

4. Вычислительные системы с массовой параллельной обработкой
Основным признаком,
по которому ВС относят к архитектуре
с массовой параллельной обработкой(MPP,MassivelyParallelProcessing),
служит количество процессоровn.
Строгой границы не существует, но обычно
при![]() считается, что это ужеMPP,
а при
считается, что это ужеMPP,
а при![]() – еще нет. Обобщенная структураMPP-системы показана на
рис. 13.4.
– еще нет. Обобщенная структураMPP-системы показана на
рис. 13.4.
Главные особенности, по которым ВС причисляют к классу MPP, сле-дующие:
стандартные микропроцессоры;
физически распределенная память;
сеть соединений с высокой пропускной способностью и малыми задерж-ками;
хорошая масштабируемость (до тысяч процессоров);
асинхронная MIMD-система с пересылкой сообщений;
программа представляет собой множество процессов, имеющих отдельные адресные пространства.
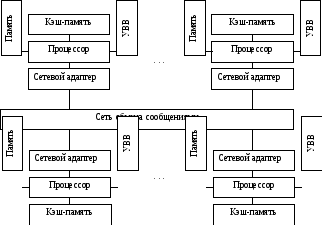
Рис. 13.4. Структура вычислительной системы с массовой параллельной обработкой
Характерная черта MPP-систем – наличие единственного управляющего устройства (процессора), распределяющего задания между множеством подчи-ненных ему одинаковых устройств. Схема взаимодействия довольно проста:
центральное управляющее устройство формирует очередь заданий, каж-дому из которых назначается некоторый уровень приоритета;
по мере освобождения подчиненных устройств им передаются задания из очереди;
подчиненные устройства оповещают центральный процессор о ходе и за-вершении выполнения задания или о потребности в дополнительных ре-сурсах;
у центрального устройства имеются средства для контроля работы под-чиненных процессоров, в том числе для обнаружения нештатных ситуаций, прерывания выполнения задания в случае появления более приоритетной задачи и т.п.
В некотором приближении можно считать, что на центральном процессоре выполняется ядро операционной системы (планировщик заданий), а на подчи-ненных ему – приложения. Подчиненность между процессорами может быть реализована как на аппаратном, так и на программном уровне. Большинство MPP-систем имеют как логически, так и физически распределенную оперативную па-мять, т.е. каждый процессорный узел владеет собственной локальной памятью.
Благодаря свойству масштабируемости MPP-системы являются лидерами по достигнутой производительности; наиболее яркий пример этому –IntelParagonс 6768 процессорами. С другой стороны, распараллеливание вMPP-системах по сравнению с кластерами, содержащими немного процессоров, является еще более трудной задачей. Приращение производительности с ростом числа процессоров довольно быстро убывает. Кроме того, достаточно трудно найти задачи, которые сумели бы эффективно загрузить множество процессорных узлов. Имеет место также проблема переносимости программ между системами с различной архи-тектурой. Эффективность распараллеливания во многих случаях сильно зависит от деталей архитектурыMPP-системы, например топологии соединения процес-сорных узлов.
Самой эффективной является топология, в которой любой узел может на-прямую связаться с любым другим узлом, но в ВС на основе MPPэто технически трудно реализуемо. Процессорные узлы в современныхMPP-компьютерах об- разуют или двумерную решетку (SNI/PyramidRM1000), или гиперкуб (как в суперкомпьютерахnCube).
Для синхронизации параллельно выполняющихся процессов необходим об-мен сообщениями, которые должны доходить из любого узла системы в любой другой узел. Поэтому важной характеристикой является диаметр системы D. В случае двумерной решеткиD~sqrt(n), в случае гиперкубаD~ln(n). Таким образом, при увеличении числа узлов более выгодна архитектура гиперкуба.
Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. В любом случае за время передачи процессорные узлы успевают выполнить много команд. Производительность процессоров растет го-раздо быстрее, чем пропускная способность каналов связи в MPP-системах, по-этому инфраструктура каналов связи является объектом пристального внимания разработчиков.
Слабым местом MPPявляется центральное управляющее устройство (ЦУУ) – при выходе его из строя вся система оказывается неработоспособной.
На рис. 13.5 показана структура MPP-системыRM1000, разработанной фирмойPyramid.
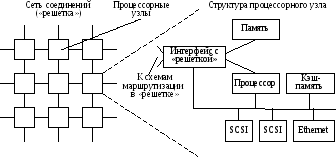
Рис. 13.5. Структура MPP-системыRM1000
В RM1000 используются микропроцессоры типаMIPS. Каждый узел со-держит процессорR4400, сетевую картуEthernetи два канала ввода/вывода типаSCSI. Реализованный вариант включает в себя 192 узла, но сеть соединений предусматривает масштабирование до 4096 узлов. Каждый узел имеет коммуни-кационный компонент для подключения к соединяющей сети, организованной по топологии двумерной решетки. Связь с решеткой поддерживается схемами маршрутизации с четырьмя двунаправленными линиями для связи с соседними узлами и одной линией для подключения к данному процессорному узлу. Ско-рость передачи информации в каждом направлении – 50 Мбит/с.
Каждый узел работает под управлением своей копии операционной сис-темы, управляет «своими» периферийными устройствами и обменивается с дру-гими узлами путем пересылки сообщений по сети соединений. Операционная система содержит средства для повышения надежности и коэффициента го-товности.
При создании MPP-систем разные фирмы отдают предпочтение различным микропроцессорам и топологиям сетей соединений (табл. 13.1).
Таблица 13.1
Основные характеристики MPP-систем
|
Фирма |
Модель |
Тип микропроцессора |
Организация соединений |
Организация памяти |
Наличие хост-компьютера |
|
Intel |
Paragon |
I860 |
Двумерная решетка |
Распределенная |
Нет |
|
IBM |
SP2 |
PowerPC 604e или Power2 SC |
Коммутатор |
Распределенная |
Нет |
|
Cray |
Cray T3D |
DEC Alpha |
Трехмерный тор |
Распределенная |
Есть |