

2 Исследование вероятностных характеристик информационных потоков
2.1 Основные предпосылки для анализа характера закона распределения информационного потока
Важной характеристикой информационного потока является закон распределения промежутков между соседними вызовами. Необходимо проанализировать выборочную совокупность реального информационного потока запросов для определения характера закона распределения промежутков между поступлениями заявок на Call-центр.
Анализ выборки позволит оценить степень независимости поступления заявок друг от друга. Анализ данных выборочной совокупности позволит оценить характер закона распределения входящего потока с целью уточнения математической модели обслуживания заявок в Call-центре.
2.2 Анализ характера закона распределения промежутков между моментами поступления заявок
Для оценки характера закона распределения входящего потока необходимо провести измерение длительностей промежутков между поступлениями заявок. Для проведения анализа из генеральной совокупности производится выборка по следующему алгоритму:
зафиксировать промежуток времени наблюдения, который задает объем выборки и обеспечивает условие, что поступающий поток сигнальных единиц близок к стационарному;
зафиксировать число операторов;
исследовать проводится отдельно для каждого оператора в течение фиксированного промежутка времени.
Для сформированной выборочной совокупности определены длительности промежутков между поступлениями сигнальных единиц и рассчитаны: среднее значение, несмещенная оценка дисперсии и среднеквадратическое отклонение случайной величины. Кроме того, выполнен расчет коэффициента асимметрии β, характеризующего скошенность распределения по отношению к математическому ожиданию.
Для доказательства предположения соответствия распределения выборочной совокупности теоретическому распределению воспользуемся критерием согласия 2 Пирсона. При анализе характера закона распределения промежутков между поступлениями заявок будем использовать статистические данные о работе Call-центра.
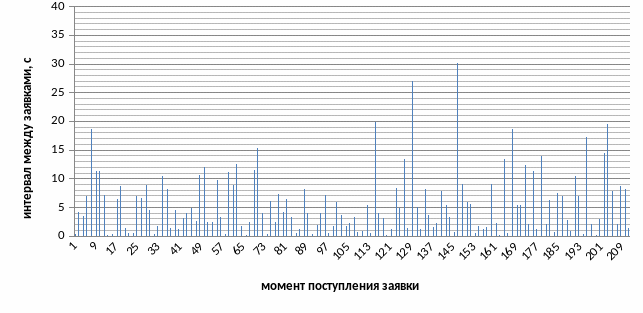
Рисунок 2.1 – Фрагмент исходной зависимости интервалов между поступлениями запросов от момента поступления
Для выбранного периода наблюдений рассчитаем статистические характеристики, такие как средняя длительность интервалов между поступлениями сообщений, стандартное отклонение и асимметрия (таблица 2.1).
При
достаточно близком совпадении среднего
значения и среднеквадратического
отклонения случайной величины (коэффициент
вариации
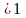 )
можно говорить о приемлемости гипотезы
о показательном законе распределения
промежутков между поступлениями
сигнальных сообщений. Однако, такие
проверки никак не могут доказать
соответствия выборки теоретическому
закону.
)
можно говорить о приемлемости гипотезы
о показательном законе распределения
промежутков между поступлениями
сигнальных сообщений. Однако, такие
проверки никак не могут доказать
соответствия выборки теоретическому
закону.
Для оценки степени зависимости случайных величин в последовательности интервалов времени между поступлениями заявок построены графики корреляционной функции.
В таблице 2.1 приведены cтатистические характеристики выборки.
Таблица 2.1 - Статистические характеристики выборки
Характеристика выборки |
Параметр |
Средняя длит.
интервалов
|
5,02 |
Стандарт. отклонен
|
5,35 |
Коэф. вариации,
|
1,06 |
Асимметрия, β |
|
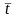 ,
с
,
с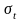 ,
мс
,
мс
Так как коэффициент вариации практически не отличается от единицы, то можно сделать первоначальное предположение, что поток запросов, поступающих на Call-центр, является простейшим.
