

2.3.5. Индексно-последовательное размещение
При индексно-последовательной организации файла (рис.2.7) поиск элементов файла проводится с помощью двух методов: в прямом порядке (с помощью ключей) и последовательном (определяемом порядком ключей). Каж-

Рис. 2.7.
дая логическая запись, входящая в файл с данной структурой, содержит ключ -некоторый индивидуальный отличительный признак. Все записи в файле упорядочиваются по значению ключей. В файл с такой с такой организацией можно выделить группы записей, ключи которых расположены подряд в файле. Эти группы хранятся в некоторой локальной области внешней памяти, например, в пределах одной дорожки на диске. Для более быстрого поиска таких групп строят специальную структуру - блок индексов. Каждый элемент индексного блока описывает отдельную группу записей. Чаще всего индекс содержит значение максимального (в текущий момент времени) ключа в группе и указатель на начальную запись в группе.
Для поиска записи с некоторым ключом необходимо сначала обратиться к индексу и определить группу записей, в диапазон значений ключей которой входит искомый ключ. По индексу находят начало первой записи требуемой группы, а затем, обращаясь к самой группе, последовательным анализом ключей в каждой записи находят требуемую запись. При такой организации файла время поиска записи будет меньше, чем в случае, если бы файл имел последовательную структуру.
Основная проблема, которая присуща работе с файлами с индексно-последовательной организацией, - проблема добавления новых записей во время работы с файлом. Это связано с тем, что взаимное расположение записей в файле требует их упорядоченности по ключам. Чтобы решить эту проблему, вводят области переполнения, куда будут заноситься записи, добавляемые в файл, и которые нельзя разместить в основной области из-за отсутствия в ней места. Из основной области устанавливаются ссылки (в соответствии с логическим порядком ключей) на требуемые элементы области переполнения.
Наиболее эффективная реализация индексно-последовательного размещения предложена в операционной системе UNIX. Каждый файл в системе имеет дескриптор (рис.2.8), называемый i - вершиной, в составе которого хранится список, содержащий адреса 13 блоков на диске. Список используется для адресации к тем блокам, которые входят в состав файла. Используется как прямая, так и косвенная адресация. Первые десять элементов списка непосредственно указывают на десять блоков, в которых могут размещаться данные файла. Поскольку размер блока здесь составляет 512 байтов, то напрямую можно адресовать файлы размером до 5120 байтов. Если размеры файла превышают 5120 байтов, используются последующие три элемента списка. Одиннадцатый элемент списка содержит адрес блока косвенной адресации первого уровня, хранящего адреса еще 128 блоков, которые могут принадлежать файлу. Если длина файла превышает 70656 (138 ´ 512) байтов, то двенадцатый адрес указывает на блок косвенной адресации второго уровня, который содержит список из 128 адресов блоков косвенной адресации первого уровня. Этим обеспечивается доступ еще к 16384 (128 ´ 128) блокам. Если длина файла превышает8459264 (16522 ´ 512) байтов, то с помощью тринадцатого элемента в списке дескриптора файла производится обращение к блоку косвенной адресации третьего уровня, содержащего адреса 128 блоков косвенной адресации второго уровня. Тем самым обеспечивается доступ к внешней памяти объемом свыше одного гигабайта.
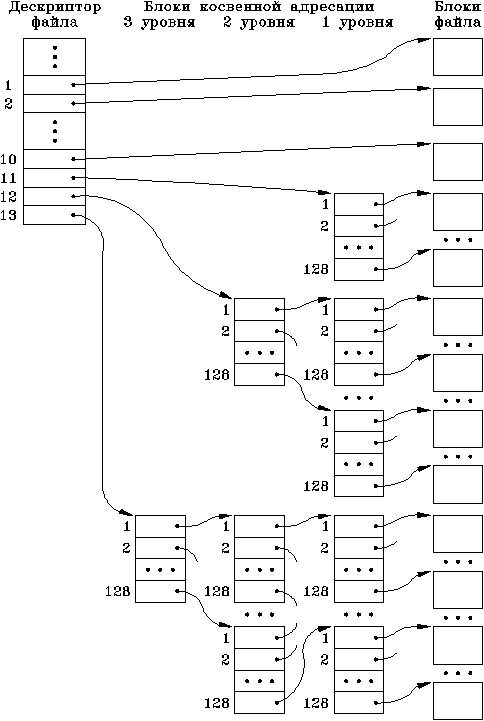
Рис. 2.8