

Парная регрессия в Statistica
.pdf2.4. Выполнение задания в пакете Statistica
ЗАДАЧА № 1 |
Тема: Парная регрессия |
1.Проведите качественный анализ связей экономических переменных, выделив зависимую и независимую переменные (если они не указаны).
2.Вычислите основные числовые характеристики переменных модели.
3.Постройте поле корреляции результата и фактора, сформулируйте гипотезу о виде связи (линейная или нелинейная; для нелинейной предложите конкретный вид)
4.Рассчитайте линейный коэффициент корреляции, определите его значимость при α=0,05.
5.Постройте интервальную оценку линейного коэффициента корреляции (с надежностью – 95%).
6.Определите параметры уравнения парной линейной регрессии и дайте интерпретацию коэффициентов регрессии.
7.С вероятностью 0,95 оцените статистическую значимость уравнения регрессии в целом и каждого параметра.
8.Отобразите на поле корреляций теоретически рассчитанную линию регрессии.
9.Постройте доверительную область для линии регрессии.
10.Оцените качество построенной модели через среднюю относительную ошибку аппроксимации. Определите среднеквадратическую ошибку модели.
11.Определите средний коэффициент эластичности.
12.Дайте экономическую интерпретацию построенной модели.
13.Рассчитайте параметры одной из функций регрессии (в соответствии с выдвинутой гипотезой (п.2):
степенной; показательной; гиперболической; экспоненциальной.
Выполните задания пп.6 – 12 для нелинейной модели.
14.Выберете лучшую из моделей (п.5 или п.13), выбор обоснуйте.
15.С надежностью 0,95 постройте доверительный интервал ожидаемого значения результативного признака в предположении, что значение признака-фактора увеличится на 5% относительно своего среднего уровня.
Пример 3.
По 7 областям региона известны данные о расходах на покупку продовольственных товаров (% от общего объема расходов) – y, среднемесячная заработная плата одного работающего (тыс.руб.) – x.
Таблица 2.1
Номер региона |
y |
x |
1 |
68.8 |
4.5 |
2 |
58.3 |
5.9 |
3 |
62.6 |
5.7 |
4 |
52.1 |
7.2 |
5 |
54.5 |
6.2 |
6 |
57.1 |
6.0 |
7 |
51.0 |
7.8 |
1.Проведите качественный анализ связей экономических переменных, выделив зависимую и независимую переменные (если они не указаны).
Внашем примере, очевидно, что доля расходов на покупку продовольственных товаров (y) будет зависеть от среднемесячной заработной платы
(x).
Запустим программу Statistica и создадим пустую таблицу. В таблицу внесем данные (или импортируем, или скопируем из исходной таблицы Excel и вставим). Введем имена переменных и имена наблюдений (последние в нашем случае – номера объектов). Вид таблицы с исходными данными представлен на рис. 2.4.
Рис. 2.4. Таблица с исходными данными
34

2.Вычислите основные числовые характеристики переменных модели.
Определим основные статистические показатели переменных. Для этого в программе Statistica необходимо выполнить коман-
ду: Анализ → Основные статистики и таблицы→Описательные статистики→ ОК (рис. 2.5).
В диалоговом окне Описательные статистики (рис. 2.6)
нажмем на кнопку Переменные и в появившемся окне выберем переменные x и y → ОК
Рис. 2.5. Окно вызова модулей для расчета основных характеристик.
Далее стартовом окне модуля
Описательные статистики отметим ос-
новные статистические характеристики: Число наблюдений, Среднее, Стандартное отклонение, Дисперсия(рис.2.6) → ОК
Рис. 2.6. Окно Описательные статистики.
В результате появится таблица, содержащая основные статистические характеристики переменных (рис. 2.7)
Рис. 2.7. Основные характеристики переменных модели
3. Постройте поле корреляции результата и фактора, сформулируйте гипотезу о виде связи (линейная или нелинейная; для нелинейной предложите конкретный вид)
Для построения поля корреляций выполним команду Графика→ Диаграммы рассеяния. В результате появится стартовое окно построения графика (рис. 2.8)
35

