

Энциклопедия PC
.pdf3.3. Пространствоввода-вывода 77
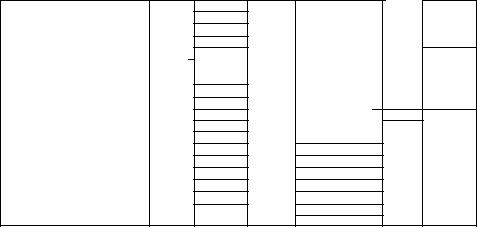
AT иPS/2 |
PC/XT |
Назначение |
OFO-OFF |
|
Сопроцессор80287 |
100-1EF |
|
PS/2 управлениемикроканалом |
170-177 |
|
КонтроллерНЖМД#2 (ЮЕ#2) |
1FO-1F7 |
|
КонтроллерНЖМД#1 (IDE#1) |
200-207 |
200-20F |
Игровойадаптер |
|
210-217 |
Блокрасширений |
238-23F |
|
COM4 |
278-27F |
278-27F |
ПараллельныйпортLPT2 (LPT3 приналичииMDA) |
|
2А2-2АЗ |
Часы MSM48321RS |
2CO-2DF |
2CO-2DF |
EGA #2 |
2ЕО-2Е7 |
|
COM4 |
2E8-2EF |
|
COM4 |
2F8-2FF |
2F8-2FF |
COM2 |
300-31 F |
|
Платапрототипа |
|
320-32F |
ЖесткийдискXT |
338-33F |
|
COM3 |
370-377 |
|
КонтроллерНГМД#2 |
376-377 |
|
ПортыкомандШЕ#2 |
378-37F |
378-37F |
ПараллельныйпортLPT1 (LPT2 приналичииMDA) |
380-38F |
380-38F |
СинхронныйадаптерSDLC/BSC #2 |
3AO-3AF |
ЗАО-ЗА9 |
СинхронныйадаптерBSC #1 |
ЗВО-ЗВВ |
ЗВО-ЗВВ |
Монохромныйадаптер(MDA) |
ЗВ4-ЗС9 |
|
PS/2 видеосистема |
3BC-3BF |
3BC-3BF |
ПараллельныйпортLPT1 платыMDA |
3CO-3CF |
3CO-3CF |
EGA#1 |
3CO-3DF |
3CO-3DF |
VGA |
3DO-3DF |
3DO-3DF |
CGA/EGA |
ЗЕО-ЗЕ7 |
|
COM3 |
3E8-3EF |
|
COM3 |
3FO-3F7 |
3FO-3F7 |
КонтроллерНГМД#1 |
3F6-3F7 |
|
ПортыкомандШЕ#1 |
3F8-3FF |
3F8-3FF |
СОМ1 |
Выбор базовых адресов стандартных устройств (3F8h, 3FOh, 378h и т. п.) объясняется стремлением к экономии. Эти адреса выбирались так, чтобы в их дешифрации участвовало максимальное количество единиц и минимальное — нулей (логические схемы «И-НЕ» применяются чаще, чем схемы «ИЛИ», а применениеболеесложныхсхемдлядешифрациибылонежелательно).
Каждой шине назначается своя область адресов ввода, и дешифратор адресов, расположенный на системной плате, при чтении открывает соответствующие буферыданных, такчтореальносчитыватьсябудутданныетолькосоднойшины. При записи в порты данные (и сигнал записи) обычно распространяются по всем шинам компьютера. Встандартном распределении адреса Oh-OFFh отведены для устройств системной платы. При наличии (и разрешении работы) периферийныхустройствнасистемнойплатечтениепоэтимадресамнераспро-
78 Глава3. АрхитектураIBM PC-совместимогокомпьютера
страняется на шины расширения. Для современных плат со встроенной периферией и несколькими шинами (ISA, PCI) распределением адресов управляет BIOS черезрегистрыконфигурированиячипсета.
