

TAIFYa_1-21
.pdf1. Конечные автоматы. Структура и поведение. Способы описания. Модели Мура и Мили.
Автомат – преобразователь информации. |
|
|
Входная информация |
Преобразователь |
Выходная информация. |
Вконечном автомате выходные данные определяются не только тем, что присутствует в данный момент, но и тем какова была последовательность подачи входных воздействий, поэтому с точки зрения внешнего наблюдателя на одно и то же входное воздействие могут быть получены разные выходные сигналы.
Вконечном автомате различные реакции на одинаковые входные воздействия реализуются за счет внутренних его состояний. Таким образом, автомат характеризуется:
множеством входных состояний.
множеством выходных состояний.
множеством внутренних состояний.
множеством переходов.
Переходы описывают, из какого внутреннего состояния под воздействием какого входного сигнала в какое состояние осуществляется переход.
Переходы могут быть описаны с помощью графов переходов. Вершинами графа ставятся в соответствии внутренние состояния, а дугами, которые связывают вершины, ставятся соответствующие переходы. Входные воздействия, по которым осуществляются переходы, надписываются над дугами.
Модель Мура.
Выходной сигнал определяется как функция от внутреннего состояния. Выходные сигналы записываются внутри вершин графа.
Модель Мили.
Выходной сигнал является функцией внутреннего состояния и входного воздействия и считается, что выходной сигнал считается во время перехода автомата из одного состояния в другое, в таком случае выходной сигнал подписываются над дугами графа - переходов и выходов.
Для конечного автомата характерной особенностью является то, что следующие внутренние состояние зависит только от того, в каком внутреннем состоянии автомат находится сейчас и какое входное воздействие на автомат оказывается сейчас и не зависит от того, какова была предыстория попадания в это внутренние состояние.
2. Минимизация конечных автоматов.
Минимизация конечных автоматов – уменьшение количества внутренних состояний в автомате, при сохранении распознаваемого им языка.
I этап: Поиск совместных состояний.
Совмещать можно только состояния с одинаковыми выходными сигналами. Если множество внутренних состояний с одинаковыми выходными сигналами замыкаются, то эти состояния можно объединить.
II этап: Построение максимально совместных множеств состояний по известной информации о совместимости пар состояний.
Подход разделения.
III этап: Из этих максимально совместимых подмножеств необходимо выбрать минимальное покрытие всех состояний исходного автомата. Проверка выполнимости условий первого этапа.
IV этап: Проверим, соблюдаются ли в выбранных максимально совместимых подмножествах требования совместимости пар.
V этап: Рисуем новую таблицу.
3. Регулярные множества и регулярные выражения.
Примеры описания регулярных множеств регулярными выражениями.
Регулярными выражениями можно описать только такие языки, которые являются регулярными множествами.
Регулярное множество – множество, состоящее из элементов символов.
Если A,B – регулярные множества, то регулярными являются множества полученные операциями:
|
|
{ |
} |
|
|
{ |
} |
{ } |
{ } |
{ } |
|
Применение операции итерация к конечному множеству получается бесконечное множество
.
Для описания регулярных языков используются регулярные выражения:
a – символ сам по себе считается регулярным выражением, к ним можно применять операции дизъюнкции, конъюнкции и итерации.
Регулярные языки, описанные регулярными выражениями – языки, которые принимаются конечными автоматами, иные языки конечными автоматами не принимаются.
{a} – неограниченное количество символов a.
{a V b} – множество всех возможных строк в алфавите a, b.
4. Построение конечного автомата по заданному регулярному выражению.
Входные символы языка определяются символами языка. Внутренние состояние автомата получается разметкой регулярного отношения.
Правила распространения индексов на внутренние позиции
1.Индекс позиции перед скобками распространяется на все дизъюнктивные члены внутри скобок
2.Индекс конечного дизъюнктивного члена распространяется на следующий символ стоящей после скобок.
