

modeling_2008
.pdfмежду клиентом и сервером, облегчающая, например, распределенные вычисления. Так, расчетную часть программы можно разместить на высокопроизводительном вычислительном сервере (с. 194), доступ к которому возможен с маломощных клиентских настольных ПЭВМ.
Касаясь вопроса о высокопроизводительных вычислениях, сразу укажем, что вычислительный сервер мог бы представлять собой многопроцессорную ЭВМ (например, кластерной архитектуры), а солвер мог бы при этом поддерживать исполнение вычислительных моделей, требующих высоких затрат времени ЦПУ в параллельном режиме. Подробнее об этом — в разд. 6.4.
6.4. Высокопроизводительные вычисления
В этом разделе обсуждается организация высокопроизводительных вычислений (англ. High Performance Computing, HPC) для моделирования РП ТД и соображения относительно архитектуры ППП, поддерживающей параллельное исполнение расчетной программы (солвера).
При моделировании РП ТД в наиболее детальной постановке требования к вычислительным ресурсам (быстродействию и объему оперативной памяти ЭВМ) могут быть очень велики, например, в расчетах турбулентных течений c выделением нестационарной вихревой структуры (подходы LES и DNS). При проведении «ресурсоемких» расчетов целесообразно распределить вычислительную работу между процессорами многопроцессорной ЭВМ, чтобы значительно сократить продолжительность каждого конкретного расчета и (или) использовать суммарно значительный объем оперативной памяти. Для таких задач, которым присущ параллелизм вычислений, возможно создание «параллельных» версий алгоритмов и программ, позволяющих эффективно использовать ресурсы ЭВМ c большим количеством (в т. ч. многоядерных) процессоров.
К счастью, в задачах вычислительной газодинамики (особенно решаемых явными методами), подобное «распараллеливание» оказывается относительно простым и достаточно эффективным. Действительно, достаточно предусмотреть в алгоритме сегментацию расчетной области на подобласти, чтобы вычисления для каждой подобласти на расчетном шаге требовали минимальной информации о состоянии в смежных подобластях. Тогда каждое такое вычисление можно проводить на отдельном вычислительном узле (процессоре) многопроцессорной ЭВМ,
191
а для восполнения недостающей информации обращаться с запросом к соответствующим узлам (процессорам).
Идеальный конечный результат «распараллеливании» вычислений — ускорение расчета в N раз, где N — число идентичных процессоров (процессорных ядер). В действительности ускорение расчета всегда оказывается несколько меньше N из-за а ) накладных расходов, в т. ч. связанных с передачей данных между процессорами и б ) несбалансированности загрузки процессоров. В любом случае производительность параллельной системы лимитируется наиболее медленно выполняемой подзадачей; при неблагоприятных условиях «эффективность» «распараллеливания» может резко снижаться.
Рассмотрение всех возможных архитектур многопроцессорных ЭВМ и лежащих в их основе принципов организации параллельных вычислений выходит за рамки данной книги. За подробностями можно обратиться, в частности, к [7,18]. Ниже мы остановимся только на практическом применении так называемых кластеров рабочих станций (называемых еще по традиции Beowulf-кластерами, см. [18, 48]).
6.4.1. Аппаратное обеспечение: кластеры. Кластер рабочих станций (Beowulf-кластер) [7, 18, 47, 48] представляет собой набор высокопроизводительных одноили многопроцессорных ЭВМ (вычислительных узлов), соединенных высокопроизводительной сетью и специально предназначенных для исполнения на них вычислительных задач. Примечательная особенность их в том, что кластеры могут целиком комплектоваться стандартным (но производительным, на данный момент) аппаратным обеспечением и специфическим (но также стандартным, в т. ч. находящимся в свободном доступе) ПО. Вычислительные системы данного класса по производительности могут конкурировать со специализированными многопроцессорными ЭВМ, а по соотношению цена/производительность — даже опережать их.