В реальном режиме процессора программе доступно все пространство адресов ввода-вывода. В защищенном режиме 32-разрядных процессоров (частным случаем которого является и виртуальный режим V86) имеется возможность программного ограничения доступного пространства ввода-вывода, определяя его максимальный размер (начиная с нулевого адреса и в пределах 64К), а внутри разрешенной области доступ может быть разрешен или запрещен для каждого конкретного адреса. Размер области и карта разрешенных портов (Ю Permission Bitmap) задается операционной системой в дескрипторе сегмента состояния задачи (TSS). При обращении по неразрешенному адресу вырабатывается исключение процессора, а поведение его обработчика определяется операционной системой. Возможно снятие задачи-нарушителя (знаменитое сообщение «приложение... выполнило недопустимую операцию и будет закрыто»). Возможен и другой вариант, когда по обращению к порту монитор операционной системы выполняет некоторые действия, создавая для программы иллюзию реальной операции ввода-вывода. Таким образом, виртуальная машина по операциям ввода-вывода может общаться с виртуальными устройствами.
3.4. Аппаратныепрерывания
Аппаратные прерывания обеспечивают реакцию процессора на события, происходящие асинхронно по отношению к исполняемому программному коду. По возникновении такого события адаптер (контроллер) устройства формирует запрос прерывания, который поступает на вход контроллера прерываний. Контроллер прерываний формирует общий запрос прерывания для процессора, а когда процессор подтвердит этот запрос, контроллер сообщит процессору вектор прерывания, по которому выбирается программная процедура обработки прерываний. Процедура должна выполнить действия по обслуживанию данного устройства, включая сброс его запроса для обеспечения возможности реакции на следующие события и посылку команды завершения в контроллер прерываний. Логика работы системы прерываний и программная модель контроллера прерываний, совместимого с микросхемой i8259A, является важной частью стандартизации архитектуры PC-совместимых компьютеров. Прерывания в процессорах х86 рассмотренывп. 5.2.3.
3.4.1.НемаскируемыепрерыванияNMI иSMI
ВPC-совместимых компьютерах класса AT немаскируемые прерывания используются для сигнализации о фатальных аппаратных ошибках. Сигнал на линию NMI приходит от схем контроля паритета памяти, от линий контроля шины ISA (ЮСНК) или шины PCI (SERR#). Сигнал NMI блокируется до входа процессора установкой в 1 бита 7 порта 070h, отдельные источники — битами 2, 3 порта 06lh (см. п. 3.6.1). Программно идентифицировать источник NMI позволяют биты 6, 7 порта 06lh.
3.4. Аппаратныепрерывания 79
В PC XT сигнал NMI вызывается еще и математическим сопроцессором при возникновении его исключения. Здесь запретить NMI позволяет обнуление бита 7 порта OAOh; отдельные источники блокируются битами 4, 5 порта 06lh; идентифицируют источники биты 6, 7 порта 062h.
Прерывание SMI возникает от схем чипсета, участвующих в управлении энергопотреблением. Это прерывание имеет наивысший приоритет и обслуживается несколько иначе, чем «классические» прерывания. Здесь процессор не выполняет вызов процедуры, описанной в таблице прерываний, а переходит в режим SMM, что сопровождается установкой сигнала SMIACT#, по которому вместо обычной памяти процессору становится доступной память SMRAM. Выход из режима S ММ происходит по выполнении инструкции RSM, завершающей процедуру обработки SMI. После обработки SMI возможен рестарт (повторное исполнение) инструкции останова (HALT) и инструкций ввода-вывода. Возможность рестарта инструкции ввода-вывода используют, например, когда прикладная программа (или системный драйвер) пытается обратиться операцией ввода-вывода к периферийному устройству, находящемуся в «спящем» режиме. Системная логика в этом случае должна выработать сигнал SMI# раньше сигнала готовности RDY#, завершающего шинный цикл рестартуемой инструкции ввода-вывода. Обработчик SMI «разбудит» устройство, после чего операция ввода-вывода рес-тартует и прикладное ПО (или драйвер) «не заметит», что устройство пребывало в спячке. Таким образом, управление потреблением может быть организовано на уровне BIOS способом, совершенно прозрачным дляпрограммного обеспечения (в том числе и ОС).