Нажмем кнопку Переменные. В окне выбора переменных укажем наши переменные. Перейдя
на вкладку Дополнительно, можем включить линейную подгонку и запросить дополнительные статистики – характеристики подгонки. → ОК
Рис. 2.8. Стартовое окно построения диаграммы рассеяния
В результате получим график исходных точек рассеяния и регрессионной прямой, плюс к этому – формулу для уравнения регрессии и некоторые характеристики линейной модели (рис.
2.9).
Глядя на диаграмму рассеяния, можно предположить, что нелинейная форма модели может быть степенной функцией (2), экспоненциальной (4) или гиперболической (5).
Рис. 2.9. Диаграмма рассеяния с подгоночной прямой регрессии
4.Рассчитайте линейный коэффициент корреляции, определите его значимость при α=0,05.
Для вычисления парных корреляций необходимо включить другой тип анализа: Анализ → Основные статистики и таблицы→ Парные и частные корреляции→ ОК (см. рис. 2.5). В появившемся окне (рис. 2.10)
нажмем кнопку Квадратная матрица, в диалоговом окне выбора переменных отметим переменные x и y → ОК.
Вернувшись в стартовое окно, нажимаем кнопку Матрица парных корреляций. В результате получим таб-
лицу (рис. 2.9).
36

Рис. 2.10. Стартовое окно для вычисления |
Рис. 2.11. Матрица парных корреляций |
|
коэффициента парной корреляции |
||
|
Значение парного коэффициента корреляции ryx= - 0,94 показывает тесную связь результативного признака y и признака-фактора x. Знак «минус» указывает, что связь между переменными - обратная, т.е. при увеличении переменной-фактора x переменная-результат y будет уменьшаться. Программа Statistica выделяет значимые на 95%-ном уровне корреляции красным цветом.
«Вручную» значимость корреляционной связи можно подтвердить проверкой гипотезы:
альтернативной - H1: r≠0 с помощью статистики |
|
|
|
|
|
|
|
|
|
|
|
, которая при выполнении нулевой гипотезы |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|||||||||||
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
имеет распределение Стьюдента с k=(n-2) степенями свободы.
Для нашего примера n=7, тогда k=7-2=5. Критическое значение показателя 




 может быть вычислено с помощью вероятностного калькулятора. В программе Statistica для этого надо выполнить команду:
может быть вычислено с помощью вероятностного калькулятора. В программе Statistica для этого надо выполнить команду:
Анализ → Вероятностный калькулятор → Распределения (рис. 2.12)
Рис. 2.12. Окно вероятностного калькулятора
После ввода всех необходимых параметров нажать кнопку Вычислить. Критическое значение 








 Выборочная t-статистика, рассчитанная для парного коэффициента корреляции,
Выборочная t-статистика, рассчитанная для парного коэффициента корреляции, 


 . Так как выборочное значение t-статистики больше критического, то гипотеза H0 отклоняется. Коэффициент корреляции признается статистически значимым (отличным от нуля).
. Так как выборочное значение t-статистики больше критического, то гипотеза H0 отклоняется. Коэффициент корреляции признается статистически значимым (отличным от нуля).
5.Постройте интервальную оценку линейного коэффициента корреляции с надежностью 95%.
Интервальную оценку для коэффициента корреляции удобнее провести в программе Excel. Для этого воспользуемся алгоритмом, изложенным в п. 2.1.
37

