

Лабораторна робота_9
.pdfпорівнюваними елементами можуть змінюватися порізному. Обов'язковим є лише те, що останній крок повинен дорівнювати одиниці.
Наприклад, хороші результати дає послідовність кроків 9, 5, 3, 2, 1, яка використана в показаному вище прикладі. Слід уникати послідовностей ступеня двійки, які, як показують складні математичні викладки, знижують ефективність алгоритму сортування. (Однак, при використанні таких послідовностей кроків між порівнюваними елементами це сортування буде як і раніше працювати правильно).
Швидке сортування
Метод швидкого сортування був розроблений Ч.А.Р. Хоаром, який дав йому цю назву. В даний час цей метод сортування вважається найкращим. Швидке сортування засноване на тому факті, що для досягнення найбільшої ефективності бажано проводити обміни на великих відстанях.
Алгоритм швидкого сортування використовує обмінний метод сортування.
У його основі принцип розбиття. Вибирається деякий елемент (наприклад, середній) і всі елементи послідовності переставляються так, щоб вибраний елемент виявився на своєму остаточному місці, тобто щоб ліворуч від нього були тільки менші або рівні йому елементи, а праворуч - тільки великі або рівні. Потім цей же метод застосовується до лівої і правої частин послідовності, на які її розділив вибраний елемент. (Зауваження: якщо в частині виявилося два-три елементи, то впорядковувати її слід більш простим способом).
Необхідна перестановка елементів виконується так. Обраний елемент копіюється в деяку змінну q. Послідовність проглядається зліва направо, поки не зустрінеться елемент, більший або дорівнює q, а потім проглядається справа наліво до елемента, меншого або рівного q. Обидва ці елементи міняються місцями, після чого перегляди з обох кінців послідовності тривають зі наступних елементів, і т.д. У підсумку обраний елемент опиниться в тій позиції, де перегляди зійшлися, це і є його остаточне місце.
Рекурсія широко використовується в алгоритмах сортування. Швидке сортування можна реалізувати рекурсивно і нерекурсивно. У другому випадку межі однієї з двох частин (краще - довшої), на які вибраний елемент розділив послідовність, запам'ятовуються в стеку, а інша частина упорядковується описаним способом. Після її упорядкування з стека витягуються межі першої частини, і тепер вже вона упорядковується.
Кроки алгоритму:
1.Беремо будь-який елемент масиву х
2.Шукаємо в масиві зліва елемент аі>х
3.Шукаємо в масиві праворуч елемент аj<х
4.Міняємо місцями аі і аj.
5.Повторити з п. 1
Наприклад, для масиву (38, 56, 17, 36, 98, 21, 12, 74) при використанні як значення розбиття «36» будуть отримані наступні проходи при виконанні алгоритму швидкого сортування:
Початковий стан: (38, 56, 17, 36, 98, 21, 12, 74) перший прохід: (12, 21, 17, 36, 98, 56, 38, 74) другий прохід: (12, 17, 21, 36, 38, 56, 98, 74) третій прохід: (12, 17, 21, 36, 38, 56, 74, 98)
Після першого проходу цей процес триває для кожної частини (12, 21, 17, 36) і (98, 56, 38, 74). Найкраще швидке сортування реалізується за допомогою рекурсивного алгоритму.
Вибір значення розбивки можна зробити двома способами. Це значення можна вибирати випадковим чином або шляхом усереднення невеликого числа значень, вибраних з масиву. Для оптимального сортування потрібно вибрати значення, яке буде знаходитися в точності посередині всіх елементів. Однак, для більшості наборів даних це зробити нелегко. Однак, навіть у найгіршому випадку, швидке сортування працює досить добре.
