

Формирование и передача сигнала_lekc
.pdfС бит / c / Гц
16 П
Недоступная область
8
64
4 |
|
|
16 |
|
|
|
|
8 |
|
|
|
||
|
|
|
|
|
||
2 |
|
4 |
|
|
|
|
-1,6 |
2 |
12 |
24 |
36 |
Eb/N0, |
|
дБ |
||||||
|
||||||
|
|
|
|
|
42
-0,5
8
-0,25 |
Рис. 31 |
|
4. Основные понятия теории информации
При построении систем связи возникает задача минимизации количества знаков, необходимых для передачи сообщения. Чтобы решить эту задачу "кодирования источника", необходимо дать определение понятиям "источник сообщения" и "количество информации". Источник сообщения определяют как объект, принимающий определенное состояние из некоторого множества. Состояния помечены знаками x1, x2,…, xm. Набор из m знаков, соответствующих всем возможным состояниям, составляет "алфавит" объема m. Состояние xi появляется с "априорной" вероятностью pi . Таким образом, источник характеризуется матрицей
x |
x |
|
....x |
|
|
|
m |
|
= 1. |
1 |
|
2 |
|
m |
|
, |
∑ p |
i |
|
|
|
|
|
|
|
|
i=1 |
|
|
p1 p2....pm |
|
|
|
||||||
Сообщение - это указание состояния, которое объект принял.
По виду распределения pi можно судить об уровне неопределенности состояний. Если все состояния равновероятны, неопределенность (непредсказуемость) состояния объекта максимальна и сообщение, снимающее эту неопределенность, наиболее ценно, наиболее информативно. Естественно связать понятие количества информации со степенью неопределенности объекта. Количественная мера неопределенности должна удовлетворять следующим достаточно очевидным требованиям: а) монотонно
возрастать в зависимости от m (больше состояний - больше неопределенность), б) принимать максимальное значение при равновероятных состояниях, в) суммироваться при увеличении числа независимых источников. В качестве такой меры неопределенности источника Шеннон предложил величину
m
H(X ) = −∑ p(xi )log p(xi ). (23)
i =1
Знак "-" поставлен для того, чтобы величина Н была положительна. Хинчин доказал, что только величина (23) удовлетворяет поставленным выше условиям. В термодинамике величина вида p logp является мерой "разнообразия" скоростей молекул "замкнутой" системы и называется энтропией. По аналогии величину H назвали в теории информации энтропией источника X. За единицу измерения энтропии, при основании логарифма 2, принимается энтропия источника Х с двумя равновероятными состояниями. Эта единица называется "двоичная единица", "бит".
Энтропия источника, имеющего n равновероятных состояний, равна log n. Если 32 буквы русского алфавита считать равновероятными, энтропия языка Н=5. Если учесть частоту появления букв в тексте, Н ≈ 4,42, если учесть корреляцию соседних букв, Н ≈ 3,53, а если и дальние связи букв, в том числе между словами, Н ≈ 1,5.
Энтропия источника указывает минимальное теоретически возможное число двоичных символов, необходимое в среднем для кодирования одного знака алфавита источника. Известен ряд способов эффективного кодирования источника, уменьшающих среднее число символов на знак. Первым был метод Шеннона-Фано, предполагающий отсутствие корреляции знаков сообщения. Рассмотрим нижеследующий пример применения этого метода.
Алфавит источника - две буквы х1 и х2 с вероятностями появления 0,9 и 0,1. Энтропия источника Н(Х)= - (0,9 log20,9 + 0,1 log20,1) = 0,47. Если знаки х1 и х2 кодировать символами 0 и 1 соответственно, то для передачи одного знака потребуется 1 бит. Будем кодировать не отдельные знаки, а двухзнаковые кодовые комбинации. Согласно рассматриваемому методу, все знаки алфавита разделяют на 2 группы так, чтобы суммы вероятностей знаков каждой группы были по возможности одинаковы. Всем знакам одной группы приписывают в качестве первого символа 0, всем знакам другой группы - 1. Затем каждую из полученных групп, в свою очередь, делят на две группы, приписывая знакам группы аналогичным образом вторые символы и т.д. В табл.1 указаны вероятности двухзнаковых комбинаций и соответствующие им двоичные коды, полученные согласно данной методике. Среднее число бит на 2 символа
1*0,81 + 2*0,09 + 3(0,09 + 0,01) = 1,29,
на один символ - 0,65. Табл.2 иллюстрирует применение методики Шен- нона-Фано к трехзнаковым кодовым комбинациям. В этом случае среднее число бит на 3 символа
1*0,729 + 3*(3*0,81) + 5*(3*0,009 + 0,001) = 1,598, а на один символ – 0,53. Этот результат близок к теоретическому пределу-
значению энтропии данного источника (0,47). Рассмотренный пример показывает, что эффективное кодирование действительно возможно, и что оно достигается благодаря кодированию не отдельных знаков, а их последовательностей.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 1 |
знаки |
p |
|