Расчет интервальной оценки для коэффициента корреляции
Переменная |
Формула |
Фунция Excel |
Результат |
|
вычислений |
||||
|
|
|
||
|
|
|
|
|
σz |
1/(n-3) |
|
0,2 |
|
tкр |
|
- СТЬЮДРАСПОБР(0,05; n-2) |
-2,571 |
|
r |
|
|
-0,94 |
|
z |
1/2*ln((1+r)/(1-r)) |
ФИШЕР(r) |
-1,738 |
|
z1 |
z + tкр* σz |
|
-1,224 |
|
z2 |
z - tкр* σz |
|
-2,252 |
|
r1 |
th (z1) |
ФИШЕРОБР(z1) |
-0,841 |
|
r2 |
th (z2) |
ФИШЕРОБР(z2) |
-0,978 |
Обратите внимание на то, что коэффициент линейной корреляции имеет отрицательное значение. Поэтому квантиль распределения Стьюдента - граница левосторонней критической области, т.е. его значение - критическая точка, взятая со знаком «минус» (Excel вычисляет всегда правую критическую точку). Соответственно, и формулы для интервальной оценки z поменяются местами. Значения границ интервала r1 и r2 могут быть вычислены как по формуле (th(z) – тангенс гиперболический) или с помощью функции Excel – ФИШЕРОБР(z).
В результате получили, что интервальной оценкой линейного коэффициента корреляции является интер-
вал (-0,978; -0,841), т.е. - 0,978 < r < - 0,841, с надежностью 95%.
6. Определите параметры уравнения парной линейной регрессии и дайте интерпретацию коэффициентов регрессии.
Строим линейную модель парной регрессии:
Выполнив команду Анализ → Множественная регрессия, запустим модуль для построения модели парной линейной регрессии (парная регрессия – частный случай множествен-
ной). В окне Множественная регрессия (рис.
2.13), нажав на кнопку Переменные, попадем в окно выбора переменных для анализа (рис. 2.14).
Рис. 2.13. Стартовое окно модуля Множественная регрессия
В окне Списки зависимых и независимых переменных слева следует указать зависимую переменную y, а справа – независимую переменную-фактор x. Подтверждаем определения переменных - ОК .
38

Рис. 2.14. Определение переменных для регрессионного анализа
Встартовом окне Множественная регрессия, куда мы возвратились, нажать кнопку ОК.
Витоге откроется окно результатов множественной регрессии (рис. 2.15).
Окно результатов анализа имеет следующую структуру: верх окна - информационный. В нем содержатся краткие сведения о результатах анализа. Нижняя часть окна представляет набор вкладок с кнопками для всестороннего изучения построенной модели.
Рис. 2.15 Окно результатов парной линейной регрессии
Информационная часть окна Результаты множественной регрессии содержит следующие сведения: Зав. перем. - имя зависимой переменной (y);
Число набл. - число наблюдений, по которым построена регрессия (n=7);
Множест. R - коэффициент множественной корреляции (описывает степень линейной зависимости между y и фактором x); в данном случае парной линейной регрессии он равен модулю коэффициента корреля-
ции (R=0,94216123);
R2 - квадрат коэффициента множественной корреляции - коэффициент детерминации (R2=0,88764894);
39

Скоррект. R2 -- скорректированный коэффициент детерминации (R2ск =0,86517873);
Стандартная ошибка оценки - среднее квадратическое отклонение ошибок наблюдений. Она является мерой рассеяния фактических значений относительно полученной линии регрессии (Se=2,294970397). F - выборочное значение F-статистики (Fв=39,50336).
cc - число степеней свободы для F-статистики. В нашем примере (k1=1,k2=5). р - вычисленный уровень значимости для F-статистики (p=0,001498).
В последней строке верхней части информационного окна приводятся данные о свободном члене уравнения регрессии:
-Своб. член - оценка свободного члена регрессии (b0=91,916794979);
-Ст. ошибка - стандартная ошибка оценки свободного члена (Sb0=5,501343);
-t(n - к) - выборочное значение t-статистики для b0 (t(5)=16,708);
-p - вычисленный по выборке уровень значимости для коэффициента b0 (p=0,000).
Во второй (нижней) части информационного окна высвечивается значимый стандартизованный регрессионный коэффициент β (x бета); он вычисляется по формуле
где  и
и  - оценки среднеквадратических отклонений для переменных x и y.
- оценки среднеквадратических отклонений для переменных x и y.
При нажатии кнопки Итоговая таблица регрессии Ststistica выдает две таблицы с результатами анализа: Итоговые статистики - таблицу, в которй отражены основные показатели из информационного окна; таблицу Итоги регрессии для зависимой переменной: y - значения и характеристики коэффициентов регрес-
сии (рис. 2.16).
Рис. 2.16. Итоги регрессии.
В первом столбце указаны переменные, коэффициенты при которых охарактеризованы в таблице: Свободный член – у нас коэффициент b0, и коэффициент при переменной x – у нас коэффициент b1. Далее в соответствующей строке содержатся характеристики, рассчитанные для каждого из коэффициентов.
Во втором столбце таблицы (БETA) выводится стандартизованный коэффициент регрессии 

