

Тема 5
.pdfТема 5: Статистика в медико-фармацевтических исследованиях
Отличительной чертой современного этапа развития естествознания является математизация и использование статистических методов анализа данных. Статистика — (от лат. status — состояние дел) наука, сочетающая учет и анализ, фиксирующая, систематизирующая и изучающая показатели наиболее типичных, массовых процессов и их изменение во времени. Статистические методы широко применяются в современной медицине и фармации. В клиниках, например, они используются для получения информации о влиянии различных антропометрических, социальных, экологических факторов на распространённость и течение заболеваний, а также дают возможность сравнивать эффективность различных методов лечения и т.д. Кроме того, бывают случаи, когда только путём анализа статистических данных можно определить являются ли некоторые побочные эффекты (случаи летального исхода) следствием применения конкретного препарата. Большое влияние статистические методы оказывают на формирование выборок, по которым происходит анализ данных. Методы статистического анализа используются также в процессе производства лекарственных препаратов, что позволяет проектировать создание оптимальных по ряду критериев (технических, экономических, экологических, фармацевтических) технологических процессов, контролировать качество получаемого сырья, выпускаемой продукции, настройки автоматических линий. Важную роль статистика играет в маркетинговых исследованиях, призванных определять потребности в лекарственных препаратах, тенденции замены одних поколений препаратов другими, оптимальную тактику продвижения препаратов на рынок. Создание различных баз данных и автоматизированных медицинских систем, накапливающих информацию, приводит к необходимости использования статистических методов для её обработки. Чрезвычайная сложность задач, решаемых медициной, и процессов, происходящих на фармацевтическом рынке, требует широкого применения математических методов статистики с использованием компьютерных технологий.
Информационные технологии в фармации. СРС. Тема 5. |
Страница 1 |

Выборочный метод наблюдения – основной метод научного исследования
Множество объектов изучаемого явления называется генеральной совокупностью. Сплошное наблюдение всех объектов генеральной совокупности (ГС) проводится редко. В научных целях чаще используют выборочный метод наблюдения, в котором используется только часть объектов ГС, по результатам анализа которой делают выводы обо всей ГС. Часть объектов, отобранных из ГС по определенным правилам, называется выборкой, или выборочной совокупностью. Выборкой х1, ..., хn объема n из совокупности называется n независимых наблюдений над случайной величиной с функцией распределения
F(x) (определение см. ниже). Вариационным рядом х(1) х(2) ... х(n) называется выборка, записанная в порядке возрастания ее элементов. При проведении исследований, особенно клинических, необходимо обеспечить следующие свойства выборки.
1. Однородность. При выборке влияние изучаемой совокупности факторов на интересующие признаки не должно противоречить друг другу. Например, при исследовании влияния кофе на организм человека, в выборке испытуемых одновременно не должно быть людей, которых кофе возбуждает, и тех, которых от него клонит в сон. В ряде случаев причины неоднородности могут быть неизвестны и поэтому перед анализом данных желательна проверка выборки методами кластерного анализа. При выборке не должно быть значимо влияющих на исследуемый параметр факторов, кроме тех, которые мы изучаем. Если мы предполагаем, что фазы Луны влияют на эффективность действия препарата, то фазу Луны необходимо учитывать как фактор или собирать выборки, в которых фаза луны одинакова.
2. Репрезентативность (структурное соответствие). Изучаемая выборка должна быть репрезентативна генеральной совокупности. Это означает что, когда мы формируем выборку из ГС, она должна отвечать следующим
требованиям: вид статистического распределения должен отвечать |
|
Информационные технологии в фармации. СРС. Тема 5. |
Страница 2 |

распределению ГС; величина выборки должна быть достаточной для отражения структуры ГС. В связи с этим выборка из больных, которые проходили курс лечения в одной клинике или покупателей одной аптеки не является репрезентативной по своей структуре. Опрос, проведённый по телефону, отражает мнение только владельцев телефонов, а не всего населения, структура заболеваемости в различных областях различна. Выводы маркетингового исследования, проведённого в Киеве, не распространяются на другие города. В тех случаях, когда мы сравниваем некоторые параметры двух выборок, необходимо обеспечить равенство распределения частот влияющих факторов (пол, возраст, серьёзность заболевания) в сравниваемых выборках.
3.Совпадение условий наблюдения. Условия наблюдения для отдельных элементов выборки или для двух сравниваемых выборок должны совпадать. Наилучшим способом обеспечения этого свойства является двойной слепой метод, при котором ни пациент, ни врач, ни средний медицинский персонал не знает, какие лекарства или плацебо выдаются конкретному больному. Это позволяет избавиться от эффекта внушаемости (влияние которого возможно на 30-50% пациентов) и эффекта предубеждённости.
