

5.3.3 Формирование ат-грамматики
Теперь покажем, как по конкретной входной КС-грамматике можно построить АТ-грамматику и определить ее класс.
Задача Дана КС-грамматика G = (VT, Vn, P, S) описания вещественных переменных, где VT- {real, имя, ,}, VN = {DCL, LIST), S = DCL и P - множество правил:
1)DCL -> real имя LIST
2)LIST ->, имя LIST
3)LIST->ε
Требуется сформировать АТ-грамматику описания переменных и распределения памяти под значения этих переменных в некотором блоке памяти. Адрес должен быть помещен в запись таблицы имен для соответствующей переменной. Для определенности положим, что переменной отводится одна нумерованная ячейка памяти.
Решение
1. Определим класс входной грамматики G. Следуя методике, изложенной в разделе LL(k)-грамматики, устанавливаем, что грамматика G обладает свойствами LL(1)-грамматик.
2. Преобразуем входную грамматику в Т-грамматику. Адрес должен быть назначен переменной сразу после чтения во входной строке символа имя. Поэтому операционный символ, который обозначим [ALLOC], располагается в Т-грамматике после каждого терминала имя:
DCL -> real имя [ALLOC] LIST
LIST-*, имя [ALLOC]LIST
3)LIST->ε
3. Определим атрибуты символов Т-грамматики. Атрибут символа имя - указатель на строку таблицы имен. Атрибуты символа DCL:
указатель на начальную ячейку блока памяти для переменных - наследуемый;
указатель на свободную ячейку после обработки всего описания - синтезируемый (от символа LIST в правой части правила).
Атрибуты символа LIST:
указатель на очередную свободную ячейку блока памяти - наследуемый (из левой части правила);
указатель на свободную ячейку после обработки всего описания — синтезируемый (от символа в левой или правой части правила).
Атрибуты символа [ALLOC]:
указатель на строку таблицы имен — наследуемый (от левого символа имя);
адрес ячейки памяти для значения переменной — наследуемый (от символа в левой части правила).
4. Выберем обозначения для атрибутов символов правила, положив i=0,1, ...:
pi — указатель на строку таблицы имен;
bi — указатель на свободную ячейку блока памяти;
ai — адрес, назначенный переменной.
5. Запишем грамматику, приписав символам атрибуты, а за тем пополнив ее комментариями для атрибутов и правилами вычисления их значений. В результате этих действий получим АТ-грамматику:
/*** DCLx1,x2 - наследуемый x1, синтезируемый х2; ***/
/*** LISTy1,y2 - наследуемый y1, синтезируемый у2; ***/
/*** [ALLOC]z1,z2 - наследуемые z1 и z2. ***********/
1) DCLb0,b1 -> real имяр0[АLLОС]p1,a0LISTb2,b3
p1 = p0, a0 = b0,b2 = b0+1, b1 = b3
2) LISTb0,b1 ->, имяр0[АLLОС]p1,a0LISTb2,b3
p1 = p0, a0 = b0,b2 = b0+1, b1 = b3
3) LISTboM -> ε
b1 = b0
Поясним отдельные формулы для вычисления значений атрибутов. Предварительно еще раз уточним функцию операционного символа [ALLOC]. По своей сути это подпрограмма, которая по указателю р1 на элемент таблицы имен для информации о переменной, предшествующей [ALLOC], помещает в определенное поле этого элемента адрес a0 ячейки для значения переменной. Носителем указателя является терминал имя, отсюда формула р1 = р0. Носителем адреса является первый атрибут нетерминала в левой части правила, отсюда формула a0 = b0. Информация о текущей свободной ячейке передается к другим правилам посредством атрибута b2 нетерминала LIST в правой части правила. Номер свободной ячейки на 1 больше последней занятой (формула b2 = b0 + 1). Атрибут b0 символа LIST в правиле 3 будет содержать адрес свободной ячейки после назначения адресов всем элементам списка переменных. Поэтому второй атрибут в этом правиле должен получить значение первого (формула b1 = b0). Формула b1 = b3 позволяет передать это значение атрибуту b1 нетерминала DCL.
6. Определим класс АТ-грамматики.
Для этого проверим выполнение условий для атрибутов из определения L-AT-грамматики. Все эти условия выполняются. Значит, полученная грамматика есть L-AT-грамматика с входной LL(1)-грамматикой.
Порядок вычисления значений атрибутов хорошо иллюстрируется с помощью дерева разбора активной атрибутной цепочки.
Пример Для входной строки real имя5, имя4 и L-AT-грамматики из предыдущей задачи дерево разбора соответствующей активной атрибутной цепочки показано на рис. 5.5. В этом примере начальный адрес в блоке принят равным нулю.
