

Insert into { базовая_таблица | представление} [(столбец1 [, столбец2] ...)]
{VALUES ({константа1 | переменная1} [,{константа2 | переменная1}]…)
|<табличный_подзапрос>}
[RETURNING <список_столбцов> [INTO <список_переменных>]];.
Пример:
INSERT INTO Abonent (AccountCD, StreetCD, HouseNO, FlatNO, Fio, Phone)
VALUES (‘50000’, 8, 1, 1, ‘ПЛИТОВ Е.Д.’, NULL);.
Если в списке предложения VALUES указаны значения для всех столбцов модифицируемой таблицы и порядок их перечисления соответствует порядку столбцов в описании таблицы (как в предыдущем примере), то список столбцов в предложении INTO можно опустить. NULL если неизвестное значение.
Многострочный запрос, пример:
INSERT INTO { базовая_таблица | представление} [(столбец1 [, столбец2] ...)]
<табличный_подзапрос>
[RETURNING <список_столбцов> [INTO <список_переменных>]];.
Пример:
INSERT INTO Fio (Abonent_name, Executor_name)
SELECT A.Fio, E.Fio
FROM Abonent A, Executor E, Request R
WHERE R.AccountCD = A.AccountCD AND
R.ExecutorCD = E.ExecutorCD;.
Если ранее было создано представление Abonent_Executor со столбцами abonent_name и executor_name, то предыдущий запрос можно переписать следующим образом:
INSERT INTO Fio
SELECT Abonent_name, Executor_name
FROM Abonent_Executor;.
Каким образом осуществляется вставка пустого значения в ячейку таблицы?
Если требуется ввести NULL-значение, например, в поле Phone (номер телефона абонента неизвестен), то оно вводится точно так же, как и обычное значение, например:
INSERT INTO Abonent
VALUES (‘50000’, 8, 1, 1, ‘ПЛИТОВ Е.Д.’, NULL);
Приведите пример удаления единственной записи таблицы.
Простой запрос DELETE позволяет удалить содержимое всех строк указанной таблицы или тех ее строк, которые выделяются условием поиска предложения WHERE , и имеет следующий формат:
DELETE FROM {базовая_таблица | представление}
[WHERE <условие_поиска> | WHERE CURRENT OF имя_курсора]
[RETURNING <список_столбцов> [INTO <список_переменных>]];.
Например, чтобы удалить из таблицы Abonent абонента с номером лицевого счета, равным '005488', требуется выполнить следующий запрос:
DELETE FROM Abonent
WHERE AccountCD = '005488';.
Приведите пример удаления множества записей.
DELETE FROM Abonent
Каким образом осуществляется удаление с вложенным подзапросом?
В предложении WHERE запроса DELETE можно использовать вложенные запросы, которые могут быть как простыми, так и коррелированными. Использование подзапросов в DELETE аналогично использованию таковых в SELECT.
Примеры:
Пусть необходимо удалить сведения о ремонтных заявках абонента Мищенко Е.В. Запрос на удаление соответствующих заявок можно записать в следующем виде:
DELETE FROM Request WHERE AccountCD IN
(SELECT AccountCD FROM Abonent
WHERE Fio = ‘МИЩЕНКО Е.В.’);.
Рассмотрим использование коррелированного подзапроса в предложении WHERE запроса DELETE, т.е. подзапроса, который содержит внешнюю ссылку на текущую строку таблицы, из которой удаляются данные. Например, для удаления всех сведений об оплате услуг газоснабжения абонентами, проживающими на улице Татарской, можно использовать следующий запрос:
DELETE FROM PaySumma P WHERE EXISTS
(SELECT * FROM Abonent A, Street S
WHERE S.StreetNM = ‘ТАТАРСКАЯ УЛИЦА’ AND A.StreetCD = S. StreetCD AND P.AccountCD = A. AccountCD);.
При помощи какой команды осуществляется модификация данных в MS SQL Server?
Модификация данных может выполняться с помощью команд:
DELETE (удалить),
INSERT (вставить),
UPDATE (обновить).
Приведите пример использования команды UPDATE с предложением FROM.
UPDATE [University].[dbo].[Fack]
SET [FackName] = 'КТАСиЗИ'
FROM [University].[dbo].[Fack], [University].[dbo].[Univeristy]
WHERE ([Univeristy].[UniveristyName] = 'КубГТУ') and ([Fack].[FackName]='КТАС')
SET указывает столбцы, которые будут изменяться, и значения, которые им присваиваются. С помощью предложения WHERE отбираются записи, которые будут обновляться. Команда UPDATE не может вставить в колонку данные «чужого» типа либо значения, которые нарушают правила ввода для столбца. В случае неудачи хотя бы с одним столбцом изменения произведены не будут.
Приведите пример обновления множества записей.
Пусть требуется утроить цену всех продуктов таблицы поставки (кроме цены за кофе, где код продукта (Поле ПР) - ПР = 17).
UPDATE Поставки
SET Цена = Цена * 3
WHERE ПР <> 17;
Приведите пример обновления записей с подзапросом.
В UPDATE можно в предложении WHERE использовать вложенные
запросы. Также допускается использование вложенного запроса в предложении SET.
Установить равной нулю цену и К_во продуктов для поставщиков из Москвы и Ростова.
UPDATE Поставки
SET Цена = 0, К_во = 0
WHERE ПС IN
(SELECT ПС
FROM Поставщики
WHERE Город IN ('Москва', 'Ростов'));
Приведите пример обновления записей нескольких таблиц.
Пусть необходимо изменить данные о продукте с кодом 13 в двух таблицах «Состав» и «Наличие».
Например требуется изменить номер продукта ПР = 13 на ПР = 20.
UPDATE Продукты UPDATE Состав
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
UPDATE Поставки UPDATE Наличие
SET ПР = 20 SET ПР = 20
WHERE ПР = 13; WHERE ПР = 13;
К сожалению, в единственном запросе невозможно обновить более одной таблицы, а так как код продукта входит в четыре таблицы, то пришлось сформировать четыре сходных запроса. Это может привести к противоречию базы данных (нарушению целостности по ссылкам), поскольку после выполнения первого предложения таблицы Состав, Поставки и Наличие ссылаются на уже несуществующий продукт. База становится непротиворечивой только после выполнения четвертого запроса.
Общая структура команды SELECT. Где и для каких целей применяется выборка? Как просмотреть результаты выборки?
С помощью команды SELECT можно найти и просмотреть данные из базы данных, причем сделать это несколькими способами. Хотя этот оператор обычно применяется для извлечения данных со специфическими свойствами, его можно использовать и для присваивания значений локальным переменным, и для вызова функций. Оператор SELECT может быть простым или сложным.
Синтаксически оператор SELECT состоит из нескольких предложений, большинство из которых не являются обязательными. Этот оператор должен обязательно иметь предложения SELECT и FROM. Они задают соответственно колонку(и) и таблицу(ы), из которых будут извлекаться данные. Предложение WHERE указывает, какие записи надо выбрать.
SELECT <Список столбцов>
FROM <Список таблиц>
[WHERE <Условия поиска>]
В случае если необходимо просто вывести информацию из всех столбцов, имеющихся в таблицах (указанных в предложении FROM), используйте звездочку (*). В этом случае поля на экран будут выводиться в том порядке, как они создавались с помощью команды CREATE TABLE.
SELECT *
FROM Groups
Результат выборки, например:
G_number P_name
-------- ------------
03-KT-21 программисты
03-KT-22 программисты
03-KT-23 программисты
(3 row(s) affected)
Приведите примеры условий формирования условий отбора? Перечислить операторы, которые могут применяться в предложении WHERE?
Операторы, используемые в предложенииWHERE
|
Тип операторов |
Операторы |
|
Сравнение |
(=, >, <, >=, <=, <>, !=, !<, !>) |
|
Интервал |
BETWEEN, NOT BETWEEN |
|
Список |
IN, NOT IN |
|
Сравнение строк |
LIKE, NOT LIKE |
|
Проверка значения |
IS NULL, IS NOT NULL |
|
Логические |
AND, OR |
|
Отрицание |
NOT |
При использовании операторов сравнения необходимо придерживаться двух простых правил:
Выражения могут содержать константы, имена столбцов, функции, вложенные запросы и арифметические операторы.
Использовать одинарные кавычки с данными типаchar, varchar, text, datetimeиsmalldatetime. Хотя двойные кавычки не запрещены, одинарные кавычки предпочтительней для совместимости со стандартомANSI.
