

все
.doc
![]()
![]() Так
Так
Запитання 145: Множинна відповідь
Існують такі типи паралелізму:
![]()
![]() за
даними
за
даними
![]()
![]() за
завданнями
за
завданнями
![]()
![]() потоковий
потоковий
![]()
![]() канальний
канальний
Запитання 146: Множинна відповідь
Паралельні обчислювальні системи за використовуваною пам’яттю поділяються на
![]()
![]() Системи
із спільною пам’яттю
Системи
із спільною пам’яттю
![]()
![]() Системи
з розподіленою пам’яттю
Системи
з розподіленою пам’яттю
![]()
![]() Системи
із пам’яттю швидкого доступу
Системи
із пам’яттю швидкого доступу
![]()
![]() Системи
без пам’яті швидкого доступу
Системи
без пам’яті швидкого доступу
![]()
![]() Системи
із багаторівневою пам’яттю
Системи
із багаторівневою пам’яттю
![]()
![]() Системи
із однорівневою пам’яттю
Системи
із однорівневою пам’яттю
Запитання 147: Множина варіантів
Система SMP відноситься до:
![]()
![]() Систем
із спільною пам’яттю
Систем
із спільною пам’яттю
![]()
![]() Систем
з розподіленою пам’яттю
Систем
з розподіленою пам’яттю
![]()
![]() Систем
із пам’яттю швидкого доступу
Систем
із пам’яттю швидкого доступу
![]()
![]() Систем
без пам’яті швидкого доступу
Систем
без пам’яті швидкого доступу
![]()
![]() Систем
із багаторівневою пам’яттю
Систем
із багаторівневою пам’яттю
![]()
![]() Систем
із однорівневою пам’яттю
Систем
із однорівневою пам’яттю
Запитання 148: Множина варіантів
Система NUMA відноситься до:
![]()
![]() Систем
із спільною пам’яттю
Систем
із спільною пам’яттю
![]()
![]() Систем
з розподіленою пам’яттю
Систем
з розподіленою пам’яттю
![]()
![]() Систем
із пам’яттю швидкого доступу
Систем
із пам’яттю швидкого доступу
![]()
![]() Систем
без пам’яті швидкого доступу
Систем
без пам’яті швидкого доступу
![]()
![]() Систем
із багаторівневою пам’яттю
Систем
із багаторівневою пам’яттю
![]()
![]() Систем
із однорівневою пам’яттю
Систем
із однорівневою пам’яттю
Запитання 149: Множинна відповідь
Продуктивність обчислювальних систем вимірюється в
![]()
![]() FLOPS
FLOPS
![]()
![]() Hz
Hz
![]()
![]() Кількості
операцій з плаваючою комою за секунду
Кількості
операцій з плаваючою комою за секунду
![]()
![]() FPS
FPS
Запитання 150: Множина варіантів
Tехнологія MPI використовується для:
![]()
![]() Систем
із спільною пам’яттю
Систем
із спільною пам’яттю
![]()
![]() Систем
з розподіленою пам’яттю
Систем
з розподіленою пам’яттю
![]()
![]() Систем
із пам’яттю швидкого доступу
Систем
із пам’яттю швидкого доступу
![]()
![]() Систем
без пам’яті швидкого доступу
Систем
без пам’яті швидкого доступу
![]()
![]() Систем
із багаторівневою пам’яттю
Систем
із багаторівневою пам’яттю
![]()
![]() Систем
із однорівневою пам’яттю
Систем
із однорівневою пам’яттю
Запитання 151: Множина варіантів
Технологія OpenMP використовується для:
![]()
![]() Систем
із спільною пам’яттю
Систем
із спільною пам’яттю
![]()
![]() Систем
з розподіленою пам’яттю
Систем
з розподіленою пам’яттю
![]()
![]() Систем
із пам’яттю швидкого доступу
Систем
із пам’яттю швидкого доступу
![]()
![]() Систем
без пам’яті швидкого доступу
Систем
без пам’яті швидкого доступу
![]()
![]() Систем
із багаторівневою пам’яттю
Систем
із багаторівневою пам’яттю
![]()
![]() Систем
із однорівневою пам’яттю
Систем
із однорівневою пам’яттю
Запитання 152: Множина варіантів
В технології CUDA частина програми, яка буде виконуватися на GPU, називається:
![]()
![]() kernel
kernel
![]()
![]() host
host
![]()
![]() device
device
![]()
![]() GPUp
GPUp
![]()
![]() CPUp
CPUp
Запитання 153: Множина варіантів
В технології CUDA частина програми, яка буде виконуватися на CPU, називається:
![]()
![]() kernel
kernel
![]()
![]() host
host
![]()
![]() device
device
![]()
![]() GPUp
GPUp
![]()
![]() CPUp
CPUp
Запитання 154: Множина варіантів
Чи вірне твердження, що в технології CUDA частина програми, яка буде виконуватися на CPU, має бути написана на мові CUDA?
