

6.4.4. Планирование работы с магнитными дисками
Как отмечалось ранее, доступ к данным, хранящимся на магнитном диске, осуществляется при помощи ряда магнитных головок записи-чтения, по одной головке на дисковую поверхность. Головке доступны только те данные, которые находятся на участке дисковой поверхности непосредственно под (над) ней. Поэтому для обеспечения возможности доступа к данным тот участок дисковой поверхности, с которого данные будут считываться (или записываться), должен вначале переместиться в процессе вращения дисков так, чтобы оказаться непосредственно под головкой. Время, затрачиваемое на перемещение участка поверхности из текущего положения в положение под головкой чтения-записи, называется временем ожидания.
Каждая из магнитных головок, если она не перемещается в данный момент, описывает на дисковой поверхности круговую дорожку, на которой могут размещаться данные. Все головки закреплены на одной каретке, или блоке позиционера. Каретка с головками может перемещаться по радиусу дисков в том или другом направлении. Группа дорожек, находящихся под всеми головками чтения-записи в каком-то конкретном положении каретки, образует вертикальный цилиндр. Процесс перемещения каретки с головками на новый цилиндр называется операцией поиска цилиндра или подвода.
Таким образом, чтобы получить возможность доступа к конкретной записи данных, расположенной на диске с перемещаемыми головками, в общем случае необходимо выполнить несколько операций. Прежде всего каретку необходимо установить на соответствующий цилиндр (поиска цилиндра). Затем нужно дождаться, когда под головкой окажется сектор, содержащий необходимую запись (это - поиск записи или поиск на дорожке, с которым связано время ожидания). Затем сама запись, которая в принципе может иметь произвольный размер (несколько секторов вплоть до полного размера круговой дорожки), должна пройти под головкой чтения-записи (это - так называемое время передачи). Поскольку каждая из перечисленных операций связана с механическим движением, общее время, требуемое для доступа к конкретной записи, может составлять до 0,1 секунды, что очень много по сравнению с весьма высокими скоростными показателями центральных устройств вычислительной машины.
В мультипрограммных вычислительных системах одновременно выполняется много процессов, которые могут генерировать запросы на обращение к дискам. Поскольку эти процессы чаще всего делают запросы гораздо быстрее, чем их обслуживают дисковые устройства с перемещающимися головками, то для каждого устройства формируется очередь запросов. Чтобы свести к минимуму время, затрачиваемое на поиск нужных записей, целесообразно упорядочить запросы по какому-либо принципу. Этот процесс называется планированием работы с диском. Планирование требует анализа ожидающих своей очереди запросов, чтобы определить наиболее эффективный порядок их обслуживания (таким образом, чтобы их выполнение обеспечивалось при минимальных механических перемещениях).
Наиболее распространенными алгоритмами планирования работы с дисками в настоящее время являются:
- первый пришедший обслуживается первым;
- с наименьшим временем поиска - первым;
- сканирования;
- циклического сканирования;
- N-шагового сканирования;
- схема Эшенбаха.
Рассмотрим указанные алгоритмы с учетом того, что очередь запросов содержит цилиндры со следующими номерами: 96, 184, 36, 120, 16, 124, 60, 64 - а головка в начальный момент времени позиционирована над цилиндром с номером 52.
Согласно алгоритму первый пришедший обслуживается первым (FCFS - First-Come-First-Served) запросы обслуживаются в порядке поступления (рис.6.8). Этот алгоритм справедлив в том смысле, что после поступления некоторого запроса его место в очереди фиксируется, и обслуживание никогда не откладывается из-за поступления запроса более высокого приоритета.
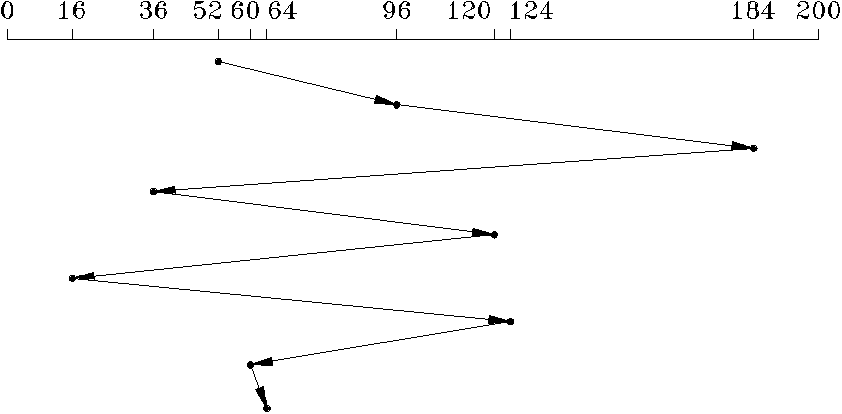
Рис. 6.8. Планирование работы с диском по алгоритму FCFS
В соответствии с алгоритмом с наименьшим временем поиска - первым (SSTF - Shorteset-Seek-Time-First) при позиционировании каретки с магнитными головками следующим выбирается запрос, для которого необходимо минимальное перемещение каретки, даже если этот запрос не является следующим в очереди (рис. 6.9). Поскольку обращения к диску проявляют тенденцию концентрироваться, то запросы на обращение к самым внутренним и самым наружным дорожкам могут обслуживаться гораздо хуже, чем запросы к средним дорожкам, что делает алгоритм SSTF мало пригодным для интерактивных систем. В основном, этот алгоритм применяется в системах пакетной обработки.