3.4.2.Маскируемыепрерывания
ВPC-совместимых компьютерах маскируемые прерывания используются для сигнализации о событиях в устройствах. Обработка сигналов запросов прерывания выполняется контроллером прерываний, программно-совместимым с8259А(см. [1, 7]). Контроллер прерываний позволяет маскировать отдельные входы запросов и организовывать систему приоритетов запросов от различных входов. В машинах класса AT применяется каскадное соединение двух контроллеров. Ведущий контроллер 8259А#1 обслуживает запросы О, 1, 3-7; его выход подключается к входу запроса прерываний процессора. К его входу 2 подключен ведомый контроллер 8259А#2, который обслуживает запросы 8-15. При этом поддерживается вложенность приоритетов — запросы 8-15 со своим рядом убывающих приоритетов вклиниваются между запросами 1 и 3 ведущего контроллера, приоритеты запросов которого также убывают с ростом номера. В XT каскадирование не применялось и один контроллер 8259А обслуживал все 8 линий запросов.
На входы контроллеров прерываний поступают запросы от системных устройств (клавиатура, системный таймер, CMOS-таймер, сопроцессор), периферийных контроллеров системной платы и от карт расширения. Традиционно все линии запросов, не занятые перечисленными устройствами, присутствуют на всех слотах шины ISA/EISA. Эти линии обозначаются как IRQx и имеют общепринятые предназначения, приведенные в табл. 3.2. Часть из этих линий отдается в

80 Глава3. АрхитектураIBM PC-совместимогокомпьютера
распоряжение шины PCI. В таблице отражены и приоритеты прерываний — запросы расположены в порядке их убывания. Номера векторов, соответствующих линиям запросов контроллеров, система приоритетов и некоторые другие параметры задаются программно при инициализации контроллеров. Эти основные настройки сохраняются традиционными для обеспечения совместимости с программным обеспечением.
Таблица3.2. Аппаратныепрерывания(впорядкеубыванияприоритета)
Имя(номер) |
Вектор |
Описание |
|
NMI |
02h |
Контрольканала, паритет(вXT — сопроцессор) |
|
IRQO* |
08h |
Таймер(канал0 8253/8254) |
|
IRQ1* |
09h |
Клавиатура |
|
IRQ2 |
OAh |
XT — резерв, AT — недоступно(подключается |
каскадIRQ8-IRQ15) |
IRQ8* |
70h |
CMOS RTC — часыреальноговремени |
|
IRQ9 |
71h |
Резерв |
|
IRQ10 |
72h |
Резерв |
|
IRQ11 |
73h |
Резерв |
|
IRQ12 |
74h |
PS/2-Mouse (резерв) |
|
IRQ13* |
75h |
Математическийсопроцессор |
|
IRQ14 |
76h |
НОСконтроллерНЖМД |
|
IRQ15 |
77h |
Резерв |
|
IRQ3 |
OBh |
COM2, COM4 |
|
IRQ4 |
OCh |
СОМ1, COM3 |
|
IRQ5 |
ODh |
XT - HDC, AT - LPT2, Sound (резерв) |
|
IRQ6 |
OEh |
FDC - контроллерНГМД |
|
IRQ7 |
OFh |
LPT1 — принтер |
|
* ЗапросыпрерыванийО, 1, 8 и13 нашинырасширенияневыводятся.