Для исследования закономерностей, проявляющих себя через случайность, изучают законы распределения случайных величин и их числовые характеристики. Закон распределения – это соответствия между значениями случайной величины и вероятностями их реализации. При этом случайной называется величина, которая в результате эксперимента может принять неизвестное заранее значение. Случайные величины могут быть дискретными и непрерывными. Дискретной называется случайная величина, которая принимает отдельные значения, например, количество родившихся детей. Непрерывной является величина, возможные значения которой непрерывно заполняют какойлибо интервал, например, масса тела или рост новорожденных. Закон распределения ля дискретной случайной величины задаётся с помощью ряда или
Информационные технологии в фармации. СРС. Тема 5. |
Страница 3 |

многоугольника распределения (графика), а для непрерывной случайной величины в виде функции распределения. Функция распределения – это функция F(x), которая задаёт вероятность того, что случайная величина Х в испытании примет значение меньшее x: F(x)=P(X<x). Иногда её называют ещё интегральной функцией. Плотность распределения при этом является производной от функции распределения: φ(x)=F'(x). Рассмотрим наиболее широко встречающиеся законы распределения.
Нормальный закон распределения (Закон Гаусса)
Нормальный закон распределения занимает центральное место в статистике. Это обусловлено тем, что этот закон проявляется во всех случаях, когда случайная величина является результатом действия большого числа различных факторов. Абсолютно все признаки в живой природе подчиняются нормальному закону распределения. Рост мужчин, как и рост женщин, в одновозрастной популяции подчиняется этому математическому закону. Чтобы его понять, взгляните на рис. 1. По горизонтальной оси – линейка с показателями длины тела, а вот по вертикали отложены числа, указывающие, сколько раз такая длина тела встретилась при измерении роста, допустим, тысячи человек одного пола и возраста. И получается при этом ровный такой колокол, внутри которого поместилась вся тысяча человек. Колокол не просто ровный, он совершенно симметричный, и середина линейки соответствует самой высокой точке колокола. Это означает, что чаще всех встречаются люди именно с такой длиной тела. И очень часто встречаются люди с ростом немного меньше или немного больше. Значит, если идти по улице, то встречается больше всего людей похожего роста, словно в этом городе для людей существует такое правило. Встречаются, конечно, и другие – очень уж высокие или совсем маленького роста, но их не много. И чем они выше или, наоборот, меньше ростом, тем реже таких странных людей можно встретить. Потому и математический закон, который отражает такие правила, назвали не только по имени автора, но еще и нормальным законом
распределения. По-латыни «норма» означает «правило». Любой признак, частота |
|
Информационные технологии в фармации. СРС. Тема 5. |
Страница 4 |
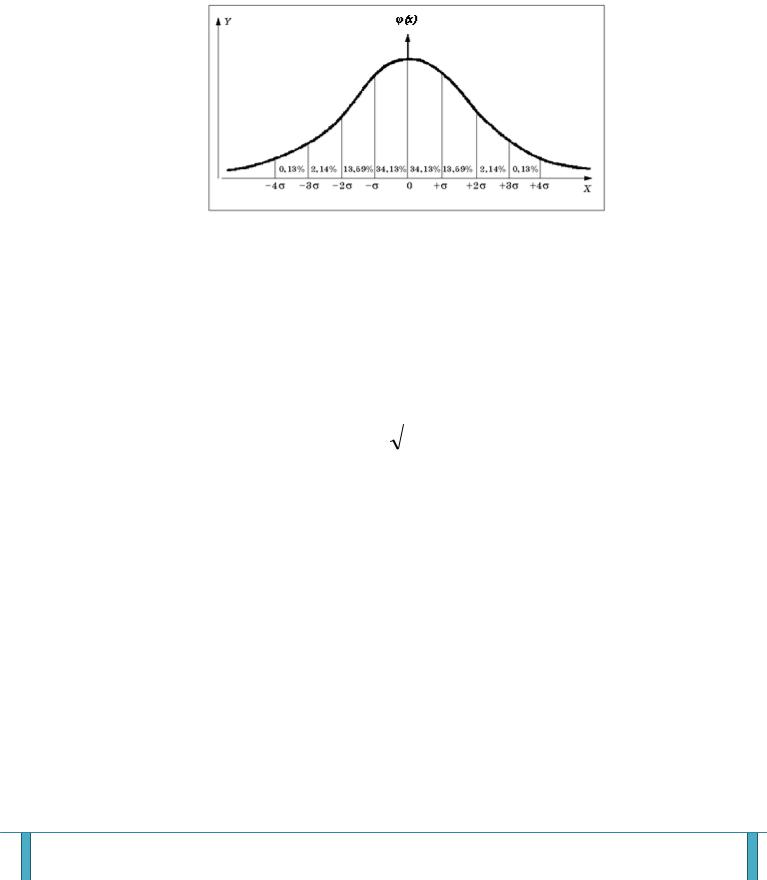
встречаемости которого соответствует закону Гаусса, называют нормально распределенным. К нормальному закону приближаются все остальные законы распределения. Закон Гаусса рассматривает то, каким образом группируются результаты измерений относительно среднего значения.
