

Розділ 3 Проектування гібридної інтелектуальної інформаційної системи для вирішення задач кластеризації та регресії
3.1. Узагальнена структура гібридної інформаційної системи та алгоритм її роботи
Одним з найважливіших етапів при побудові ГІС є побудова достовірної моделі, яку можливо представити у вигляді багаторівневої ієрархічно впорядкованої структури. Ієрархія, як певний тип системи, заснований на припущенні, що елементи системи можуть групуватися в незв’язні множини. Елементи кожної групи чинять вплив на елементи іншої групи. Представлення у вигляді ієрархічної структури різних методів певного класу задач є найбільш зручним способом для реалізації гібридної інтелектуальної системи.
Ієрархія будується методом структурної декомпозиції (формування структур «зверху»).
Одним з варіантів побудови ієрархії пропонується знайти незалежні групи (кластера) та їх характеристики у всій множині аналізованих даних, далі для кожного кластера вирішити задачу регресії – визначити за відомими характеристиками об’єкта значення деякого його параметра.
Загальний вигляд алгоритму побудови ГІС поданий нами на рис. 3.1.
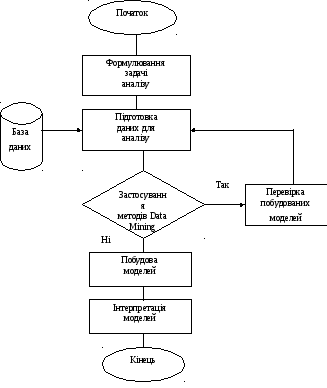
Рис. 3.1. Алгоритм побудови ГІС
На першому етапі виконується формування поставленого завдання і уточнення цілей, які повинні бути досягнуті методами Data Mining.
Другий етап полягає у підготовці даних для аналізу, необхідної для застосування конкретних методів Data Mining.
Третій і четвертий етапи – застосування методів Data Mining, а також побудова моделей. Сценарії цього застосування можуть бути самими різними і можуть включати складну комбінацію різних методів, особливо якщо використовувані методи дозволяють проаналізувати дані з різних точок зору.
П’ятий етап – перевірка побудованих моделей. На останньому етапі відбувається інтерпретація отриманих моделей людиною з метою їх використання для прийняття рішень, додавання одержані правил і залежностей в базі знань
Можна зробити висновок, що не існує єдиного універсального алгоритму кластеризації. При використанні будь-якого алгоритму важливо розуміти його переваги і недоліки, враховувати природу даних, з якими він краще працює і здатність до масштабованості.
Розроблена методика побудови гібридної інтелектуальної системи для рішення основних задач Data Mining, а саме кластеризації та регресії веде до підвищення ефективності аналізу статистичної інформації. Тому запропонована методика може знайти застосування у багатьох галузях.
3.2. Програмна реалізація гібридної інтелектуальної системи для рішення задач кластеризації та регресії
Для проектування гібридної інтелектуальної системи було обрано використовувати бібліотеку Extreme Optimization Numerical Libraries for. NET.
Бібліотека Extreme Optimization Numerical Libraries for. NET є набором засобів загального призначення, яка має математичні і статистичні класи та побудована для платформи Microsoft.NET. Дана бібліотека забезпечує першу повну платформу для технічних і статистичних розрахунків побудована для Microsoft .NET платформи версії 2.0 та вище. Вона поєднує в собі математичну, векторну та матричну бібліотеки, а також бібліотеку статистики. Підтримує розробку додатків на мовах програмування C ++, Visual Basic C + + / CLI, IronPython або будь-яку іншу. NET Framework мову.
Для розробки програмної реалізації було обрано мову програмування C++, що заснована на строгій компонентної архітектури і реалізує передові механізми забезпечення безпеки коду. У свою чергу, мова програмування C ++ реалізовує компонентно-орієнтований підхід до програмування, який спричиняє меншу машинно-архітектурну залежність результуючого програмного коду, більшій гнучкості, переносимості та легкості повторного використання (фрагментів) програм.
В якості методів кластерного аналізу при розробці програмного продукту було обрано два типи методів: ієрархічні та неієрархічні (агломеративні методи включені до складу ієрархічних, ітеративні включені до складу неієрархічних методів). Правила об’єднання кластерів в ієрархічних агломеративних методах були обрані наступні: Average (середнього); Centroid (центроїдного); Complete (повних зв’язків); Median (медіанного); Single (одиночного зв’язку); Ward (метод Уорда).
В якості міри подібності були обрані наступні метрики: CanberraDistance (відстань Канберра); CorrelationDistance (кореляційна відстань); EuclidianDistance (Евклідова метрика); ManhattanDistance (Манхеттенська відстань); MaximumDistance (максимальна відстань); SquaredEuclidianDistance (квадрат Евклідової метрики).
Для регресійного аналізу при розробці програмного продукту було обрано: лінійна модель, логістична модель, поліноміальна модель, а також реалізовано наступну послідовність функціонально пов’язаних дій: завантажувати вхідні дані для аналізу з файлу; зберігати змінені вхідні дані у файл; будувати графік вхідних даних; проводити налаштування параметрів для кластерного аналізу; проводити кластерний аналіз наведеними вище методами; проводити налаштування параметрів для регресійного аналізу (в тому числі обирати номер кластеру та вид моделі); проводити регресійний аналіз наведеними вище методами.
Для цього прописано лістинг програми запропонованого програмного рішення (додаток Б) та зопропоновано діаграми бізнес-варіантів використання та варіантів використання, що наведено у додатку В.
Головне вікно програми (рис. 3.2) складається з трьох панелей: 1) робота з вхідними даними; 2) головна функціональність; 3) налаштування параметрів для аналізу.
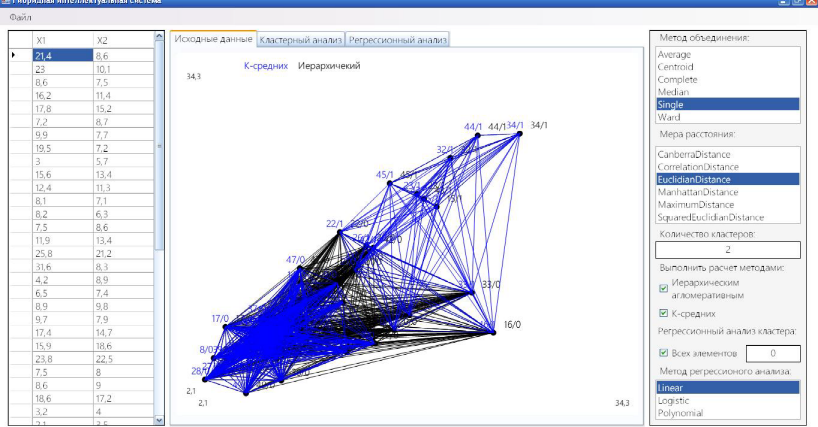
Рис. 3.2. Головне вікно програми
На вкладці «Исходные данные» будується графік вихідних даних з об’єднанням у кластери за двома методам (рис. 3.3).