3.Символы позиции перед операционной скобкой переходит на следующий символ после операционных скобок, а индекс места за итерационными скобками – на начальные места всех дизъюнктивных членов, заключенных в итерационные скобки.
4.Индекс конечного места любого дизъюнктивного члена, заключенного в итерационные скобки, распространяется на начальные места всех дизъюнктивных членов, заключенных в эти итерационные скобки
5.Индексы мест, слева и справа от которых стоят буквы, никуда не распространяются
6.Индекс конечного места распространяется на те же места, на которые распространятся индекс начального состояния. Это правило справедливо только в тех случаях, когда предлагается построение автомата многократного действия.
Символ в регулярных выражениях – входное воздействие, слева от него стоит индекс исходного внутреннего состояния, а справа состояние перехода.
Все состояния, в имени которого присутствует метка позиции конечной, следует поставить метки выходного правильного сигнала.
Для получения автомата можно построить другую эквивалентную ему таблицу меньших размеров.
Два автомата называются эквивалентными, если на одинаковые последовательности входных символов, они отвечают одинаковыми последовательностями выходных символов.
Объединить можно такие состояния, из которых под воздействием одноименных входных символов автомат переходит в одни и те же состояния, либо эквивалентность состояния.
Из полученной таблицы можно удалить состояния, в которые нельзя попасть, начиная с начального состояния.
5. Формальные грамматики. Описания регулярных языков регулярными грамматиками.
(
T – алфавит языка.
V– множество вспомогательных символов.
–один из вспомогательных символов. P – множество правил.
Для описания правил используются метаязык – форма Бэкуса-Наура.
Метасимволы:
-это есть по определению, слева определенный символ, справа определение.
-используются для определения вспомогательных символов.
-или, используется для разграничения правил с одинаковой левой частью.
Требования к автоматной грамматике.
1.В левой части всех правил может стоять только 1 детерминированный символ.
2.Правая часть правил может содержать либо только один терминальный символ, либо 2 символа один из которых терминальный, а другой не терминальный.
6. Построение конечного автомата по заданной регулярной грамматики.
Множество входных символов автомата определяются множеством T – терминальных символов грамматики. Множеством внутренних состояний автомата определяются множеством V – нетерминальных символов грамматики.
Последнее состояние автомата определяются аксиомой.
Множество правил грамматики определяет множество переходов графа. 1. Если есть правило вида:
Это соответствует дуге графа:
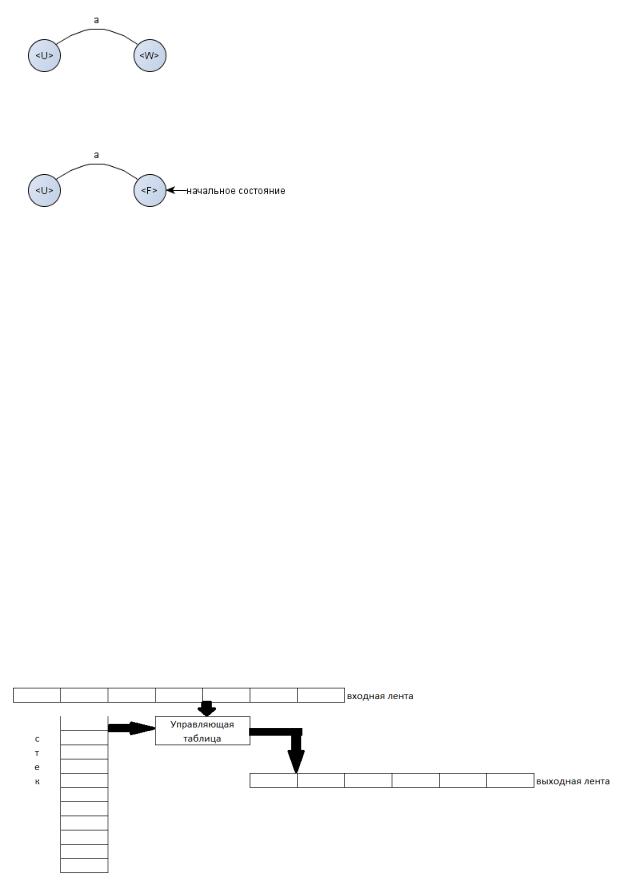
2. Если есть правило вида:
Это соответствует дуге графа:
7.Недетерминированные конечные автоматы.