Рисунок 1 – Нормальное распределение.
Для нормального закона распределения плотность распределения описывается формулой:
x |
|
1 |
|
e |
x m 2 |
|
|
|
2 2 |
||||
|
|
|
|
|||
|
|
2 |
|
|||
|
|
|
|
|
||
где m – математическое ожидание, σ – среднее квадратическое отклонение (σ2 - дисперсия).
На нормальном законе распределения базируется практически вся параметрическая статистика. Это связано с тем, что большинство распределений, используемых для проверки статистических гипотез (Фишера, Стьюдента) являются преобразованиями нормального закона распределения.
Определение размеров выборки
При маркетинговых исследованиях выборочные исследования очень
распространены. Это различные опросы, анкетирование и пр. Например, |
|
Информационные технологии в фармации. СРС. Тема 5. |
Страница 5 |

консалтинговые фирмы получают информацию из 200-300 аптек и распространяют её на всю совокупность анкет страны. Выполняются опросы врачей по их предпочтению в назначении препаратов или аналогично больных. Рассмотрим вопрос определения необходимого размера выборки исходя из требований к точности результатов и сведений о генеральной совокупности. Наиболее часто применяется простой случайный отбор, когда из всей ГС случайным образом формируется выборка.
Размер выборки для определения долей
Для вычисления объёма выборки используется следующая формула:
|
|
|
|
|
tn2, PQ |
|
|
|||
n |
|
|
|
|
|
d 2 |
|
|
|
|
|
|
1 |
|
|
2 |
|
|
|
(1) |
|
|
|
|
|
|
|
|||||
|
|
|
|
tn, PQ |
|
|||||
1 |
|
|
|
|
|
|
|
1 |
|
|
|
|
d |
2 |
|
|
|||||
|
|
|
N |
|
|
|
|
|||
где N – размер генеральной совокупности, P – предположительный размер оцениваемой доли, а Q=1-P, d – абсолютная предельно допустимая ошибка в определении значения доли, tn,α - критическое значение распределения Стьюдента для числа степеней свободы n и уровня значимости α. Поскольку n точно не известно – берут приближённое значение tn,α ≈2.
К примеру, пусть необходимо выяснить какую долю составляет некоторый препарат в розничной продаже. Для этого мы предполагаем опросить некоторое количество аптек и полученный результат распространить на все аптеки. Допустим, общее количество аптек N=5000, предполагаемая доля препарата равняется P=0,03, предельное допускаемое нами отклонение от доли d=0,05. Тогда подстановка данных в формулу (1) даёт ответ: приблизительно 31. Если бы нас устроило предельно допускаемое абсолютное отклонение от доли d=0,1, то в таком случае достаточно было бы опросить 83 аптеки.
Информационные технологии в фармации. СРС. Тема 5. |
Страница 6 |

Формула (1) имеет предел при увеличении размера ГС:
|
t 2 |
|
PQ |
|
lim n |
n, |
|
(2) |
|
|
d 2 |
|||
N |
|
|||
Для нашего примера это значение равно 336. Таким образом, независимо от ГС (в данном случае количества аптек в стране) больше чем 336 аптек опрашивать не нужно.
Определение объёма выборки при заданной абсолютной точности при оценке значений.
Во многих случаях нам необходимо определить не доли, а значения, например среднее значение объёма продаваемого в одной аптеке конкретного препарата. Для определения объёма выборки используется формула (3):
|
|
|
|
t |
2 |
S 2 |
|
|
||
|
|
|
|
n, |
|
|
|
|
||
n |
|
|
|
|
|
d 2 |
|
|
||
|
1 |
|
tn2, S 2 |
(3) |
||||||
|
|
|
||||||||
1 |
|
|
|
|
|
|
|
|||
N |
|
|
d 2 |
1 |
||||||
|
|
|
|
|
|
|
|
|
|
|
где N – размер ГС, d – абсолютное значение предельно допустимой ошибки в определении значения, S2 – оценка выборочной дисперсии, tn,α - критическое значение распределения Стьюдента для числа степеней свободы n и уровня значимости α. Поскольку n точно не известно – берут приближённое значение tn,α ≈2.