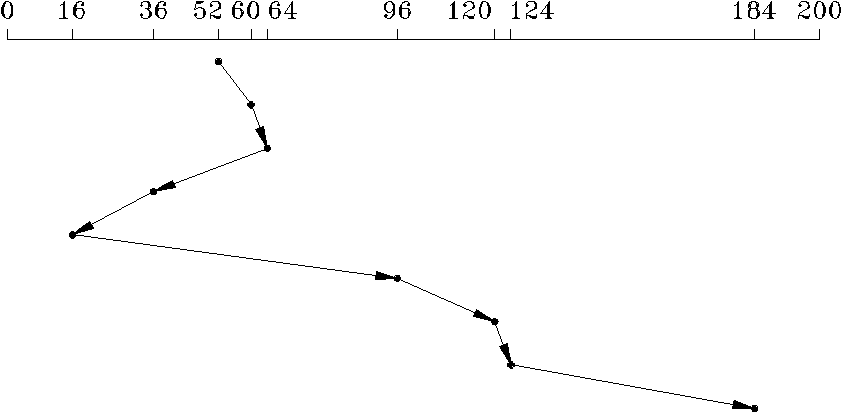
Рис. 6.9. Планирование работы с диском по алгоритму SSTF
При алгоритме по принципу сканирования (SCAN) каретка с головками совершает движения туда и обратно над поверхностью, обслуживая все запросы, встречающиеся по пути. Каретка меняет направление движения только в случае, если в текущем направлении больше нет запросов для обслуживания. Алгоритм SCAN в общем аналогична SSTF, если не считать того, что он выбирает для обслуживания тот запрос, для которого характерно минимальное расстояние поиска в привилегированном направлении (рис.6.10). Если в текущий
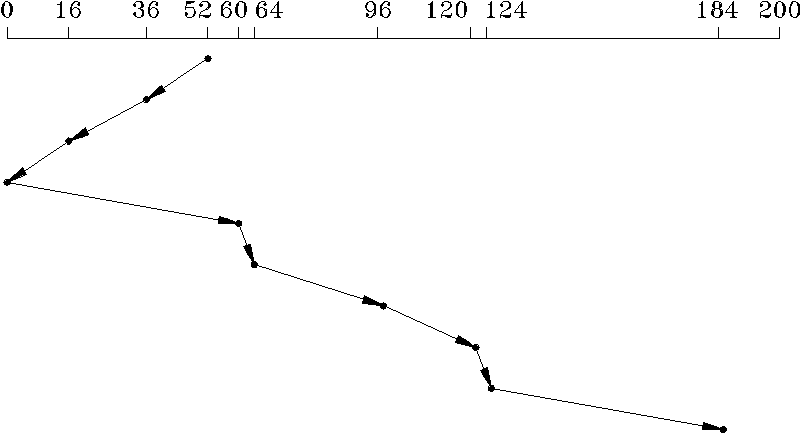
Рис. 6.10. Планирование работы с диском по алгоритму SCAN
момент привилегированное направление - от внутренних дорожек к наружным, то алгоритм SCAN выбирает запрос с минимальным расстоянием подвода в наружном направлении. При этом каретка с головками не меняет направления своего движения до тех пор, пока она не достигнет самого наружного цилиндра, или пока не выяснится, что больше нет запросов, ожидающих обслуживания при движении в текущем привилегированном направлении. В связи с тем, что головки сканируют диск, совершая движения туда и обратно, на крайних дорожках они бывают реже, чем на средних, однако в меньшей степени, чем при алгоритме SSTF. Алгоритм SCAN является основой большинства реализованных алгоритмов планирования работы с дисковой памятью.
