

1.3. Решение задачи
Решение задачи: определим рекурсивную функцию с мемоизацией, вычисляющую значение основного функционального уравнения. Функция считает значение выигрыша на текущем этапе, изменяет состояние и рекурсивно вызывается для расчетов на следующем этапе. На каждом этапе перебираются все возможные управления, и то, значение выигрыша при котором было минимальным, сохраняется в качестве наилучшего.
best_w = None
best_u = None
for ui in self.u:
# Если этап последний, то учитываем, какая температура будет после него.
if stage == 11:
final_t = round(self.phi(ui, state, self.Tout[stage]), 1)
wi = round(self.w(self.alpha, self.b[stage], final_t, self.c[ui]), 2)
else:
wi = round(self.w(self.alpha, self.b[stage], state, self.c[ui]) + \
self.W(stage + 1, round(self.phi(ui, state, self.Tout[stage]), 1))[0], 2)
Функции расчета выигрыша и нового состояния:
def w(self, alpha, is_at_home, current_T, heat_cost):
"""
Возвращает выигрыш: сумму дискомфорта пользователя и стоимость
режима работы.
"""
return is_at_home * alpha * pow(18 - current_T, 2) + (1 - alpha) * heat_cost
def phi(self, heat, current_T, Tout):
"""Возвращает новое состояние: температуру в доме."""
return current_T + 0.5 * (heat - 0.2 * (current_T - Tout))
Сохранение происходит следующим образом:
self.W_cache[stage][state] = (best_w, best_u)
где stage – номер этапа, state – текущее состояние, температура на начало этапа. Таким образом получаем 1 значение для первого этапа, лучшее среди возможных. Затем 6 для следующего (лучшее для каждого из вариантов предыдущего этапа), затем 36 и так далее по степеням 6. Но на самом деле, благодаря мемоизации количество сохраненных значений оказывается значительно меньше (так как, если для этапа и состояния были произведены расчеты, то берется значение из памяти).
if state in self.W_cache[stage]:
return self.W_cache[stage][state]
Это значительно ускоряет работу программы (для последнего этапа имеем 339 вариантов, а не 2 миллиарда).
Для последнего этапа считаем состоянием не ту температуру, которая имеется на момент этапа, а ту, которая будет при происшествии этапа. Это сделано потому, что в ином случае значение выигрыша будет зависеть только от стоимости режима работы обогревателя, поэтому всегда будет выбираться режим нулевой стоимости.
Функция restore_optimal() восстанавливает оптимальный план по цепочке состояний: получаем лучший режим работы для первого этапа, считаем новое состояние, и для следующего этапа находим лучший режим по состоянию, и так далее.
def restore_optimal(self):
# Массив режимов работы в каждый час.
control = []
# Массив температуры на начало каждого этапа.
temperature = []
# Начальная температура.
state = 18
for stage in range(len(self.b)):
temperature.append(state)
# Значение не персчитывается, так все они были записаны.
u = self.W(stage, state)[1]
control.append(u)
state = round(self.phi(u, state, self.Tout[stage]), 1)
return control, temperature, state
Коэффициент зададим равным 0,8. То есть, в большем мере будем учитывать дискомфорт пользователя. Результат:
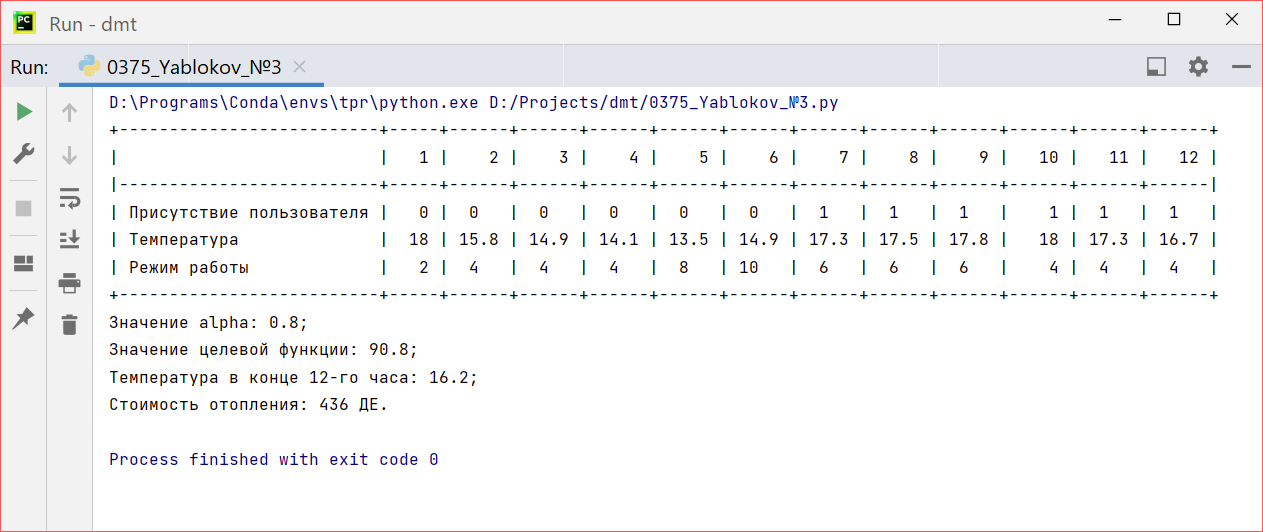
Рисунок 1 – Результаты решения при

При таком значении коэффициента дискомфорт оказывает сильное влияние на целевую функцию, поэтому в момент присутствия пользователя средняя температура в доме составляет 17,4 градуса по Цельсию. Также, можно заметить, что на шестом этапе включается самый мощный режим отопления, чтобы быстро нагреть дом перед приходом пользователя. Таким образом наглядно виден принцип ДП, когда на текущем выбирается управление, приводящее к максимальному выигрышу на всех оставшихся этапах.