

Теория Информации - Методичка (1 семестр)
.pdfМетод Хаффмана не работает в случае двоичного входного алфавита, в таком алфавите одному символу придется присвоить код 0, а другому 1 и сжатия не получится, а присвоить одному символу код короче одного бита метод Хаффмана не может. Если источник выдает двоичные символы, то для построения кода Хаффмана можно использовать группы бит некоторой длины. Например, если мы будем рассматривать группы по 4 или по 8 бит, то это будет равносильно входному алфавиту мощностью 24 или 28.
К сожалению, алгоритм Хаффмана имеет существенный недостаток. Дело в том, что для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться вместе с данными, что может свести все усилия по сжатию сообщения к нулю. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного – для построения модели сообщения, другого – для собственно кодирования.
Отметим, что существуют несколько модификаций метода Хаффмана, адаптированных для конкретных задач, для более подробного изучения этих модификаций следует обратиться к специальной литературе.
3.3.Семейство алгоритмов Лемпеля–Зива
В1977–1978 гг. Абрахам Лемпель (Abraham Lempel) и Якоб Зив (Jacob Ziv) предложили два алгоритма сжатия: LZ77 и LZ78. Эти алгоритмы легли в основу целого семейства алгоритмов построения кодов сжатия с использованием словарного подхода (к этому семейству относятся, например, алгоритмы LZ-LZO, LZS, LZW, LZC, LZMA, LZH). Все модификации этого алгоритма кодируют данные с априорно неизвестной статистикой и без потерь.
Все алгоритмы семейства Лемпеля–Зива основаны на следующих принципах:
– каждая очередная закодированная последовательность символов добавляется к ранее закодированным символам таким об-
59

разом, что вместе с ними она образует разложение всей принятой и переданной информации на несовпадающие между собой фразы. Такое разложение хранится в памяти и используется в дальнейшем в качестве словаря;
– если представить входные данные одной длинной строкой, то можно сказать, что алгоритм использует «скользящее» по сообщению окно, которое движется слева
Обычно, в программ- |
направо (от начала к концу строки). Ок- |
|
ной реализации, размер |
но состоит из двух частей: первая – сло- |
|
окна составляет несколь- |
||
|
||
ко килобайт, а размер |
варь, большая по размеру, включает уже |
|
буфера – не более ста |
просмотренную и закодированную часть |
|
байт. |
||
|
||
|
сообщения. Вторая – буфер, намного |
меньшая словаря, содержит еще незакодированные символы входного потока. Размер буфера обычно зафиксирован и в него входят не все необработанные символы сообщения, а лишь некоторая часть из них;
– алгоритм заменяет второе и последующее вхождения некоторой строки символов в сообщении (из буфера) ссылками на ее первое вхождение (из словаря);
Декодирование этих кодов проще кодирования, так как нет необходимости строить словарь.
Рассмотрим два базовых алгоритма Лемпеля–Зива. Алгоритм LZ78 не использует буфер и скользящее окно.
Вместо этого он использует словарь, размер которого ограничен только объемом используемой памяти. Процесс кодирования в LZ78 алгоритме Лемпеля–Зива начинается с пустого словаря, так что первые элементы являются позициями, которые не ссылаются на более ранние позиции. В словаре рекуррентно формируется выполняемая последовательность адресов. Каждому адресу соответствует последовательность из элементов алфавита. Закодированные данные хранятся в виде пакетов со следующей структурой:
<ссылка на адрес словаря, следующий знак данных>. Каждый новый входной элемент словаря образован как па-
кет, содержащий адрес того словаря, за которым следует следующий
60
символ. Код предполагает, что существующий словарь содержит уже закодированные сегменты последовательности символов алфавита. Данные кодируются с помощью просмотра существующего словаря для согласования со следующим сегментом кодируемой последовательности. Если согласование найдено, то, так как получатель уже имеет этот сегмент кода в памяти, нет необходимости пересылать его вновь, требуется только определить адрес, чтобы найти сегмент. Код ссылается на расположение последовательности сегмента в памяти, затем дополняет следующий символ в последовательности, чтобы образовать новую позицию в словаре кода. Декодер работает примерно так же, как и кодер, строя словарь и оперируя с ним.
