

Завдання 1.
Побудувати дискретне групування за даними про вік співробітників фірми (у роках)
|
21 |
20 |
24 |
21 |
23 |
24 |
23 |
24 |
20 |
25 |
|
22 |
24 |
25 |
23 |
21 |
25 |
20 |
24 |
21 |
20 |
|
20 |
22 |
23 |
25 |
23 |
22 |
20 |
21 |
22 |
20 |
Для
виконання завдання студентові потрібно
скорегувати значення параметру,
збільшивши представленні значення на
число
![]() ,
де
,
де
![]() - шифр студента, який дорівнює останній
цифрі номеру залікової книжки.
- шифр студента, який дорівнює останній
цифрі номеру залікової книжки.
Скореговані значення параметру, збільшені на число А = 33 - 24 = 9
|
30 |
29 |
33 |
30 |
32 |
33 |
32 |
33 |
29 |
34 |
|
31 |
33 |
34 |
32 |
30 |
34 |
29 |
33 |
30 |
29 |
|
29 |
31 |
32 |
34 |
32 |
31 |
29 |
30 |
31 |
29 |
Розв’язання.
Для побудови дискретного групування використаємо статистичну таблицю, у першій графі якої покажемо вік співробітників фірми у порядку зростання, у другій – кількість співробітників певного віку, у третій – частку співробітників кожного віку в загальній кількості.
Групування співробітників за віком
Таблиця 1
|
Вік співробітників фірми, х років |
Кількість співробітників f |
Частка співробітників кожного віку, % загальної кількості |
|
29 30 31 32 33 34 |
7 5 4 5 5 4 |
23,3 16,7 13,3 16,7 16,7 13,3 |
|
Разом |
30 |
100,0 |
Завдання 2.
-
За даними побудованого в завданні 1 ряду розподілу розрахувати характеристики центру розподілу (середню величину, моду та медіану). Представити графічне зображення розрахованих величин.
-
За даними ряду розподілу розрахувати абсолютні та відносні показники варіації, а також характеристики форми розподілу (коефіцієнти ексцесу та асиметрії).
-
Приймаючи досліджувану сукупність за 5% генеральної, визначити:
-
середню та граничну похибки оцінки середньої та інтервал можливих значень середньої величини для генеральної сукупності з вірогідністю 0,9545,
-
середню та граничну похибки частки першої групи розподілу з вірогідністю 0,9973, а також межі, в яких вона знаходиться в генеральній сукупності,
-
необхідний обсяг вибірки, яка б забезпечила оцінку вірогідності (частки) першої групи розподілу з точністю до 4% при довірчій вірогідності 0,9876.
За результатами розрахунків зробити висновки.
Розв’язання.
1. Розрахуємо середню величину (середній вік співробітників фірми).
Для розрахунку середнього віку співпрацівників фірми використаємо формулу середньої зваженої:
 .
.
Групування співробітників за віком
Таблиця 2
|
Вік співробітників фірми, х років |
Кількість співробітників f |
Частка співробітників кожного віку, % загальної кількості |
|
29 30 31 32 33 34 |
7 12 16 21 26 30 |
23,3 40,0 53,3 70,0 86,7 100,0 |
Знайдемо характеристику центру розподілу – моду (Мо).
Мода у статистиці – це та варіанта, яка найчастіше повторюється в сукупності.
Виходячи з даних таблиці 1, на фірмі найбільше працює співробітників 29-річного віку (f =7 чоловік).
Отже, мода Мо = 29 років.
Побудуємо графічне зображення у вигляді гістограми на основі даних табл.1 :
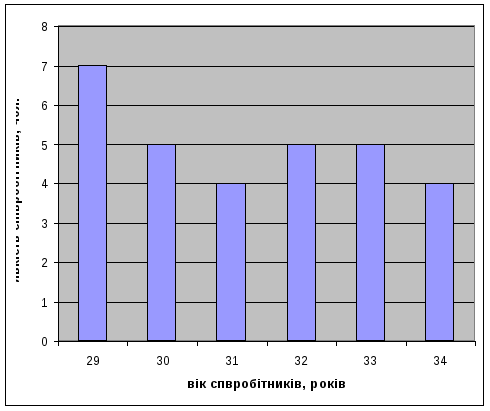
Тепер визначимо характеристику центру розподілу – меридіану (Ме).
Меридіана – це варіанта, що ділить упорядкований ряд на дві рівні за чисельністю частини. При цьому в одній частині значення варіюючої величини буде меншим, ніж у другій.
Ме
=
31 рік , так
як
![]()
Для побудови графічного зображення використаємо дані табл.2.