Удетерминированного автомат может быть несколько начальных внутренних состояний и из одного
внутреннего состояния может быть определенно несколько переходов по одному и тому же воздействию. Если в грамматике есть правила с одинаковыми правыми частями, а левые разные, то автомат
недетерминированный.
Строка считается принадлежащей языку принимаемому автоматом, если под воздействием ее символов можно пройти хотя бы из одного начального состояния, хотя бы в одно конечное.
Недетерминированный конечный автомат всегда можно преобразовать к детерминированному эквивалентному по принимаемому языку.
В детерминированном автомате, внутренние состояния будем обозначать внутренние состояния сложными именами, состоящими из детерминированного автомата.
|
Начальное состояние считается то, что является объединением начальных состояний |
||
недетерминированного автомата. |
|
||
|
Если имя исходного состояния |
, а входное воздействие , то переход из этого состояния в |
|
( |
|
|
|
( |
{ |
} |
|
|
Из множества P под воздействием |
переход во множество R. |
|
Последними состояниями в новом автомате считаются такие, в именах которых присутствуют имена последних состояний исходного недетерминированного автомата.
8. Автомат с магазинной памятью. Структура и поведение. Примеры использования.
Магазин – синоним к слову стек, а стек – это структура данных, в которых все включения и выключения делаются с одного конца.
В автоматах с магазинной памятью структура тела стек используется для хранения информации некоторого прошлого автомата.
Та запись, которая доступна – вершина стека и она определяет текущее состояние внутренние. Языки, которые распознаются с помощью таких автоматных моделей называются контекстно-свободными языками и описываются контекстно-свободными грамматиками.
9. Контекстно-свободные грамматики. Пример описания контекстно-свободных грамматик.
Языки, которые распознаются с помощью таких автоматных моделей, как автомат с магазинной памятью, называются контекстно-свободными языками и описываются контекстно-свободными грамматиками:
1.В левой части правил стоит один нетерминальный символ, а справа строка.
2.В правой части правил может стоять произвольная строка терминалов, не терминалов и пуста строка.
3.В общем случае для КС-языка может быть построен недетерминированный автомат с магазинной памятью.
10. Задача разбора. Классификация и краткая характеристика алгоритмов решения задачи разбора.
Дана грамматика, описывающая формальный язык, дана строка символов, требуется определить, является ли эта строка предложением языка, который описываются заданной грамматикой.
Каждая строка, которая получается в процессе вывода, называется сентенциальной формой. Процесс разбора, как в прочем и вывода удобно изображать в виде синтаксического дерева ввод или
вывода.
Дерево – частный случай графа, у каждой вершины может быть несколько потомков, а предков не более одного. Та вершина, у которой нет предков, называются корнем дерева. Вершины, у которых нет потомковлистья или терминальные вершины.
В сентенциальном дереве разбора в корне помещается аксиома, потомки каждой внутренней вершины составляют правую часть правила грамматики, а сама вершина содержит левую часть этого правила, крона дерева – предложение языка.
Решить задачу разбора – это значит погаситься построить синтаксическое дерево разбор, кроной которого является заданная строка.
Все алгоритмы решения задачи разбора делятся на - восходящие и нисходящие в зависимости от того, в каком направлении они строят это дерево.
11. LL(1)-грамматики. Построение управляющей таблицы для LL(1)-разбора.
Детерминированный распознаватель с магазинной памятью для LL(1)-грамматики просматривает строку один раз слева направо, в процессе распознавания используется левый разбор – последовательность выделения правил с левым выводом.
Левый вывод – на каждом шаге вывод в сентенциальной формой для замены выбирается самый левый не терминал.
LL(1)-грамматики позволяют построить такой автомат, у которого в заголовках столбцов управляющей таблицы помещено по 1 символу.