Для запросов прерывания с шины PCI (см. п. 12.5.5) используются 4 линии запросов прерывания, которые обозначают как INTR А, В, С, D. Эти линии работают по низкому уровню, что дает возможность их совместного (разделяемого) использования. Линии циклически сдвигаются в слотах и независимо коммутируются на доступные линии IRQx с помощью конфигурационных регистров чипсета. Линии IRQx, используемые шиной PCI, становятся недоступными для шины ISA. «Дележку» линий между шинами, а также управление чувствительностью отдельных линий обеспечивают параметры CMOS Setup, а также система РпР. В параметрах настройки «ISA» или «Legacy» подразумевают использование линий IRQx традиционными адаптерами шины ISA (статическое распределение), a «PCI/PnP» — использование адаптерами шины PCI или адаптерами РпР для шины ISA (динамическое распределение). Общая схема формирования запросов прерываний изображена на рис. 3.4.
Каждому устройству, для поддержки работы которого требуются прерывания, должен быть назначен свой номер прерывания. Назначения номеров прерываний выполняются с двух сторон: во-первых, адаптер, нуждающийся в прерываниях, должен быть сконфигурирован на использование конкретной линии шины (джамперами или программно). Во-вторых, программное обеспечение, поддер-
3.4. Аппаратныепрерывания 81
живающее данный адаптер, должно быть проинформировано о номере используемого вектора. В процессе назначения прерываний может участвовать система РпР для шин ISA и PCI, для распределения линий запросов между шинами служат специальные параметры CMOS Setup.
INTA# |
x INI |
ГА# ^ INTA# 'B# |
INTB# V INI |
V INTB# \ "C# \ |
|
INTC# ЛINI |
INTC# ' •D# ^ |
|
INTD# ' INI |
INTD# ' |
|
|
|
|
PCI#4 |
PCI#3 |
PCI#2 |
СлотыPCI
/ INTA# x INTB# V INTC# INTD#
От устройств шины ISA о и системной платы 5
*
IRQ2/9
IRQ3
I R Q 4
I R Q 5 *
IRQ6
I R Q 1 0 *
IRQ11 :
IRQ12
IRQ14
IRQ15
"Р |
|
|
|
Клавиатура^ |
|||
s |
|||
|
| |
||
Я |
|
||
|
|
||
|
|
||
& |
|
|
|
|
|
||
|
|
||
1 |
|
|
|
CMOS RTC |
|
||
|
|
||
|
|
|
|
ЫРХь
^
i
-JOJCn-li.OJM-'O |
PIC 8259A#1 |
8
9 csj 10 $ •to ?j it oo
13 0 14 0-
15
INTR
(кCPU)'
-
Рис. 3.4. Коммутациязапросовпрерываний
Контроллер прерываний позволяет программировать свои входы на чувствительностькуровнюилиперепадусигнала.
» Чувствительность к уровню (level sensitive) означает, что контроллер прерываний вырабатывает запрос прерывания процессора по факту обнаружения определенного уровня (на ISA — высокого) на входе DRQx. Если к моменту завершения обработки этого запроса (после записи команды EOI в регистр контроллера прерываний) контроллер снова обнаруживает активный уровень на том же входе DRQx, то он снова сформирует запрос на прерываниепроцессора.
я Чувствительность к перепаду (edge sensitive) означает, что контроллер прерываний вырабатывает запрос прерывания процессора только по факту обнаружения перепада (на ISA — положительного) на входе DRQx. Повторно запрос по этому входу возможен только по следующему такому же перепаду, то есть сигнал предварительно должен вернуться в исходное состояние.
В любом случае сигнал запроса аппаратного прерывания IRQx должен удерживаться генерирующей его схемой, по крайней мере, до цикла подтверждения прерывания процессором. В противном случае источник прерывания корректно идентифицирован не будет, и контроллер сообщит ложный вектор прерывания (spurious interrupt), соответствующий его входу с максимальным номером (IRQ7 для первого контроллера и IRQ 15 для второго). Обычно адаптеры строят так, что сигнал запроса сбрасывается при обращении программы обслуживания прерыаания ксоответствующимрегистрамадаптера.