Рассмотрим подробнее работу этого алгоритма на примере. Пример 3.7. Используя алгоритм LZ78, закодировать после-
довательность
abaababbbbbbbabbbba. (*)
Результат кодирования будем записывать в таблицу, содержащую три строки. В первой строке – адрес пакета данных, во второй – пакет данных в виде <адрес словаря, следующий знак данных>, в третьей – содержимое текущего пакета данных.
На начальном этапе работы алгоритма формируемый словарь пуст. Пока словарь пуст, будем просматривать кодируемую фразу посимвольно и кодировать отдельные символы, по мере заполнения словаря будем пытаться кодировать в один пакет данных несколько подряд идущих символов.
Сформируем первый пакет данных и добавим его в словарь. Первый символ кодируемой последовательности (*) – «а» запишем по первому адресу. Пакет данных будет иметь вид: <0,a>. При формировании текущего пакета данных не используется ссылка на содержимое других позиций словаря, поэтому первый элемент пакета данных равен нулю, значение следующего знака данных равно «а», – символу, который необходимо записать в словарь.
Адрес: 1
Пакет данных: <0,a> Содержимое: а.
61
Второй символ кодируемой последовательности (*) – «b» запишем по второму адресу. Пакет данных будет иметь вид: <0,b>. При формировании этого пакета данных также не используется ссылка на содержимое других позиций словаря, поэтому первый элемент пакета данных равен нулю, а значение следующего знака данных равно «b», – символу, который необходимо записать в словарь.
Адрес: 2
Пакет данных: <0,b> Содержимое: b.
Просматриваем далее входную последовательность abaababbbbbbbabbbba. Будем отмечать в ней подчеркиванием уже закодированные символы. Следующий из не закодированных символов – «а» уже встречался в словаре, поэтому теперь в один пакет запишем объединение этого символа со следующим
Адрес: 3 Пакет данных: <1,а>
Содержимое: аа.
Запись <1,а> в пакете данных означает, что необходимо взять символ(ы), записанные по адресу 1, и добавить к ним символ «а». Далее будем аналогичным образом продолжать процесс кодирования, каждый раз просматривая динамически формируемый словарь справа налево, т.е. с последней записи к первой. Оформим процесс кодирования в таблицу.
Адрес |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Пакет |
<0,a> |
<0,b> |
<1,a> |
<2,a> |
<2,b> |
<5,b> |
<5,a> |
<6,b> |
<1,-> |
данных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Содер- |
a |
b |
aa |
ba |
bb |
bbb |
bba |
bbbb |
a |
жимое |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Следует обратить внимание, что последний пакет данных, записанный по адресу 9, не содержит знака данных.
62

Рассмотрим еще один вариант алгоритма, известный как
LZ77-модификация алгоритма Лемпеля–Зива, который отличается от рассмотренной ранее модификации структурой пакета данных. Концепция адреса не используется, наоборот, имеются ссылки, предшествующие последовательности данных. Пакет данных формируется из трех значений: <А, В, С>, первые два из которых указывают на уже закодированную подпоследовательность данных, следующим образом: число А указывает на сколько знаков необходимо отступить назад, чтобы найти начало нужной подпоследовательности, В – длина подпоследовательности которую необходимо считать; С – следующий знак.
Этот алгоритм использует идею скользящего окна. Рассмотрим идею метода на примере, затем обсудим работу алгоритма с упреждающим буфером и скользящим окном.