На каждом узле кластера выполняется отдельная копия операционной системы (ОС), а под ее управлением — расчетные процессы (по одному на процессор или ядро процессора), располагающие свои данные в локальной памяти узла. Между собой расчетные процессы «общаются» по определенному протоколу, используя высокопроизводительную сеть, объединяющую узлы.
За прошедшие полтора десятилетия было создано множество подобных вычислительных систем. На момент выхода данного пособия типичный недорогой кластер представлял собой набор из примерно 8 . . . 24
192

одноили двухпроцессорных компьютеров на базе (двухили четырехъядерных) процессоров фирм Intel или AMD, работающих под управлением ОС Linux. Количество процессоров в кластерах, входящих в верхние строчки рейтинга суперкомпьютеров Top500 [49], достигает десятков тысяч.
Возможно создание кластеров, работающих под управлением ОС семейства Windows (NT/2000/XP/2003), но доминируют в этом секторе все же свободные версии Unix-подобных ОС, главным образом в силу традиции и удобства, а отчасти из стремления снизить полную стоимость вычислительной системы.
В УГАТУ в 2000-2006 гг. функционировали несколько кластеров, наиболее крупный — 64-процессорный кластер из 32 узлов с процессорами Pentium III на тактовой частоте 1,0 ГГц. На момент написания продолжал работать собранный в 1999 г. 13-процессорный кластер на процессорах DEÑ Alpha 21164 (тактовая частота 667 МГц).
На рис. 6.4 показан кластер, собранный в 2006 г. на кафедреSempronДВС3000+УГАТУ из 4 материнских плат с процессорами AMD (тактовая частота около 1,9 ГГц), работающий под
Linux.
Рис. 6.4. Четырехпроцессорный кластер, собранный на кафедре ДВС УГАТУ в 2006 г.
193

Показательно, что по производительности кластер на рис. 6.4) уступает в ≈ 1,5 раза настольному компьютеру с черырехъядерным
процессором Intel Core 2 Quad.
В декабре 2007 г. в УГАТУ вступил в эксплуатацию суперкомпьютер кластерной архитектуры, содержащий 266 двухпроцессорных узлов с черырехъядерными процессорами Intel Õåîn (2128 ядер, часто-
та 2,33 ГГц). Показав пиковую производительность |
19,86 Тфлопс1, |
он занял 169-е место в рейтинге Top500 [49] |
по состоянию |
на июнь 2008 г. |
|
6.4.2. Программное обеспечение: MPI и параллельный солвер. Для расчетов на многопроцессорных ЭВМ требуется переработка алгоритмов — их «распараллеливание», которое технически сводится к встраиванию в текст программы вызовов процедур передачи сообщений между расчетными процессами.
Наибольшее распространение получило использование вызовов процедур библиотек, реализующих спецификации интерфейса передачи сообщений (Message Passing Interface, MPI), стандартизованной в 1993 г., что позволяет создавать переносимые параллельные программы (в стандарте MPI), компилировать и исполнять
их на многопроцессорных системах различной архитектуры (т. е. не только на кластерах).
Свободно распространяемый пакет MPICH реализует спецификацию M (MPICH2 — спецификацию MPI второй версии), позволяет работать с программами, написанными на С, С++ и Fortran. Кроме собственно исходных текстов библиотеки, сценариев трансляции и запуска, пакет MPICH содержит исходные тексты утилит отладки, диагностирова-
ния и профилирования -программ и документацию на пакет.
Имеется версия MPICH для линейки ОС Windîws, установ-
ка и использование которой существенно отличаются от таковых для Unix-систем.
Спецификация MPI и некоторые ее реализации имеют статус промышленного стандарта де-факто, и, например, солверы коммерческих CFD-пакетов используют именно их при запуске в «параллельном» режиме.
Итак, для проведения «параллельных» расчетов (в стандарте MPI) в многопроцессорной вычислительной системе (для кластеров —
1Т. е. 19,86 × 1012 операций над вещественными числами в секунду.