Нижче як значення розбиття використовується середнє значення. Хоча такий підхід не завжди є найкращим, він досить простий, і сортування буде виконуватися правильно.
procedure QuickSort; procedure sort (l, r: index); var
i, j: index; x, y: integer; begin
i: = l; j: = r;
x: = a [(l + r) div 2]; repeat
while a [i] <x do i: = i + 1; while a [j]> x do j: = j-1; if i <= j then
begin
y: = a [i];
a [i]: = a [j]; a [j]: = y;
i: = i + 1; j: = j-1;
end;
until i> j;
if l <j then sort (l, j); if i <r then sort (i, r) end;
begin
sort (1, n); end;
У даному прикладі процедура швидкого сортування звертається до основної процедури сортування з ім'ям «sort». Це забезпечує доступ до даних «a» і «n» при всіх викликах «sort».
Сортування злиттям
Основна ідея такого сортування - розділити послідовність на вже впорядковані підпослідовності (назвемо їх «відрізками») і потім об'єднувати ці відрізки у все більш довгі впорядковані відрізки, поки не вийде єдина впорядкована послідовність. Відзначимо, що при цьому необхідна додаткова пам'ять (масив Y [1..n]).
Алгоритм будується за допомогою алгоритмічної стратегії «розділяй і володарюй». Суть цієї стратегії в тому, що рішення задачі складається з наступних трьох етапів.
1.Поділ. Завдання розбивається на дві або більше аналогічні підзадачі, що не перетинаються меншої розмірності. Підзадачі, що не перетинаються - це означає, що рішення кожної підзадачі ніяк не залежить від рішення інших підзадач.
2.Підкорення. Рекурсивно вирішуються підзадачі. Коли розмірність підзадачі досить мала, ця підзадача вирішується безпосередньо.
3.Комбінування рішення вихідної задачі з рішень підзадач.
Для визначеності будемо виконувати сортування за зростанням. Згадані вище етапи зводяться до наступного.
1.Поділяємо масив з n елементів на дві приблизно рівні частини: у першій [n/2] елементів, у другій - всі інші. (Дужки означають, що - округлюється в меншу сторону.)
2.Сортуємо методом злиття кожну частину окремо.
3.Відсортовані частини масиву зливаємо в один відсортований масив. Розбиття на підзадачі можна припиняти, коли у виділеній для
сортування частині масиву виявиться всього один елемент. Масив з одного елемента є впорядкованим. Це і є умова виходу з рекурсії.
Найскладнішою частиною задачі сортування злиттям є само злиття двох відсортованих частин масиву з утворенням упорядкованого масиву. Нехай процедура Merge (A, p, q, r) вирішує цю задачу: зливає відсортовані частині масиву A [p..q] (частина масиву A від A [p] до A [q] включно) і A [q + 1 .. r] у відсортовану послідовність A [p..r]. Тут p <q <r.
Тоді алгоритм сортування злиттям Merge Sort (A, p, r) можна представити таким чином (рис.).
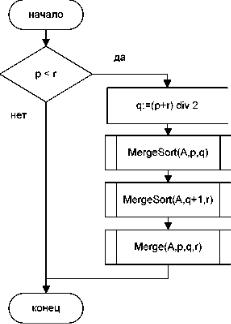
Рис. Сортування злиттям MergeSort (A, p, r)
Сенс параметрів процедури тут той же, що і для процедури Merge: A - ім'я масиву, p - ліва, а r - права межа (індекс) сортованої частини масиву.
Щоб відсортувати весь масив A [1..n], треба викликати описану процедуру наступним чином:
MergeSort (A, 1, n)
Тепер приступимо до розробки процедури злиття Merge.
Уявімо собі, що на столі лежать дві стопки карт, звернених лицьовою стороною вниз. Карти в кожній стопці відсортовані, причому нагорі знаходиться карта найменша. Ці дві стопки треба об'єднати в одну вихідну, в якій карти також будуть відсортовані. Для цього, поки в обох стопках є карти, будемо брати по одній верхній карті з обох стопок, вибирати з них меншу і поміщати її у вихідну стопку. У стопці,що зменшилася верхньою буде тепер інша карта. Після того, як одна з стопок закінчиться, карти з другої стопки треба буде по одній перекласти у вихідну стопку. На цьому сортування буде закінчено. Можна трохи вдосконалити алгоритм. Підкладемо під кожну стопку по одній сигнальної карті особливо великої. Настільки великої, щоб жодна з карт в обох стопках не мала більшої карти. Тоді можна бути впевненими, що ці сигнальні карти залишаться у своїх стопках, коли всі інші карти вже будуть перекладені у вихідну. Ці сигнальні карти позначимо символом ∞.
