработки было достаточно мало, и пользователь не замечал параллельной работы с мэйнфреймом других пользователей. У него создавалась иллюзия единоличного владения компьютером.
3 Обработка на автономных персональных компьютерах. Она стала возможной в 1980-е гг. в связи с появлением этой техники. На персональном компьютере (ПК) устанавливалась СУБД, с помощью которой пользователь создавал на данном компьютере свою локальную базу данных и работал с ней в однопользовательском режиме. Такая СУБД называлась настольной. Она была ответственна за выполнение запросов и поддержание целостности базы данных. К аппаратному обеспечению компьютера предъявлялись скромные требования. Данные передавались с компьютера на компьютер на внешних носителях – дискетах. Настольные СУБД были просты для освоения и использования, обладали понятным пользовательским интерфейсом, ориентировались на самую широкую категорию пользователей – непрофессионалов, обеспечивали хорошее быстродействие при работе с небольшими базами данных.
4 Обработка с использованием компьютерных сетей. Основная концепция такой обработки заключается в обмене данными между компьютерами в автоматическом режиме посредством линий связи и специального оборудования. В первых компьютерных сетях были реализованы службы обмена файлами, синхронизации файлов (устранение различий между файлом, хранящимся на одном компьютере, и версией того же файла на другом компьютере), электронной почты и другие сетевые службы, ставшие теперь традиционными.
ПК стали идеальными элементами для построения сетей. С одной стороны, они были достаточно мощными для работы сетевого программного обеспечения, а с другой – не очень дорогими. При их объединении совокупная вычислительная мощность оказывалась достаточной для решения сложных задач, и стало возможным совместное использование периферийных устройств (например, принтеров) и дисковых массивов (RAID-массивов). Поэтому ПК стали преобладать в локальных сетях, причем в качестве не только компьютеров пользователей, но и центров хранения и обработки данных, потеснив с этих привычных ролей мэйнфреймы. Обработка данных с использованием компьютерных сетей является в настоящее время наиболее распространенной. При этом наблюдается тенденция к унификации технологий обработки данных в локальных сетях и в глоб. сети Интернет.
7.3 Системы совместного использования файлов
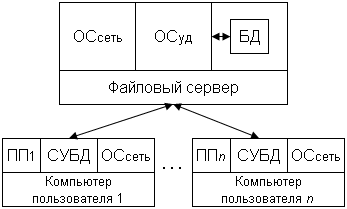
7.3.1 Обработка запросов в архитектуре файл/сервер
7.3.2 Обработка запросов в архитектуре клиент/сервер
|
|
|
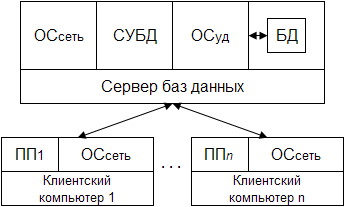
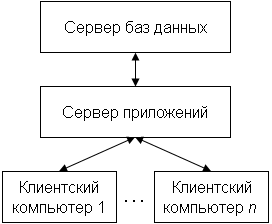
7.4 Системы обработки распределенных БД
7.4.1 Архитектура системы обработки РаБД
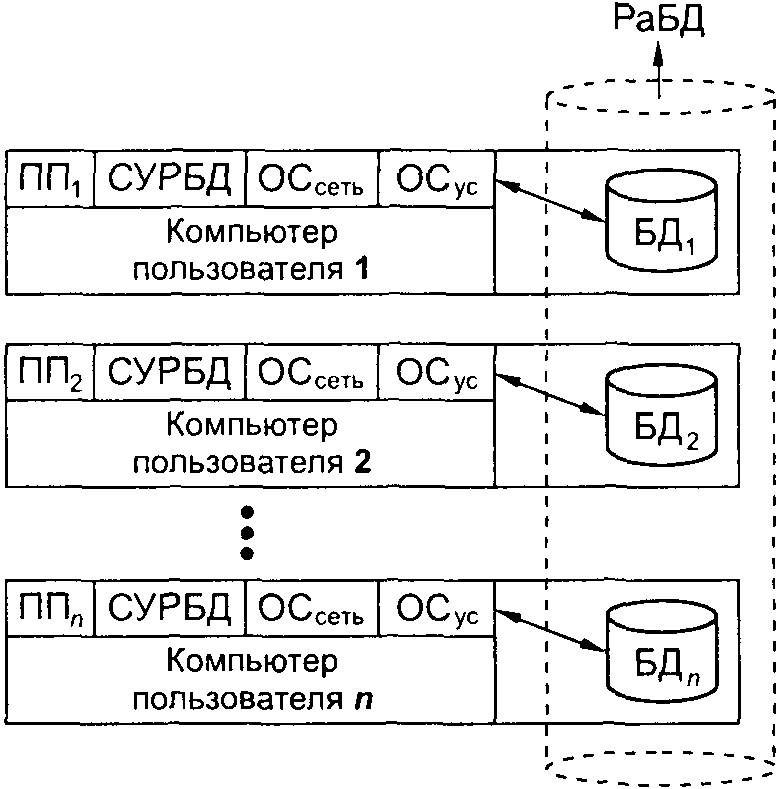
7.4.3 Правила К. Дейта для РаБД
Американский ученый Крис Дейт сформулировал 12 правил, которым должна следовать РаБД:
1) локальная независимость предполагает, что управление локальными БД выполняется на каждом из узлов сети независимо от других узлов сети;
2) отсутствие опоры на центральный узел означает, что ни один узел сети не зависит от центрального или какого-либо другого узла. Все узлы имеют равные возможности;
3) непрерывное функционирование состоит в том, что система продолжает функционировать и в случае сбоя на каком-либо узле, и при неисправности узла, и при расширении сети;
4) независимость от расположения означает полную прозрачность расположения данных. Пользователь, обращающийся к РаБД, ничего не должен знать о реальном, физическом размещении данных в узлах сети;
5) независимость от фрагментации дает пользователю возможность работать с РаБД как с единой БД, хотя она может быть физически разделена на отдельные фрагменты;
6) независимость от репликации предполагает, что процесс внесения изменений в реплики баз данных невидим для пользователей;
7) обработка распределенных запросов трактуется как возможность выполнения операций выборки распределенных данных в виде обычного запроса на языке SQL как и операций выборки локальных данных;
8) управление распределенными транзакциями означает возможность выполнения операций обновления РаБД, не разрушая целостность и согласованность данных;
9) аппаратная независимость означает, что в качестве узлов сети могут выступать компьютеры любых моделей и любых производителей;
10) независимость от операционной системы предполагает использование различных операционных систем, управляющих узлами сети;
11) независимость от сети означает возможность использования различных сетей и сетевых технологий для соединения узлов;
12) независимость от типа СУБД дает возможность использования СУБД различных производителей, которые должны поддерживать один и тот же интерфейс взаимодействия между узлами.
Достоинства РаБД состоят в том, что они более полно отражают территориально распределенную структуру предприятий и обеспечивают большую живучесть информационной системы, так как в случае разрушения одной из локальных БД другие БД остаются работоспособными.
К недостаткам РаБД следует отнести повышенную сложность их практической реализации.