 . С помощью него можно записать стандартизованное уравнение регресии:
. С помощью него можно записать стандартизованное уравнение регресии:
Стандартизированные коэффициенты регрессии - безразмерные величины. В случае множественной регрессии стандартизованные коэффициенты регрессии используются для сравнения влияния на зависимую переменную факторов, имеющих различную размерность.
В третьем столбце (Стд.Ош.БЕТА) - стандартные отклонения стандартизованного коэффициента .
40

Вчетвертом столбце (В) приведены МНК-оценки коэффициентов регрессии: b0 и b1:
Впятом столбце (Стд.Ош.B) - стандартные отклонения:
.
Вшестом столбце - t-статистики для проверки гипотезы H0: bi=0
Вседьмом столбце - соответствующие уровни значимости
Таблица Итоговые статистики (рис.2.16) содержит данные, которые обсуждались выше (см. Информационную часть окна).
Уравнение регрессии имеет вид:
Коэффициент детерминации R2=0,8876. Это означает, что почти 89% вариации результативного признака y объясняется данным уравнением регрессии.
7. С вероятностью 0,95 оцените статистическую значимость уравнения регрессии в целом и каждого параметра.
а) Проверим значимость уравнения регрессии в целом.
Проверяемая гипотеза: H0: R2=0; альтернативная гипотеза: H1: R2≠0
Проверка осуществляется с помощью F-статистики. F-статистика представляет собой отношение двух дисперсий, приходящихся на одну степень свободы: дисперсии, объясненной регрессией 
 и дисперсии остатков
и дисперсии остатков
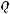





 :
:
Можно показать, что при выполнении основного дисперсионного отношения 



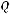 указанная статистика может быть представлена в виде
указанная статистика может быть представлена в виде
При выполнении нулевой гипотезы F-статистика имеет распределение Фишера с k1=p и k2=n-p-1 степенями свободы. Для нашего примера n=7, p=1 (число факторов), тогда k1=1; k2=7-1-1=7-2=5.
Критическое значение показателя




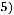 может быть вычислено с помощью вероятностного калькулятора: Анализ → Вероят-
может быть вычислено с помощью вероятностного калькулятора: Анализ → Вероят-
ностный |
калькулятор |
→ Распределения |
(рис.2.17). |
В результате |
получаем, что значение |
|
|
. |
Так как вычисленное выборочное значение критерия FВ >Fкр (39,503 > 6,608), то гипотеза H0 отклоняется. Уравнение в целом признается значимым.
Рис.2.17. Вычисление Fкр с помощью Вероятностного калькулятора
41

Нажав на кнопку Дисперсионный анализ, можем подробно рассмотреть составляющие, с помощью которых вычисляется F-статистика (рис.2.18).
Рис. 2.18. Таблица дисперсионного анализа
В таблице Дисперсионный анализ в первом столбце прописаны составляющие диспесии зависимой переменной: Регресс. – объясненная регрессией, Остатки - необъясненная часть вариации, Итого - общая вариация.
Во втором столбце Сумма квадратов вычислены суммы квадратов отклонений для каждой составляющей -




