

Uchebnoe_posobie_GLAVA_7m3
.pdfСтроки
Как уже упоминалось, массивы могут быть любого типа, но массивы типа char в ISO/ANSI C++ имеет некоторые встроенные особенности, которых нет у массивов других типов. Это связано с тем, что массив типа char – это строка. Символьная строка это последовательность символов, дополненная специальным символом «конца строки» -- ‘\0’. Этот символ иногда называют нулевым, так как все его биты заполнены значением 0. Строки, организованные подобным образом, часто называют строками в стиле С, поскольку такое определение строк впервые было представлено этом языке. В С++ существует класс String, но в ISO/ANSI C++ нет типа данных string.Возможно, это не очень удобно, но дополнительные возможности при работе с массивами типа char позволяют не очень страдать из-за его отсутствия.
Инициализация символьного массива может быть такой же как и у других массивов:
char str[9]={‘п’,’р’,’и’,’в’,’е’,’т’,’ ’,’я’,’\0’};
или быть своей собственной: char str[9]={"привет я"};
расположение элементов такого массива показано на рис. Следует обратить внимание, что при втором способе инициализации не добавлен символ конца строки, ограничивающий символ '\0' добавляется компилятором автоматически. Если его включить в строчный литерал явно, то в строке будут два нулевых символа. При работе со строковыми необходимо всегда учитывать дополнительный размер для нулевого символа.
|
|
str |
|
|
|
|
|
|
Элементы строки |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
п |
|
р |
|
и |
|
в |
|
е |
|
т |
|
|
я |
|
\0 |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
str[0] |
str[1] |
str[2] |
|
|
str[3] |
|
str[4] |
str[5] |
str[6] |
str[7] |
str[8] |
|||||||||||
Индексы элементов Каждый символ в строке занимает один байт, поэтому вместе с
ограничивающим нулевым символом строке необходимо количество байт, на единицу превышающее количество символов в ней.
Можно позволить компилятору определить длину инициализированного массива самостоятельно, не указав принудительно размер при инициализации.
char str[]={"привет я"};
В ISO/ANSI C++ существуем много достаточно много функций обработки строковых. С некоторыми, наиболее распространѐнными можно
познакомится в таблице. Для работы с ними необходимо подключить заголовочный файл string.h
Заголовок функции |
Примечание |
|
|
|
|
|
|
|
char* strcat(char* str1, char* str2); |
К строке str1 добавляется строка str2 |
|||||||
|
результат str1+ str2 |
|
|
|
|
|||
char* strchr(char* str1, int sim); |
Возвращается |
указатель |
на |
первое |
||||
|
вхождение символа sim в строке str1, |
|||||||
|
NULL если не найден |
|
|
|
||||
int strcmp(char* str1, char* str2); |
Сравниваются 2 строки, если str1> |
|||||||
|
str2 результат >0, str1== |
str2 |
— |
|||||
|
=0,иначе <0 |
|
|
|
|
|
|
|
char* strcpy(char* str1, char* str2); |
Копирует str2 в str1 и его возвращает |
|||||||