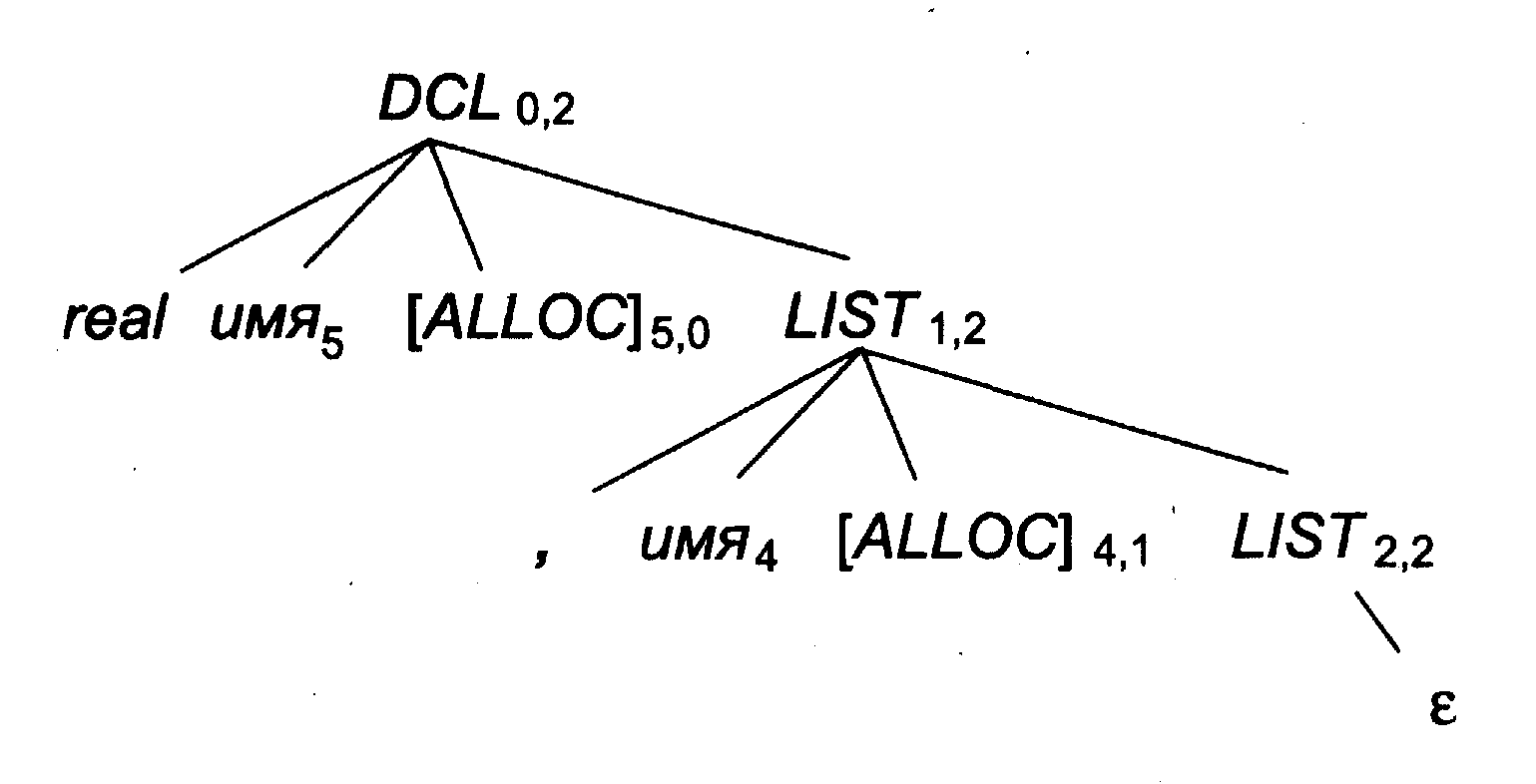
Рисунок 5.5 Дерево разбора активной атрибутной цепочки
real имя5 [ALLOC]5 имя4 [ALLOC]4
После построения безатрибутного дерева оно заполнялось значениями атрибутов. Вычисление наследуемых атрибутов выполнялось раньше синтезируемых и велось в направлении от корня дерева к его листьям. Синтезируемые атрибуты, напротив, вычислялись при движении от листьев к корню. Интересно проследить, как пришедшая сверху информация (номер 2 очередной свободной ячейки) направляется снова вверх после применения правила 3 грамматики. Заметим также, что свойство L-атрибутной грамматики обеспечивает вычисление атрибутов в порядке, пригодном для нисходящей обработки входной строки.
Атрибутную трансляцию, описанную формально АТ - грамматикой, можно выполнить с помощью атрибутного МП - преобразователя, который называют также атрибутным МП - процессором или атрибутной МП - машиной. Выполнение атрибутной трансляции предполагает следующие действия МП - преобразователя:
- последовательное чтение входных символов вместе с их атрибутами;
- проверку принадлежности входной строки языку, определенному входной грамматикой;
- выдачу последовательности атрибутных операционных символов, соответствующей входной строке, из активной атрибутной цепочки.
Атрибутный МП - преобразователь представляет собой обычный МП- преобразователь, у которого состояния, входные, выходные и магазинные символы имеют атрибуты. На каждом шаге работы преобразователя значения атрибутов нового состояния, нового верхнего символа магазина (если этот шаг — не выталкивание из магазина) и выходных символов вычисляются как функции атрибутов старого состояния, верхнего символа магазина и входного символа (если это не пустой шаг). Вопросы построения атрибутных МП - преобразователей здесь рассматривать не будем.