82Глава3. АрхитектураIBM PC-совместимогокомпьютера
Вшине ISA прерывание вырабатывается по положительному перепаду сигнала на линии запроса — разработчики IBM PC сэкономили целую микросхему ТТЛ (своеобразный «плевок в вечность»). Это плохо по двум причинам: во-первых, как известно из общей цифровой схемотехники, такой способ подачи сигнала имеет меньшую помехозащищенность, чем срабатывание по отрицательному перепаду. Если кто обращал внимание на сообщение «Spurious Interrupt was detected on controller...», иногда появляющееся на консоли сервера NetWare, то оно относится именно к обнаружению этих помех. В операционных системах, неактивно использующих прерывания (а к ним, в первую очередь, относится MS-DOS), эти явления незаметны и обычными тестами (PC Check, Checklt) не выявляются. Вовторых, такой способ подачи сигнала отрезает путь к нормальному разделению линий запросов (см. ниже), для которого полностью пригоден способ подачи сигнала по низкому уровню. Поскольку традиционный контроллер позволяет задавать чувствительность — уровень (Level) илиперепад (Edge) — толькодлявсех входов одновременно, в общем случае разделяемые прерывания на шине ISA вместе с корректной работой системных устройств использоваться немогут.
На современных системных платах функции контроллеров прерываний возлагаются на чипсет, который может иметь и более гибкие возможности управления, чем пара контроллеров 8259А. В операционном режиме всегда сохраняется программная совместимость с 8259А. Процедура инициализации контроллеров может и отличаться от традиционной, но ею занимается тест POST, который «знает» особенности системной платы. В симметричных мультипроцессорных системах аппаратные прерывания работают сложнее, поскольку их могут обслуживать различные процессоры. Для реализаций системы прерываний процессоры Pentium, Pentium Pro и Pentium II имеют встроенный контроллер прерываний
APIC (Advanced Programmable Interruption Controller). Внутренние контроллеры процессоров связаны между собой по шине APIC, к которой подключена и «ответная часть» чипсета, преобразующая запросы аппаратных прерываний в сигналы протокола APIC. В операционном режиме такая связка также совместима с
8259А.
При работе с контроллером прерываний от программы требуется лишь управление маской своего запроса (при инициализации программы нужно обнулить маску требуемого запроса) и корректно завершать обработку прерываний. Каждая процедура обработки аппаратного прерывания должна завершаться командой EOI (End Of Interruption), посылаемойконтроллеру:
» для 1-го контроллера — посылка байта 20h по адресу 020h;
ав для 2-го контроллера — посылка байта 20h по адресу OAOh; программный вызов прерывания OAh — завершение для ведущего контроллера; для некоторых старых версий BIOS был необходим явный сброс маски запроса в регистре2-гоконтроллера.
Некорректно завершенная процедура не позволит повторно использовать данный илидругиезапросыпрерываний.
3.4. Аппаратныепрерывания 83
3.4.3. Разделяемоеиспользованиепрерываний
Линии запросов прерываний в компьютере, насыщенном дополнительными адаптерами, являются самым дефицитным ресурсом, поэтому возникает желание использовать эти линии совместно, то есть разделять между несколькими устройствами. Обработчики прерываний (программы) от разных устройств, использующих одну линию запроса (и, следовательно, общий вектор прерывания), должны быть выстроены в цепочку. В процессе обработки прерывания очередной обработчик в цепочке чтением известного ему регистра своего устройства должен определить, не это ли устройство вызвало прерывание. Если это, то обработчик должен выполнить необходимые действия и сбросить сигнал запроса прерывания от своего устройства, после чего передать управление следующему обработчику в цепочке; в противном случае он просто передает управление следующему обработчику. Чтобы прерывания, одновременно возникающие от нескольких устройств, не терялись, контроллер прерываний должен быть чувствительным к уровню, а не к перепаду на входе запроса. В соответствии со схемотехникой логики ТТЛ и КМОП активным уровнем должен быть низкий; выходной формирователь сигнала запросов у адаптеров — с открытым коллектором (ТТЛ) или открытым стоком (КМОП); вход запроса у контроллера должен быть «подтянут» к высокому уровню резистором. Тогда непосредственное соединение этих выходов со входом контроллера («монтажное И») даст требуемый результат в аппаратном плане, а в программном плане необходимо корректно выстроить обработчикивцепочку.