194
на всех узлах) должен быть инсталлирован пакет поддержки компиляции и выполнения (например, MPICH). Тогда MPI-программа, включающая файл заголовков и содержащая вызовы процедур MPI, компилируется и компонуется с объектным кодом этих процедур в исполняемый файл, который запускается в вычислительной системе в нужном числе экземпляров.
С параллельным программированием (с использованием MPI и др. подходов) можно познакомиться по [7, 15, 18].
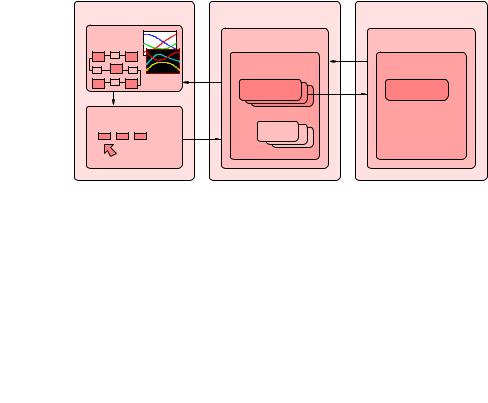
Солвер ППП также может быть написан c поддержкой режима параллельных вычислений (рис. 6.5). Это оправдано в основном при использовании «ресурсоемких» моделей. Тогда, при включении в расчетный проект («сборку») подобного элемента (элементов), расчет его следует проводить на многопроцессорной ЭВМ (например, на кластере). Может быть применено (усложненное по сравн. со схемой на рис. 6.3, но сохраняющее гибкость и эффективность) архитектурное решение для ППП, когда «ресурсоемкие» расчеты передаются на многопроцессорный вычислительный сервер (кластер), а «легковесные» модули рассчитываются, например, на клиентской машине.
ГИП |
Солвер |
Пар. солвер |
Вид |
Модель |
Модель |
|
||
|
Сборка |
Сборка |
|
МЭ |
МЭ |
Контроллер |
МС |
|
|
|
Рис. 6.5. Вариант архитектуры со специальным «параллельным» солвером
Другое решение — удаленный запуск единого для ППП солвера в «параллельном» режиме работы на кластере, с перенаправлением графического вывода на терминал, на котором запущена программа ГИП, выполняющая функции «тонкого клиента».
195
Вопросы для самоконтроля
1) Какие требования можно считать наиболее приоритетными при разработке ППП, предназначенных для широкого распространения? для «внутрфирменного» использования?
2)Укажите программные компоненты, необходимые для реализации функциональных возможностей развитого прикладного программного пакета.
3)Перечислите основные операции, выполняемые расчетной программой ППП (солвером) как при запуске, так и на шаге численного расчета.
4)Перечислите базовые классы объектов, которыми может быть представлена компонентная модель сложного моделируемого объекта (системы) — «сборка» в солвере.
5)Чем обусловлено применение многопроцессорных вычислительных систем для численного моделирования рабочих процессов тепловых двигателей?
6)К чему в идеале должно приводить «распараллеливание» вычислений на N идентичных процессоров (процессорных ядер)?
7)Что представляет собой высокопроизводительная ЭВМ кластерной архитектуры?
196
Глава 7
Примеры моделирования процессов
В данной главе приводятся результаты некоторых расчетных и расчетно-экспериментальных исследований, в которых численное моделирование выполнено с применением описанных в предыдущих главах моделей и подходов.
7.1. Решение тестовых задач методами типа Годунова
Прежде чем использовать тот или иной метод для расчета реальных течений в ГВТ, полезно убедиться в том, что он дает численные решения, сходящиеся к точным, и что численные решения не содержат нефизичных дефектов. Для этого вполне подходит решение идеализированных тестовых задач, точные решения которых известны. Это позволяет сравнивать решения, полученные разными методами, с ним как с эталонным,
ачисленные решения, полученные разными методами — между собой.