Эта формула также имеет предельное значение при стремлении размера ГС к бесконечности:
|
t 2 |
S 2 |
|
|
lim n |
n, |
|
(4) |
|
d 2 |
||||
N |
||||
Информационные технологии в фармации. СРС. Тема 5. |
Страница 7 |

Некоторую проблему представляет необходимость получить оценку выборочной дисперсии. Для этого необходимо провести выборочное исследование, для нашего примера опросить 20-30 аптек и получить эту оценку, а затем использовать её для определения размера выборки. Размер выборки сильно зависит от дисперсии, т.е. от степени разброса данных – чем больше разброс (дисперсия), тем большим должен быть размер выборки. К примеру, для условий предыдущего примера нам необходимо определить средний размер продаж определённого препарата в аптеке, при этом предельное абсолютное отклонение не должно превышать 1000 грн. Таким образом, N=5000, d=1000, tn,α =2, S2=25000000 – оценка выборочной дисперсии, полученная в предварительном обследовании. Такая оценка соответствует большому разбросу в значении объёма продаж данного препарата в разных аптеках. Отсюда согласно формуле (3) при подстановке данных размер выборки должен быть762. Предельное значение в этом случае составляет 1000.
Существуют и другие формулы для расчета размера выборки, которые используются при расслоённом отборе, при котором возможна неоднородность отдельных частей ГС.
Характеристики (параметры) случайной величины
Кхарактеристикам случайной величины относятся:
1.Меры положения (среднее, медиана, мода, и пр.);
2.Меры рассеивания (размах, коэффициент вариации, дисперсия СКО – среднеквадратическое отклонение);
3.Меры формы (асимметрия, эксцесс, моменты третьего и четвёртого порядка).
I.Среднее арифметическое (выборочное). Характеризует положение центра в распределении. Рассчитывается по формуле:
Информационные технологии в фармации. СРС. Тема 5. |
Страница 8 |
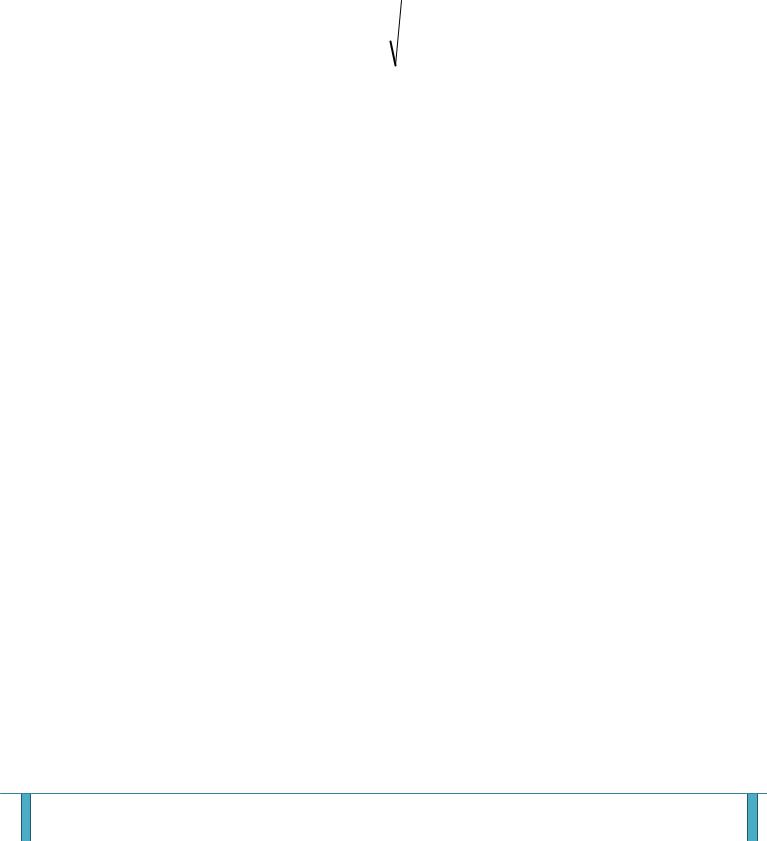
|
|
N |
|
|
|
|
xi |
|
|
X |
i 1 |
(5) |
||
N |
||||
|
|
|
II.Среднее геометрическое. Применяется когда отдельные значение в выборке отличаются друг от друга на порядок и выше.
