

os2016-24-03-dist
.pdfКонвейер команд…
•Конвейерная обработка инструкций – это метод реализации CPU, при котором множество операции над несколькими инструкциями перекрываются.
•Конвейерная обработка инструкций использует программный параллелизм уровня инструкций (Instruction-Level Parallelism, ILP)
•Конвейеризация увеличивает пропускную способность CPU - среднее число инструкций, завершенных за такт.
•В идеальном случае происходит завершение одной инструкции за машинный такт
•Конвейеризация не сокращает время выполнения отдельной инструкции (также называемое временем задержки завершения инструкции).
•Минимальное время задержки завершения инструкции - n тактов, где n – число ступеней конвейера
•Конвейер, описанный здесь, называется упорядоченным (in-order) конвейером так как инструкции обрабатываются или исполняются в порядке, указанном в исходной программе
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
31 из 66 |
|
энергопотребление |
|
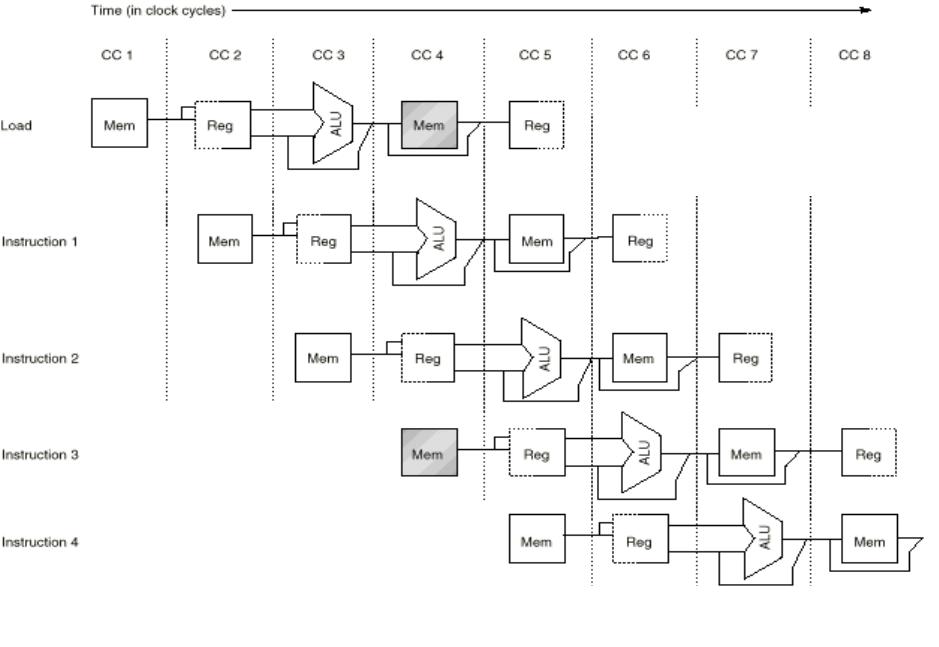
Однопортовый конвейер MIPS с упорядоченной обработкой целочисленных операций
Число тактов до заполнения = время разгона = число ступеней -1
Номер такта
Номер инструкции |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
9 Время в тактах |
||
Инструкция I |
IF |
ID |
EX |
MEM |
WB |
|
|
|
|
|
|
|
|
|
|
|
|
Первая инструкция, I |
|||||||
Инструкция I+1 |
|
IF |
ID |
EX |
MEM |
WB |
|
|
|
|
завершена |
|
Инструкция I+2 |
|
|
IF |
ID |
EX |
MEM WB |
|
|
|
|
||
|
|
|
|
|
|
|||||||
Инструкция I+3 |
|
|
|
IF |
ID |
EX |
MEM WB |
|
|