2. Для виміру і оцінки варіації використовують систему абсолютних і відносних характеристик, а саме: розмах варіації, середнє лінійне і середнє квадратичне відхилення, коефіцієнти варіації, дисперсію. Кожна з названих характеристик має певні аналітичні переваги при вирішенні тих чи інших завдань статистичного аналізу.
Розмах варіації (R) — це різниця між найбільшим і найменшим значеннями ознаки. Показник характеризує межі, в яких змінюється значення ознаки.
R = хmах—хmіп = 34 – 29 = 5 років
Середнє лінійне відхилення (l) – це середня арифметична з відхилень індивідуальних значень ознаки від їх середнього значення. Модуль відхилень варіації від її середнього значення використовують тому, що алгебраїчна сума цих відхилень дорівнює нулю. Для рядів з нерівними частотами

Отже, вік співробітників фірми відхиляється від середнього значення в середньому на 1,6 роки.
Дисперсія – це середній квадрат відхилення варіантів від їх середньої арифметичної. Отже,

Середнє квадратичне відхилення (абсолютне коливання значень варіюючої ознаки)

Отже, вік співробітників фірми відхиляється в окремих групах відхиляється від середнього значення в сукупності на 1,75 року.
При
порівнянні варіації різних ознак або
однієї ознаки в різних сукупностях
використовуються коефіцієнти варіації
V.
Вони визначаються відношенням абсолютних
іменованих характеристик варіації
(![]() ,
, ![]() ,
R) до центра розподілу, найчастіше
виражаються у процентах. Значення цих
коефіцієнтів залежить від того, яка
саме абсолютна характеристика варіації
використовується.
,
R) до центра розподілу, найчастіше
виражаються у процентах. Значення цих
коефіцієнтів залежить від того, яка
саме абсолютна характеристика варіації
використовується.
Коефіцієнти варіації визначаються:
лінійний
![]() ;
;
квадратичний
![]() ;
;
осциляції ![]() .
.
Вихідні дані та допоміжні розрахунки для розв’язання задачі
-
Вихідні показники
Розраховані показники
Вік співробітників фірми, х років
Кількість співробітників f
xf
x -

(x -
 )²
)²(x -
 )²f
)²f(x -
 )³
)³(x -
 )³f
)³f|x -
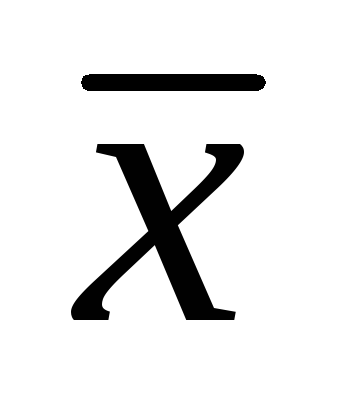 |
||x -
 |f
|f(x -
 )
)
(x -
 )
) f
f29
7
203
-2,27
5,14
35,96
-11,65
-81,52
2,27
15,87
26,40
184,78
30
5
150
-1,27
1,60
8,02
-2,03
-10,16
1,27
6,33
2,57
12,87
31
4
124
-0,27
0,07
0,28
-0,02
-0,08
0,27
1,07
0,01
0,02
32
5
160
0,73
0,54
2,69
0,39
1,97
0,73
3,67
0,29
1,45
33
5
165
1,73
3,00
15,02
5,21
26,04
1,73
8,67
9,03
45,13
34
4
136
2,73
7,47
29,88
20,42
81,68
2,73
10,93
55,82
223,27
Разом
30
938
1,40
17,83
91,87
12,33
17,94
9,00
46,53
94,11
467,52
Найпростішою
мірою асиметрії
є стандартизоване відхилення
![]()
![]() ,
яке характеризує напрям і міру скошеності
розподілу; при правосторонній асиметрії
,
яке характеризує напрям і міру скошеності
розподілу; при правосторонній асиметрії
![]() >
0, при лівосторонній —
>
0, при лівосторонній —
![]() <
0.
Звідси
правостороння асиметрія називається
додатною, а лівостороння — від’ємною.
<
0.
Звідси
правостороння асиметрія називається
додатною, а лівостороння — від’ємною.
![]()
![]()
Отже, коефіцієнт асиметрії 0,62 свідчить про високу правосторонню скошеність розподілу.
Асиметрія та ексцес — дві пов’язані з варіацією властивості форми розподілу. Комплексне їх оцінювання виконується на базі центральних моментів розподілу. Алгебраїчно центральний момент розподілу — це середня арифметична k-го ступеня відхилення індивідуальних значень ознаки від середньої:
 .
.
Моменти 3-го і 4-го порядків характеризують відповідно асиметрію та ексцес.
У
симетричному розподілі
![]() =
0. Чим більша скошеність ряду, тим більше
значення
=
0. Чим більша скошеність ряду, тим більше
значення
![]() .
Для того щоб характеристика скошеності
не залежала від масштабу вимірювання
ознаки,
для порівняння ступеня асиметрії різних
розподілів використовується
стандартизований момент
.
Для того щоб характеристика скошеності
не залежала від масштабу вимірювання
ознаки,
для порівняння ступеня асиметрії різних
розподілів використовується
стандартизований момент
![]() .
.