Операторы сравнения
-
Оператор
Значение
=
Равно
>
Больше чем
<
Меньше чем
>=
Не меньше
<=
Не больше
!=
Не равно
<>
Не равно
Обычно в предложении WHEREприходится использовать несколько условий поиска, которые объединяются логическими операторамиAND,OR,NOT(их еще называют булевыми операторами). Смысл этих операторов такой же, как и во всех языках программирования:AND– это логическое И,aOR– ИЛИ.
При выборке символьных данных иногда возникают трудноразрешимые вопросы, связанные с тем, что мы не всегда можем точно вспомнить какую-либо информацию. В этом случае на помощь приходит оператор LIKE. Синтаксис оператораLIKE:
WHERE <Имя столбца> [NOT] LIKE < 'Шаблон' > [ESCAPE <Символ>]
Дополнительные возможности вывода в предложении SELECT.
По умолчанию сортировка производится по возрастанию. Если вам нужна сортировка в обратном порядке, можете воспользоваться опцией DESC предложения ORDER BY. Например, если в предыдущем запросе в предложении ORDER BY будет добавлена опция DESC, то выборка будет отсортирована в обратном алфавитному порядке:
SELECT 'Студенты:'+space(1), S_lastname Фамилия, S_name Имя, S_patronymic Отчество
FROM Student
ORDER BY S_lastname, S_name, S_patronymic DESC
Проверка на принадлежность диапазону значений. Проверка на соответствие шаблону.
Другой формой условия поиска является проверка на принадлежность
диапазону значений, которая реализуется с помощью ключевого слова
BETWEEN. Синтаксис использования этого условия поиска следующий:
<значение> [NOT] BETWEEN <значение1> AND <значение2>.
Например, если необходимо найти номера лицевых счетов абонентов, у которых значения начислений за оказанные услуги лежат в диапазоне от 60 до 250, то соответствующий запрос будет выглядеть следующим образом:
SELECT AccountCD, Nаchislsum
FROM NachislSumma
WHERE NachislSum BETWEEN 60 AND 250;.
Результат выполнения запроса:
ACCOUNTCD NACHISLSUM
115705 250,00
080047 80,00
080047 80,00
115705 250,00
443069 80,00
005488 62,13
080270 60,10
Проверка на соответствие шаблону, которая осуществляется с помощью ключевого слова LIKE, позволяет определить, соответствует ли значение данных некоторому шаблону. Синтаксис использования этого условия поиска следующий:
<значение> [NOT] LIKE 'шаблон' [ESCAPE 'символ_пропуска'].
Например, пусть необходимо выбрать из таблицы Abonent абонентов, фамилии которых начинаются с буквы С. Для условия поиска используется шаблон 'С%' следующим образом:
SELECT Fio FROM Abonent WHERE Fio LIKE 'C%';.
Результат выполнения запроса:
FIO
СВИРИНА З.А.
СТАРОДУБЦЕВ Е.В.
Составные условия поиска.
- NOT задает отрицание условия поиска, к которому применяется, и имеет наивысший приоритет. Используется следующий синтаксис: NOT <условие_поиска>;
- AND создает сложный предикат, объединяя два или более условий поиска, каждое из которых должно быть истинным, чтобы был истинным и весь предикат. Данная операция является следующей по приоритету после NOT. Используется следующий синтаксис: <условие_поиска1> AND <условие_поиска2> …;
- OR создает сложный предикат, объединяя два или более условий поиска, из которых хотя бы одно должно быть истинным, чтобы был истинным и весь предикат. Является последней по приоритету из трех логических операций и имеет следующий синтаксис: <условие_поиска1> OR <условие_поиска2> ….
Дайте определения функции агрегирования. Перечислить функции агрегирования, опишите их назначение?
Для подведения итогов по данным, содержащимся в БД, в языке SQL предусмотрены агрегатные (статистические) функции. Агрегатная функция берет в качестве аргумента какой-либо столбец (для множества строк), а возвращает одно значение, определяемое типом функции:
AVG – среднее значение в столбце;
SUM – сумма значений в столбце;
MAX – наибольшее значение в столбце;
MIN – наименьшее значение в столбце;
COUNT – количество значений в столбце.
Примеры использования:
чтобы вычислить среднее значение оплат всех абонентов, необходимо выполнить следующий запрос:
SELECT AVG(Paysum) FROM Paysumma;.
Результат выполнения :
AVG
45,17
для нахождения суммы всех значений начислений можно использовать следующий запрос:
SELECT SUM(NachislSum) FROM NachislSumma;.
Результат выполнения:
SUM
2 213,61
чтобы найти в таблице PaySumma максимальное и минимальное значения оплат можно выполнить следующий запрос:
SELECT MAX(PaySum), MIN(PaySum) FROM PaySumma;.
Результат выполнения:
MAX MIN
250,00 8,30
Следующий запрос позволяет подсчитать число различных абонентов, которые подавали заявки на ремонт газового оборудования:
SELECT COUNT(DISTINCT AccountCD) FROM Request;.
Результат выполнения :
COUNT
10
Какое предложение применяется для сортировки данных выборки, условия его применения? Каким образом осуществляется выборка из нескольких страниц? Приведите пример создания таблицы на основе выборки.
Скалярные функции SQL.
Скалярные пользовательские функции возвращают скалярный (однозначный) результат, такой как строка или число. На типы данных, возвращаемых скалярной функцией, накладывается несколько ограничений. Запрещается использовать нескалярные типы, такие как курсоры и таблицы. Кроме того, скалярные функции не могут возвращать значения с типом timestamp, text, ntext или image, а также значения, имеющие тип данных, определенный пользователем, даже если базовый тип при этом является скаляром.
Скалярные функции могут использоваться везде, где может использоваться возвращаемое функцией значение с соответствующим типом данных. Это может быть список столбцов в фразе WHERE оператора SELECT, выражение, условие ограничения в определении таблицы или даже описание типа данных в столбце таблицы.
Строковые ф-ии
Например, для вывода номеров лицевых счетов абонентов и первых трех символов их фамилии можно использовать следующий запрос:
SELECT A.AccountCD, SUBSTRING (A.Fio FROM 1 for 3) AS Fio3
FROM Abonent A;
Числовые ф-ии
Эти функции возвращают числовые значения на основании значений того же типа, заданных в аргументе. Числовые функции используются для обработки данных, а также в условиях поиска.
Ф-ии даты и времени
Для выделения значений дня, месяца и года из даты используется функция EXTRACT. Синтаксис этой функции следующий:
EXTRACT( { DAY | MONTH | YEAR} FROM <значение> ),
где <значение> - любое выражение, возвращающее результат типа «дата-время» (т.е. название таблицы в формате даты).
Ф-ия преобразования типа
Агрегатные функции SQL.(см вопрос 67)
Условные операторы в SQL.
Многотабличные и вложенные запросы. Соединение таблиц.
Дайте определения триггеру. Приведите примеры возможных триггеров? Описать синтаксис набора команд создания триггеров? Что необходимо учитывать при использовании триггеров?
Триггер – это специальный тип хранимой процедуры, которая запускается автоматически системой SQL Server при модифицировании какой-либо таблицы одним из трех операторов: UPDATE, INSERT или DELETE. Триггеры, как другие хранимые процедуры, могут содержать простые или сложные операторы T-SQL. В отличие от других типов хранимых процедур триггеры запускаются автоматически при указанных модификациях данных; их нельзя запустить вручную по имени. Триггер создается по одной таблице базы данных, но он может осуществлять доступ и к другим таблицам и объектам других баз данных. Триггеры нельзя создать по временным таблицам или системным таблицам, а только по определенным пользователем таблицам или представлениям.
Существует пять типов триггеров: UPDATE, INSERT, DELETE, INSTEAD OF и AFTER.
Команда CREATE TRIGGER имеет следующий синтаксис:
CREATE TRIGGER [<Имя владельца>.]<Имя триггера>
ON [<Имя владельца>.]<Имя таблицы>
FOR { INSERT | UPDATE | DELETE [, ...]}
AS
<Команда>
Пример:
CREATE TRIGGER Table_delete
ON Student_c
FOR DELETE
AS
DELETE S_lastname
FROM Student, Deleted
WHERE EXISTS Student.S_lastname = Deleted.Lastname
Необходимо учитывать, что есть команды, которые нельзя использовать в триггерах:
все команды CREATE применительно к объектам DATABASE, TABLE, INDEX, PROCEDURE, DEFAULT, RULE, TRIGGER и VIEW;
все команды DROP;
ALTER TABLE и ALTER DATABASE;
TRUNCATE TABLE;
GRANT и REVOKE;
UPDATE STATISTICS;
RECONFIGURE;
LOAD DATABASE и LOAD TRANSACTION;
все команды DISK;
SELECT INTO (из-за того, что она создает таблицу).