|||
Инструкция I +4 |
|
|
|
|
IF |
ID |
EX |
MEM |
WB |
|||
|
Время разгона = 4 такта |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
Последняя инструкция, |
||||
Ступени конвейера MIPS: |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
I+4 завершена |
||||
IF |
= Выборка инструкции (Instruction Fetch) |
|
|
|
|
|||||||
|
|
|
|
|||||||||
ID |
= Декодирование инструкции (Instruction Decode) |
|||||||||||
EX |
= Исполнение (Execution) |
|
|
|
|
|
|
|
||||
MEM |
= Обращение к памяти (Memory Access) |
|
|
|
|
|||||||
WB |
= Запись результата (Write Back) |
|
|
|
|
|
|
|||||
Архитектура Intel от i386 до Xeon Phi:
Нижний Новгород 2014 процессоры, производительность, 32 из 66 энергопотребление

Intel 80286
•Intel 80286 (1982)
•Тактовая частота – 6 (12,5) МГц
•Производительность – 0,9 (2,66) MIPS
•Количество транзисторов – 134 000
•Площадь кристалла – 49 кв.мм
•Техпроцесс – 1,5 мкм
•0.21 Instructions Per Clock
•Конвейер команд (длина - 4)
•Защищенный режим
•Linear Memory Management Unit (MMU)
•Intel 80287 (1983)
•Математический сопроцессор
•Производительность – ~65 000 FLOPS
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
33 из 66 |
|
энергопотребление |
|
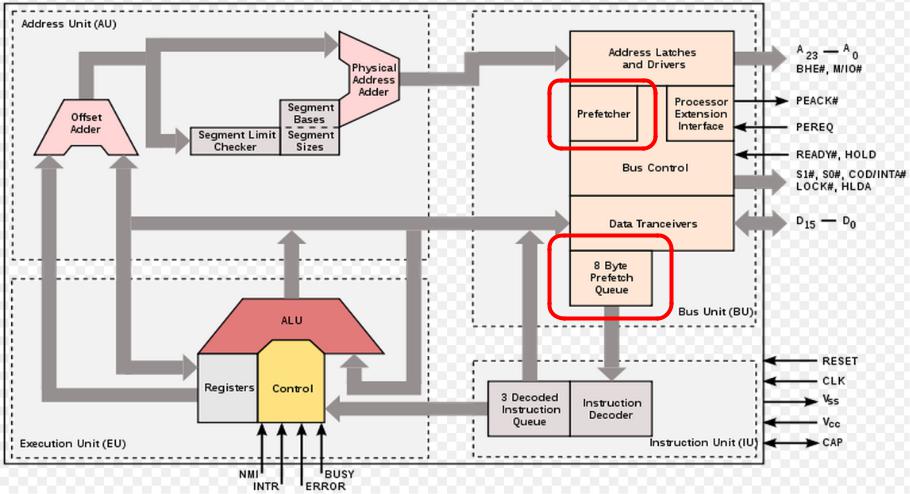
Intel 80286
http://en.wikipedia.org/wiki/File:Intel_i80286_arch.svg
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
34 из 66 |
|
энергопотребление |
|

Intel 80386
•Intel 80386DX (1985)
•Тактовая частота – 12 (33) МГц
•Производительность – 5 (11,4) MIPS
•Количество транзисторов – 275 000
•Площадь кристалла – 104 (39) кв.мм