Поясним, почему надежная разделяемость при чувствительности к перепаду на линии запроса невозможна. Если устройство 1 выработает сигнал запроса после того, как его выработает (но еще не снимет) устройство 2, то контроллер обработает только один запрос. Цепочка программных обработчиков окажется ненадежной: если обработчик устройства 1 в этой цепочке будет проверять свое устройство до возникновения прерывания, то прерывание будет потеряно. Поскольку прерывания по своей природе обычно асинхронны, работа этих устройств совместно с поддерживающими программами будет загадочно нестабильной.
Как уже говорилось, в шине ISA прерывание вырабатывается по положительному перепаду сигнала на линии запроса. Стандартный контроллер 8259А позволяет задавать чувствительность — уровень или перепад — только для всех входов одновременно, поэтому разделяемые прерывания на шине ISA неработоспособны. Тем не менее некоторые чипсеты, реализующие контроллеры прерываний, допускают индивидуальное управление чувствительностью каждого входа. Тогда при соответствующих возможностях CMOS Setup, адаптеров и их ПО разделяемые прерывания технически реализуемы.
Для шины PCI, казалось бы, проблема разделяемости прерываний решена — здесь активным уровнем запроса является низкий, так что запрограммировав входы контроллера на чувствительность к уровню, создается аппаратная база разделяемости. Однако на практике разделяемые прерывания работают не всегда, и иногда приходится подбирать положение карт расширения в слотах PCI, при которых устройства не конфликтуют друг с другом по прерываниям. Виной конфликтов могут быть как сами карты расширения, так и их драйверы, неспособныевыстраиватьсявкорректнуюцепочку.
84 Глава3. АрхитектураIBM PC-совместимогокомпьютера
Если карта PCI использует одну линию запроса прерываний, то этой линией по умолчанию является INTR А. Если все четыре карты PCI используют по одной линии запроса, то, как это видно на рис. 3.4, каждая линия занимается монопольно. Однако если сложная карта нуждается в большем числе линий запроса, то ей придется разделять линии с соседними картами. На современных системных платах часто устанавливают более четырех слотов PCI, при этом, естественно, «угроза» разделяемости линий запросов «нависает» и над картами с одной линией запроса. Порт AGP в плане прерываний следует рассматривать наравне со слотами
PCI.
Проявления конфликтов и ошибок назначения прерываний могут быть разнообразными. Сетевая карта при ошибке в прерываниях не сможет принимать кадры из сети (при этом она может их успешно посылать). У устройств хранения доступ к данным будет поразительно медленным (иногда можно минутами ожидать, например, появления информации о файлах и каталогах) или вообще невозможным. Звуковые карты будут молчать или «заикаться», на видеопроигрывателях изображение будет дергаться и т. д. Конфликты могут приводить и к внезапным перезагрузкам компьютера, например, по приходу кадра из сети или сигналуотмодема.
3.5.Прямойдоступкпамяти— DMA
Вобычном режиме обмена для пересылки байта или слова данных из порта устройства в ячейку памяти требуется выполнение шинного цикла чтения порта, за которым следует шинный цикл записи в память. На эти действия требуется как минимум одна команда процессора (INSB, INSW), которую с помощью префикса REP можно повторить заданное число раз. Таким способом реализуется режим обмена РЮ (Programmed Input-Output), используемый, например, при обмене данными с устройствами АТА. Передача в обратную сторону реализуется аналогично, командамиOUTSB илиOUTSW. СпомощьюкомандIN иOUT можнопрочитатьиз порта в регистр процессора (AL, АХ или ЕАХ) или вывести в порт байт или слово из того же регистра, но для пересылки этих данных в память (из памяти) требуется команда, адресующаясякпамяти.