int stricmp(char* str1, char* str2); |
Делает то же, что и strcmp, но считает |
|||||||
|
заглавные |
и |
прописные |
буквы |
||||
|
эквивалентными |
|
|
|
|
|||
int strlen(char* str); |
Возвращает длину строки str без ‘\0’ |
|||||||
char* strlwr(char* str); |
Переводит заглавные в строчные |
|
||||||
char* strstr(char* str1, char* str2); |
Возвращает |
указатель |
на |
первое |
||||
|
вхождение подстроки str2 в строку |
|||||||
|
str1 |
|
|
|
|
|
|
|
double strtod(char* nprt, char** end); |
Преобразует строку nprt в значение |
|||||||
|
типа double, очень часто end== |
|||||||
|
NULL, |
а строка |
nprt |
имеет |
вид: |
|||
|
[пробелы][знак][цифры][,цифры][{d| |
|||||||
|
D|e|E}[знак][цифры]. Первый символ, |
|||||||
|
не |
соответствующий |
|
форме |
||||
|
прерывает преобразование. |
|
|
|||||
long strtol(char* nprt, char** end, int |
Преобразует строку nprt в значение |
|||||||
base); |
типа long, очень часто end== NULL, а |
|||||||
|
строка |
|
nprt |
имеет |
|
вид: |
||
|
[пробелы][знак][0][x][цифры]. |
|
||||||
|
Первый символ, не соответствующий |
|||||||
|
форме |
прерывает |
преобразование. |
|||||
|
Если значение 2<= base<=32, оно |
|||||||
|
используется как система счисления, |
|||||||
|
если ==0, то интерпретация идет по |
|||||||
|
первым двум символам 0+(1-7) 8- |
|||||||
|
ричная, 0х-16ти ричная. |
|
|
|
||||
char* strtok(char* str1, char* str2); |
Находится |
|
первое |
вхождение |
||||
|
разделителя из строки str2 в строке |
|||||||
|
str1, если надо найти следующее |
|||||||
|
слово надо снова вызвать функцию |
|||||||
|
str1== NULL |
|
|
|
|
|
||
char* strupr(char* str); |
Переводит строчные в заглавные |
|
||||||
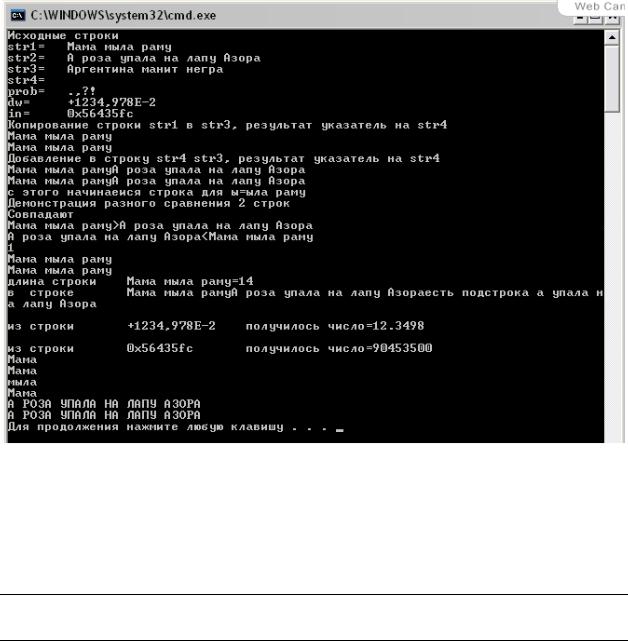
Пример реализации приведенных в таблице функций:
#include <iostream> #include <string.h> using namespace std; int main(void)
{ setlocale(NULL,"Russian");
char str1[80]={"Мама мыла раму\0"}; char str4[80]={""};
char str2[80]={"А роза упала на лапу Азора\0"}; char str3[80]={"Аргентина манит негра\0"}; char *str_r;
char prob[]={".,?! \0"};
char dw[80]={"+1234,978E-2\0"}; char in[80]={"0x56435fc\0"}; long i,l;
double d;
cout<<"Исходные строки \n"; cout<<"str1=\t"<<str1<<endl; cout<<"str2=\t"<<str2<<endl; cout<<"str3=\t"<<str3<<endl; cout<<"str4=\t"<<str4<<endl; cout<<"prob=\t"<<prob<<endl; cout<<"dw=\t"<<dw<<endl; cout<<"in=\t"<<in<<endl;
cout<<"Копирование строки str1 в str3, результат указатель на str4\n";
str_r=strcpy(str4,str1); cout<<str_r<<endl<<str4<<endl;
cout<<"Добавление в строку str4 str3, результат указатель на str4\n";
str_r=strcat(str4,str2); cout<<str_r<<endl<<str4<<endl; str_r=strchr(str1,'ы');
cout<<"с этого начинаеися строка для ы="<<str_r<<endl; cout<<"Демонстрация разного сравнения 2 строк\n"; if(strcmp(str1, str1)==0)
cout<<"Совпадают\n"; if(strcmp(str1, str2)>0) cout<<str1<<">"<<str2<<endl; if(strcmp(str2, str1)<0) cout<<str2<<"<"<<str1<<endl;