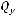 . В третьем столбце – сс - указано число степеней свободы для каждой составляющей. Четвертый столбец - Средн. квадрат - содержит суммы квадратов, приходящиеся на одну степень свободы. Далeе приводится значение вычисленной F-статистики – частное от деления первого значения предыдущего столбца на торое. В последнем столбце p-уров. вычисляется вероятность ошибки 1-го рода для вычисленной статистики FВ.
. В третьем столбце – сс - указано число степеней свободы для каждой составляющей. Четвертый столбец - Средн. квадрат - содержит суммы квадратов, приходящиеся на одну степень свободы. Далeе приводится значение вычисленной F-статистики – частное от деления первого значения предыдущего столбца на торое. В последнем столбце p-уров. вычисляется вероятность ошибки 1-го рода для вычисленной статистики FВ.
б) Для проверки значимости коэффициентов уравнения регрессии используется t-статистика Стьюдента, которая вычисляется для каждого коэффициента:
,
где bi – числовое значение коэффициента, Sbi – его среднеквадратическое отклонение (в таблице – Стд. Ош.В, рис. 2.16 ); tв для каждого коэффициента представлены в таблице в столбце t(5). Если выполняется гипотеза H0: bi=0, то вычисленное значение t-статистики по модулю должно быть меньше критического значения tкр=t(0,95; n-p- 1)=t(0,95; 5). В этом случае коэффициенты признаются незначимыми (равными нулю). С помощью вероятностного калькулятора находим tкр=2,0128. Вычисленные для коэффициентов статистики 










 Оба значения по модулю больше tкр, следовательно, оба коэффициента признаются статистически значимыми (отличными от нуля).
Оба значения по модулю больше tкр, следовательно, оба коэффициента признаются статистически значимыми (отличными от нуля).
8.Отобразите на поле корреляций теоретически рассчитанную линию регрессии
Вокне Результаты множественной регрессии (рис. 2.15) перейдем на вкладку Остатки/ предсказан-
ные/ наблюдаемые значения, выберем кнопку Анализ остатков. В результате появится одноименное окно (рис.
2.19).
Рис. 2.19. Окно Анализ остатков
42

В этом окне нажатие на кнопку Остатки и предсказанные выводит таблицу, в которой во втором столбце приводятся исходные данные для переменной  (Наблюд. значение), во втором – теоретически рассчитанные по уравнению регрессии значения переменной
(Наблюд. значение), во втором – теоретически рассчитанные по уравнению регрессии значения переменной  (Предск. значение), в третьем – значения ошибки
(Предск. значение), в третьем – значения ошибки 



 (Ос-
(Ос-
татки).
Предсказанные значения и остатки (2 и 3 столбцы) скопируем в исходную таблицу данных (без последних четырех строк – итоговых статистик). Присвоим имена введенным переменным: YY для предсказанных значений зависимой переменной, Е – для остатков. В результате исходная таблица примет вид, изображенный на рис.
2.21
Рис. 2.20. Таблица предсказанных значе- |
Рис. 2.21. Вид исходной таблицы со встав- |
|
ний |
и остатков |
ленными данными |
Для добавления линии регрессии на диаграмму рассеяния выполним следующие действия:
1)В рабочей книге слева, где изображена ее структура в виде дерева, выберем построенную Диаграмму рассеяния.
2)Щелкнув правой кнопкой на одной из точек графика, и выбрав в выпадающем меню команду Свойства…, попадаем в окно Общие настройки (рис.2.22). Выберем кнопку Новый график. В результате появится диалоговое окно, в котором надо указать тип графика, название и количество данных, по которым он будет строиться (рис. 2.23)
Рис. 2.22. Окно Общие настройки графика
При нажатии на кнопку подтверждения ОК, появится окно добавления нового графика (рис. 2.23). Указываем в нем тип графика, его имя, количество добавляемых графиков, количество данных (точек). Подтверждаем введенные данные. В результате появится таблица редактирования данных графика с двумя пустыми столбцами.
Рис. 2.23 Добавление нового графика
43