Внутри LL(1) таблицы находятся команды 4-х типов:
1.,где α – произвольная строка терминалов и не терминалов, а i – целое число.
2.Выброс.
3.Допуск.
4.Привидение.
Для того, чтобы у грамматики было свойство LL(1) необходимо, чтобы терминальные префиксы всех альтернативных правых частей правил для одного и того же не терминала были различны.
Если не терминал левой части правила, в правой части правила занимает леву позицию, то такое правило называется леворекурсивным и у такой грамматики нет свойства LL(1).
Алгоритм построения LL(1)-таблицы. |
|
|
||
1. |
Если в грамматике есть правило |
|
, то во все клетки управляющей таблицы с координатами |
|
(A,α)=α,i, следует записать команду α,i. |
|
|
|
|
2. |
Во все клетки таблицы с координатами |
( |
, где b-терминальный символ |
|
3. |
В клетку таблицы ( |
. |
|
|
4. |
Во все клетки, оставшиеся пустыми, заносятся команда ошибка. |
|||
Взаголовки строк выносятся в произвольном порядке все терминальные символы, нетерминальные символы и маркер стека.
Взаголовки столбцов выносятся все терминальные символы и маркер правого конца строки. Каждое правило должно попасть хотя бы в одну ячейку таблицы.
Терминальные префиксы всех строк выводимых из правой части 1-ого правила, поэтому 1 правило
помещается в таблицу с координатой S,a.
Если в грамматике есть правило вида то во все ячейки ( , где b – терминальный символ, который может следовать после данного терминала в какой-либо сентенциальной форме.
|
12. Применение детерминированного автомата с магазинной памятью для LL(1)-разбора. |
Внутри LL(1) – таблицы находится команды четырех типов: |
|
|
, где – произвольная строка терминальных и нетерминальных символов, – целое число. Из |
вершины стека удаляется один символ, а вместо него посимвольно помещается строка , таким образом, что самый первый символ строки оказался в вершине стека. Число помещается в выходную строку.
Выброс. Из вершины стека удаляется один символ и автомат переходит по входной ленте к следующему символу справа.
Допуск. Алгоритм прекращает разбор с выводом о том, что строка правильная, при этом в выходной ленте находится левый разбор.
Ошибка. Разбор прекращается с сообщением, что строка неправильная.
Детерминированный автомат с магазинной памятью для LL(1) – разбора применяется для распознавания строк языка описанного LL(1) – грамматикой.
Используется в трансляторах.
13. LR(1)-грамматики. Построение управляющей таблицы для LR(1)-разбора. Работа восходящего алгоритма разбора – это последовательность шагов двух типов – сдвиг и
приведение.
Управляющая таблица для LR(1) – грамматики содержит команды четырех типов:
|
Сдвиг . |
|
Приведение . |
Допуск.
Ошибка.
Строится правый разбор – это обобщенная последовательность номеров правил примененных при правом выводе.
Алгоритм построения LR(1) – таблицы.
Взаголовки столбцов – все нетерминальные, терминальные символы и маркер конца строки.
Взаголовки строк выносится внутренние состояния.
Внутренние состояния автомата определяются в результате разметки правых частей грамматики: индексами внутренних состояний отмечаются позиции перед первым символом, после последнего и между рядом стоящими символами правых частей грамматики.
Начальные позиции всех правил грамматики для аксиомы отмечаются индексами начального состояния автомата.
Если индекс состояния оказался перед нетерминальным символом, его следует распространить на начальные позиции всех правых для этого не терминала.
Если в двух или более правилах слева от одного и того же символа оказались одинаковые индексы состояний, то и справа от этих символов следует поставить одинаковые индексы состояний.
Если в правилах грамматики обнаружилась конфигурация iaj, то ( |
. |
|
размещаются в строках |
(управляющей таблицы) озаглавленных индексом конечных позиций |
|
правил, а столбцы для размещения команд типа R определяются символами-следователями для не терминалов левых частей соответствующих правил.