В случае применения алгоритма циклического сканирования (C-SCAN - circular scan) Обслуживая запросы, каретка с головками, обслуживая запросы, движется в одном направлении, а именно в направлении к внутренней дорожке. Если впереди больше нет запросов для обслуживания, каретка скачком возвращается к началу, обслуживая запрос, ближайший к наружной дорожке, а затем продолжает движение внутрь (рис.6.11). Алгоритм C-SCAN можно реализовать таким образом, чтобы запросы, поступающие во время текущего прямого хода, обслуживались при следующем ходе, благодаря чему запросы на обращение к наружным и внутренним дорожкам будут обслуживаться так же, как и запросы к средним дорожкам.
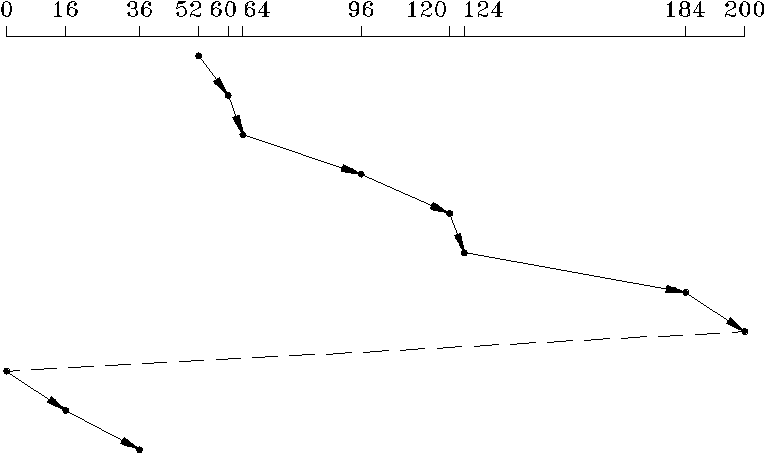
Рис. 6.11. Планирование работы с диском по алгоритму C-SCAN
Алгоритм N-шагового сканирования (N-Step SCAN) является модификацией алгоритма сканирования. Каретка с головками совершает движения туда и обратно, как и в случае SCAN, но на каждом проходе обслуживаются только те запросы, которые существовали в момент начала прохода. Запросы, поступающие во время хода в одном направлении, группируются и перестраиваются таким образом, чтобы их можно было наиболее эффективно обслуживать во время обратного хода. Значение N определяет длину групп запросов, на которые разбивается очередь запросов. При большом значении N данный алгоритм аналогичен алгоритму SCAN, при N = 1 - алгоритму FCFS. На рис.6.12 приведена последовательность обработки очереди запросов при N = 4.
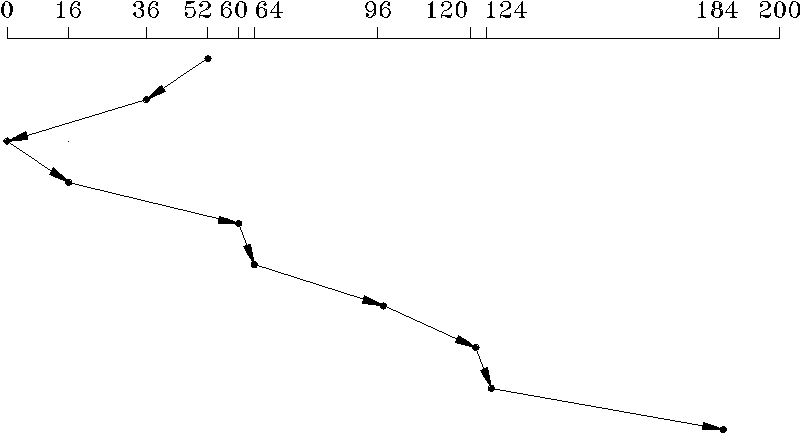
Рис. 6.12. Планирование работы с диском по алгоритму N-Step SCAN
При алгоритме планирования работы с диском по схеме Эшенбаха каретка с головками движется циклически, как в алгоритме С-SСАN. Однако при обслуживании каждого цилиндра осуществляется доступ точно к одной полной дорожке информации независимо от наличия еще запроса для этого цилиндра. Предусматривается переупорядочение запросов для обслуживания в рамках одного цилиндра с учетом углового положения записей, однако если два запроса относятся к перекрывающимся секторам одного цилиндра, то только один из них обслуживается при текущем ходе каретки. Схема Эшенбаха позволяет оптимизировать обработку запросов не только по времени поиска цилиндров, но и с учетом времени поиска записи на дорожке.