Прямой доступ к памяти — DMA (Direct Memory Access) позволяет выполнить ту же пересылку за один цикл обмена, причем минуя центральный процессор. Для этого на системной плате компьютера имеется многоканальный контроллер DMA, программируемый по командам от центрального процессора. Процессор при обмене занят только инициализацией контроллера, которая сводится к записи в его регистры нескольких байт, задающих начальный адрес и размер пересылаемого блока памяти, направление и режим обмена. Затем обмен производят системная шина и контроллер DMA, а инициатором обмена выступает устройство, сигнализирующее контроллеру DMA о своей готовности к обмену. Во время операций DMA процессор может продолжать работу, если выбранный режим обмена не занимает всей пропускной способности шин, используемых процессором
вданный момент (шины памяти, шины PCI, через которые подключается ISA в современныхкомпьютерах). КонтроллерDMA можносчитатьпро-
3.5. Прямойдоступкпамяти— DMA 85
стейшим сопроцессором ввода-вывода, разгружающим центральный процессор от рутинныхоперацийобмена.
Для интерфейса ПУ каждый канал DMA представляется парой сигналов: запрос обмена — DRQx и подтверждение обмена — DACKx#. В операциях по каналу DMA адресуется текущая ячейка памяти, адрес порта не фигурирует, а используется только пара сигналов, соответствующая номеру канала.
В PC/AT доступны 7 каналов DMA: четыре 8-битных (номера 0-3) и три 16битных (5-7), подключенные к первичному и вторичному контроллерам соответственно. Канал 4 используется для каскадирования (соединения контроллеров). В PC/XT были только три 8-битных канала, канал 0 использовался для регенерации памяти. Контроллеры DMA программно совместимы с системами 18237, используемыми в первых моделях PC/XT и AT. Стандартные каналы и адреса регистров приведены в табл. 3.3.
Таблица3.3. Стандартныеканалыпрямогодоступакпамяти
НомерканалаDMA* |
0 |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
Стандартное |
XT |
MRFR |
|
- |
FDD |
HDD |
Отсутствуют |
|
|
|
назначение |
|
|
|
|
|
|
|
|
|
|
AT |
- |
|
SDLC |
FDD |
HDD |
Каскад |
- |
- |
- |
|
Разрядность, байт |
1 |
|
|
|
|
2 счетного адреса |
|
|
||
Макс, размерблока |
64 Кбайта |
|
|
|
128 Кбайт, четный |
|
|
|||
Граница блока |
|
КратнаlOOOh |
|
|
Кратна 2000h |
|
|
|||
Регистрстраниц |
8 бит А16-А23 |
|
|
7 бит А17-А23 |
|
|
||||
Адресарегистров: |
087 |
|
083 |
081 |
082 |
08F |
08В |
089 |
087 |
|
страниц |
|
|
|
|
|
|
|
|
|
|
адреса |
|
000 |
|
002 |
004 |
006 |
ОСО |
ОС4 |
ОС8 |
осе |
счетчика |
|
001 |
|
003 |
005 |
007 |
ОС2 |
ОС6 |
ОСА |
ОСЕ |
Примечание. SDLC-адаптерустанавливаетсяредко. HDD-контроллервAT DMA обычнонеиспользует.
Канал0 вXT использовалсядлярегенерациипамяти(MRFR). Канал4 доступентольковPS/2 МСА.