cout<<"Возврат номера для любых совпадающих символов из строк str1 и str3\n";
i=strcspn(str1,str3);
cout<<"совпавший символ\t="<<str1[i]<<" №= "<<i<<endl; i=strlen(str1);
cout<<"длина строки\t"<<str1<<"="<<i<<endl;
cout<<"поиск совпадения подстроки str2 начиная с 5 позиции в строке str4\n";
str_r=strstr(str4,str2+5);
cout<<"в строке\t"<<str4<<"\nесть подстрока "<<str_r<<endl; d=strtod(dw,NULL);
cout<<"\nиз строки\t"<<dw<<"\tполучилось число="<<d<<endl; l=strtol(in,NULL,0);
cout<<"\nиз строки\t"<<in<<"\tполучилось число="<<l<<endl; cout<<"Поиск указателя на разделитель из prob в str1\n"; str_r=strtok(str1, prob);
cout<<str_r<<endl<<str1<<endl;
cout<<"str1 необратимо испорчена, но можно найти следующие слова\n";
str_r=strtok(NULL, prob); cout<<str_r<<endl<<str1<<endl;
cout<<"st1 необратимо испорчена, но можно найти следующие слова\n";
str_r=strtok(NULL, prob); cout<<str_r<<endl<<str1<<endl; cout<<"Перевод в заглавные буквы\n"; str_r=strupr(str2); cout<<str_r<<endl<<str2<<endl; cout<<"Перевод в маленькие буквы\n"; str_r=strlwr(str2); cout<<str_r<<endl<<str2<<endl;
}
Результат работы программы:
Массивы, которые определялись до сих пор, имеют один индекс и называются одномерными массивами. Но массив может иметь и более одного индексного значения — в этом случае он называется многомерным массивом. Аналогом двухмерного массива можно рассматривать матрицы (тензоры).
Объявление двухмерного статического массива имеет вид: тип_элементов имя_массива[конст_1][конст_2],
где конст_1 – это размер по строкам (количество строк) , а конст_2 – количество элементов в строке, то есть размер по столбцам или количество столбцов.
По аналогии можно объявить трех- и более мерные массивы. В Microsoft Visual Studio 2008 даже объявление 10-ти мерного массива не вызывает проблемы, проверить возможность использования массива с большей мерностью у автора не хватило терпения.
Массивы хранятся в памяти так, что самый правый индекс растет быстрее всего. Пример массива data[2][4] рассмотрен на рис.
Элементы массива располагаются в непрерывном блоке памяти, как показано стрелочками на рис. 4.4. Первый индекс выбирает определенную строку внутри массива, а второй индекс выбирает элемент внутри строки.
data[0][0] |
data[0][1] |
data[0][2] |
data[0][3] |
|
|
|
|
data[1][0] |
data[1][1] |
data[1][2] |
data[1][3] |
|
|
|
|
Рис. 4.4. Организация массива data[2][4]
Следует обратить внимание, что двумерный массив в родном C++ – на самом деле одномерный массив, состоящий из одномерных массивов. Массив с тремя измерениями в родном C++ – это одномерный массив элементов, в котором каждый элемент представляет собой одномерный массив одномерных массивов. Большую часть времени программисту не придется об этом беспокоиться. Из сказанного следует, что для массива, показанного на рис. выражения data[0], data[1] представляют одномерные массивы.
