

-
Классификация баз данных
Прежде всего необходимо отметить разделение автоматизированных информационных систем на два класса: документальные и фактографические. Документальные системы предназначены для работы с текстовыми данными или документами. В силу этого они имеют в наличии поисковые массивы документов, словари (тезаурусы), инвертированные массивы и т.п., т.е. все то, что облегчает поиск информации, максимально приближенной к разговорному языку. Все остальные базы данных относятся к фактографическим системам, которые еще называют банками данных.
Задачи обработки данных - это специальный класс решаемых на ЭВМ задач, связанных с вводом, хранением, сортировкой, отбором по заданному условию и группировкой записей данных однородной структуры. При этом предусматривается генерация для пользователя различных отчетов, как правило, табличной формы, обеспечивающих систематизацию и, возможно, агрегирование данных, с промежуточными итогами по некоторым элементам данных для групп записей и с полными итогами по всему отчету.
При построении информационного обеспечения любой системы необходимо начинать рассмотрение ее предметной области (ПО). Под предметной областью обычно понимают совокупность реальных объектов (сущностей), как часть реального мира, которую предстоит изучить, систематизировать и, в конечном итоге, автоматизировать. Именно на ее основе может быть построена информационная система. Примером ПО может служить лицо (фамилия, имя отчество, возраст, пол и т.д.), Транспортное средство (марка, цвет, гос.номер и т.д.).
Ввиду громоздкости описания предметной области в терминах объектов множество ПО разбивают на типы объектов. Каждый такой тип обладает одинаковыми наборами свойств (атрибутов) объектов.
Всем объектам присваивается идентификатор для быстрого поиска элемента в базе. Для того, чтобы можно было однозначно ссылаться на определенный объект, существует уникальный идентификатор, называемый первичным ключом, в качестве которого может использоваться какой-либо обязательный атрибут объекта. Значения первичного ключа не могут обновляться. Примером первичного ключа автомобиля может служить его номер двигателя. В случае, если невозможно подобрать атрибут с уникальными значениями, то в качестве первичного ключа используется комбинация атрибутов (Например: Фамилия – Имя – Отчество – Год рождения). Вторичным ключом является не уникальный идентификатор.
Между объектами существуют структурные связи различной размерности (арности). Большинство связей ПО могут быть представлены простыми или составными бинарными связями (т.е. связи между двумя объектами или двумя множествами объектов). Их 3 типа:
а) один-к-одному (1:1)

б) один-ко-многим (1:n)
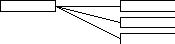
в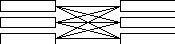 )
многие-ко-многим (m:n)
)
многие-ко-многим (m:n)
В основе построения любой базы данных лежит понятие структуризации информации, целью которого является наиболее полное отображение свойств реальных объектов.
Различают три основных уровня структуризации:
-
концептуальный (с позиции пользователя системой) осуществляющий сбор, анализ и редактирование требований к данным;
-
уровень реализации или логический уровень (с позиций прикладного программиста) где требования к данным преобразуются в структуры будущей системы;
-
физический (с позиций системного программиста), когда решаются вопросы, связанные с производительностью системы, определяется структура хранения данных и методы доступа.
Каждый этап имеет свою модель. Каждой модели соответствует инфологическое описание, т.е. "взгляд" на предметную область пользователя (оперативника, администратора БД, программиста) который, кстати, не связан со средствами реализации информационной системы [5].
Система баз данных поддерживает в памяти ЭВМ модель предметной области. Результат отображения предметной области в терминах модели данных является моделью баз данных. Вообще моделью данных называется формализованное описание информационных структур и операций над ними. Любая модель должна обеспечивать представление объектов предметной области, их атрибутов и структурных связей.
Наиболее известными и часто применяемыми являются три модели данных: иерархическая, сетевая и реляционная. В первых двух моделях база данных описывается графом, вершины которого соответствуют логическим записям, ребра - адресным указателям, обеспечивающими связи между записями. Иерархическое представление состоит их нескольких типов записей, один из которых определен как корневой (входной) тип данных [7]. Иерархическая модель данных используется в системах IMS, и SYSTEM 2000, отечественных (ИНЭС, ОКА, ДИАМС, ФОРБИН, КВАНТ, МИРИС [3]).
Сетевая модель подобна иерархической, но является более общей в том смысле, что любая запись может входить в любое число именованных связей как исходная или порожденная или как и то и другое. Поэтому здесь нет корневого узла, т.к. любая запись может быть определена как точка входа. Сетевые модели реализованы ряде систем основанных на модели CODASYL (IDMS, DMS1100, DBMS, отечественных - СЕТОР, СЕТЬ). Еще несколько систем, относящиеся к категории систем с инвертированными файлами, могут косвенно представить сетевую концепцию (Model 204, DATACOM/DB, ADABAS, отечественной - МОДИС).
В настоящее время наиболее широкое распространение получили реляционные (от английского relation - отношение) модели, благодаря тому, что к ней применима математическая теория множеств. Отношением R, определенным на множествах D1,D2,...,Dn, называют подмножество декартова произведения D1 x D2 x ... Dn. При этом множество D1, D2, ..., Dn называется доменами отношения, а элементы декартова произведения - кортежами отношения. Число n определяет степень (арность) отношения, а количество кортежей - его мощность [5].
Отношения удобно располагать в виде таблиц. При этом строки таблицы соответствуют кортежам, а столбцы - атрибутам. Каждый атрибут определен на некотором домене. Доменом называют множество атомарных значений. Несколько атрибутов отношения могут быть определены на одном и том же домене.
Множество объектов реляционной модели данных однородно - структура данных определяется только в терминах отношений. Основная единица обработки в реляционной модели данных не запись (как в сетевых и иерархических моделях), а множество записей - отношение.
Важной особенностью реляционной модели является то, что в отличии от иерархических и сетевых у нее отсутствует понятие групповые отношения, использующихся в последних для отражения ассоциаций между записями.
Чаще всего база данных организуется так, чтобы каждому состоянию предметной области соответствовало некоторое состояние БД. Однако, существуют базы организуемые таким образом, что наряду с текущим состоянием используется некоторая предыстория, хронология.
Различаются централизованные и распределенные базы данных. При использовании централизованной БД в локальных сетях доступ к ней осуществляется через ЭВМ данной сети. Распределенная БД состоит из нескольких, возможно пересекающихся и дублирующих частей данных, хранимых на разных ЭВМ, причем конечный пользователь может и не знать на какой именно ЭВМ расположены те или иные ее компоненты. Работа с такой базой данных ведется с помощью системы управления распределенной базой данных (СУРБД). А все данные и их размещение описываются в системном справочнике.