(начальное состояние, аксиома)=допуск.
Все клетки оставшиеся пустыми заполняются командой ошибка.
14. Применение детерминированного автомата с магазинной памятью для LR(1)-разбора.
LR(1) алгоритм в процессе своей работы ведет два стека – стек символов, в который читаются символы из входной ленты, и стек – состояний. В вершине стека-состояний находится код текущего внутреннего состояния автомата, именно он определяет координату строки управляющей таблицы, к которой надо обращаться.
|
Сдвиг (S – Shift), где – код внутреннего состояния, в которое нужно перейти. Из входной ленты |
|
читается символ в стек-символов и выполняется переход к следующему символу и в стек-состояний |
||
заносится код . |
|
|
|
Приведение |
(R – Reduction), где – номер правила, по которому выполняется приведение. В |
выходную ленту пишется число , из стека-символов удаляется правая часть j-ого правила и из стекасостояний удаляется столько же символов, сколько и из стека-символов. Далее надо обеспечить чтение из входной ленты левой части j-ого правила.
Допуск. Заканчивается разбор строки с сообщением, что строка правильная.
Ошибка. Заканчивается разбор строки с сообщением об ошибке.
15. Детерминированный разбор с использованием грамматики простого предшествования.
1) |
тогда |
̇ . |
2) |
где |
и из W выводится за один или более шагов строка, начинающаяся с B, то |
|
. |
|
3) |
|
где |
и из W выводится за один или более шагов строка, оканчивающаяся |
на A, то |
. |
|
|
4) |
Если A и B не могут стоять рядом не в какой сентенциальной форме, то отношения простого |
||
предшествования для них неопределенно.
Левые символы из пары, считаем, стоят в заголовках строк, а правые – в з заголовках столбцов. КС-грамматика называется грамматикой простого предшествования если:
В ней нет – правил.
В ней нет правил с одинаковой правой частью.
Для каждой пары символов из алфавита терминалов и не терминалов определенно не более одного отношения простого предшествования.
В сентенциальной форме |
основой является такая самая левая подстрока |
, для |
символов которой выполняется следующие отношения простого предшествования:
̇̇ ̇ ̇
Вводим маркеры левого и правого конца строки. Левый маркер меньше всех символов, с которых может начинаться строка, а правый маркер больше всех символов, на которых может заканчиваться строк.
̇- команды сдвига.
- команда приведение.
Пустые клетки – ошибка.
16.Детерминированный разбор с использованием грамматики слабого предшествования.
КС-грамматика называется грамматикой слабого предшествования если:
В ней нет – правил.
В ней нет правил с одинаковыми правыми частями.
Для каждой пары символов из алфавита терминалов и не терминалов выполняется одновременно
отношения |
и ̇ . |
Если в грамматике есть правила вида:
и.
Если правая часть одного правила является суффиксом правой части правила, то между символами X и B не должно быть ни отношения , ни ̇.
Матрицу отношений для грамматики слабого предшествования можно заменить таблицей типа сдвиг – приведение, удали из нее столбцы, озаглавленные нетерминальными символами, поскольку имитация чтения не терминалов из входной ленты выполняется для уточнения отношения предшествования между символами находящимися в вершине стека и не терминалом, к которому было выполнено приведение. Поскольку грамматика слабого предшествования не делает различий между отношениями и ̇, нет необходимости имитировать чтение не терминала.
̇- команды сдвига.
- команда приведение.
Грамматика слабого предшествования всегда может быть преобразована к грамматике простого предшествования.
17. Детерминированный разбор с использованием грамматики расширенного предшествования. (m,n) – предшествование.
m,n – целые числа, показывающие длину контекста.