|
|
группы |
|
|
|
код |
||||||
Х 1 |
Х1 |
0,81 |
|
1 |
|
|
|
|
|
|
1 |
||||
Х 1 |
Х2 |
0,09 |
0 |
|
0 1 |
|
|
|
0 1 |
||||||
|
|
|
|
|
|
||||||||||
Х 2 |
Х1 |
0,09 |
0 |
|
0 0 |
|
0 0 1 |
|
0 0 1 |
||||||
Х 2 |
Х2 |
0,01 |
0 |
|
0 0 |
|
0 0 0 |
|
0 0 0 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2 |
|
знаки |
р |
|
|
|
|
|
группы |
|
|
код |
|||||
Х1 Х1 Х1 |
0,729 |
1 |
|
|
|
|
|
|
|
1 |
|||||
Х2 Х1 Х1 |
0,081 |
0 |
|
01 |
|
011 |
|
|
|
011 |
|||||
Х1 |
Х 2 Х1 |
0,081 |
0 |
|
|
|
010 |
|
|
|
010 |
||||
Х1 Х1 Х2 |
0,081 |
0 |
|
|
|
001 |
|
|
|
001 |
|||||
Х2 |
Х2 |
Х1 |
0,009 |
0 |
|
|
|
|
|
0001 |
00011 |
00011 |
|||
Х2 |
Х1 |
Х2 |
0,009 |
0 |
|
00 |
|
000 |
|
|
00010 |
|
00010 |
||
Х1 |
Х2 |
Х2 |
0,009 |
0 |
|
|
|
|
|
0000 |
00001 |
00001 |
|||
Х2 |
Х2 |
Х2 |
0,001 |
0 |
|
|
|
|
|
|
00000 |
00000 |
|||
Если сообщение передается по каналу без помех и знаки сообщения не искажаются, принятое сообщение полностью снимает неопределенность состояния источника. В этом случае количество переданной информации, приходящееся на один знак, равно энтропии источника. Если канал с помехами, его можно описать матрицей вероятностей pij (табл.3), в которой столбцы помечены символами xi алфавита источника, строки - символами yj алфавита приемника, а элементы матрицы pij = p(xi yj) - вероятности приема символа yj при передаче символа xi. Вероятность передачи символа xi p(xi) является суммой элементов соответствующего столбца матрицы, а вероятность приема символа yj р(yj ) – суммой элементов строки. Если канал без помех, pij=1 при i=j, pij=0 при i≠j.
Количество информации на один знак, переданный по каналу с помехами, считают равным величине I(X) = H(X) - H(X/Y), где H(X/Y) - "остаточная", или "апостериорная" неопределенность источника X при условии, что приняты символы системы Y. Остаточную неопределенность на-
ходят следующим образом. Неопределенность символа xi - p(xi) log p(xi) , неопределенность символа xi при условии, что принят символ yj , равна p(xi/yj) log p(xi/yj). Эту величину надо усреднить по всем i (символ yj может быть принят при передаче, вообще говоря, любых символов xi ). Затем надо учесть, что символ yj появляется с вероятностью p(yj) , и усреднить по всем j. В итоге имеем
|
|
|
m |
m |
||
|
H(X /Y) = ∑ p(yj )∑ p(xi / yj )log p(xi / yj ). |
|||||
|
|
|
j =1 |
i =1 |
||
Условные вероятности находятся из соотношения |
||||||
|
|
p(xi y j ) = p(xi ) p(y j / xi ) = p(y j ) p(xi / y j ). |
||||
|
|
|
|
|
|
Таблица 3 |
|
|
x1 |
х2 ………хi……….xm |
|||
y1 |
|
p11 |
p12 …… |
p1i …………..p1m |
|
p(yi) |
|
|
|||||
y2 |
|
p21………….p2i……….p2m |
|
p(y2) |
||
|
…………………………………………. |
|
|
|||
yj |
|
pj1 ………….pji………..pjm |
|
p(yj) |
||
|
…………………………………………. |
|
|
|||
ym |
|
pm1…………..pmi ……...pmm |
|
p(ym) |
||
|
|
p(x1)………...p(xi)…….p(xm)… |
||||
Шеннон доказал теоремы о кодировании для канала без помех и с помехами, являющиеся основой теории эффективного и помехоустойчивого кодирования. В этих теоремах используются понятия производительности источника и пропускной способности канала. Производительность источника дискретных сообщений - это количество информации, вырабатываемое источником в единицу времени:
I(X ) = H(X ) /τu ,
где H(X) - энтропия источника, τu - длительность одного символа. Пропускная способность "С" дискретного канала без помех - это максимальная скорость передачи информации по каналу. Максимальное среднее количество информации, приходящееся на 1 символ, достигается, когда символы равновероятны. При этом
C = log m /τk ,
где τk - средняя длительность символов, m - объем алфавита символов. Теорема о кодировании для канала без помех утверждает, что если
I(X) < C, то существует способ кодирования, позволяющий передать по каналу все сообщения источника. Важно не количество знаков, выдаваемых источником в единицу времени, а объем имеющейся в них информации. Надо кодировать не отдельные знаки, а достаточно длинные последовательности знаков. Из всех возможных последовательностей реально бу-
дут появляться, причем с почти одинаковой вероятностью, "типичные" последовательности, составляющие очень небольшую часть общего числа последовательностей. Остальные (нетипичные) последовательности будут появляться крайне редко. Их можно вообще не кодировать, или кодировать их всех одним символом. Равновероятность появления символов, соответствующих типичным последовательностям, устранит избыточность в передаваемом сообщении. Чем больше длина последовательности (больше объем алфавита), тем выше эффективность такого способа кодирования. Конечно, кодировать длинные последовательности технически сложнее, чем короткие.