|
|
n |
|
|
n X i |
|
|
X G |
(6) |
||
|
|
i 1 |
|
III.Среднее гармоническое. В ряде случаев, например, расчёт средней продолжительности жизни используется гармоническое среднее:
|
|
n |
|
|||
X H |
||||||
n |
1 (7) |
|||||
|
|
|
||||
|
|
X i |
|
|||
|
|
i 1 |
||||
IV. Мода. Это значение, которое наблюдается наибольшее число раз (наиболее вероятное), рассчитывается по формуле:
Mo XMo h |
(8) |
|
|
mMo mMo 1 |
|
|
2mMo mMo 1 mMo 1 |
|
где XMo – начало модального интервала (такого, которому соответствует наибольшая частота), h – величина модального интервала, mMo – частота модального интервала, mMo-1 – частота интервала, предшествующего модальному, mMo+1 – частота интервала, следующего за модальным.
V.Медиана. Это значение, которое делит ранжированный ряд на две равные по объёму группы. Вариационный ряд ранжируется. Если количество членов ряда нечётное, медианой является значение ряда, которое расположено посередине, то есть элемент с номером (N+1)/2. Если число членов ряда чётное, то медиана равна среднему членов ряда с номерами N/2 и N/2+1. медианным называется интервал, в котором находится значение медианы.
Информационные технологии в фармации. СРС. Тема 5. |
Страница 9 |
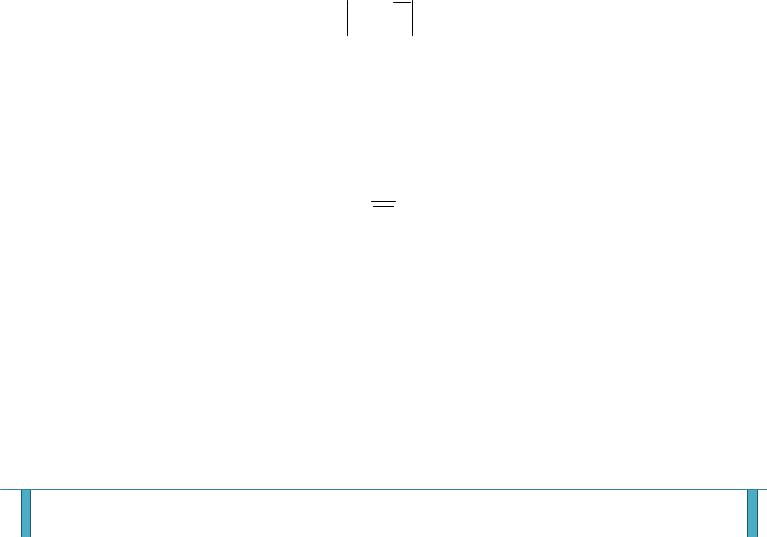
VI. Вариационный размах. Не меняется при любых изменениях вариационного ряда, не затрагивающих крайние значения:
RB X max X min (9)
VII. Эмпирическая дисперсия |
(дисперсия) |
– мера разброса данной случайной |
||
величины, т. е. её отклонения от математического ожидания, определяемая |
||||
по формуле: |
|
|
|
|
|
N |
2 |
|
|
|
X i |
|
|
|
|
X |
|||
S 2 |
i 1 |
|
(10) |
|
N 1 |
|
|||
|
|
|
||
VIII. Стандартное отклонение (среднеквадратическое отклонение (СКО)) –
корень квадратный из дисперсии. Обозначается как S или σ.
IX. Среднее линейное отклонение – величина, вычисляемая по формуле:
N
Xi X
d |
|
i 1 |
|
(11) |
|
N |
|||
|
|
|
|
X.Коэффициент вариации. Если коэффициент вариации больше 100%, то это обычно означает что данные неоднородны.
V XS 100% (12)
XI. Доверительный интервал. Это интервал, относительно которого с наперёд заданной вероятностью P=1-α можно утверждать, что он содержит неизвестное значение параметра θ: P[θ1< θ< θ2]=1- α, где (1- α) – доверительная вероятность, α – уровень значимости. Доверительный интервал означает не вероятность попадания значение оцениваемого параметра в пределы определённых границ, а то что, если достаточное
число выборок, 100×p% случаев параметр будет находится в заданном
Информационные технологии в фармации. СРС. Тема 5. Страница 10