Дайте определение соединению. Перечислите основные конструкции для формирования соединений.
Приведите пример использования конструкции JOIN. Приведите пример использования конструкции INNER JOIN.
Конструкция JOIN выполняет именно ту задачу, на которую указывает смысл соответствующего английского глагола, — соединяет информацию из двух таблиц в один результирующий набор.
Отличительная особенность INNER JOIN состоит в том, что она возвращает только те строки, которые были согласованны по всем полям. Наиболее предпочтительный формат кода для конструкции INNER JOIN выглядит примерно таким образом:
SELECT <select list>
FROM <first_table>
<join_type> <second_table>
[ON <join_condition>]
Чем отличаются результаты выполнения соединений конструкций JOIN и INNER JOIN?
Во время работы с данными, хранящимися в нормализованной базе данных, часто приходится сталкиваться с ситуациями, в которых всю необходимую информацию невозможно получить только из одной таблицы. В других случаях вся информация, которая должна быть получена, находится в одной таблице, но выборка этих данных должна осуществляться по условиям, подлежащим проверке по другой таблице. Конструкция JOIN предназначена для использования именно в таких ситуациях.
Конструкция JOIN выполняет именно ту задачу, на которую указывает смысл соответствующего английского глагола, — соединяет информацию из двух таблиц в один результирующий набор. Результирующий набор можно рассматривать как «виртуальную» таблицу. В него входят и столбцы, и строки, а сами столбцы характеризуются определенными типами данных. Результирующий набор можно использовать так, как если бы это была таблица, и обращаться к нему для выполнения других запросов.
Конкретные способы, применяемые в конструкции JOIN для соединения информации из двух таблиц в один результирующий набор, зависят от того, какие указания предусмотрены в этой конструкции, касающиеся сбора данных из разных таблиц, поэтому и предусмотрены четыре разных типа конструкции JOIN. Но все разности конструкций JOIN имеют одну общую отличительную особенность в том, что в них одна строка согласуется с одной или несколькими другими строками для получения результирующей строки, представляющей собой надмножество, созданное путем соединения нолей из нескольких записей.
Например, предположим, что строки с данными о кинофильмах берутся из таблицы Films
Таблица 1. Одна строка с данными из таблицы Films
|
FilmlD |
FilmName |
YearMade |
|
1 |
My Fair Lady |
1964 |
Теперь перейдем к рассмотрению строки из таблицы с данными об актерах, называемой Actors (таблица 2).
Таблица 2. Одна строка с данными из таблицы Actors
|
FilmlD |
FirstName |
LastName |
|
1 |
Rex |
Harrison |
Конструкция JOIN позволяет создать одну строку из двух строк, находящихся в полностью отдельных таблицах (таблица 3).
Таблица 3. Строка, полученная в результате соединения строк с данными из таблиц Films и Actors
|
FilmID |
FilmName |
YearMade |
FirstName |
LastName |
|
1 |
My Fair Lady |
1964 |
Rex |
Harrison |
С помощью этой конструкции JOIN строки соединяются на основании СВЯЗИ "один к одному" (по крайней мере такое впечатление складывается на основании приведениях данных). Одна строка из таблицы Films соединяется с одной строкой из таблицы Actors.
Немного дополним условия этого примера и рассмотрим, что при этом произойдет. Введем еще одну строку в таблицу Actors (таблица 4).
Таблица 4. Две строки с данными из таблицы Actors
|
FilmlD |
FirstName |
LastName |
|
1 |
Rex |
Harrison |
|
1 |
Audrey |
Hepburn |
Теперь рассмотрим, что произойдет после соединения дополненной таблицы Actors с той же таблицей Films (содержащей только одну строку) (таблица 5).
Таблица 5. Результаты соединения дополненной таблицы Actors с таблицей Films
|
FilmID |
FilmName |
YearMade |
FirstName |
LastName |
|
1 |
My Fair Lady |
1964 |
Rex |
Harrison |
|
1 |
My Fair Lady |
1964 |
Audrey |
Hepburn |
Вполне очевидно, что полученные данные существенно изменились, поскольку больше нельзя утверждать, что между таблицами наблюдается связь «один к одному»; скорее, здесь присутствует связь «один ко многим».
О тличительная
особенность
INNER
JOIN
состоит
в том, что она возвращает только те
строки, которые были согласованны по
всем полям.
тличительная
особенность
INNER
JOIN
состоит
в том, что она возвращает только те
строки, которые были согласованны по
всем полям.
Отметим, что ее помощью можно создавать исключительное соединение, т.е. соединение, в котором исключены все строки, не имеющие определенного значения в обеих таблицах
Пример:
USE Universitet
Select sp.SpecName, stud.StudentFirstName
FROM Spec AS sp
INNER JOIN Students AS stud
ON stud.IdSpec = sp.IdSpec
GO
Перечислите общие свойства конструкции INNER JOIN и конструкции WHERE.
До сих пор при описании особенностей конструкции INNER JOIN фактически затрагивались только те концепции, которые применимы к соединениям любых других типов, поскольку принципы определения порядка расположения столбцов в результирующем наборе и применения псевдонимов являются полностью одинаковыми для конструкций JOIN любых типов. А то, в чем конструкция INNER JOIN отличается от конструкций JOIN других типов осталось не рассмотренным. Отметим, что ее помощью можно создавать исключительное соединение, т.е. соединение, в котором исключены все строки, не имеющие определенного значения в обеих таблицах (в левой таблице, как называют таблицу, указанную в первую очередь, и в правой таблице, заданной во вторую очередь).
Рассмотрим несколько примеров того, как проявляется это свойство.
Допустим, что имеется таблица Customers, в которой собраны все данные об именах и адресах заказчиков. Но наличие большого списка заказчиков компании отнюдь не означает, что в текущий момент компанией действительно выполняются заказы, полученные от всех заказчиков. Фактически можно смело предположить, что в текущий момент имеются такие заказчики, которые не разместили в компании ни одного заказа. Например, требуется выполнить запрос, позволяющий отобрать информацию обо всех заказчиках, заказы которых выполняются в настоящее время.
SELECT DISTINCT с.CustomerID, с.CompanyName
FROM Customers с
INNER JOIN Orders о
ON c.CustomerID = o.CustomerlD
Обратите внимание на то, что в запросе используется ключевое слово DISTINCT, поскольку достаточно знать только количество заказчиков, сделавших заказы (причем достаточно только одного упоминания каждого заказчика), а не количество заказов. Если бы в этом запросе отсутствовало ключевое слово DISTINCT, то была бы возвращена отдельная строка, относящаяся к каждому заказчику для каждой строки из таблицы Orders, в которой имеется информация об этом заказчике.
Теперь попытаемся получить информацию об общем количестве заказчиков и для этого вызовем на выполнение следующий простой запрос с агрегирующей функцией COUNT:
SELECT COUNT (*) AS "No. Of Records" FROM Customers
Применение конструкции INNER JOIN приводит к исключению строк в связи с тем, что не обнаруживаются соответствующие им строки в другой таблице, а использование конструкции WHERE приводит к исключению строк из возвращаемого набора, поскольку эти строки не соответствуют сданным критериям.
Дайте определение связующей таблице? Для чего и в каком случае используются связующие таблицы?
Связующей таблицей (иногда называемой также таблицей ассоциации, или таблицей слияния) называют любую таблицу, основным назначением которой является не хранение собственных данных, а создание связей между данными, хранимыми в других таблицах. Такие таблицы можно рассматривать как средства "обеспечения взаимодействие", или "создания связей" между двумя или несколькими таблицами. В частности, связующие таблицы позволяют найти выход в такой часто складывающейся ситуации, когда имеет место так называемая связь "многие ко многим" между таблицами. В такой ситуации две таблицы содержат связанные друг с другом данные, причем и в той и s другой таблице может находиться большое количество строк, которые согласуются со многими строками в другой таблице. СУБД SQL Server не позволяет непосредственно реализовывать подобные связи, поэтому применяются связующие таблицы, позволяющие разделить связь "многие ко многим" на две связи "один ко многим", а последние поддерживаются СУБД SQL Server.
|
authors |
titles |
titleauthor |
|
au id |
title id |
au id |
|
au lname |
Title |
title id |
|
au fname |
Type |
au ord |
|
Phone |
pub_id |
royaltyper |
|
address |
Price |
|
|
City |
Advance |
|
|
State |
Royalty |
|
|
Zip |
ytd_sales |
|
|
contract |
Notes pubdate |
|
Введение указанной третьей таблицы в конструкции JOIN не составляет труда, этого достаточно снова указать в конструкции FROM таблицу, в которой находится требуемая информация, и задать ключевые слона JOIN (прежде чем вызвать на выполнение этот оператор, не забудьте переключиться на базу данных pubs):
SELECT a.au_lname + ', ' + a.au_fname AS "Author", t.title FROM authors a JOIN titleauthor ta
ON a.au_id = ta.au_id JOIN titles t
ON t.titleJLd = ta.title_id
Обратите внимание на то, что таблицам присвоены псевдонимы, поэтому необходимо вернуться в начало оператора и внести изменения в конструкцию SELECT с учетом использования псевдонимов, но на этом составление оператора SELECT с соединением трех таблиц заканчивается.
