

Теория Информации - Методичка (1 семестр)
.pdf2. Как будет выглядеть содержимое пакета данных на 4-м шаге при выполнении LZ78–модификации алгоритма Лемпеля–Зива над последовательностью abaababbbbbbbabbbba?
а) ba; б) bb; в) ааb; г) ab.
3. Какой из указанных кодов не мог быть построен с помощью алгоритма Хаффмана для заданного источника?
а) {10, 01, 00, 110, 1111, 1110} |
в) {01, 10, 00, 011, 1110, 0111} |
б) {0, 12, 11, 10} |
г) {00, 01, 02, 10, 11, 12} |
4. При создании файлов какого из указанных форматов используется сжатие с потерями?
а) 7z; б) zip; в) png; г) jpg.
Вариант 3
1. Какая информация отбрасывается в случае кодирования
без потерь? |
|
а) избыточная информация |
в) повторяющаяся информация |
б) несущественная информация |
г) в таком случае кодирования |
|
потерь информации не происхо- |
|
дит |
2. Как будет выглядеть содержимое пакета данных на 4-м шаге при выполнении LZ77–модификации алгоритма Лемпеля–Зива над последовательностью abaababbbbbbbabbbba?
а) ba; б) bb; в) ааb; г) ab.
3. Дискретный источник выдает символы с вероятностями
р1=1/4; р2=1/4; р3=1/4, р4=1/8, р5=1/16, р6=1/16. Какой из указанных кодов не мог быть построен с помощью алгоритма Хаффмана для
этого источника? |
|
а) {10, 01, 00, 100, 1111, 0111} |
в) {10, 01, 11, 001, 0000, 0001} |
б) {10, 01, 00, 110, 1111, 1110} |
г) {00, 01, 02, 10, 11, 12} |
4. При создании файлов какого из указанных форматов используется сжатие с потерями?
а) rar; б) zip; в) png; г) mp3.
69
4. ВВЕДЕНИЕ В ТЕОРИЮ ПОМЕХОУСТОЙЧИВОГО КОДИРОВАНИЯ
В данной главе рассмотрены идея помехоустойчивого кодирования, возможности классификации помехоустойчивых кодов, представлены графическая интерпретация идеи помехоустойчивого кодирования, а также теоретические оценки параметров линейных блочных кодов.
Ключевые слова: помехоустойчивое кодирование; помехоустойчивые код, кодер и декодер; подбор помехоустойчивого кодека к каналу связи; желаемые свойства помехоустойчивых кодов; код трехкратного повторения; код проверки на четность; виды классификации кодов; блочные коды; сверточные коды; информационные и кодовые слова; кодовый алфавит; понятие кода как отображения; графическая интерпретация кода; понятие метрики и метрического пространства; расстояние Хемминга; основные параметры блочных кодов; радиус сферической упаковки кода; радиус покрытия кода; совершенный и квазисовершенный коды; граница Хемминга; оценка Варшамова–Гилберта; оценка Синглтона; оценка Грайсмера.
Вспомните, как Вы обычно диктуете собеседнику некоторую информацию, в которой легко ошибиться, например, номер телефона или номер машины: «Восемь, девятьсот семь, ….. Давай повторю, проверяй! Восемьдесят девять, ноль семь,…» или «Аня, Коля, четыреста пять, Олег. Аня, Коля, четыре, ноль, пять, Олег.». В таких ситуациях собеседники не задумываясь, применяют основной принцип помехоустойчивого кодирования. А именно, вносят в передаваемые данные, избыточность. «Как же так?» – удивится внимательный читатель. – «При кодировании источника мы старались избавиться от избыточности, а теперь возвращаем ее на место?» Действительно, в кодере источника мы старались минимизировать размер данных, а в кодере канала будем вносить избыточные данные. Но эта избыточность будет не случайной, а специальным образом организованной.
Помехоустойчивым называют кодирование, которое вносит в данные специальным образом организованную избыточность, что
70
вдальнейшем позволит обнаружить или исправить ошибки, внесенные в данные каналом связи.
Часто у слушателей лекций по помехоустойчивому кодированию возникает вопрос о том, что может быть стоит использовать надежные каналы связи, вместо того, чтобы встраивать в передаваемые данные помехоустойчивую защиту. К сожалению, ошибки действуют во всех каналах связи без исключения. Так, например, даже новый компакт-диск уже содержит ошибки, например, мельчайший мусор и пузырьки воздуха, застывшие в пластике, из которого изготовлен диск.