Для того чтобы инициализировать многомерный массив, используется расширенный метод инициализации одномерных массивов. Например, вы можете инициализировать двумерный массив data с помощью следующего объявления:
long data[2][4] = {{1,2,3, 5}, {7, 11, 13, 17} };
То есть, инициализация значений каждой строки массива содержится внутри собственной пары фигурных скобок. Поскольку в каждой строке четыре элемента, в каждой группе присутствует по четыре значения инициализации, и поскольку строк всего две, внутри скобок находится две группы инициализирующих значение, разделенных запятой.
Вы можете пропустить инициализацию значений в любой строке, в этом случае остальные элементы массива инициализируются нулевыми значениями, например:
long data[2] [4] = { { 1, 2, 3},{ 7, 11 } };
В этом примере списки инициализации не полны. Элементы data[0][3], data[1][2] и data[1][3] не получают инициализирующих значений и потому равны нулю.
Если есть желание инициализировать весь массив нулевыми значениями, его можно реализовать просто:
long data[2] [4] = {0};
Если происходит инициализация массива с большим числом измерений, необходимо помнить, что надо указать столько вложенных фигурных скобок для групп инициализирующих значений, сколько в массиве измерений.

Если вспомнить о динамическом выделении памяти под массив, то необходимо, вывести соответствие между указателем и многомерным массивом.
Рассмотрим двухмерный массив: как уже говорилось это одномерный массив одномерных массивов. Если одномерный массив это указатель, то двухмерный массив – указатель на указатель, то есть двойной указатель.
Для работы с двухмерным динамическим массивом потребуется: тип_элемента **имя_массива;
При динамическом выделении памяти под двухмерный массив можно пользоваться двумя разными путями.
Первый : можно представить его как одномерный массив длинно n*m, где n
— количество строк, а m — количество столбцов. Сложность только в соотношении привычного представления индексации элементов массива Аij ,
использовать A[i][j] не получится, так как эта запись применима только к двойным указателям, но можно использовать зависимость глубины расположения элементов такого вида: A[i*m+j]. Здесь один индекс зависит от i-строки и j-го столбца.
Рассмотрим пример программы с такой реализацией массива.
#include <iostream>
#include <stdlib.h> // заголовочный файл функций для генерации чисел
#include <time.h>// заголовочный файл функций для функции time()
using namespace std;
// прототипы функций
void zap_mas(int mas[],int n,int m,int min,int max);
//функция заполнения массива случайными числами в диапозоне от min до max
void print_mas(int mas[],int n,int m); // вывода массива на экран int sun_d_mas(int mas[],int n,int m);
//расчет суммы элементов, стоящих на глаdной диагонале i==j
//описания функций
void zap_mas(int mas[],int n,int m,int min,int max) {int i,j;
//для работы с 2-х мерным масивом требуются 2 вложенных цикла
//первый изменяет индекс для строк, второй для столбцов
for( i=0;i<n;i++) for(j=0;j<m;j++)
mas[i*m+j]=rand()%(max-min+1)+min;
// заполнене элемента случайным образом
}
void print_mas(int mas[],int n,int m) {int i,j;
{// вывод на экран, между элементами одной строки ‘\t’, строки разделяются ‘\n’
for( i=0;i<n;i++)
{
for(j=0;j<m;j++) cout<<mas[i*m+j]<<"\t";
cout<<endl;
}
}
int sun_d_mas(int mas[],int n,int m)
{
int i,sum=0; // переменная для суммы int k=n;
/* Необходимо учитывать, что считать элементы можно пока i<n и j<m,так как для главной диагонали i==j, то используемый индекс должен быть <n <m, k будет минимальным из этих чисел. */
if(k<m) k=m;
/* нужно использовать один индекс, так как другие элементы нас не интересуют, следовательно используется один цикл*/