Приведите пример соединения с использованием конструкции OUTER JOIN.
Применение конструкции JOINтакого типа, какOUTERJOIN, скорее можно считать исключением, а не правилом:
Чаще всего при выборке данных с использованием оператора соединения необходимо обеспечить, чтобы данные соответствовали всем заданным критериям, а этого позволяет добиться только конструкция INNERJOIN.
Многие разработчики, использующие язык SQL, осваивают лишь внутреннее соединение, осуществляемое с помощью конструкции INNER JOIN, но так и не заходят глубже; иными словами, многие разработчики просто не умеют пользоваться разновидностью оператора соединения с конструкцией OUTER.
Цели, которые позволяет достичь применение конструкции OUTER JOIN, часто достижимы с помощью других методов.
Разработчики зачастую просто забывают о том, что может использоваться подобная конструкция.
При использовании конструкции INNERJOINисключаются все строки, не соответствующие всем заданным критериям, а при использовании конструкцииOUTERсуществует возможность включить в результирующий набор строки, которые соответствуют хотя бы одному из заданных критериев.
Задача освоения первого варианта синтаксиса является несложной, и большинство разработчиков с ней успешно справляются:
SELECT <SELECT list>
FROM <the table you want to be the "LEFT" table>
<LEFT|RIGHT> [OUTER] JOIN <table you want to be the "RIGHT" table> ON <join condition>
Следует отметить, что ключевое слово OUTER является необязательным, достаточно лишь включить ключевое словоLEFTилиRIGHT(например,LEFTJOIN). Таблица, имя которой упоминается перед ключевым словомJOIN, рассматривается как левая таблица,LEFT, а таблица, имя которой следует за ключевым словомJOIN, — как правая таблица,RIGHT.
Предположим, что необходимо узнать, какие скидки предоставляются покупателю, величину каждой скидки и названия магазинов, в которых эти скидки предоставляются. В базе данных pubs находятся таблицы discounts и stores,
Эти таблицы имеют общий столбец, stor_id, поэтому можно попытаться непосредственно выполнить их соединение.
Если теперь оператор SELECT * будет выполнен применительно к таблице stores, то обнаружится, что в состав результатов запроса включены все строки из таблицы stores, причем при наличии соответствующей строки в таблице discounts отображается относящаяся к этой строке информация о скидке. А во всех остальных случаях столбцы, взятые из таблицы discounts, заполняются NULL-значениями. Итак, если допустить, что таблица discounts всегда будет упоминаться в запросе в первую очередь, а таблица stores — во вторую, то, чтобы получить информацию обо всех скидках, нужно использовать конструкцию LEFT JOIN, а для ознакомления с информацию обо всех магазинах - конструкцию RIGHT JOIN.
Приведите пример соединения с использованием конструкции FULL JOIN.
Как и многие конструкции в языке SQL, конструкция FULL JOIN (применяемая также в форме FULL OUTER JOIN) по существу выполняет именно то действие, о котором говорит ее название, — эта конструкция согласует данные в таблицах, имена которых находятся по обе стороны от ключевого слова JOIN, и вводит в окончательные результаты все строки, независимо от того, с какой стороны соединения они определены.
Конструкции FULL JOIN относятся к числу тех языковых средств, которые вызывают восхищение во время их изучения, но в дальнейшем почти не применяются. Основное назначение этой конструкции состоит в том, что она позволяет увидеть полную связь между данными в таком виде, в котором не дается преимущество ни левой, ни правой стороне. Эта конструкция применяется, если есть необходимость ознакомиться с каждой строкой всех таблиц, вводящихся по обе стороны от ключевого слова JOIN, без каких-либо исключений. По-видимому, если одно и то же соединение может быть применено и в форме левого, и в форме правого соединения, то лучше всего использовать полное соединение, имеющее форму конструкции FULL JOIN. Эта конструкция не только дает возможность получить все согласующиеся строки с учетом того поля (полей), на котором основано соединение, но и те строки, которые имеются только в таблицах, находящихся на левой стороне, притом что столбцы, относящиеся к правой стороне заполняются NULL-значениями. Наконец, та же операция возвращает все строки, имеющиеся только в таблицах, заданных с правой стороны, а вместо значений полей таблиц, относящихся к левой стороне, подставляются NULL-значения.
Вначале выполним соединение двух первых таблиц с использованием конструкции FULL JOIN:
SELECT a.Address, va.AddressID
FROM VendorAddress va
FULL JOIN Address a
ON va.AddressID = a.AddressID
Введем еще одну конструкцию JOIN:
SELECT a.Address, va.AddressID, v.VendorlD, v.VendorName FROM VendorAddress va FULL JOIN Address a
ON va.AddressID = a.AddressID FULL JOIN Vendors v
ON va.VendorlD = v.VendorlD
Теперь в нашем распоряжении имеется оператор, позволяющий получить из рассматриваемых таблиц всю имеющуюся в них информацию.
Приведите пример соединения с использованием конструкции CROSS JOIN.
Операторы с конструкциями CROSSJOINобладают действительно необычными особенностями. СоединенияCROSSJOINотличаются от соединений других типов тем, что в них отсутствуют операцииON, а также тем, что в них происходит соединение каждой строки таблиц, находящихся с одной стороны от ключевого словаJOIN, с каждой строкой таблиц, находящихся с другой стороны от ключевого словаJOIN. Короче говоря, в конечном итоге формируется декартово произведение всех строк, заданных по обе стороны от ключевого словаJOIN. Операторы с конструкциейCROSSJOINимеют такой же синтаксис, как и любые другие операторыJOIN, за исключением того, что в них используется ключевое словоCROSS(вместоINNER,OUTERилиFULL), а операцияONотсутствует. Ниже приведен краткий пример.
SELECT v.VendorName, a.Address
FROMVendorsv
CROSSJOINAddressa
Чаще всего формирование базы данных осуществляется с учетом того, что эта база войдет в состав более крупномасштабной системы, требующей существенной проверки. А при тестировании систем большого масштаба снова и снова возникает проблема, связанная с высокой трудоемкостью создания больших объемов данных, применяемых при испытаниях. Использование операции CROSSJOINоткрывает такую возможность, что могут быть созданы две или несколько таблиц с количеством строк испытательных данных, намного меньшим по сравнению с требуемым. После этого к таким промежуточным таблицам можно применить операторыCROSSJOINдля создания гораздо более крупных наборов испытательных данных.
Соединение таблицы со своей копией.
В ряде приложений возникает необходимость одновременной обработки данных какой-либо таблицы и одной или нескольких ее копий, создаваемых на время выполнения запроса.
Например, при создании списков студентов (таблица Студенты) возможен повторный ввод данных о каком-либо студенте с присвоением ему второго номера зачетной книжки. Для выявления таких ошибок можно соединить таблицу Студенты с ее временной копией, установив в WHERE фразе равенство значений всех одноименных столбцов этих таблиц кроме столбцов с номером зачетной книжки (для последних надо установить условие неравенства значений).
Временную копию таблицы можно сформировать, указав имя псевдонима за именем таблицы во фразе FROM. Так, с помощью фразы
FROM Блюда X, Блюда Y, Блюда Z
будут сформированы три копии таблицы Блюда с именами X, Y и Z.