Пример 3.8. Используя LZ77, закодировать последователь-
ность |
|
|
|
|
|
|
|
|
|
abaababbbbbbbabbbba. |
|
(**) |
|||
|
|
|
|
|
|
|
|
Пакет |
<0,0,a> |
<0,0,b> |
<2,1,a> |
<3,2,b> |
<1,1,b> |
<3,3,b> |
<8,5,a> |
данных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Содержимое |
A |
B |
Aa |
bab |
bb |
bbbb |
bbbb |
пакета |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Уже закоди- |
a |
ab |
abaa |
aba |
aba |
abaaba |
abaa |
рованный |
|
|
|
abab |
ababbb |
bbbbbbb |
bab |
текст |
|
|
|
|
|
|
bbbbbb |
|
|
|
|
|
|
|
|
В данном примере, не учтены ограничения, связанные со скользящим окном. Однако алгоритм использует эту технологию. Так, перед началом работы алгоритма должны быть заданы размеры словаря и буфера. Кодер просматривает словарь в обратном порядке (справа налево) и ищет в нем появление первого символа из буфера. Далее кодер определяет, сколько совпадающих символов следует за найденным. Кодер продолжает поиск, стараясь найти максимально длинные совпадающие последовательности.
63

Пример 3.9. Рассмотрим работу алгоритма с заданными длинами словаря и буфера. Пусть требуется закодировать последовательность «масло масляное». Ниже представлен фрагмент пошагового кодирования заданной фразы в случае, когда размер словаря 8 символов, а размер буфера 5 символов.
Словарь 8 символов |
Буфер 5 символов |
Код |
........ |
масло |
<0,0,м> |
…….м |
асло_ |
<0,0,а> |
..….ма |
сло_м |
<0,0,с> |
…..мас |
ло_ма |
<0,0,л> |
….масл |
о_мас |
<0,0,о> |
…масло |
_масл |
<0,0,_> |
..масло_ |
масля |
<6,4,я> |
ло_масля |
ное |
<0,0,н> |
Пусть необходимо вычислить длину закодированного файла в битах. Из рассмотренных примеров видно, что закодированный файл составляют кодовые слова. Следовательно, необходимо подсчитать количество таких слов и их длину. Для подсчета длины необходимо просуммировать размеры трех компонентов слова. Так, величина смещения не может быть больше размера словаря, следовательно, длина этого значения не превысит log2(размер словаря). Количество считываемых символов не может быть больше размера буфера, т. е. log2(размер буфера). Длина символа обычно составляет 8 бит, но в общем случае равна log2(мощность входного алфавита).
Таким образом, для рассмотренного фрагмента кодирования из примера 10 длина закодированного сообщения вычисляется сле-
дующим образом: 8 (log28+log25+8)=8 (3+3+8)=8 14=126 бит. При вычислении логарифма использовано округление до ближайшего большего целого. Очевидно, в данном случае кодирование оказалось неэффективным, так как простая запись 8 закодированных символов в двоичном виде заняла бы всего 8 8=64 бит. 
Основным недостатком алгоритмов семейства Лемпеля–Зива является малая эффективность при кодировании незначительного
64
объема данных. Кроме этого, для кодирования алгоритмами Лемпе- ля–Зива установлено, что повторяющиеся символы и часто появляющиеся цепочки символов кодируются эффективно; на кодирование начальных фраз затрачивается относительно большое количество бит. Методы теории информации позволяют доказать, что кодирование методом Лемпеля–Зива асимптотически оптимально. Это означает, что для очень длинного текста избыточность исчезает, т. е. среднее число бит, необходимое для кодирования текста, стремится к энтропии текста.
Краткие итоги
Сжатие позволяет минимизировать технические затраты на передачу и хранение данных.
Алгоритм Хаффмана основан на статистике входного сооб-
щения.
Группа алгоритмов Лемпеля–Зива основана на формировании динамического словаря.
Рекомендуемая литература
1.Вернер М. Основы кодирования / М. Вернер. – М.: Тех-
носфера, 2004. – 288 с.
2.Скляр Б. Цифровая связь. Теоретические основы и практическое применение / Б. Скляр. пер. с англ. – 2-е изд. – М.: Виль-
ямс, 2003. – 1104 с.
3.Сэломон Д. Сжатие данных, изображения и звука / Д. Сэломон. – М.: Техносфера, 2006. – 368 с.
4.Все о сжатии данных, изображений и видео [Электронный ресурс]. – Режим доступа: http://compression.ru/
5.Хаффман Д.А. Метод построения кодов с минимальной избыточностью / Д.А. Хаффман // Кибернетический сб. – М.: Мир, 1961. – Вып.3.
