

Тест на предпочтительность моделей
В качестве примера возьмем линейную и логарифмическую модели.
Проводится оценка параметров моделей, и выдаются прогнозные значения:
![]() ,
,
![]() .
.
Далее рассматриваются две вспомогательные регрессии:
-
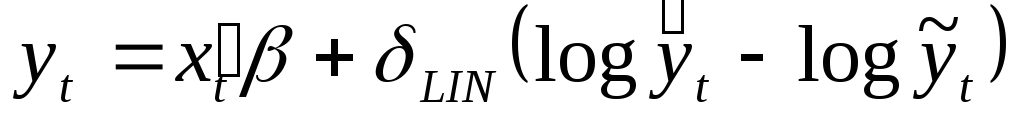 ,
,
выдвигается
гипотеза:
![]() ,
если гипотеза не отвергается, то линейная
модель предпочтительнее.
,
если гипотеза не отвергается, то линейная
модель предпочтительнее.
выдвигается
гипотеза:
![]() .
.
Метод максимального правдоподобия
Один из наиболее общих методов. Maximum likelihood.
Пусть
есть случайный вектор
![]() ,
распределение его зависит от параметра
,
распределение его зависит от параметра
![]() .
Оценка должна быть такова, чтобы
наблюдение было наиболее вероятно.
.
Оценка должна быть такова, чтобы
наблюдение было наиболее вероятно.
![]() - функция правдоподобия. Она исследуется
на вмаксимум по всем возможным значениям
параметра.
- функция правдоподобия. Она исследуется
на вмаксимум по всем возможным значениям
параметра.
В
некоторых случаях используется
логарифмическая функция правдоподобия:
![]() .
.
Далее
строится уравнение правдоподобия:
![]() .
.
Оценки,
получаемые этим методом, являются
состоятельными, несмещенными и
оптимальными. Кроме того, распределение
величины
![]() - асимптотически нормальное. Недостатком
метода является незнание закона
распределения.
- асимптотически нормальное. Недостатком
метода является незнание закона
распределения.
Пример.
-
одно наблюдение в схеме Бернулли. Y - бином
![]()
![]()
![]()
![]() ,
,
![]() - m+1
- мерный вектор,
- m+1
- мерный вектор,
![]() ;
;
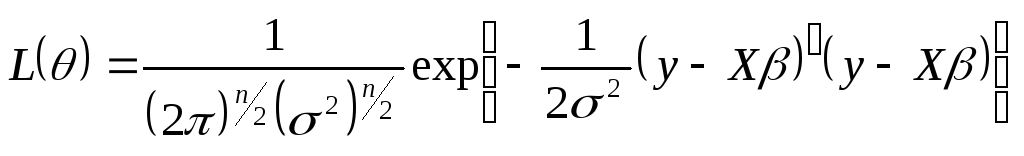 ;
;
![]() .
.
![]() ,
таким образом
,
таким образом
![]() ,
,
![]() .
.
Смещенность оценки максимального правдоподобияследует из инвариантности.
Modes with discret and limitted depended variables
Классический пример - выборы. Необходимо объяснить, от чего зависит выбор. Здесь y - качественная переменная. Следующий пример - переменная является количественной, но случай ранжирования. Т.е. по уровню дохода, как правило интересует не конкретное значение, превышение некоторого порогового значения. Третья группа переменных - количество чего-либо, но эти модели эквивалентны классике. И последняя группа limitted - смешанный тип. Например, сколько вы истратили на автомобиль в течение 2 лет.
Модели для первого, второго и четвертого вида не подлежат методу наименьших квадратов.
Модели бинарного выбора
![]()
1. Линейная модель вероятности
Обычная
регрессия.
![]() .
.
Дисперсия
![]() .
.
При оценке модели возникают проблемы. Эта модель полезна, если имеется много наблюдений и хорошая спецификация модели. Могут быть получены хорошие результат в смысле тенденции.
2. Probit, logit - модели
![]() ,
,
![]() ,
где значения F
- от 0 до 1.
,
где значения F
- от 0 до 1.
Необходимо ввести понятие латентных (скрытых) переменных.
Предполагается,
что есть скрытая переменная с обычным
уравнением регрессии:
![]() ,
а тогда
,
а тогда
![]() имеет вид:
имеет вид:
![]()
В общем случае сравнение идет не обязательно с нулем, а с величиной порога.
![]() .
Будем полагать, что
.
Будем полагать, что
![]() имеет симметричное распределение. Если
обозначить через
имеет симметричное распределение. Если
обозначить через
![]() функцию распределения
функцию распределения
![]() ,
то
,
то
![]() .
.
Задача
та же, оценить параметры. Параметры
порознь не идентифицируются, поэтому
можно считать, что
![]() .
.
Если
![]() ,
то имеем Probit
модель; если
,
то имеем Probit
модель; если
![]() ,
тогда Logit.
,
тогда Logit.
Модель в обоих случаях нелинейная, что затрудняет интепретацию. Теперь для объяснения параметров необходимо брать производную.
![]() ,
,
при этом смысл имеет только знак. Для оценки используется метод максимального правдоподобия. Предполагается, что y по t независимы.
Так для величины Бернулли получим следующее:
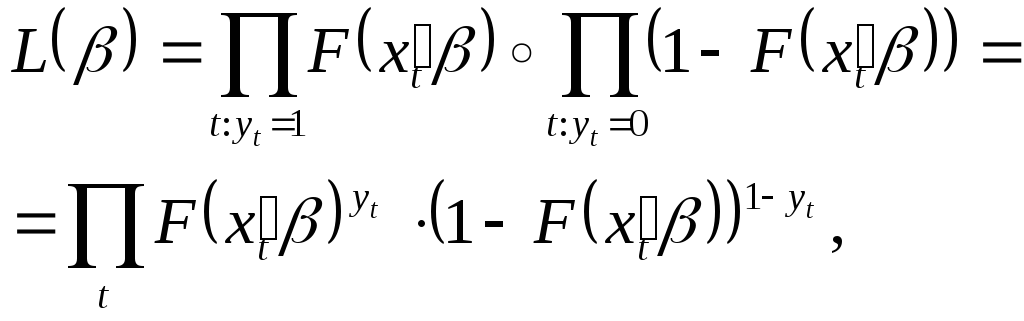
тогда
![]() .
.
После дифференцирования:
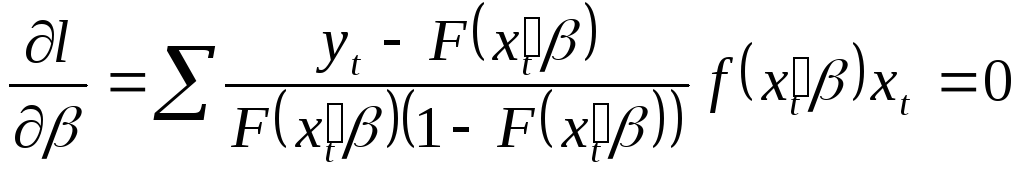 .
.
Коэффициент
перед
![]() называется обобщенным остатком, он
должен быть ортогонален регрессорам.
называется обобщенным остатком, он
должен быть ортогонален регрессорам.
Для logit модели этот вид упростится.
В случае ранжированного выбора проводится та же идеология со скрытой переменной, но порогов устанавливается несколько. В Eviews порог можно включать в оцениваемые параметры. Если альтернативы не ранжированы, то для построения модели используется дерево.