В качестве примера соединения таблицы с ней самой сформируем запрос на вывод таких пар блюд таблицы Блюда, в которых совпадает основа, а название первого блюда пары меньше (по алфавиту), чем номер второго блюда пары. Для этого можно создать запрос с одной копией таблицы Блюда (Копия):
SELECT Блюдо, Копия.Блюдо, Основа
FROM Блюда, Блюда Копия
WHERE Основа = Копия.Основа
AND Блюдо < Копия.Блюдо;
или двумя ее копиями (Первая и Вторая):
SELECT Первая.Блюдо, Вторая.Блюдо, Основа
FROM Блюда Первая, Блюда Вторая
WHERE Первая.Основа = Вторая.Основа
AND Первая.Блюдо < Вторая.Блюдо;
Получим результат вида
|
Первая.Блюдо |
Вторая.Блюдо |
Основа |
|
Морковь с рисом |
Помидоры с луком |
Овощи |
|
Морковь с рисом |
Салат летний |
Овощи |
|
Морковь с рисом |
Салат витаминный |
Овощи |
|
Помидоры с луком |
Салат витаминный |
Овощи |
|
Помидоры с луком |
Салат летний |
Овощи |
|
Салат витаминный |
Салат летний |
Овощи |
|
Бастурма |
Бефстроганов |
Мясо |
|
Бастурма |
Мясо с гарниром |
Мясо |
|
Бефстроганов |
Мясо с гарниром |
Мясо |
Дайте определение представлению. Какие данные использует представление?
Представление – виртуальный объект в базе данных (виртуальными их можно считать, лишь в определённом смысле).
Практика показывает, что представления используются, либо слишком часто, либо слишком редко, т.е. очень редко встречаются базы, где бы использование представлений было бы оправданно. Однако представления позволяют достичь следующих целей:
Сократить кажущуюся сложность базы данных для конечных пользователей.
Обеспечить доступ пользователей ко всем необходимым данным и вместе с тем запретить доступ к некоторым столбцам, к которым доступ обычных пользователей нежелателен.
Предусмотреть в базе дополнительные средства индексации, повышающие производительность всей базы.
В действительности же представление – это не что иное, как хранимый запрос. Удобство состоит в том, что они обеспечивают выборку данных из одной или нескольких таблиц, так же обеспечивают согласование данных.
Представление является объектом базы данных, но, в отличие от таблиц, не является физическим хранилищем данных. Его можно представить как хранимое выражение выборки с минимальным набором свойств. Удаление всего представления как объекта никак не повлияет на данные, на основе которых оно построено. В то же время удаление всех записей в представлении может удалить эти записи в исходных таблицах.
Приведите пример простого представления.
Синтаксическая структура оператора – комбинация рассматриваемых ранее операторов CREATE , а так же оператора SELECT.
CREATE VIEW <название_представления>
AS
SELECT <описание_оператора…>
Пример простейшего представления, которое будет выводить все имена, фамилия и отчества всех студентов:
CREATE VIEW FIOStud_vw
AS
SELECT StudentFirstName, StudentLastName, StudentPatronymic
FROM Students
GO
Теперь проверим полученный результат, путём выборки всей информации из созданного представления:
USE Universitet
SELECT *
FROM FIOStud_vw
GO
Результат будет следующим:
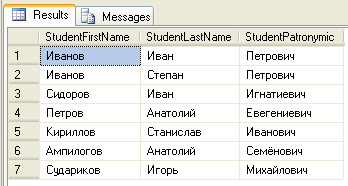
Данный запрос был аналогичен запросу
USE Universitet
SELECT StudentFirstName, StudentLastName, StudentPatronymic
FROM Students
GO
В запросах участвующих в создании представлений допускается использование любых конструкций, таких как WHERE и др.
Приведем еще один пример для создания представления:
CREATE VIEW [<Владелец>.]<Имя представления>
[(<Имя столбца> [, <Имя столбца>]...)]
[WITH ENCRYPTION]
AS <Команда> [WITH CHECK OPTION]
Как можно использовать представления для корректировки данных?
Изменения, которые производятся с помощью представлений, могут воздействовать только на один объект. Пусть представление создано на основе двух таблиц, order_ и customer.
CREATE VIEW cust_Order
AS
SELECT customer.name_customer, customer.address, customer.tel, order_.key_model
FROM customer, order_
WHERE customer.key_customer = order_.key_customer
Если в запросе, который используется для создания представления, присутствуют выражения, встроенные функции или функции агрегирования, то изменить данные вы не сможете. Что вполне логично, так как нет столбцов в исходных таблицах, связанных со столбцами в представлении. В следующем примере используется функция агрегирования:
CREATE VIEW total_sum
AS
SELECT customer.name_customer, customer.address,
customer.tel. Sum (account.summa)
AS SumOfAc
FROM customer, account
WHERE customer.key_customer = account.key_customer
GROUP BY customer.name_customer, customer.address, customer.tel;
Данный запрос выбирает имена клиентов вместе с их адресами и телефонами, а также суммы по всем платежным документам.
В полученном представлении мы можем менять значения во всех столбцах, кроме последнего, который является итогом работы функции агрегирования.
Запись не может быть добавлена в представление, если столбцы, которые не входят в представление, не принимают значение NULL или не имеют значения по умолчанию.
Если создать представление с помощью выражения SELECT *, а затем поменять структуру исходных таблиц, новые столбцы не появятся в представлении. То есть (на более низком уровне) звездочка интерпретируется как названия столбцов только во время создания представления. Единственный выход – удалить представление и создать его заново. Для представлений нет команд изменения структуры. Если вы вынуждены поменять список полей и выражений, отображаемых с помощью представления, то удалите его и создайте заново.
Если представление ссылается на таблицы, которые были удалены, то при запуске представления вы получите сообщение об ошибке. Если исходные таблицы или представления были удалены, то настоятельный совет разработчиков Microsoft SQL Server таков: вначале удалите представление, а затем создайте его заново.
Чтобы не путать представления с таблицами, рекомендуется давать им имена, которые сразу отличали бы их от таблиц.
Перечислите последовательность действий для создания и редактирования представлений в программе Management Studio.
Некоторые разработчики не стремятся глубоко разобраться в том, чем они занимаются, поэтому охотно используют возможности программы Management Studio. Мы называем таких разработчиков говнарями. C помощью этой программы задачи составления базы значительно упрощается и фактически не требуется знание того, как действуют запросы.
Ч тобы
посмотреть запросы необходимо открыть
подузелUniversitet
узла Databases
и щёлкнуть правой кнопкой мыши на
обозначении Views.
Появиться следующее окно:
тобы
посмотреть запросы необходимо открыть
подузелUniversitet
узла Databases
и щёлкнуть правой кнопкой мыши на
обозначении Views.
Появиться следующее окно:
Т еперь
выберите командуNew
View,
чтобы открыть новое диалоговое окно.
Это диалоговое окно позволяет выбирать
таблицы, которые должны быть включены
в представление. Выберем несколько
таблиц удерживая клавишу CTRL.
еперь
выберите командуNew
View,
чтобы открыть новое диалоговое окно.
Это диалоговое окно позволяет выбирать
таблицы, которые должны быть включены
в представление. Выберем несколько
таблиц удерживая клавишу CTRL.
Затем щёлкните на кнопке Add, чтобы СУБД добавила несколько таблиц к представлению. И понаблюдайте за тем, как открывается окно редактора.
В окне редактора можно увидеть несколько независимых окон:
Окно Diagrams:

Окно Criteria(Grid):

И окно SQL:
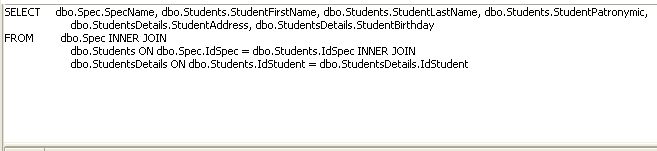
Дайте определение хранимой процедуре. Что понимается под системными хранимыми процедурами?
Хранимая процедура — это специальный вид процедуры, который выполняется сервером баз данных. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Они могут вызывать друг друга, читать и изменять данные в таблицах, и их можно вызвать из клиентского приложения, работающего с базой данных.
Хранимые процедуры обычно используются при выполнении часто встречающихся задач (например, сведение бухгалтерского баланса). Они могут иметь аргументы, возвращать значения, коды ошибок и иногда наборы строк и колонок (такой набор данных иногда называется термином dataset). Однако последний тип процедур поддерживается не всеми СУБД.
Хранимые процедуры –это откомпилированныеSQL-инструкции, которые хранятся на сервере. При их использовании следует принимать во внимание следующее:
В связи с тем, что процедурный кэш работает по принципу хранения либо самых ранних использовавшихся данных (LRU—least recently used) либо недавно использовавшихся данных (MRU—most recently used), хранимая процедура остается в кэше до тех пор, пока не будет вытеснена оттуда другой часто исполняемой процедурой.