![]()
![]() Ні
Ні
![]()
![]() Так
Так
Запитання 155: Множина варіантів
Чи вірне твердження, що в технології CUDA частина програми, яка буде виконуватися на GPU, має бути написана на мові CUDA?
![]()
![]() Так
Так
![]()
![]() Ні
Ні
Запитання 156: Множинна відповідь
При використанні OpenCL необхідними є наступні інструменти:
![]()
![]() OpenCL
Compiler
OpenCL
Compiler
![]()
![]() OpenCL
Runtime Library
OpenCL
Runtime Library
![]()
![]() OpenCL
Compouser
OpenCL
Compouser
![]()
![]() OpenCL
Debuger
OpenCL
Debuger
Запитання 157: Множинна відповідь
OpenCL надає доступ ядру до таких типів памяті:
![]()
![]() Global
Memory
Global
Memory
![]()
![]() Constant
Memory
Constant
Memory
![]()
![]() Local
Memory
Local
Memory
![]()
![]() Private
Memory
Private
Memory
![]()
![]() Public
Memory
Public
Memory
![]()
![]() Protected
Memory
Protected
Memory
Запитання 158: Множинна відповідь
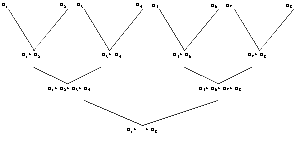
![]()
![]() на
рисунку зображений граф подвоювання
на
рисунку зображений граф подвоювання
![]()
![]() на
рисунку показано, як можна здійснити
підсумовування восьми чисел у три етапи
на
рисунку показано, як можна здійснити
підсумовування восьми чисел у три етапи
![]()
![]() на
рисунку показано, як можна здійснити
підсумування восьми чисел у сім етапів
на
рисунку показано, як можна здійснити
підсумування восьми чисел у сім етапів
![]()
![]() на
рисунку показано, як можна здійснити
підсумування восьми чисел у чотири
етапи
на
рисунку показано, як можна здійснити
підсумування восьми чисел у чотири
етапи
Запитання 159: Множина варіантів
Global Memory в OpenCL – це:
![]()
![]() пам'ять,
яка доступна зі всіх робочих елементів
(work item)
пам'ять,
яка доступна зі всіх робочих елементів
(work item)
![]()
![]() пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
![]()
![]() пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
![]()
![]() пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
Запитання 160: Множина варіантів
Constant Memory в OpenCL – це:
![]()
![]() пам'ять,
яка доступна зі всіх робочих елементів
(work item)
пам'ять,
яка доступна зі всіх робочих елементів
(work item)
![]()
![]() пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
![]()
![]() пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
![]()
![]() пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
Запитання 161: Множинна відповідь

![]()
![]() на
рисунку проілюстрований загальний
принцип розділяй і володарюй
на
рисунку проілюстрований загальний
принцип розділяй і володарюй
![]()
![]()
дана їдея подвоювання може бути
застосована для обчислення добутку n
чисел
![]()
![]()
![]()
дана їдея подвоювання не може бути
застосована для того щоб знайти
максимальне n з чисел
![]()
![]()
![]() граф
на рисунку є двійковим деревом, тому
операцію, що виконується за допомогою
графа здвоювання, інколи називають
операцією на дереві
граф
на рисунку є двійковим деревом, тому
операцію, що виконується за допомогою
графа здвоювання, інколи називають
операцією на дереві
Запитання 162: Множина варіантів
Local Memory в OpenCL – це:
![]()
![]() пам'ять,
яка доступна зі всіх робочих елементів
(work item)
пам'ять,
яка доступна зі всіх робочих елементів
(work item)
![]()
![]() пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
![]()
![]() пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
![]()
![]() пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
Запитання 163: Множина варіантів
Private Memory в OpenCL – це:
![]()
![]() пам'ять,
яка доступна зі всіх робочих елементів
(work item)
пам'ять,
яка доступна зі всіх робочих елементів
(work item)
![]()
![]() пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
пам'ять,
яка доступна для робочих елементів
(work item) в середині окремої робочої групи
(work group)
![]()
![]() пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
пам'ять,
яка доступна тільки в середині окремого
робочого елемента (work item)
![]()
![]() пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