Сприменением трех консервативных методов для численного решения одномерных уравнений газовой динамики (раздел 5.5) решены две тестовые задачи о распаде разрыва. Выбор тестовых задач обусловлен необходимостью проверки работоспособности данных монотонных методов сквозного счета на задачах, содержащих как сильные разрывы искомых функций (КП и скачок уплотнения), так и изоэнтропных волн. В условиях обеих задач задавалась нулевая начальная скорость одно-
родного газа c cp/cv = 1,40 = const. Отношения плотностей и давлений по обе стороны от начального разрыва составляли 2 и 20 для первой и второй задач соотвественно. В решении первой задачи весь газ в зоне, возмущенной при распаде начального разрыва, движется с дозвуковой скоростью, в условиях второй задачи за хвостом волны разрежения поток движется быстрее скорости звука в этой зоне (M ≈ 1,36).
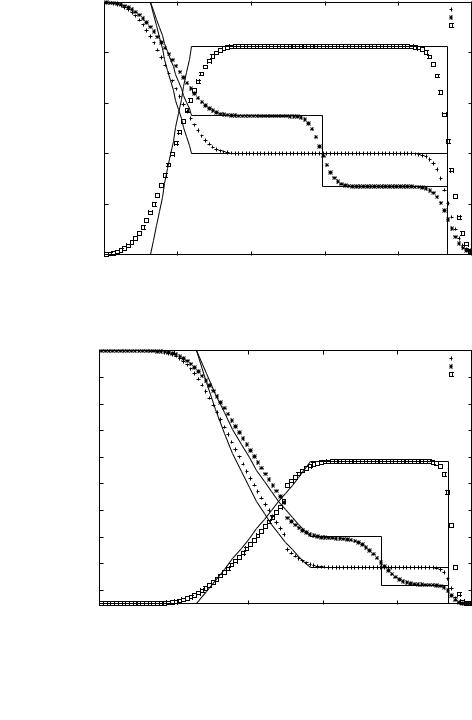
На рис. 7.1 показано решение первой тестовой задачи классическим методом «распада разрыва» С. К. Годунова, а на рис. 7.2 — решение второй задачи этим же методом. Расчетная сетка содержит 100 ячеек, сделано 100 шагов по времени с числом Куранта, равным 0,5. Числен-
197
ные решения на рисунках наложены на точные решения тестовых задач. В методе Годунова, реализованном в специальной программе для ЭВМ на языке C, применена процедура решения задачи о РПР на границах ячеек итерационным методом Ньютона из [40].
В решениях (рис. 7.1 и 7.2) этим методом заметно сильное «размазывание» решения, хотя положение разрывов воспроизводится правильно. В решении второй, «сверхзвуковой» задачи, виден дефект, присущий всем методам типа Годунова первого порядка — нефизичный скачок параметров на звуковой линии (|u| = c).
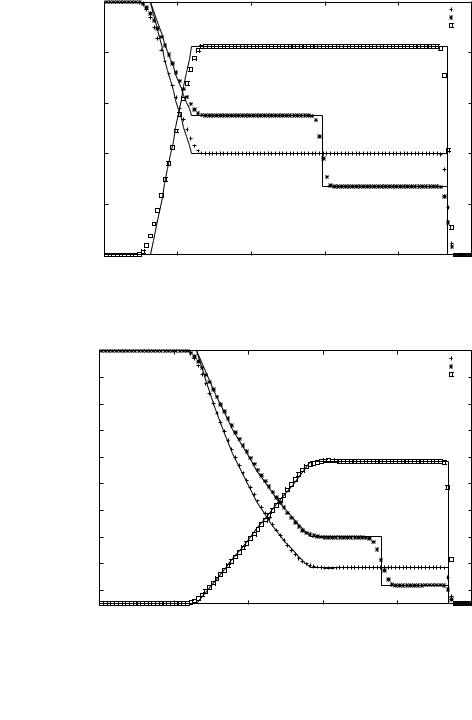
Метод повышенной точности (с. 169) применен в трехшаговом варианте, с линеаризованной процедурой решения задач о РПР на границах ячеек. Решения тестовых задач этим методом на той же сетке показаны на рис. 7.3 и рис. 7.4. Видно, что нефизичные осцилляции практически отсутствуют, значения параметров в зонах постоянных параметров и положение разрывов воспроизводится правильно, как и в решениях по методу Годунова, а численное «размазывание» разрывов значительно меньше.