Используем далее уже привычные нам термины, связанные с кодированием. Так, кодом будем называть правило (алгоритм), по которому каждому конкретному сообщению ставится в соответствие строго определенная комбинация символов. Отдельная комбинация таких символов – кодовое слово. Процесс преобразования сообщения
вкомбинацию символов в соответствии с кодом называется кодированием, процесс восстановления сообщения из комбинации симво-
лов называется декодированием.
Существует большое количество различных помехоустойчивых кодов, различающихся вносимой в данные избыточностью, обнаруживающей и исправляющей способностью, сложностью алгоритмов кодирования и декодирования, требованиями к системным характеристикам аппаратуры их реализующих. Более того, в помехоустойчивом кодировании можно различать не только коды, но и их алгоритмы кодирования и декодирования. Так, для одного и того же кода может быть несколько алгоритмов кодирования и несколько алгоритмов декодирования. Причем специальные алгоритмы декодирования могут, например, в некоторых случаях увеличивать способности кода по исправлению ошибок.
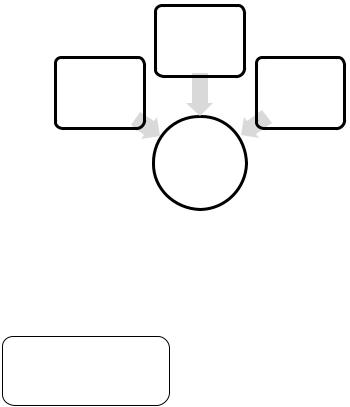
Вобщем случае подбор помехоустойчивого кода к конкретному каналу связи является сложной многокритериальной задачей. Диаграмма на рис. 4.1 показывает желаемые свойства кода, которые справедливы для всех ситуаций. Указанные требования к коду во
71
многом противоречат друг другу, а нахождение компромисса между ними – сложная задача.
|
Минимальная |
|
избыточность |
|
кода |
Исправление |
Простота |
максимально |
алгоритмов |
возможного |
кодирования и |
числа ошибок |
декодирования |
|
Желаемые |
|
свойства |
|
помехо- |
|
устойчивых |
|
кодов |
Рис. 4.1. Желаемые свойства помехоустойчивых кодов
Рассмотрим два примера помехоустойчивого кодирования. Пример 4.1. Код трехкратного повторения ставит в соответ-
ствие любому биту входных данных этот же бит, но повторенный трижды. Таким образом, входной бит «1» кодируется словом «111», а бит «0» – «000». Этот код легко исправляет любую одну ошибку, попавшую на кодовое слово. Так,
«010» декодируется в «0», «110» – в «1».
Происходит так называемое голосование. Мы сравниваем число нулевых и единичных бит и результатом декоди-
рования становится наиболее часто встречающийся бит. Если же в кодовом слове произойдет две ошибки, то код не сможет их исправить: «1» кодируем в «111», вносим две ошибки – «100», декодируем – «0». Очевидно, что для случая, когда необходимо исправлять большее число ошибок, можно увеличить число повторения бита в кодовом слове, так, код пятикратного повторения будет гарантированно исправлять все одиночные и двойные ошибки.
72
Пример 4.2. Код проверки на четность добавляет к строке входных данных фиксированного размера k один (k+1)-й бит таким образом, чтобы число единиц в кодовом слове было четным. Например, рассмотрим ситуацию k=2. Тогда все возможные последовательности из двух бит: «00», «01», «10», «11» кодируются в слова «000», «011», «101», «110», соответственно. Жирным выделен проверочный бит. Этот код не исправляет ошибки, а умеет только обнаруживать одиночные ошибки. Так, если декодер получил из канала связи слово «111», то по нечетному числу единичных бит он понимает, что слово искажено ошибкой, однако указать ее местоположение этот код не в состоянии. 
Мы рассмотрели примеры кодов с различными характеристиками. Так, код трехкратного повторения обладает наипростейшими алгоритмами кодирования и декодирования, исправляет одну ошибку, но вносит большую избыточность – размер входных данных увеличивается втрое. Код с проверкой на четность имеет минимальную избыточность (которая уменьшается с ростом k), простые алгоритмы кодирования и декодирования, однако возможности кода по коррекции и обнаружению ошибок минимальные. Очевидно, что для реальных ситуаций нужны коды с другими характеристиками.
4.1. Классификация кодов
Помехоустойчивые коды, как и любые другие объекты, можно классифицировать по различным признакам. Так, коды и кодеки, построенные на их основе, различают по структуре, функциональному назначению, эффективности, алгоритмам кодирования и декодирования. Рассмотрим несколько типов кодов.