Проверка синтаксических ошибок и компиляция происходят при первом запуске хранимой процедуры на исполнение.
Процедуры могут выполняться любыми приложениями, что облегчает контроль над целостностью данных.
В отличие от триггеров процедуры запускаются приложением, а не SQLServer.
Процедуры могут либо выбирать данные, либо модифицировать их, но не то и другое одновременно.
Хранимые процедуры могут использоваться как механизм безопасности. Пользователю предоставляется право запускать хранимую процедуру, но не право непосредственного доступа к данным таблицы. Обратите внимание на следующие преимущества хранимых процедур:
Изменения в бизнес-правила достаточно внести только на уровне хранимой процедуры.
Все пользовательские приложения будут использовать одну и ту же логику!
Процедуры могут принимать и возвращать параметры.
Процедуры создаются как для постоянного, так и для временного использования (в течение текущего сеанса работы с SQLServer).
В процессе работы многие системные хранимые процедурынеобходимы как быстрое средство манипулирования информацией из системных таблиц. Многие задачи администрированияSQLServerвыполняются с помощью этих заранее определенных системных процедур, но помните, что вы тоже можете создать системные хранимые процедуры. По умолчанию системная хранимая процедура начинается с префиксаsp_. Для создания своих собственных системных хранимых процедур используйте тот же префикс. Системные процедуры могут исполняться в любой базе данных.
Что понимается под расширенными хранимыми процедурами? Приведите пример создания хранимой процедуры.
Для прямого доступа к системным ресурсам Windows NT в SQL Server встроены специальные средства – расширенные хранимые процедуры (extended stored procedure). Они позволяют обращаться к функциям, написанным в виде динамических библиотек Windows – DLL, что существенно повышает скорость их выполнения. Расширенные хранимые процедуры отличаются тем, что их имя начинается с символов хр_. Эти процедуры используются для поддержки интегрированной модели безопасности и системы оповещения SQL Mail. Кроме того, есть пользовательские расширенные процедуры и процедуры общего назначения. Пользовательские расширенные хранимые процедуры могут быть написаны программистом с помощью Microsoft Open Data Services (MODS). MODS – это специальный 32-разрядный интерфейс программирования для разработки приложений доступа клиентов SQL Server к другим источникам данных. По сути, MODS представляет собой дополнительный уровень между хранимой процедурой и Win32 API.
Хранимые процедуры создаются с помощью команды CREATE PROCEDURE. Процедуры можно создавать только в текущей базе данных (за исключением временных процедур, которые относятся к базе данных tempdb. Команда CREATE PROCEDURE не может смешиваться с другими SQL-командами в одном пакете.
Локальные и глобальные временные хранимые процедуры похожи на временные таблицы. Для того чтобы процедура стала временной, необходимо добавить знак # перед ее именем (локальная процедура) или два знака # (глобальная процедура). Полное имя, включая знаки # и ##, не может превышать 20 символов.
Хранимая процедура представляет собой сценарий, который храниться в базе данных и может принимать и передавать параметры, которые фактически не могут быть использованы в обычных сценариях. Основным языком программирования для СУБД SQL Server 2005 продолжает оставаться язык T-SQL, который не поддерживает таких ходов управления программой, как языки C++, Object Pascal, Java или Visual Basic. Однако он является непревзойденным, когда идёт речь об определении, обработки, доступа к данным. Так же есть возможность использования инфраструктуры .NET. Простейший синтаксис операторов создания хранимых процедур:
CREATE PROCEDURE <название_процедуры>
AS
<Код_процедуры, например (SELECT <описание_оператора…>)>
Проще всего описать синтаксис хранимой процедуры на примере, например возвращающий все поля таблицы базы данных.
Пример:
USE Universitet
GO
CREATE PROCEDURE spStudents
AS
SELECT * FROM Students
В этом сценарии заслуживает особого внимания то, что оператору CREATE предшествует оператор GO. Дело в том, что большинство операторов CREATE не допускает включение других операторов, кроме оператора создания хранимой процедуры.
П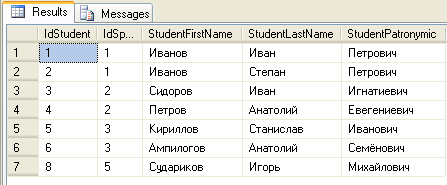 осле
создания хранимой процедуры вызовем
её на исполнение, чтобы ознакомиться с
полученными результатами:
осле
создания хранимой процедуры вызовем
её на исполнение, чтобы ознакомиться с
полученными результатами:
EXEC spStudents
Дайте определение ограничению. Какие типы ограничений вы знаете?
Ограничение — это, прежде всего, формулировка требований к данным. Ограничения устанавливаются на уровне столбца или таблицы и гарантируют соответствие данных определенным правилам обеспечения целостности данных.
<s>В настоящей лабораторной работе приведен общий обзор следующих трех типов ограничений.</s>
Ограничения сущностей.
Ограничения сущности полностью относятся к отдельным строкам. В действительности в ограничении этого типа не рассматривается весь столбец как таковой, интерес представляет только какая-то конкретная строка. Самым наглядным ограничением этого типа является такое ограничение, согласно которому в каждой строка таблицы должно присутствовать уникальное значение одного столбца или комбинации столбцов.
Ограничения домена.
распространяются на один или несколько столбцов. Под этими ограничениями подразумеваются способы обеспечения того, чтобы какой-то конкретный столбец или ряд столбцов соответствовал определенным критериям. Эти ограничения применяются при вставке или обновлении строки без учета того, что в таблице имеются какие-либо иные другие строки; интерес представляют только данные рассматриваемого столбца.
Ограничения ссылочной целостности.
Ограничения ссылочной целостности создаются в том случае, если значения в одном столбце должны согласовываться со значениями в другом столбце (либо в той же таблице, либо, гораздо чаще, в другой таблице).
Кроме того, более подробно будут рассматриваться конкретные методы реализации каждого из ограничений этих типов, включая перечисленные ниже.
Ограничения первичного ключа (PRIMARYKEY).
Ограничения внешнего ключа (FOREIGNKEY).
Ограничения уникальности (UNIQUE, именуемые также ограничениями альтернативного ключа).
Ограничения проверки (CHECK).
Ограничения заданных по умолчанию значений (DEFAULT).
Что такое ограничение домена?
Ограничения домена распространяются на один или несколько столбцов. Под этими ограничениями подразумеваются способы обеспечения того, чтобы какой-то конкретный столбец или ряд столбцов соответствовал определенным критериям. Эти ограничения применяются при вставке или обновлении строки без учета того, что в таблице имеются какие-либо иные другие строки; интерес представляют только данные рассматриваемого столбца.
Дайте определение ограничению сущности. Какие правила именования ограничений вы знаете?
Ограничения сущности полностью относятся к отдельным строкам. В действительности в ограничении этого типа не рассматривается весь столбец как таковой, интерес представляет только какая-то конкретная строка. Самым наглядным ограничением этого типа является такое ограничение, согласно которому в каждой строка таблицы должно присутствовать уникальное значение одного столбца или комбинации столбцов.
На первый взгляд может показаться, что такое определение ограничения сущности, согласно которому, допустим, какой-то столбец должен содержать уникальные значения, полностью совпадает с определением ограничения домена. Но фактически дело обстоит иначе. В формулировке ограничения сущности ничего не сказано о том, что данные столбца должны соответствовать какому-то определенному формату или что значения в столбце должны быть больше или меньше какой-то величины. Единственное, что сказано, относится только к определенной строке и предъявляемое к ней требование состоит лишь в том, чтобы содержащееся в ней значение больше не встречалось в какой-либо другой строке в той же таблице.
Ограничения такого рода будут рассматриваться в контексте описания ограничений PRIMARYKEYиUNIQUE.
Все возможные виды ограничений должны быть обозначены именем, но разработчик не обязан сам задавать такое имя. Иными словами, всегда можно воспользоваться тем, что СУБД SQL Server предоставляет имя для того ограничения, для которого имя не было предусмотрено разработчиком. Тем не менее следует избегать соблазна воспользоваться такой возможностью, поскольку вскоре обнаруживается, что имена, создаваемые СУБД SQL Server, не вполне приемлемы.
Но основной недостаток имен, сформированных системой, состоит не в их сложности, а в том, что эти имена не раскрывают сути применяемых ограничений; например при использовании ограничения CHECK системой формируется имя, напоминающее нечто вроде СК__Customers__22АА2996.