Если |
существует такая сентенциальная форма, что |
и при этом последний символ и первый |
||
символ |
принадлежат основе, то |
̇ . |
|
|
Если существует такая сентенциальная форма |
и при этом последний символ строки находится |
|||
за пределами основы, а первый символ внутри основы, то |
, а если символ находится внутри |
|||
основы, |
а первый символ за основой, то |
. |
|
|
Если |
не могут стоять рядом не в какой сентенциальной форме, то отношение (m,n) – |
|||
предшествования для них неопределенно. |
|
|
||
Изначально строится такое вспомогательное множество |
всех возможных строк длины m + n из |
|||
всевозможных сентенциальных форм грамматики (m,n) – предшествования начинается со строк
вместо аксиомы следует подставить все возможные правые части правил и из полученных сентенциальных форм выбрать все строки длиной m + n. Этот шаг повторяется о тех пор, пока не скажется невозможным включить во множество какую-либо новую подстроку длиной m + n.
Для обнаружения отношения выбираем такие строки из множества , у которых S стоит на правом конце.
Справа от отношений стоят символы, с которых начинаются строки выводимые из S, а слева все подстроки для m, которые присутствуют в тройках с S на правом конце множества Y.
Для обнаружения отношений ̇рассмотрим строки, в которых S стоит в середине.
|
Для того, чтобы найти отношения |
нужно взять строки с S в середине, тогда справа от S окажутся |
строки |
, а строки , будут последовательности символов, выводимых из S. |
|
Результат сведем в матрицу отношений (m,n) – предшествования.
18. Детерминированный разбор с использованием грамматики операторного предшествования.
Отношение операторного предшествования определяются только для терминальных символов.
. |
|
|
|
|
|
|
|
|
|
Если в грамматике есть форма |
или |
|
, где |
, то тогда |
̇ . |
||||
|
Если |
|
, где |
|
или |
, где |
, то тогда |
̇ . |
|
|
Если |
|
, где |
|
или |
, где |
, то тогда |
. |
|
Если в контекстной грамматике нет правил, в которых рядом стояли два не терминальных символа, то |
|||||||||
грамматика называется операторной, а так же в ней нет |
– правил, правил с одинаковыми правыми частями |
||||||||
и для каждой пары не терминалов определено не более одного операторного предшествования. |
|||||||||
Теорема: Пусть текущая сентенциальная форма имеет вид |
|
, где N – не терминал, t – |
|||||||
терминал и присутствие всех N символов не обязательно. Основой в этой сентенциальной форме является |
|||||||||
такая самая левая подстрока: |
|
|
, для терминальных символов, которой выполняется |
||||||
следующие отношение операторного предшествования: |
̇ |
̇ |
̇ |
. |
|||||
|
|
|
|
19. Классификация грамматик по Хомскому. |
|
|
|||
Классы пронумерованы от 0 до 3 и классификация выполняется по виду грамматики. |
|
||||||||
Класс 0 – грамматики общего вида (машина Тьюринга) |
|
|
|
||||||
|
, где |
( |
|
( |
. |
|
|
|
|
Класс 1 – контекстно зависимые грамматики (машина Тьюринга с ограниченной входной лентой) |
|||||||||
|
, где |
( |
|
|
( |
|
|
|
|
|
– не терминал, |
( |
|
|
|
|
|
|
|
Не терминал U может быть заменен строкой и только в контексте |
. |
|
|
||||||
Класс 2 – контекстно свободные – частный случай зависимых ( ( |
( |
|
|
||||||
|
, где |
|
( |
. |
|
|
|
|
|
Класс 3 – автоматные (регулярные) грамматики , где
Для распознавания контекстно свободных языков требуется не детерминированный автомат с магазинной памятью, а для автоматной грамматики в общем случае требуется детерминированный конечный автомат.
20. Алгоритм Эрли решения задачи разбора.
Алгоритм Эрли – универсальный алгоритм для всех контекстно свободных грамматик.
Выполнение алгоритма заключается в построении ситуаций. Для разбора строки n, надо построить n+1 список ситуаций. Ситуация представляет собой объект следующего вида:
, где запятая ( , ) и точка ( . ) – метасимволы, не принадлежащие языку; l –
целое число от 0 до N. |
|
|
В список включается ситуация вида |
если из части A выводится |
фрагмент |
разбираемой строки.