По способу восприятия входной последовательности символов выделяют две большие группы кодов: блочные и сверточные. Кодер блочного (или, как его еще называют, блокового) кода можно представить как устройство без памяти, на вход которого поступают k входных символов, а на выходе кодера отображаются n (>k) символов. Термин «без памяти» указывает на тот факт, что при кодиро-
73
вании очередных k символов кодер не учитывает символы, которые он кодировал до этого, и которые он будет кодировать далее. Схематично работа блочного кодера представлена на рис. 4.2. Входная последовательность делится на блоки по k символов – информационные слова – и каждое из слов кодируется независимо от других в кодовые слова длиной n символов. Декодер отображает n входных символов кодового слова в k символов информационного слова.
|
k |
k |
k |
|
k |
k |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
n |
|
|
|
n |
|
|
|
|
n |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
n |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 4.2. Схематичное изображение работы блочного кодера
На вход сверточного кодера посимвольно поступает входная последовательность, а все результирующие символы зависят не только от очередного входного символа, но и от ряда предыдущих. Строго говоря, блочным кодам верно противопоставлять древовидные коды. Однако только одна из разновидностей древовидных кодов – сверточные – получила признание. И в современной научной литературе, посвященной разработке, исследованию и использованию древовидных кодов, говорится только о сверточных кодах, особенностью которых является линейность.
Пример 4.3. Рассмотрим пример работы сверточного кодера (рис. 4.3). Этот кодер представляет собой регистр сдвига, ячейки которого перед началом работы кодера заполнены нулями. В каждый момент времени на вход регистра поступает один информационный бит, при этом символы, заполняющие регистр, сдвигаются вправо на один бит и самый правый бит выталкивается из регистра, далее в работе этот «вытолкнутый бит» использоваться не будет. Результат кодирования записывается как последовательность значений, образующихся на выходах сумматоров. Сумматоры применяют
74
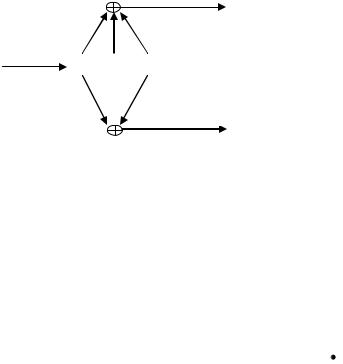
операцию сложения по модулю два для элементов регистра сдвига, с которыми у них есть связи. По рис. 4.3 легко понять, что на каждый входной бит рассматриваемый декодер выдает два выходных бита. Результатом кодирования входной последовательности 111000 будет 110110011100. Обратите внимание, что для трех входных единиц все выходные последовательности различны. Это связано с тем фактом, что кодер учитывает состояние регистра, т. е. «помнит» о символах, которые он обрабатывал ранее.
Входной бит |
|
|
|
Выходной бит |
ai |
|
|
|
|
|
|
|
b1i |
|
|
|
|
|
|
|
|
|
|
|
Выходной бит b2i
Рис. 4.3. Пример кодера сверточного кода
Шаги работы |
Входной бит |
Состояние |
Выходная |
кодера |
|
регистра |
последовательность |
|
|
|
|
0 |
– |
000 |
– |
1 |
1 |
100 |
11 |
|
|
|
|
2 |
1 |
110 |
01 |
|
|
|
|
3 |
1 |
111 |
10 |
|
|
|
|
4 |
0 |
011 |
01 |
|
|
|
|
5 |
0 |
001 |
11 |
|
|
|
|
6 |
0 |
000 |
00 |
|
|
|
|
Еще один подход в разделении кодов на группы зависит от мощности q алфавита, над которым задан код. Особо выделяют случай, когда код задан над алфавитом мощности 2, такие коды называют двоичными; другие коды называют недвоичными или q-ичными.
75

Взависимости от воздействия на ошибки в кодовом слове помехоустойчивые коды разделяют на коды, обнаруживающие ошибки и коды, исправляющие ошибки. Обнаруживающие ошибки коды позволяют только обнаружить искажение информации, полученной по каналу связи, и обычно представляют собой контрольные суммы. Так, в примере 4.1 представлен код, исправляющий ошибки,
ав примере 4.2 – обнаруживающий.
Взависимости от структуры кода выделяют линейные и нелинейные коды. В группе линейных кодов общим свойством является то, что результатом применения любых линейных комбинаций над кодовыми словами является кодовое слово. Использование линейных кодов способствует упрощению аппаратной и программной реализации данных кодов, повышает скорость выполнения необходимых операций. В нелинейном коде линейные операции над кодовыми словами могут дать в результате вектор, не являющийся кодовым словом.