6.Ziv J. A Universal Algorithm for Sequential Data Compression / J. Ziv, A. Lempel // IEEE Transactions on Information Theory. – May 1977. – 23(3). – Р. 337–343.
65
Набор для практики по теме «Алгоритмы сжатия данных»
Проверьте уровень освоения материала по теме «Алгоритмы сжатия данных», используя предложенные упражнения и тесты.
Упражнения
1.Исследуйте степень сжатия файлов в зависимости от типа исходного файла и вида архиватора, обратите внимание на влияние размера исходного файла на степень сжатия.
2.Предложите несколько вариантов оценки степени сжатия данных для случая кодирования с потерями.
3.Закодируйте предложенную фразу рассмотренными выше двумя модификациями алгоритма Лемпеля–Зива, считая размер буфера и словаря неограниченными. Оцените эффективность кодирования.
Номер варианта |
Последовательность для кодирования |
1 |
12112323212123333333 |
2 |
ABAABAABBBAABBBB |
3 |
WWQEWQEEWWEQEWW |
4 |
1212231223311213 |
5 |
АВСВСВАВСААВАВСС |
6 |
SPSPPQQPPQQQSPSQ |
7 |
3331211233323332223 |
8 |
12323332331231122333 |
9 |
ЩФЫФЫФЩФЫЩЩФЩФЫЫ |
10 |
YXZYXZZZXXYXYXXYXY |
11 |
ZZXXYXZYXZZXXZYYYY |
12 |
22311232231123123321 |
13 |
ЭЮЭЮЮЯЭЮЮЯЯЭЭЮЭЯ |
14 |
ЭЮЯЭЮЯЯЯЭЭЯЭЮЯЭЮЯ |
15 |
QWEQWEQQWWEEWQWEQWE |
16 |
ABCABCACCABBBB |
17 |
SRPRPRPSRSSPPRSRR |
18 |
12312313312222 |
19 |
EQWQWQQEQWQQEWQE |
20 |
EEWQEWEEWQQWEEWE |
66
4. Для указанного входного алфавита, мощностью 5 элементов, дважды постройте код Хаффмана для выходных алфавитов различной мощности. Вычислите средние длины построенных кодов. Сравните значения энтропии исходного кода и среднюю длину кода.
Номер |
p(a) |
p(b) |
p(c ) |
p(d) |
p(e) |
p(f) |
Мощность |
варианта |
|
|
|
|
|
|
нового |
|
|
|
|
|
|
|
алфавита |
|
|
|
|
|
|
|
|
1 |
0,16 |
0,32 |
0,27 |
0,05 |
0,19 |
0,01 |
2, 3 |
|
|
|
|
|
|
|
|
2 |
0,64 |
0,15 |
0,03 |
0,06 |
0,08 |
0,04 |
2, 4 |
|
|
|
|
|
|
|
|
3 |
0,09 |
0,01 |
0,17 |
0,32 |
0,23 |
0,18 |
2, 3 |
|
|
|
|
|
|
|
|
4 |
0,12 |
0,35 |
0,05 |
0,1 |
0,1 |
0,28 |
2, 4 |
|
|
|
|
|
|
|
|
5 |
0,08 |
0,47 |
0,12 |
0,1 |
0,1 |
0,13 |
2, 3 |
|
|
|
|
|
|
|
|
6 |
0,44 |
0,01 |
0,34 |
0,1 |
0,1 |
0,01 |
2, 3 |
|
|
|
|
|
|
|
|
7 |
0,01 |
0,34 |
0,37 |
0,03 |
0,1 |
0,15 |
2, 4 |
|
|
|
|
|
|
|
|
8 |
0,34 |
0,4 |
0,06 |
0,1 |
0,05 |
0,05 |
2, 3 |
|
|
|
|
|
|
|
|
9 |
0,01 |
0,65 |
0,12 |
0,1 |
0,04 |
0,08 |
2, 4 |
|
|
|
|
|
|
|
|
10 |
0,21 |
0,01 |