•Техпроцесс – 1,5 (1) мкм
•Страничное преобразование
•Аппаратная отладка
•Встроенный математический сопроцессор 80387
•Производительность – ~300 000 FLOPS
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
35 из 66 |
|
энергопотребление |
|
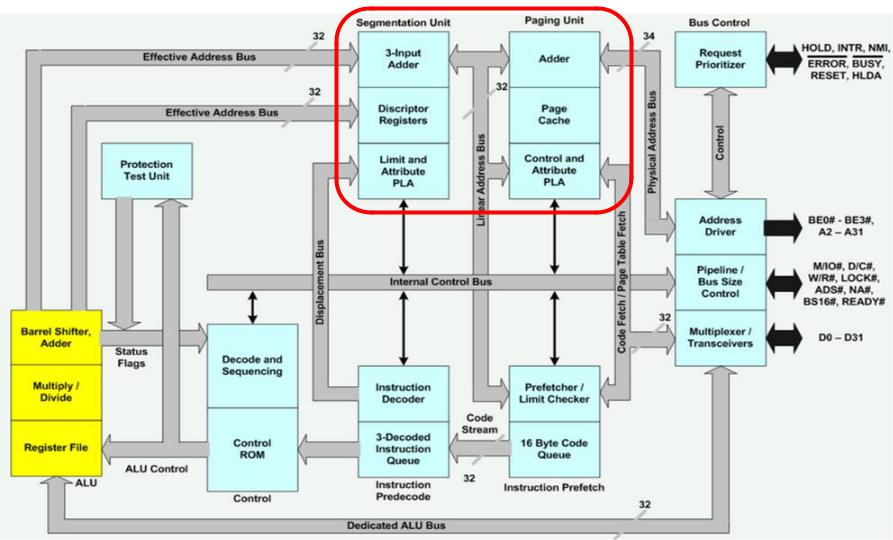
Intel 80386
http://en.wikipedia.org/wiki/File:80386DX_arch.png
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
36 из 66 |
|
энергопотребление |
|
Конвейер команд: конфликты
•Структурные конфликты
•Возникают из-за недостатков аппаратных ресурсов когда доступное аппаратное обеспечение не в состоянии поддерживать все возможные комбинации инструкций
•Конфликты данных
•Возникают когда инструкция зависит от результата выполнения предыдущей инструкции так, что это проявляется при перекрытии инструкций в конвейере
•Конфликты управления
•Возникают при конвейеризации условных переходов и других инструкций, которые изменяют PC
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
37 из 66 |
|
энергопотребление |
|
Единая разделяемая память для инструкций и данных
Процессор с блоком памяти,
вызывающим структурные
конфликты
В машине с единственным портом памяти будет возникать конфликт при любом обращении к памяти.
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
38 из 66 |
|
энергопотребление |
|
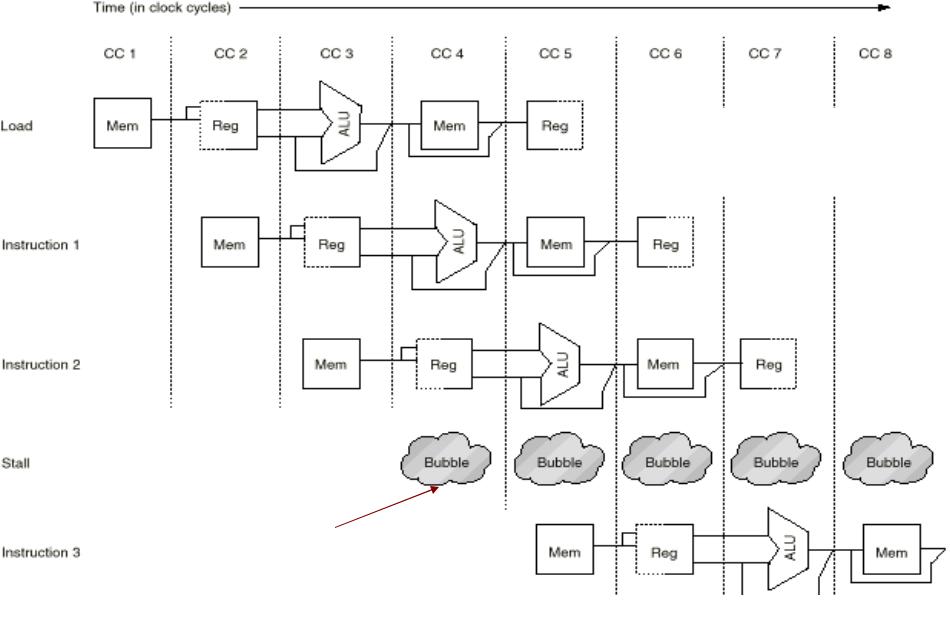
Единая разделяемая память для данных и инструкций
Разрешение
структурного конфликта при помощи тактов простоя
Структурный конфликт приводит к необходимости вставки «пузырей» в конвейер.