По этому имени можно определить, что оно относится к ограничению CHECK, однако невозможно что-либо узнать, в чем состоит характер соответствующей проверки CHECK.
Учитывая то, что на одной таблице может быть задано несколько ограничений CHECK, можно понять, что при формировании имен ограничений системой все ограничения, заданные на одной и той же таблице, приобретают примерно такие имена:
СК__Customers__22AA2996
СК__Customers__258 69 641
СК__Customers__2 67ABA7A
Вполне очевидно, что если возникнет необходимость отредактировать одно из этих ограничений, будет очень сложно выяснить, к чему относится каждое из них.
<s>В предыдущих лабораторных работах уже говорилось</s> Предыдущий оратор уже говорил о том, какими правилами следует руководствоваться при выборе имен различных объектов, но отметим еще раз, что в действительности не так важен выбор самих имен, как соблюдение перечисленных ниже требований.
Обеспечение единообразия.
Применение имен, понятных для всех.
Применение наиболее краткой формулировки для имен и вместе с тем соблюдение двух указанных правил.
Приведите пример ограничения primary key. Приведите пример ограничения foreign key.
Ограничения primary key
Первичные ключи представляют собой уникальные идентификаторы для каждой строки. Столбец первичного ключа должен содержать уникальные значения (и поэтому в этом столбце не допускается наличие NULL-значения). Первичные ключи очень важны для нормальной эксплуатации реляционной базы данных, поэтому являются наиболее фундаментальными объектами базы данных по сравнению со всеми прочими ключами и ограничениями.
Таблица может иметь не больше одного первичного ключа. Кроме того, как уже было сказано выше, в базе данных редко встречаются такие таблицы, для которых не требуется первичный ключ.
Следует подчеркнуть высказанную выше мысль, отметив, что таблицы без первичного ключа встречаются не просто редко, а очень редко. Наличие в базе данных таблицы, не имеющей первичного ключа, полностью противоречит представлениям о реляционном характере данных, хранимых в базе данных, поскольку из этого следует, что возможность установить связь с какой-либо конкретной строкой этой таблицы отсутствует. Данные, представленные в таблице, не имеющей первичного ключа, не имеют также каких-либо отличительных признаков.
Безусловно, нередко встречаются ситуации, в которых многочисленные строки таблицы логически идентичны друг другу, но это не означает, что возможность создания первичного ключа для такой таблицы отсутствует. В подобных обстоятельствах может быть предусмотрено искусственное создание ключа того или иного типа.
Первичный ключ гарантирует уникальность сочетания значений столбцов, объявленных как принадлежащие к этому первичному ключу. Сами эти уникальные значения служат в качестве идентификаторов для каждой строки в таблице. Для создания первичного ключа по существу применяются два способа. Первичный ключ может быть либо создан с помощью команды CREATE TABLE во время создания таблицы, либо введен в действие впоследствии с помощью команды ALTER TABLE.
CREATE TABLE Sess
(
ekzID int IDENTITY NOT NULL
PRIMARY KEY,
studentName varchar (30) NOT NOLL,
prepName varchar(30) NOT NULL,
otmetko int(2) NOT NULL,
)
Внешние ключи не только обеспечивают целостность данных, но и создают связи между таблицами. После задания внешнего ключа на таблице устанавливается зависимость между таблицей, для которой определяется внешний ключ (так называемой ссылающейся таблицей), и таблицей, на которую ссылается внешний ключ (так называемой таблицей, упомянутой в ссылке). После задания на ссылающейся таблице внешнего ключа любая строка, вставляемая в эту таблицу, должна соответствовать одному из следующих двух условий: иметь согласующуюся с ней строку в столбце (столбцах), которому соответствует внешний ключ таблицы, указанной в ссылке, или иметь значение столбца (столбцов) внешнего ключа, равное NULL.
USE Accounting CREATE TABLE Orders
(
OrderlD int IDENTITY NOT NULL
PRIMARY KEY,
CustomerNo int NOT NULL
FOREIGN KEY REFERENCES Customers(CustomerNo),
OrderDate smalldatetime NOT NULL,
EmployeelD int NOT NULL
)
В отличие от первичных ключей, количество внешних ключей, заданных на таблице, не должно ограничиваться только одним. Для любой таблицы может быть задано от нуля до 253 внешних ключей. Единственным условием является то, что каждый конкретный столбец может упоминаться только в одном внешнем ключе. Тем не менее в каждом отдельном внешнем ключе может быть задано несколько столбцов. Кроме того, предусмотрена также возможность использовать какой-то конкретный столбец в качестве назначения ссылок, заданных во внешних ключах многих таблиц.
Приведите пример таблицы, ссылающейся на саму себя. Приведите пример ограничения unique. Приведите пример ограничения check. Приведите пример ограничения default.
Иногда возникает необходимость задать в ограничении столбец, находящийся не в другой таблице, а непосредственно в той же таблице, в которой создается ссылка на исходное ограничение. Это означает, что одна и та же таблица применительно к некоторому ограничению может играть роль и ссылающейся таблицы, и таблицы, указанной в ссылке. Разумеется, подобные ситуации встречаются не очень часто, но достаточно регулярно.
Итак, в данном случае рассматривается таблица, в которой имеется ссылка на столбец, представляющий собой столбец идентификации, поэтому необходимо вначале ввести в таблицу хотя бы одну первичную строку и только после этого задавать ограничение:
Теперь, после ввода первичной строки, можно приступить к заданию внешнего ключа. В этом варианте создания таблицы, ссылающейся на саму себя, в котором используется оператор ALTER, осуществляемые действия аналогичны тем, которые выполняются при уточнении любого другого определения внешнего ключа. Проверим действие следующего оператора на практике:
ALTER TABLE Employees
ADD CONSTRAINT FK_EmployeeHasManager
FOREIGN KEY (ManagerEmpID) REFERENCES Employees(EmpioyeelD)
В данном операторе есть только одно отличие от оператора CREATE. Но есть и еще один нюанс, состоящий в том, что в данном определении допускается не использовать ключевое слово FOREIGN KEY (но этого не следует делать) и оставлять только конструкцию REFERENCES. К этому времени таблица Employees уже определена, но если бы речь шла о ее создании с самого начала, то на данном этапе можно было бы применить следующий сценарий (особого внимания заслуживает определение внешнего ключа на столбце ManagerEmpID):
CREATE TABLE Employees
(
EmpioyeelD
PRIMARY KEY, FirstName Middlelnitial LastName Title SSN
Salary PriorSalary
irtt
varchar (25) char (1) varchar (25) varchar (25) varchar (11) money money
IDENTITY
LastRaise AS Salary - PriorSalary, HireDate smalldatetime TerminationDate smalldatetime ManagerEmpID int
REFERENCES Employees(EmpioyeelD), Department varchar (25) NOT NULL
)
Следует отметить, что при попытке уничтожить таблицу Employees в данный момент (чтобы выполнить оператор, рассматриваемый во втором примере) было бы получено сообщение об ошибке.
Удобным свойством ограничений CHECK является то, что эти ограничения не обязательно должны применяться только к какому-то конкретному столбцу. Безусловно, указанные ограничения могут относиться лишь к некоторому столбцу, но также допускается их распространение по существу на всю таблицу, в том смысле, что с их помощью может осуществляться проверка значений в одном столбце на основании значений другого столбца (при условии, что все эти столбцы принадлежат к одной и той же таблице, а значения берутся из одной и той же обновляемой или вставляемой строки). С помощью ограничений CHECK может также осуществляться проверка того, соответствует ли некоторое сочетание значений столбцов заданному критерию.
ALTER TABLE Customers
ADD CONSTRAINT CN_CustomerDateInSystem
CHECK
(DatelnSystem <= GETDATE ())
Теперь попытаемся выполнить вставку строки со значением, нарушающим ограничение CHECK; эта попытка должна привести к возникновению ошибки:
INSERT INTO Customers
(CustomerName, Addressl, Address2, City, State, Zip, Contact, Phone, FedlDNo, DatelnSystem) VALUES
CCustomerl', 'Addressl', 'Add2', 'MyCity', 'NY', '55555', 'No Contact', '553-1212', '930984954', '12-31-2049') Msg 547, Level 16, State 0, Line 1
The INSERT statement conflicted with the CHECK constraint
"CN_CustomerDateInSystem". The conflict occurred in database "Accounting", table "dbo.Customers", column 'DatelnSystem'. The statement has been terminated.
Если после этого будет внесено такое исправление, чтобы данные, вводимые в столбец DatelnSystem, соответствовали критерию, заданному в ограничении CHECK (относились к дате, совпадающей с нынешней или предшествующей ей), то попытка выполнить оператор INSERT завершится успешно.