Через N1 позначена довжина масиву A [p..q], через N2 - довжина масиву A [q + 1, r]. Для роботи процедури MergeSort(A,p,q,r) створюються 2 допоміжних масиви L і R. У перший з них переписується підмасив A [p..q], ліва частина масиву A [p..r]. У масив R переписується підмасив A [q + 1..r].
Останніми елементами масивів L і R будуть сигнальні дуже великі значення. У циклі з параметром k наприкінці алгоритму в масив A [p..r] зливаються відсортовані масиви L і R.
Program Merge Sort;
Const MAXN = 10000000; // Максимальна кількість елементів масиву
BIG = MaxInt; // Сигнальний елемент
Type TElem = Integer;
massiv = array [1..MAXN] of TElem;
massiv2 = array [1 .. (MAXN + 1) div 2 +1] of TElem;
{Злиття відсортованих підмасивів A [p..q] і A [q + 1..r] у відсортований підмасив A [p..r]}
var Left, Right: massiv2; {Глобальні масиви} Procedure Merge (Var A: massiv; p, q, r: Integer);
var i, j, k, N1, N2: integer; begin
{Обчислюємо довжини подмассивов} N1: = q-p + 1;
N2: = r-q;
{Копіюємо елементи подмассивов у допоміжні масиви} for i: = 1 to N1 do
Left [i]: = A [p + i-1]; for j: = 1 to N2 do
Right [j]: = A [q + j]; {Встановлюємо сигнальні елементи}
Left [N1 + 1]: = BIG; Right [N2 + 1]: = BIG;
{Виконуємо злиття масивів Left і Right}
i:= 1;
j:= 1;
for k: = p to r do
If Left [i] <= Right [j] then begin
A [k]: = Left [i]; i: = i + 1
end else begin
A [k]: = Right [j]; j: = j + 1
End
End;
{Сортування злиттям, виконується для масиву A [p..r]} Procedure MergeSort (Var A: massiv; p, r: Integer);
Var q: Integer; Begin
If p <r Then Begin
q: = (p + r) div 2; MergeSort (A, p, q); MergeSort (A, q + 1, r); Merge (A, p, q, r)
End;
End;
{Основний алгоритм} Var a: massiv; f: Text; i, N: Integer;
Begin
Assign (f, 'merge.in'); Reset (f);
Read (f, N); {Кількість елементів масиву} for i: = 1 to N do Read (f, a [i]);
Close (f); MergeSort (a, 1, N);
Assign (f, 'merge.out'); Rewrite (f);
for i: = 1 to N do begin
Write (f, a [i]: 10, ''); If i mod 7 = 0 then
WriteLn (f) {Дані виводимо по 7 чисел в рядок}
end; Close (f)
End.
Допоміжні масиви L і R в програмі позначені як Left і Right. Так як в підпрограмі Merge вже є змінна r, а в мові Паскаль регістр символів у написанні ідентифікаторів не відрізняється, то позначати масив ідентифікатором R ми не мали права. Розмірність цих масивів обрана такою, щоб у них могла поміститися половина вихідного масиву плюс один елемент (сигнальний). При обчисленні половини розміру початкового масиву результат округляємо в більшу сторону: (MAXN + 1) div 2. Масиви Left і Right зроблені глобальними для того, щоб пам'ять під них виділялася лише 1 раз.
Час роботи сортування злиттям для масиву з n елементів пропорційний n•1оg(n), що значно краще прямих методів сортування (вставкою, прямим вибором і обміном). Однак у цього алгоритму є один суттєвий недолік. Для його роботи потрібні додаткові масиви, які в сумі займають такий же обсяг пам'яті, як і вихідний.
Алгоритм сортування злиттям є стійким. Це означає, що відносний порядок рівних елементів не змінюється.