Рис. 3.3. Побудова графіку вхідних даних з об’єднанням у кластери
Вхідні дані можна вводити як вручну, так і завантажувати з файлу. Для того щоб завантажити дані необхідно натиснути на пункт меню «Файл» та обрати підпункт «Загрузить» (рис. 3.4). В діалоговому вікні що відкриється необхідно обрати потрібний файл. Дане діалогове вікно має стандартний windows інтерфейс, тому ніяких проблем при роботі з ним не повинно виникати.
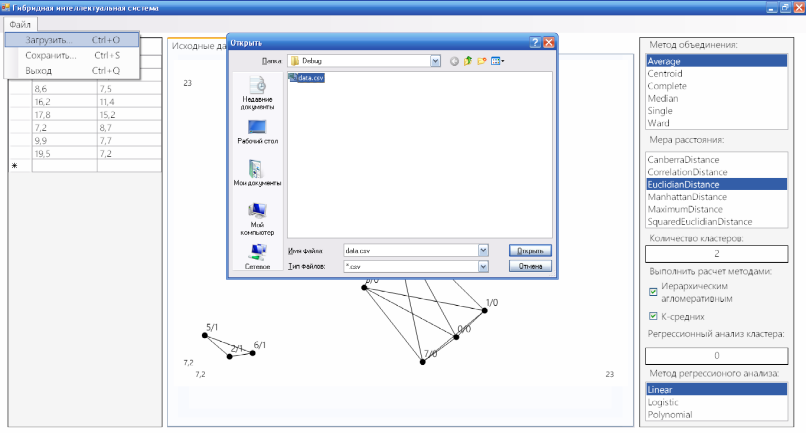
Рис. 3.4. Завантаження файлу з вхідними даними
Після завантаження даних з файлу графік вихідних даних будується автоматично.
Якщо необхідно змінити вхідні дані необхідно в панель для роботи з даними ввести необхідні значення та натиснути на пункт меню «Файл» та обрати підпункт «Сохранить». В діалоговому вікні що відкриється необхідно ввести ім’я файлу та натиснути на кнопку «Сохранить».
На вкладці «Кластерный анализ» відображається результат кластерного аналізу зі встановленими параметрами для аналізу в правій області вікна. Можливо обрати метод об’єднання, відстань, кількість кластерів для розрахунку за методом K-середніх, а також обрати який з методів відображати в області з результатами кластерного аналізу (рис. 3.5).

Рис. 3.5. Результат кластерного аналізу
На вкладці «Регрессионный анализ» відображається результат регресійного аналізу зі встановленими параметрами для аналізу в правій області вікна. Можливо обрати номер кластеру для якого необхідно проводити регресійний аналіз та метод регресійного аналізу. Кількість кластерів в які групуються вхідні дані залежить від даних, які розраховані на вкладці «Кластерный анализ». Результати розрахунку регресійного аналізу, в тому числі з розрахованими показниками регресії відображаються в центральній області вікна у вигляді таблиць (рис. 3.6).
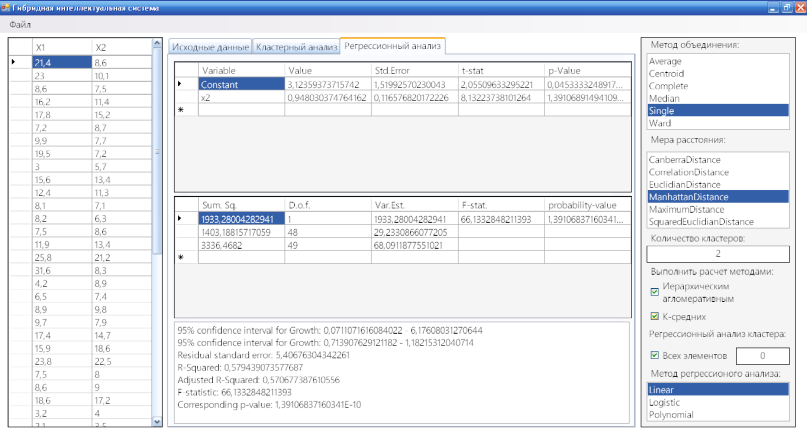
Рис. 3.6. Результат регресійного аналізу
За допомогою запропонованого програмного продукту у подальшому будуть проведені статистичні дослідження гібридної інтелектуальної системи.