

Зміст
Зміст 1
Оптимальне кодування 3
Основні властивості оптимальних кодів 3
Методика Шенона і Фано 3
Методика Хаффмана 3
Оптимальні нерівномірні коди (ОНК) 4
Завадостійке кодування 4
Роздільні і не роздільні коди 4
Лінійні групові коди 5
Спосіб формування кодів. 6
Лінійні блокові коди 7
Загальні особливості стиснення інформації. 7
Розглянемо деякі способи стиснення 8
Стиск інформації 8
Метод стиску Лемпеля-Зіва (Lempela-Ziva) 9
Алгоритм LZSS 9
Алгоритм LZ78 9
Алгоритм LZW 10
Стиск інформації із втратами 10
Загальні теоретичні основи цифрових комунікацій 10
Особливості та алгоритми кодування голосу. 12
Огляд каналів та систем передачі інформації 13
Мережі типу Wi-Fi 15
Мережі типу Bluetooth 15
Мережі типу Wi-MAX 15
Cтандарт ІЕЕЕ 80216 15
Загальні особливості оптичних каналів зв’яку 15
Вірогідність передачі колових повідомлень 16
Деякі способи стиснення при передачі інформації 17
Зонне стиснення інформації 17
Стиснення інформації використанням адаптивного кодування 17
Стиснення інформації збільшення основи коду 18
Ефективність кодуванні при збільшення основи коду 18
Вплив зворотнього зв'язку на ефективність передачі інформації 19
Код Ріда-Соломона 19
Оптимальне кодування
Код чи кодування може бути оптимальним лише за певних умов, за певними критеріями. Найбільш часто оцінюють оптимальність коду за показниками надійності передачі або за швидкістю передачі.
Поєднання двох умов в одному оптимальному коді не рекомендується, оскільки вони переважно є суперечливими. Наприклад, для збільшення швидкості передачі інформації необхідно усувати надлишковість, а для покращення показників надійності потрібно вводити надлишковість.
Одним з основних критеріїв, які характеризують код є середня довжина кодових слів, яка визначається за виразом:
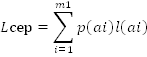
p(ai) – ймовірність появи і-ї букви первинного алфавіту
l(ai) – її довжина в коді.
Оптимальними без надлишковими називаються коди, які представляються кодовими словами мінімальної середньої довжини l. Ці коди є практично з нульовою надлишковістю. Верхня і нижня границі l визначаються нерівністю
H/log2m ≤ L ≤ (H/log2m) + 1
Н – ентропія первинного алфавіту; m – кількість якісних ознак вторинного алфавіту.
У випадку по блокового кодування де кожен блок складається з М незалежних букв а1, а2, а3… ам. Мінімальна середня довжина кодового слова лежить в межах які позначаються виразом:
(H*M)/log2m ≤ LM ≤ ((H*M)/log2m) + 1
З точки зору інформаційного навантаження на один символ повідомлення, блочне кодування є вигіднішим ніж одиночне по символьне.
Основні властивості оптимальних кодів
1. Мінімальна середня довжина кодового слова для оптимального коду забезпечується у тому випадку, коли надлишковість кожного кодового слова зводиться до мінімуму, а в ідеальному випадку зводиться до 0;
2. Кодові слова оптимального коду повинні будуватись з рівно ймовірних і взаємонезалежних символів.
З цих двох основних властивостей оптимальних кодів випливають принципи побудови оптимальних кодів:
1. принцип: вибір кожного кодового слова необхідно проводити так, щоб кількість вмістимо інформації була максимальною.
2. принцип: полягає в тому, що буквам вторинного алфавіту, які мають більшу ймовірність появи присвоюються короткі слова у вторинному алфавіті.
Методика Шенона і Фано
Для побудови кодів з мінімальною довжиною кодових слів можуть бути використані дві найбільш універсальні методики: перша базується на роботах вчених Шенона і Фано. Вона і отримала назву методики Шенона-Фано. Згідно з цією методики побудова оптимального ансамблю з повідомлень, які передаються, зводиться до наступних 6 кроків:
1. множина повідомлень розміщується, сортується у порядку спадання ймовірностей;
2. перший ансамбль символів розбивається на 2 групи таким чином, що сумарні ймовірності повідомлень обох груп були по можливості рівними.
Якщо рівної ймовірності у підгрупах досягти неможливо, тоді їх ділять таким чином, щоб у верхній підгрупі залишились символи, сумарна ймовірність яких менша сумарної ймовірності символів у нижній підгрупі.
3. першій групі присвоюється символ «0». другі1 – «1»;
4. кожну з утворених груп ділять на дві частини таким чином, щоб сумарні ймовірності нових утворених груп по можливості були рівні.
5. першим групам кожній із підгруп знову присвоюється нуль, а другим – одиниця. Таким чином отримують другі символи коду.
6. після цього кожне з 4-х груп ділиться на рівні, з точки зору сумарної ймовірності, частини до тих пір, поки в кожній с підгруп не залишиться по одній букві.