

2.4 Построение распознавателя для заданного конечного языка
На практике могут встречаться задачи, когда устройство должно реагировать только на определенные последовательности сигналов, подаваемых на вход. Если набор таких последовательностей конечен, то задача построения устройства может быть сформулирована в следующем виде. Задано множество слов в некотором алфавите А и требуется построить конечный распознаватель этого множества. Эта задача может быть решена путем построения автоматной грамматики для заданного конечного языка, как это было показано в предыдущем параграфе, и последующего построения автомата без выходов для этой грамматики.
Различают два вида автоматных распознавателей. Первый вид распознавателей используется для определения принадлежности входной цепочки заданному языку. Такой распознаватель должен иметь два состояния. Одно состояние должно показывать, что входная цепочка является допустимой и она принадлежит входному языку, а переход во второе состояние должно говорить о том, что цепочка не входит в язык.
Второй вид распознавателей применяется для определения цепочек, подаваемых на вход. Такой распознаватель должен иметь число заключительных состояний равным числу входных цепочек и еще одно состояние для указания того, что цепочка не принадлежит заданному языку.
В общем случае заданный конечный язык может содержать слова разной длины. Возможность построения детерминированного распознавателя для такого языка можно сформулировать следующим образом.
Утверждение. Если заданный конечный язык не содержит слов, являющихся начальными отрезками другого слова этого языка, то для него можно построить детерминированный конечный распознаватель.
В качестве примера построим распознаватель, определяющий принадлежность слов к заданному языку, который состоит из трехбуквенных слов двоичного алфавита Vт = {0,1}, содержащих две единицы:
L1= { 011, 101, 110 }
Построим А-грамматику, порождающую этот язык. В качестве нетерминальных символов будем использовать прописные буквы латинского алфавита. Начальный символ грамматики обозначим <I>. Все слова начинаются либо с 0, либо с 1, поэтому построим правила <I> ® 0 <A>, <I> ® 1 <B>. Слова, начинающиеся с 0, в качестве второго символа имеют 1 , следовательно, построим правило <A> ® 1 <C>. Слова, начинающиеся с 1, имеют второй буквой 0 или 1, поэтому построим правило <B> ® 0<D> и <B> ® 1<E> . Конечные правила должны иметь вид, определяемый последней буквой каждого слова, следовательно получаем правила <C> ® 1, <D> ® 1, <E> ® 0.
В результате получаем схему искомой грамматики в виде:
R = {<I> ® 0 <A>, <I> ® 1 <B>, <A> ® 1 <C>, <B> ® 0<D>, <B> ® 1 <E>, <C> ® 1, <D> ® 1, <E> ® 0}.
Обозначим состояния искомого распознавателя нетерминальными символами грамматики и добавим два символа Z и U для обозначения заключительных состояний. Дополним заключительные правила построенной грамматики символом Z. Затем для всех состояний, из которых не определены переходы для какого-либо входного символа, добавим переход из этих состояний в заключительное состояние U. В результате получаем диаграмму переходов распознавателя, изображенную на рис. 2.12.
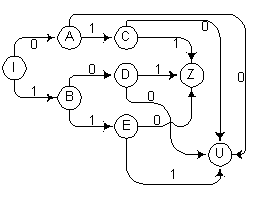
Рис. 2.12. Диаграмма переходов распознавателя, определяющего принадлежность цепочки к языку L1
Для того чтобы построить распознаватель, определяющий, какое из слов входного языка подано на вход, заключительные правила построенной грамматики нужно дополнить не одним символом Z , а тремя различными символами: Z1, Z2, Z3. В результате получаем диаграмму переходов распознавателя, изображенную на рис. 2.13.
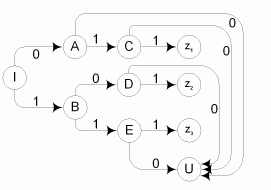
Рис. 2.13. Диаграмма переходов распознавателя входных цепочек языка L1
Распознаватели, построенные описанным способом, как правило, обладают избыточными состояниями. Такие состояния можно объединить с другими состояниями, не нарушая заданных функций распознавателя. Правила выявления и объединения состояний строятся на основе отношения эквивалентности, которое рассматривается в следующем параграфе.