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
39 из 66 |
|
энергопотребление |
|
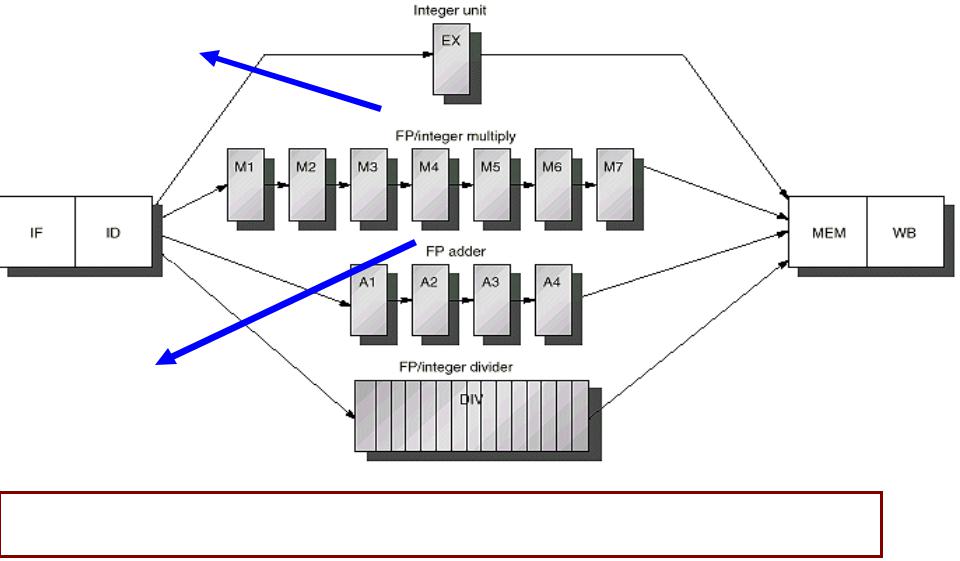
Многотактовый конвейер вещественных операций
Задержка = 6 |
|
Целочисленный блок (Задержка= 0 Период запуска = 1) |
|
Конфликты: |
||
Период запуска = 1 |
|
|
|
|
|
RAW, WAW |
|
|
|
|
|
||
Конвейеризуемое |
|
|
|
|
возможны |
|
|
|
|
|
|
|
WAR |
|
|
|
|
|
|
невозможен |
|
|
|
|
|
|
Структурные: |
|
|
|
Вещественное (FP)/целочисленное умножение |
|
|
|
|
|
|
|
|
возможны |
|
|
|
|
|
|
|
Управления: |
|
|
|
|
|
|
|
|
|
|
|
|
|
возможны |
|
|
|
|
|
|
|
|
|
|
|
|
|
EX |
|
|
|
|
IF |
|
ID |
|
|
|
|
MEM |
|
WB |
|
|
|
FP сумматор |
|
|||||||
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
Задержка = 3 |
целочисленное деление |
|
Период запуска = 1 |
|
Задержка = 24 |
|
||
Конвейеризуемое |
Период запуска = 25 |
|
|
Неконвейеризуемое |
|
Однопортовый конвейер MIPS с упорядоченной обработкой и поддержкой FP Супер-конвейерный CPU: Конвейерный CPU с конвейеризуемыми FP блоками
|
Архитектура Intel от i386 до Xeon Phi: |
|
Нижний Новгород 2014 |
процессоры, производительность, |
40 из 66 |
|
энергопотребление |
|