for( i=0;i<k;i++) sum+=mas[i*m+i];
return sum;
}
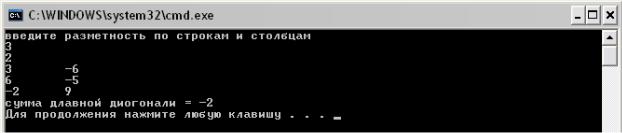
int main(void)
{
setlocale(NULL,"Russian"); // подключение кодировочной таблицы
int *A,n,m;
srand(time(NULL)); // подготовка работы генератора случайных чисел
cout<<"введите разметность по строкам и столбцам\n"; cin>>n>>m;
A=new int[n*m]; // выделение памяти под массив zap_mas(A,n,m,-10,10); // заполнение массива от -10 до 10 print_mas(A,n,m); // вывод на экран
// расчет суммы элементов главной диагонали
cout<<"сумма длавной диогонали = "<<sun_d_mas(A,n,m)<<endl; delete[] A; // удвление памяти
}
Результат работы программы имеет вид:
В коде необходимо пояснить строки, связанные с генерацией случайных чисел:
srand(time(NULL)); и mas[i*m+j]=rand()%(max-min+1)+min;
srand() подготавливает генерацию случайных чисел, без этой функции генератор будет выдавать одни и те же числа при разных запусках программы. Параметром генератора может быть 1 или любое достаточно большое положительное число, в данном примере используется результат работы функции time(NULL) который возвращает число секунд прошедших с момента 00:00:00 по Гринвичу 1 января 1970 года. Параметр NULL говорит о том, что этот результат не надо сохранять в переменную.
Функция rand() возвращает случайные числа в диапазоне [0, MAX_INT]. Операция % позволяет сузить этот диапазон до [0, max-min]. Потом этот диапазон сместится на [min, max], так как к обоим его частям приплюсуется min (0+min=min, max-min+min=max). В результате этого элементы массиваы будут принимать значания от min до max.
Второй способ требует усилий при выделении памяти, необходимо вначале выделить память под массив указателей на строки, а потом для каждого указателя строки выделить память для элементов каждой строки. Это даст возможность обращаться к элементам массива A[i][j], но кроме выделения памяти потребует в конце работы программы удалить выделенную память (количество использованных операторов new должно соответствовать количеству использованных delete). В этом методе удобно написать функции удаления и выделения памяти под массив. Но они потребуют обязательно вернуть как результат указатель на измененную память, в процессе работы программы.
#include <iostream> #include <stdlib.h> #include <time.h>> using namespace std;
// прототипы функций
int** new_mas(int n,int m); // выделения памяти под массив int** del_mas(int *mas[],int n); // освобождения памяти void zap_mas(int *mas[],int n,int m,int min,int max);
void print_mas(int *mas[],int n,int m); int sun_d_mas(int *mas[],int n,int m);
// описания функций int** new_mas(int n,int m) { int **mas;
/* для выделеня требуется локальный указатель, так как в параметрах указателя нет, Microsoft Visual Studio 2008 не позволяет использовать неинициализированный указатель*/
mas=new int*[n]; // выделение памяти под массив строк for(int i=0;i<n;i++) // для каждой строки
mas[i]=new int [m]; // выделение памяти под массив элементров return mas; // возврат на начало выделенной памяти
}
int** del_mas(int *mas[],int n)
{
for(int i=0;i<n;i++) // для каждой строки
{
delete[] mas[i]; // удаление памяти выделенной на строку mas[i]=0;
}
delete[] mas; // удаление памяти выделенную на массив mas=0;
return mas; // возврат указателя, он равен 0
}
void zap_mas(int *mas[],int n,int m,int min,int max) {int i,j;
for( i=0;i<n;i++) for(j=0;j<m;j++)
mas[i][j]=rand()%(max-min+1)+min;
}
void print_mas(int *mas[],int n,int m) {int i,j;
for( i=0;i<n;i++)
{
for(j=0;j<m;j++) cout<<mas[i][j]<<"\t";
cout<<endl;
}
}
int sun_d_mas(int *mas[],int n,int m)
{
int i,k=n,sum=0; if(k>m) k=m; for( i=0;i<k;i++)
sum+=mas[i][i]; return sum;
}