Строка является правильной, если удалось построить все n+1 списков и в последнем списке есть ситуация
|
– иначе строка неправильная. |
|
|
|||
Алгоритм. |
|
|
|
|
|
|
1. |
Для каждого правила вида |
включается ситуация |
. |
|||
2. |
Если в списке |
есть ситуация вида |
, где B – не терминал, то для каждого правила |
|||
грамматики |
следует включать ситуацию |
, если этой ситуации еще в списке нет. |
||||
3. |
Если в списке |
есть ситуация вида |
, то для каждой ситуации из этого же списка |
|||
включается ситуация |
|
, если этой ситуации еще в списке нет. |
||||
4. |
В списке |
описывается ситуация, в которой точка ( . ) стоит перед j-ым символом разбираемой |
||||
строки, тогда точка ( . ) перетаскивается перед j–ый символ и эта ситуация заносится в список j.
5. |
Если в списке с номером j есть ситуация вида |
, то для каждого правила грамматики |
||
|
следует внести в список ситуацию вида |
, если этой ситуации еще в списке нет. |
||
6. |
Если в списке с номером j есть ситуация вида |
, то для каждой ситуации из списка с |
||
номером k вида |
следует внести в список с номером j ситуацию |
. |
||
21. Синтаксически управляемые схемы перевода.
Автоматы с магазинной памятью были нужны для того, чтобы ответить на вопрос, принадлежит ли слово языку + выдать дерево разбора, если да.
СУ-схемы (синтаксически управляемые) имеют на выходе новую цепочку (итоговую программу (например, на Assembler’е)). Фактически, такая схема представляет собой КС-грамматику, в которой к каждому правилу добавлен элемент перевода. Всякий раз, когда правило участвует в выводе входной цепочки, с помощью элемента перевода вычисляется часть выходной цепочки, соответствующая части входной цепочки, порожденной этим правилом.
Грамматика — это четверка
( , где
N — алфавит нетерминальных символов;
— алфавит терминальных символов,
P — конечное множество правил вида , где (N )*N(N )*, (N )*, S — начальный знак (или аксиома) грамматики.
Cхемой синтаксически управляемого перевода (или трансляции, сокращенно: СУ-схемой) называется
пятерка |
|
( |
, где |
N — конечное множество нетерминальных символов (алфавит);
—конечный входной алфавит;
—конечный выходной алфавит;
R — конечное множество правил перевода вида ( ( и вхождения нетерминалов в цепочку образуют перестановку вхождений не терминалов в цепочку , так что каждому вхождению не терминала B в цепочку соответствует некоторое вхождение этого же не терминала в цепочку ; если не терминал B встречается более одного раза, для указания соответствия используются верхние целочисленные индексы;
S — начальный символ, выделенный не терминал из N.
Определим выводимую пару (аналог сентенциальные формы) в схеме Tr следующим образом:
(1)(S, S) — выводимая пара, в которой символы S соответствуют друг другу;
(2)если ( A ; 'A ') — выводимая пара, в цепочках которой вхождения A соответствуют друг другу,
и |
— правило из R, то ( |
— выводимая пара. |
||||
Для обозначения такого вывода одной пары из другой будем пользоваться обозначением : |
||||||
( |
|
( |
. Рефлексивно-транзитивное замыкание отношения обозначим *. |
|||
Переводом ( |
определяемым СУ-схемой Tr, назовем множество пар |
|||||
{( |
( |
( |
|
|
|
} |
СУ-схема |
( |
|
|
называется простой, если для каждого |
||
правила A , из R соответствующие друг другу вхождения не терминалов встречаются в и в одном и том же порядке.
Перевод, определяемый простой СУ-схемой, называется простым синтаксически управляемым переводом (простым СУ-переводом).
Имея дерево вывода для входной цепочки (полученное ранее (с помощью МПА)), применяем к нему правые части правил СУ-схемы и получаем выходную цепочку. Т.о. СУ-сехма — это алгоритм.