16-битные каналы DMA 5-7 могут быть использованы интеллектуальными устройствами для прямого управления шиной ISA (bus mastering), при этом контроллер DMA фактически лишь играет роль арбитра шины (см. п. 12.1). Интеллектуальный контроллер может выполнять более эффективные процедуры обмена, чемстандартный DMA, например:
ж Scatter Write — «разбросанная» запись внесколько блоков памяти; ш Gather Read — чтениесосбором данных из нескольких блоков памяти; « обмен нечетнымколичеством байт и (или) снечетного адреса по16-битномуканалу.
Шиной ISA управляют высокопроизводительные адаптеры SCSI и локальных сетей, а также интеллектуальные графические адаптеры. Однако архитектурой шины доступное им пространство памяти ограничено областью в 16 Мбайт, что по нынешним меркам маловато. «Заботливые» операционные системы (например, Novell NetWare) для таких адаптеров позволяют под буферы резервировать область в пределах младших 16 Мбайт.
86 Глава3. АрхитектураIBM PC-совместимогокомпьютера
Ограничения на доступную память для «чистого» режима DMA в новых машинах могут быть сняты применением расширенных регистров страниц, но об этих не совсем стандартных возможностях, конечно же, должно «знать» и программноеобеспечение.
Стандартный контроллер DMA на шине ISA с частотой 8 МГц работает на половинной частоте и требует для одиночной передачи не менее пяти своих тактов (включая IDLE). Длительность одиночного цикла составляет 1,125 мкс. В случае медленных устройств через сигнал IOCHRDY возможно введение тактов ожидания. В блочных передачах такт IDLE присутствует только в начале, так что пропускная способность DMA достигает 1 Мбайт/с для 8-битных каналов и 2 Мбайт/с для 16битных (время цикла составляет 1 мкс). Программно-управляемый ввод-вывод, выполняемый инструкциями REP INS/OUTS, может иметь производительность для той же шины в два раза выше. По этой причине для обмена данными с контроллерами жестких дисков стандартные каналы DMA используются редко, предпочтениеотдаетсяпрограммномуобмену.
В машинах с архитектурой МСА для DMA используется специальный контроллер, программно-совместимый с контроллером AT, но имеющий и дополнительные возможности конфигурирования (регистры 0018, 001А). Все каналы могут работать в 8- и 16-битном режиме, их запросы посылаются общему арбитру канала. Доступны 8 каналов, частота работы 10 МГц.
На шине EISA каналы DMA могут работать в 8-, 16- и 32-битном режиме, они могут использовать все 32 разряда шины адреса — иметь доступ ко всей памяти компьютера. Каждый канал может программироваться на 1 из 4 типов цикла передачи.
шCompatible — полностьюсовместимсISA.
шТуре А — сокращенный на 25 % цикл: время одиночного цикла 875 не, в блочном режиме время цикла 750 не. Работает почти со всеми ISA-адап- терамисбольшейскоростью.
тТуре В — сокращенный на 50 % цикл (750/500 не на цикл), работает с большинством EISA-адаптеров и некоторыми ISA. Этот тип цикла возможен только с памятью, непосредственно доступной контроллеру шины EISA (памятью на адаптерах EISA, а также системной в случае, еслиEISA является основной шиной системной платы). Если декодированный адрес памяти относится к 8/16-битной памяти ISA, то контроллер DMA EISA автоматическипереводится врежимCompatible.
пТуре С (Burst Timing) — сокращенный на 87,5 % цикл, ориентированный на пакетный режим передач. Работает со скоростными EISA-адаптерами и при обмене 32-битных устройств с 32-битной памятью позволяет развивать скорость обмена до 33 Мбайт/с.
EISA DMA имеет специальные режимы: Buffered Chaining (сцепка буферов), Scatter Write («разбросанная» запись), Gather Read («собирающее» чтение).
В PCI-системах для обмена с устройствами системной платы возможно использование DMA с типом Type F, при котором между соседними циклами интервал может не превышать 3 тактов шины (360 не). Для разгрузки системной шины используется дополнительный 4-байтный буфер. Тип F может работать