Решения тех же тестовых задач экономичным одноэтапным методом (с. 174) показаны на рис. 7.5 и рис. 7.6. Эта схема показывает наибольшую «разрешающую способность», однако в решениях заметна некоторая «шероховатость», которая, очевидно, является следствием примененных линеаризаций; впрочем, этот дефект существенно проявляется лишь для «сверхзвуковой» задачи (рис. 7.6).
Затраты времени процессора: для метода Годунова — 3,58 с, метода повышенной точности — 8,33 с, экономичного метода — 2,23 с (задачаPentiumоIII«дозвуковом» РПР, сетка из 1000 узлов по x и по t, Intel
на частое 700 МГц).
По результатам этого (и других) тестов метод повышенной точности (в двухэтапном варианте) и экономичный одноэтапный метод были приняты в качестве методов численного интегрирования уравнений модели нестационарного течения в МЭ ТРУБКА в СИМ «Альбея» [32].
7.2. Моделирование движения ВКА в трубопроводе
Следующей задачей тестирования моделей, используемых для численного расчета нестационарных течений по трубопроводам, становится проверка всей расчетной методики на задачах, содержащих движение длинных ВКА по трубопроводам, включающим местные сопротивления.
198
2 |
|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
|
ρ |
|
|
|
|
|
u |
1.8 |
|
|
|
|
|
1.6 |
|
|
|
|
|
1.4 |
|
|
|
|
|
1.2 |
|
|
|
|
|
1 |
|
|
|
|
|
0 |
20 |
40 |
60 |
80 |
100 |
|
|
|
Ячейки |
|
|
Рис. 7.1. Решение «дозвуковой» задачи о РПР методом Годунова |
|||||
20 |
|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
|
ρ |
18 |
|
|
|
|
u |
|
|
|
|
|
|
16 |
|
|
|
|
|
14 |
|
|
|
|
|
12 |
|
|
|
|
|
10 |
|
|
|
|
|
8 |
|
|
|
|
|
6 |
|
|
|
|
|
4 |
|
|
|
|
|
2 |
|
|
|
|
|
0 |
20 |
40 |
60 |
80 |
100 |
|
|
|
Ячейки |
|
|
Рис. 7.2. Решение «сверхзвуковой» задачи о РПР методом Годунова |
|||||
199
2 |
|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
|
ρ |
|
|
|
|
|
u |
1.8 |
|
|
|
|
|
1.6 |
|
|
|
|
|
1.4 |
|
|
|
|
|
1.2 |
|
|
|
|
|
1 |
|
|
|
|
|
0 |
20 |
40 |
60 |
80 |
100 |
|
|
|
Ячейки |
|
|
Рис. 7.3. «Дозвуковой» распад разрыва; метод повышенной точности |
|||||
20 |
|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
|
ρ |
18 |
|
|
|
|
u |
|
|
|
|
|
|
16 |
|
|
|
|
|
14 |
|
|
|
|
|
12 |
|
|
|
|
|
10 |
|
|
|
|
|
8 |
|
|
|
|
|
6 |
|
|
|
|
|
4 |
|
|
|
|
|
2 |
|
|
|
|
|
0 |
20 |
40 |
60 |
80 |
100 |
|
|
|
Ячейки |
|
|
Рис. 7.4. «Сверхзвуковой» распад разрыва; метод повышенной точности |
|||||
200