Кроме рассмотренных, существуют и другие критерии, по которым классифицируют коды. Часть из них будет рассмотрена далее по ходу изложения основного материала, в котором основное внимание уделено двоичным линейным блочным кодам.
4.2. Графическая интерпретация блочных кодов
У помехоустойчивого кодирования есть естественная геометрическая интерпретация. С этой точки зрения теорию кодирования можно рассматривать как изучение точек в различных метрических пространствах.
Под метрическим пространством понимают множество M,
в котором определена функция расстояния d(x,y) между любой парой элементов, такая что
1. d(x,y)=0 x=y;
2.d(x,y)= d(y,x);
3.d(x,z)≤ d(x,y)+d(y,z).
76
Пусть X – конечное q-элементное множество X={a1, a2, … , aq}, а множество Xn содержит все возможные векторы длиной n из элементов X. Введем функцию расстояния на множестве Xn.
Расстоянием (метрикой) Хемминга d(x,y) между элементами x,y Xn называется число несовпадающих в x и y позиций.
Пример 4.4. Найдем расстояние Хемминга между заданными парами векторов: d(1011,1111)=1; d(123123, 122223)=2, d(100,1000) –
не определено, так как векторы 100 и 1000 имеют разную длину, а следовательно, принадлежат различным множествам Xn. 
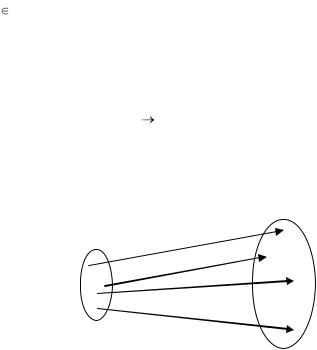
Кодом С называется отображение
F: Xk Xn, где k<n. (4.1)
Графически это отображение представлено на рис. 4.4. Отметим, что обычно в качестве X для построения кода выбирают множество с некоторой алгебраической структурой, например конечное поле или кольцо. А для построения кодера и декодера используют свойства этой структуры.
Xk |
Xn |
Рис. 4.4. Графическое представление кода
Каждому из qk символов из Xk ставится в соответствие один из символов из Xn. Получается, что каждый элемент из Xk связан с одним из элементов в Xn. qk элементов множества Xn имеют прообразы в Xk, а qn–qk элементов множества Xn прообразов в Xk не имеют. За счет этих векторов, не связанных с информационными словами, и происходит исправление ошибок.
77

Пример 4.5. Пусть на вход кодера поступило информационное слово i Xk. Кодер выдает кодовое слово c=F(i), c Xn. В процессе передачи некоторые символы слова с могут быть искажены. Мы хотим, чтобы, несмотря на ошибки в слове, декодер выдал нам слово i, а не некоторое другое i . Если канал связи вносит не более t ошибок в кодовое слово, то для однозначного восстановления необходимо и достаточно, чтобы для расстояния между словами F(i), F(i ) выполнялось неравенство:
d(F(i), F(i )) 2t+1. 
Минимальное значение d(F(i), F(i )) между всеми парами кодовых слов F(i), F(i ), таких, что F(i) F(i ) называется минимальным расстоянием кода, далее будем обозначать его dmin.
Таким образом, геометрически задачу построения хорошего кода можно интерпретировать следующим образом. В метрическом пространстве Xn нужно упаковать (расположить) как можно больше шаров радиусом t. Иначе можно сказать так: в пространстве Xn требуется найти как можно больше точек, находящихся на расстоянии 2t+1 или большем от любой другой точки. После того как шары выбраны, нужно найти целое число k ≤ logqN, где N – число найденных шаров в пространстве, и произвольно сопоставить слова длины k со словами длины n, являющимися центрами этих шаров.
Введем еще несколько определений.
Рассмотрим некоторый код С. Представьте себе маленькие сферы с центрами во всех кодовых словах; пусть все эти сферы имеют одинаковый целочисленный радиус. Пусть далее радиус сфер увеличивается (оставаясь целочисленным) до тех пор, пока дальнейшее его увеличение не станет невозможным без пересечения сфер. Значение этого радиуса равно числу ошибок, гарантированно исправляемых кодом С. Этот радиус называется радиусом сферической упаковки кода. Пусть радиус сфер увеличивается далее, пока все точки пространства не окажутся внутри хотя бы одной сферы. Такой радиус называется радиусом покрытия кода.
78