![]()
При
правосторонній асиметрії коефіцієнт
![]() >
0, при лівосторонній
>
0, при лівосторонній
![]() <
0. Звідси правостороння асиметрія
називається додатною, а лівостороння
— від’ємною. Вважається, що при
<
0. Звідси правостороння асиметрія
називається додатною, а лівостороння
— від’ємною. Вважається, що при
![]() <
0,25 асиметрія низька, якщо
<
0,25 асиметрія низька, якщо
![]() не перевищує 0,5 — середня, при
не перевищує 0,5 — середня, при![]() >
0,5 — висока.
>
0,5 — висока.
Для вимірювання ексцесу використовується стандартизований момент 4-го порядку

![]()
У
симетричному, близькому до нормального
розподілі
![]() =3.
При
гостровершинному розподілі
=3.
При
гостровершинному розподілі
![]() >
3, при плосковершинному
>
3, при плосковершинному
![]() <
3.
<
3.
3. 1. Середня вибіркова

Гранична похибка

Чисельність вибіркової n = 30 чол. (5% генеральної), чисельність генеральної сукупності – 600 чол.
Під час визначення середнього віку співробітників середня похибка вибірки
![]()
Граничну похибку вибірки (похибку репрезентативності) обчислюють за такою формулою:
![]()
де t — коефіцієнт кратності похибки, який показує, скільки середніх похибок міститься у граничній похибці; μх — середня похибка репрезентативності.
Межі можливої похибки (∆) визначають з певною ймовірністю. Значення t ймовірності наведено в табл.3
Таблиця 3
|
t |
ймовірність |
t |
ймовірність |
|
1,0 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 1,96 2,0 |
0,6827 0,7287 0,7699 0,8064 0,8385 0,8664 0,8904 0,9109 0,9281 0,9426 0,9500 0,9545 |
2,1 2,2 2,3 2,4 2,5 2,58 2,6 2,7 2,8 2,9 3,0 3,28 |
0,9643 0,9722 0,9786 0,9836 0,9876 0,9900 0,9907 0,9931 0,9949 0,9963 0,9973 0,9990 |
Визначимо інтервал можливих значень середньої величини для генеральної сукупності з вірогідністю 0,9545:
![]() ;
;
![]()
![]()
2. Межі, в яких знаходиться частка в генеральній сукупності, розраховуються:
![]() ,
,
![]() ,
де р — частка одиниць, які мають цю
ознаку в генеральній сукупності.
,
де р — частка одиниць, які мають цю
ознаку в генеральній сукупності.
У вибірковій сукупності перша група розподілу - вік співробітників 29 років (m = 7). Частка першої групи розподілу розраховується за формулою
![]() або
23,3%
або
23,3%
У разі безповторного відбору за умови, що N = 600, n = 30, ω = 0,233, P = 0,9973, t = 3, гранична похибка вибірки для частки
![]()
або 22,6%
Отже, частка першої групи розподілу вибіркової сукупності в генеральній сукупності перебуватиме в таких межах:
p
= 23,3
± 22,6, або
![]()
3. Необхідний обсяг вибірки, яка б забезпечила оцінку вірогідності (частки) першої групи розподілу з точністю до 4% при довірчій вірогідності 0,9876 ( t=2,5) розрахуємо за формулою:
![]()
Висновки: статистичне дослідження віку співробітників фірми проводилося вибірковим методом у вибірковій сукупності 30 чол., що становить 5% генеральної сукупності. Найбільш поширений вік співробітників фірми (Мо) – 29 років. Середній вік працівників фірми – 31,3 роки. Вік співробітників фірми відхиляється від середнього значення в середньому на 1,6 роки. Розраховані коефіцієнти асиметрії та ексцесу вказують на високу правосторонню скошеність та плосковершинність ряду розподілу. Інтервал можливих значень середньої величини для генеральної сукупності з вірогідністю 0,9545 знаходиться в межах від 30,7 до 31,9 років. Частка першої групи розподілу (m=7) вибіркової сукупності (n=30) в генеральній сукупності (N=600) з вірогідністю 0,9973 перебуватиме в межах від 0,7% до 45,9%. Необхідний обсяг вибірки, яка б забезпечила оцінку вірогідності (частки) першої групи розподілу з точністю до 4% при довірчій вірогідності 0,9876, становить 322 чол.