0,45 |
0,1 |
0,1 |
0,13 |
2, 3 |
|
|
|
|
|
|
|
|
11 |
0,34 |
0,04 |
0,12 |
0,1 |
0,1 |
0,3 |
2, 4 |
|
|
|
|
|
|
|
|
12 |
0,29 |
0,37 |
0,08 |
0,1 |
0,1 |
0,06 |
2, 3 |
|
|
|
|
|
|
|
|
13 |
0,12 |
0,02 |
0,24 |
0,1 |
0,1 |
0,42 |
2, 4 |
|
|
|
|
|
|
|
|
14 |
0,07 |
0,45 |
0,01 |
0,1 |
0,1 |
0,27 |
2, 3 |
|
|
|
|
|
|
|
|
15 |
0,06 |
0,12 |
0,58 |
0,1 |
0,1 |
0,04 |
2, 4 |
|
|
|
|
|
|
|
|
16 |
0,14 |
0,37 |
0,08 |
0,1 |
0,1 |
0,21 |
2, 3 |
|
|
|
|
|
|
|
|
17 |
0,03 |
0,1 |
0,05 |
0,1 |
0,1 |
0,62 |
2, 4 |
|
|
|
|
|
|
|
|
18 |
0,03 |
0,17 |
0,34 |
0,1 |
0,1 |
0,26 |
2, 3 |
|
|
|
|
|
|
|
|
19 |
0,31 |
0,11 |
0,35 |
0,1 |
0,1 |
0,03 |
2, 4 |
|
|
|
|
|
|
|
|
20 |
0,33 |
0,11 |
0,36 |
0,01 |
0,1 |
0,09 |
2, 3 |
|
|
|
|
|
|
|
|
21 |
0,39 |
0,31 |
0,02 |
0,1 |
0,1 |
0,08 |
2, 4 |
|
|
|
|
|
|
|
|
22 |
0,12 |
0,02 |
0,32 |
0,1 |
0,1 |
0,34 |
2, 3 |
|
|
|
|
|
|
|
|
23 |
0,49 |
0,03 |
0,09 |
0,1 |
0,1 |
0,19 |
2, 4 |
|
|
|
|
|
|
|
|
24 |
0,21 |
0,22 |
0,03 |
0,1 |
0,1 |
0,34 |
2, 3 |
|
|
|
|
|
|
|
|
25 |
0,01 |
0,08 |
0,4 |
0,01 |
0,1 |
0,4 |
2, 4 |
|
|
|
|
|
|
|
|
67
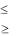
Тесты
Вариант 1
1. Как в теории сжатия данных называется информация, ко-
торой можно пренебречь при передаче? |
|
а) ерунда |
в) несущественная информация |
б) избыточная информация |
г) лишняя информация |
2. Как будет выглядеть пакет данных на 2-м шаге при вы- |
|||
полнении LZ78 алгоритма Лемпеля–Зива над последовательностью |
|||
abaababbbbbbbabbbba? |
|
|
|
а) <0,0,b>; |
б) b; |
в) <2,1,a>; |
г) bab. |
3. Для дискретного источника, выдающего символы с разной вероятностью, были построены различные коды. Какой из кодов, заданных множеством кодовых слов, не мог быть построен с помощью алгоритма Хаффмана?
а) {0, 10, 111, 110} |
в) {01, 10, 00, 11} |
|
б) {00, 01, 02, 10, 11, 12} |
г) {0, 10, 11, 100} |
|
|
4. Как связана средняя длина кода nср, построенного с помо- |
|
щью алгоритма Хаффмана, с энтропией источника H? |
||
а) nср |
Н |
в) nср = Н |
б) nср |
Н |
г) эти величины не связаны между |
|
|
собой |
|
Вариант 2 |
|
|
1. Какими свойствами обладают коды, построенные с помо- |
|
щью алгоритма Хаффмана? |
|
|
а) префиксные коды фиксиро- |
в) мгновенно декодируемые ко- |
|
ванной длины |
ды постоянной длины |
|
б) не префиксные коды постоян- |
г) префиксные коды переменной |
|
ной длины |
длины |
|
68