пам'ять,
яка доступна тільки для читання
(read-only) зі всіх робочих елементів (work
item)
Запитання 164: Відповідність (просте)
Встановіть відповідність між середовищем розробки OpenCL програм та виробником:
|
|
A. Nvidia B. AMD C. Apple D. Intel |
Запитання 165: Множина варіантів
Для
![]() чисел,
алгоритм подвоювання:
чисел,
алгоритм подвоювання:
![]()
![]() складається
з q=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
складається
з q=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
![]()
![]() складається
з q=log n етапів. На першому етапі виконується
n додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
складається
з q=log n етапів. На першому етапі виконується
n додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
![]()
![]() складається
з p=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
складається
з p=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на останньому етапі не буде виконано
єдине додавання
![]()
![]() складається
з q=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на (n-1) етапі не буде виконано єдине
додавання
складається
з q=log n етапів. На першому етапі виконується
n/2 додавань, на другому – n/4 і т. д., поки
на (n-1) етапі не буде виконано єдине
додавання
Запитання 166: Множина варіантів
Щоб отримати список платформ, які підтримують OpenCL, необхідно виконати команду:
![]()
![]() clGetPlatformIDs()
clGetPlatformIDs()
![]()
![]() clReceivePlatformList()
clReceivePlatformList()
![]()
![]() clGetPlatformList()
clGetPlatformList()
![]()
![]() clReceivePlatformIDs()
clReceivePlatformIDs()
Запитання 167: Множина варіантів
Для алгоритму здвоювання середній степінь паралелізму дорівнює:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Запитання 168: Множина варіантів
Щоб отримати список пристроїв, які підтримують OpenCL, необхідно виконати команду:
![]()
![]() clGetDeviceIDs()
clGetDeviceIDs()
![]()
![]() clReceiveDevicesList()
clReceiveDevicesList()
![]()
![]() clGetDevicesList()
clGetDevicesList()
![]()
![]() clReceiveDeviceIDs()
clReceiveDeviceIDs()
Запитання 169: Множинна відповідь
За допомогою яких OpenCL runtime API команд запускається виконання ядра (kernel) на обчислювальному пристрої?
![]()
![]() clEnqueueTask()
clEnqueueTask()
![]()
![]() clEnqueueNDRangeKernel()
clEnqueueNDRangeKernel()
![]()
![]() clSetKernelArg()
clSetKernelArg()
![]()
![]() clRunKernel()
clRunKernel()
Запитання 170: Множина варіантів
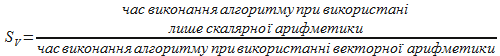
![]()
![]() прискорення,
яке отримується при використанні
векторних операцій
прискорення,
яке отримується при використанні
векторних операцій
![]()
![]() час
підготовки даних у векторному комп'ютері
час
підготовки даних у векторному комп'ютері
![]()
![]() степінь
векторизації обчислень в векторному
комп'ютері
степінь
векторизації обчислень в векторному
комп'ютері
![]()
![]() величина,
що характеризує векторні комп'ютери
величина,
що характеризує векторні комп'ютери
Запитання 171: Множина варіантів
Щоб створити OpenCL контекст, необхідно виконати команду:
![]()
![]() clCreateContext()
clCreateContext()
![]()
![]() clBuildContext()
clBuildContext()
![]()
![]() clProduceContext()
clProduceContext()
![]()
![]() clBuildContekst()
clBuildContekst()
Запитання 172: Множина варіантів
Що в OpenCL означає специфікатор «__kernel» ?
![]()
![]() зазначає,
що функція буде виконана на обчислювальному
пристрої (device)
зазначає,
що функція буде виконана на обчислювальному
пристрої (device)
![]()
![]() зазначає,
що функція буде виконана на хості (host)
зазначає,
що функція буде виконана на хості (host)
![]()
![]() запускає
виконання ядра на обчислювальному
пристрої (device)
запускає
виконання ядра на обчислювальному
пристрої (device)
![]()
![]() виділяє
основну частину програми
виділяє
основну частину програми
Запитання 173: Множина варіантів
Яке розширення, програми написаної на OpenCL, повинно мати ядро (kernel)?
![]()
![]() cl
cl
![]()
![]() ocl
ocl
![]()
![]() c
c