

Реализация структур данных типа дерево и типовые алгоритмы их обработки
Постановка задачи
Реализовать процедуры создания красно-черных деревьев (динамическое представление), поиска, удаления и добавления узлов. Реализовать малое левое вращение для решения задач балансировки
Теоретические положения.
Красно-чёрное дерево— самобалансирующееся двоичное дерево поиска, имеющее сложность О(logn), которое быстро выполняет основные операции: добавление, удаление и поиск узла. Узлы дерева имеют атрибут «цвет», что помогает сбалансировать дерево. Атрибут может принимать значения «черный» или «красный». Дерево обладает свойствами: корень и листья дерева – обязательно черные и оба потомка красного узла – черные.
Балансировка дерева– операция изменения связи предок-потомок в случае разницы высот правого и левого поддеревьев больше 1. Результат достигается путем вращения поддерева данной вершины.
Описание сферы практического применения используемого типа данных – дерева.
Красно-черное дерево – особый вид двоичного дерева, который используется для организации данных, например, чисел или текста. В таком дереве быстро выполняется поиск. Листья красно-черного дерева не имеют данных. Эти деревья – самобалансирующиеся.
Описание алгоритмов обработки дерева.
Вставка: Узел окрашивается в красный цвет, и если мы вставляем узел в лист, то добавляем в этот лист красный узел с двумя черными потомками. Затем выполнить балансировку.
Удаление:
Если у вершины нет потомков, то изменяем указатель на неё у родителя на null.
Если у неё только один потомок, то делаем у родителя ссылку на него вместо этой вершины.
Если же имеются оба потомка, то находим вершину со следующим значением ключа. У такой вершины нет левого потомка. Удаляем уже эту вершину описанным во втором пункте способом, скопировав её ключ в изначальную вершину.
Сбалансировать дерево.
Результаты работы программы
Представлен пример выполнения программы.
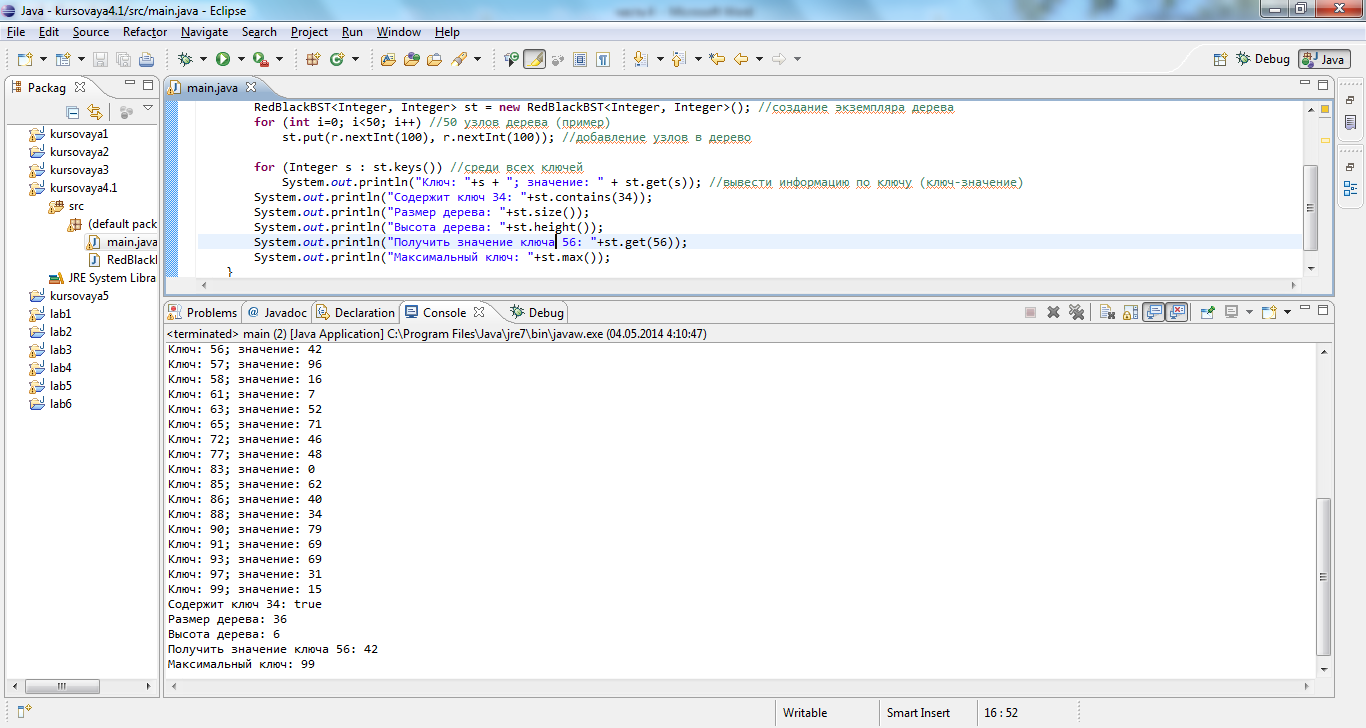
Рис.6. Результат работы 4-ой части программы
Реализация функций расстановки (хеширование) и различных методов разрешения коллизий
Постановка задачи
Хеш-таблица представляет базу данных предметной области, соответствующей варианту. Реализовать:
Выбор ключа для соответствующей базы данных.
По крайней мере, 3 различных функции хеширования для конкретных данных.
Заполнение таблицы для каждой функции.
Добавление новых данных для каждой функции.
Удаление данных.
Поиск данных по ключу.
Оценку качества хеширования для каждой функции.
Сравнение функций хеширования.
Краткое теоретическое положение.
Хеш-таблица– структура данных, которая реализует интерфейс ассоциативного массива, т.е., хранит пары: ключ и значение и выполняет основные операции: добавление пары, удаление по ключу и поиск по ключу.
Хеширование – средство быстрого поиска данных, основанное на вычислении хеш-функции (числа, определяемого элементом данных). Это число - индекс в массиве ссылок на данные. При одинаковых хеш-значениях разных ключей возникают так называемые коллизии.
Метод разрешения коллизий: двойное хеширование. Двойное хеширование – основан на использовании двух хеш-функций. Коллизии возникают при открытой адресации. Берется значениеhash1, если значение уже использовано, то вычисляется вторая вспомогательная функция, и берется значениеhash1+hash2,hash1+2*hash2 и т.д.