Ограничения DEFAULT принадлежат к одному из двух различных типов инструментальных средств обеспечения целостности данных, которые можно рассматривать как относящиеся к заданным по умолчанию значениям. К сожалению, в связи с наличием двух таких разных средств почти с одинаковыми названиями возникает значительная путаница.
Ограничения DEFAULT, как и все прочие типы ограничений, предусмотрены в синтаксической структуре определения таблицы. Ограничения DEFAULT указывают, какие действия должны быть выполнены, если происходит вставка новой строки, не содержащей данных, соответствующих тому столбцу, к которому относится это ограничение.
CREATE TABLE Shippers
(
ShipperlD int IDENTITY
PRIMARY KEY, ShipperName varchar(30)
DatelnSystem smalldatetime DEFAULT GETDATE ()
)
Дайте определение пакету данных. Приведите примеры команд, которые можно использовать в пакете и которые нельзя.
Пакет – это набор SQL-команд, запускаемых как единое целое. Пакет компилируется только один раз. Пакет заканчивается символом конца пакета (команда GO).
Пакеты могут запускаться интерактивно или из файла. Например, вы можете запускать пакеты диалоговыми средствами SQL Enterprise Manager или ISQL/w или с помощью файлов, которые содержат скрипт (script). Такой файл может включать более одного пакета, если каждый пакет заканчивается командой-разделителем GO. Пакет разбирается, оптимизируется, компилируется и выполняется целиком. Если в пакете произойдет ошибка, ни одна из его команд не выполнится.
При создании пакетов необходимо учитывать, что некоторые команды могут объединяться в одном пакете, тогда как другие – нет. Например, можно объединять в одном пакете следующие команды:
CREATE DATABASE
CREATE TABLE
CREATE INDEX
Следующие команды объединять нельзя:
CREATE PROCEDURE
CREATE RULE
CREATE DEFAULT
CREATE TRIGGER
CREATE VIEW
Можно создать такой пакет:
CREATE DATABASE...
CREATE TABLE...
GO
Следующий пакет создать нельзя:
CREATE DATABASE...
CREATE TABLE...
CREATE RULE...
CREATE RULE...
GO
Вместо него следует создать несколько пакетов. Это будет выглядеть следующим образом:
CREATE DATABASE...
CREATE TABLE...
GO
CREATE RULE...
GO
CREATE RULE...
GO
Поясните синтаксис блокировки данных. Какие виды блокировок данных вам известны? Приведите примеры.
Когда несколько пользователей обращаются к базе данных одновременно, Microsoft SQL Server использует блокировку, для того чтобы гарантировать не перекрывание. Блокировка запрещает пользователям читать данные, которые изменяются другим пользователем, и не позволяет пользователям делать более одного изменения записи за один раз.
Блокируются страницы, которые читаются или изменяются во время транзакции, что позволяет избежать проблем при большом количестве транзакций. Уменьшение объема блокировок увеличивает скорость доступа и производительность. Хотя существует много способов уменьшить время и количество блокировок, лучший метод – завершить транзакцию, как только она выполнила все операции, которые планировались.
Microsoft SQL Server может применять несколько типов блокировки. В общем случае операции чтения довольствуются мягкой блокировкой, а операции записи требуют монопольной блокировки. Приведенная ниже таблица 1 описывает три типа блокировок, которые использует Microsoft SQL Server для поддержки целостности данных.
Таблица 1. Типы блокировок
|
Тип |
Описание |
|
Разделяемая |
Microsoft SQL Server использует разделяемую блокировку для операций, которые не изменяют и не модифицируют данные, например таких, как выборка с помощью команды SELECT |
|
Модификации |
Microsoft SQL Server использует блокировку модификации, когда он пытается модифицировать страницу, и позже повышает блокировку модификации на монопольную блокировку страницы, перед тем как действительно совершить изменения |
|
Монопольная |
Microsoft SQL Server использует монопольную блокировку для модификации данных с помощью таких операций, как UPDATE, INSERT или DELETE |
Что такое уровень изоляции транзакции?
Уровень изоляции транзакций устанавливается для всего SQL Server. Чтобы задать его, используйте команду SET TRANSACTION ISOLATION LEVEL. Когда вы устанавливаете уровень изоляции транзакции, вы указываете блокировку по умолчанию для всех команд SELECT в сессии. Вы можете переустанавливать уровень для индивидуальных выборок с помощью опций команды SELECT. Чтобы выяснить, какой уровень изоляции использован, применяется команда DBCC USEROPTIONS. В таблице 3 указаны опции команды SET TRANSACTION ISOLATION LEVEL и их назначение.
Таблица 3. Опции команды SET TRANSACTION ISOLATION LEVEL
|
Опция |
Описание |
|
READ COMMITTED |
SQL Server будет использовать разделяемую блокировку во время чтения. На этом уровне вы не можете применять «грязное чтение» |
|
READ UNCOMMITTED |
SQL Server не использует разделяемую блокировку и не поощряет монопольную блокировку. Вы можете экспериментировать с «грязным чтением» |
|
REPEATABLE, READ |
Указывает, что «грязное чтение», неповторяемые SERIALIZABLE считывания и значения-призраки не могут произойти |
После системных сбоев Microsoft SQL Server использует журнал транзакций для восстановления базы данных в исходном состоянии путем отказа от всех незавершенных транзакций. Помимо этого, SQL Server использует журнал, чтобы удостовериться, что все изменения, связанные с завершенными транзакциями, отражены в базе данных
Если транзакция должна быть прервана до своего завершения – или по причине сбоев, или из-за действий пользователя, – то все её команды должны быть отменены. Транзакции могут быть прерваны с помощью команды ROLLBACK TRANSACTION. Эта команда должна быть выдана до команды COMMIT TRANSACTION. Можно «откатить» всю транзакцию или её часть. Естественно, никто не может «откатить» транзакцию после её завершения.
Приведите пример команды управления циклом.
declare @tmp1 int;
declare @tmp2 int; set @tmp2 = 45;
declare @max int;
declare @iff int;
use Sess;
select @tmp1 = idGroup from stud where idGroup = 3;
select @max = MAX(idStud) from stud
if @tmp1 = 99
begin
print 'Эта строка не будет показана!'
end
else
begin
print 'А вот это уже будет показано!)))';
//отсюда цикл с предусловием:
while @tmp2 <= @max
begin
--select @iff = idStud from stud where idStud = @tmp2
--if @iff <> null
--begin
select stud.idStud , stud.nameStud, stud.Adres from stud where idStud = @tmp2
--end
set @tmp2 = @tmp2 + 1
end
//а тут он закончился. Всё понятненько?
end
Какая команда позволяет выходить из процедуры принудительно?
|
RETURN |
Независимый выход из процедуры |
Защита данных. Управление доступом к данным.
Стабильная система управления пользователями – обязательное условие безопасности данных, хранящихся в любой реляционной СУБД. В языке SQL не существует единственной стандартной команды, предназначенной для создания пользователей базы данных – каждая реализация делает это по-своему. В одних реализациях эти специальные команды имеют определенное сходство, в то время как в других их синтаксис имеет существенные отличия. Однако независимо от конкретной реализации все основные принципы одинаковы.
В системе SQL-сервер организована двухуровневая настройка ограничения доступа к данным. На первом уровне необходимо создать так называемую учетную запись пользователя (login), что позволяет ему подключиться к самому серверу, но не дает автоматического доступа к базам данных. На втором уровне для каждой базы данных SQL-сервера на основании учетной записи необходимо создать запись пользователя. На основе прав, выданных пользователю как пользователю базы данных (user), его регистрационное имя (login) получает доступ к соответствующей базе данных. В разных базах данных login одного и того же пользователя может иметь одинаковые или разные имена user с разными правами доступа. Иначе говоря, с помощью учетной записи пользователя осуществляется подключение к SQL-серверу, после чего определяются его уровни доступа для каждой базы данных в отдельности.
В системе SQL-сервер существуют дополнительные объекты – роли, которые определяют уровень доступа к объектам SQL-сервера. Они разделены на две группы: назначаемые для учетных записей пользователя сервера и используемые для ограничения доступа к объектам базы данных.
Итак, на уровне сервера система безопасности оперирует следующими понятиями:
аутентификация;
учетная запись;
встроенные роли сервера.
На уровне базы данных применяются следующие понятия;
пользователь базы данных;
фиксированная роль базы данных;
пользовательская роль базы данных.