С помощью критерия серий, основанного на медиане выборки, докажем стационарность процесса
Определяется медиана этого вариационного ряда Me.
Образуется последовательность δi из плюсов и минусов по следующему правилу:
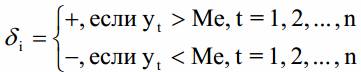 Если
значение yt равно медиане, то это
значение пропускается.
Если
значение yt равно медиане, то это
значение пропускается.Подсчитывается v(n) - число серий в совокупности δi, где под серией понимается последовательность подряд идущих плюсов или минусов. Один плюс или один минус тоже будет считаться серией. Определяется t(n) - протяженность самой длинной серии.
Проверка гипотезы основывается на том, что при условии случайности ряда (при отсутствии систематической составляющей) протяженность самой длинной серии не должна быть слишком большой, а общее число серий - слишком маленьким. Поэтому для того, чтобы не была отвергнута гипотеза о случайности исходного ряда (об отсутствии систематической составляющей) должны выполняться следующие неравенства (для 5% уровня значимости uкр = 1.96):
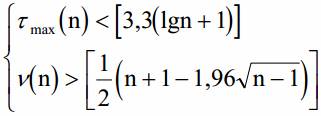
Если хотя бы одно из неравенств нарушается, то гипотеза об отсутствии тренда отвергается. Квадратные скобки в правой части неравенства означают целую часть числа.
Зависимость между последовательными значениями временного ряда называют автокорреляцией значений ряда. Количественно ее можно измерить с помощью величины корреляции между значениями исходного временного ряда и значениями этого ряда, сдвинутыми нанесколько шагов во времени. Таким образом, ставится задача исследования глубины ретроспективных данных на основании вычисления величины корреляции, то есть вычисления интервала длины, после которого влияние предшествующих данных не влияют на текущее.
Для оценки функции автокорреляции строится ее график (коррелограмма), значения который лежит в пределах [-1 ÷ 1].
Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается. Максимальный лаг должен быть не больше (n/4).
Коэффициент автокорреляции уровней ряда первого порядка, измеряющий зависимость между соседними уровнями ряда yt и yt-1, т. е. при лаге 1, рассчитывается по формуле:
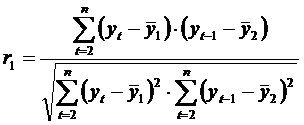
где
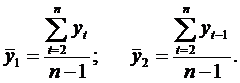
Аналогично определяются коэффициенты автокорреляции второго и более высоких порядков. Так, коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями yt и yt-2 и определяется по формуле:
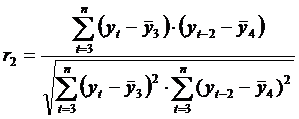
где
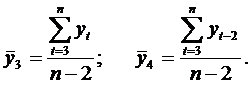
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока: 0.1 < rt,t-1< 0.3: слабая; 0.3 < rt,t-1< 0.5: умеренная; 0.5 < rt,t-1< 0.7: заметная; 0.7 < rt,t-1< 0.9: высокая; 0.9 < rt,t-1< 1: весьма высокая.
Рассчитанные коэффициенты корреляции, а также корреляционнаяфункции показывают отсутствие зависимость между поступающими запросами.
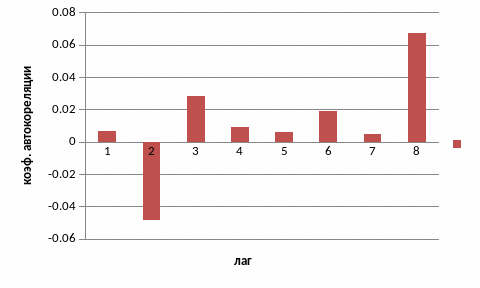
Рисунок 2.2 – Вычисленная коррелограмма исходного ряда