Пропускная способность канала с помехами
C = [H(X ) − H(X /Y)]/τk.
Чтобы увеличить H(X)-H(X/Y) - среднее количество информации, приходящейся на символ, необходимо увеличить H(X), кодируя информацию равновероятными символами, т.е. довести до значения log2m , и уменьшить H(X/Y), применяя помехоустойчивое кодирование. К знакам сообщения добавляются контрольные знаки и кодирование становится избыточным. Можно предположить, что с неограниченным увеличением шумов потребуется неограниченно увеличивать и избыточность. Тогда, чтобы успевать пропускать избыточные символы, потребуется неограниченно увеличивать техническую скорость передачи символов в канале. Теорема о кодировании для канала с помехами утверждает, что при условии I(X)<C существует способ кодирования, позволяющий передать всю информацию источника со сколь угодно малой вероятностью ошибки. Согласно этой теореме, безошибочная передача информации по каналу с помехами обеспечивается не за счет неограниченного увеличения избыточности кодирования, а за счет удлинения кодируемых (типичных) последовательностей знаков. Конечно, при этом возрастает сложность аппаратуры.
Одним из основных результатов теории информации является доказательство того, что максимальная скорость передачи информации достигается при использовании сигналов с равновероятными и взаимно независимыми, некоррелирующими символами. В их последовательности нельзя установить какую-то закономерность, последовательность "шумоподобна". В то же время с «самой случайной» помехой вида белого шума, обладающей максимальной энтропией, особенно трудно бороться.
5. Методы кодирования
Процесс кодирования в цифровой системе разделяют на кодирование источника и канальное кодирование. Задачей кодирования источника является минимизация среднего числа двоичных знаков, представляющих сообщение, или, другими словами, уменьшение избыточности в тексте сообщения. Цель канального кодирования - создать возможность диагностики и исправления ошибок в принятом сообщении с учетом вида наиболее типичных ошибок в канале связи. Эта цель достигается применением помехоустойчивого кодирования и "перемешивания". В помехоустойчивом коде к информационным битам добавляются избыточные, контрольные биты, в результате все возможные кодовые комбинации разделяются на разрешенные и запрещенные. Появление в приемном устройстве запрещенной комбинации является признаком ошибки. В результате анализа запрещенной комбинации, при соответствующем методе кодирования, можно исправить ошибку.
В процессе перемешивания (чередования) биты одной кодовой комбинации разносятся по времени, чередуясь с битами других кодовых комбинаций. Благодаря этому упрощается диагностика пакетов ошибок, т.к. ошибочные биты пакета после операции, обратной чередованию, оказываются расположенными по одному в различных кодовых комбинациях.
Канальное кодирование позволяет существенно повысить достоверность передачи сообщений. Оно значительно эффективнее, чем повторные передачи сообщений или дублирование каналов связи, особенно в тех случаях, когда повторы слишком часты из-за высокого уровня помех и нет обратного канала связи.
5.1. Кодирование источника.
Аналоговые сигналы, до этапа кодирования, необходимо дискретизировать по времени и квантовать по уровню. Частота дискретизации fт , по теореме Найквиста, должна удовлетворять условию fт>2fm , где fm - максимальная частота сигнала. Т.к. спектр реального сигнала неограничен, происходит наложение спектральных компонент (рис.32) и перенос высокочастотной части спектра, начиная с частоты f* =0,5fт (f* … f2), в низкочастотную область (f* … f1), приводящий к искажениям сигнала. Искажений можно избежать, если спектр сигнала до дискретизации ограничить частотой f* с помощью аналогового фильтра. Аналоговые фильтры с резким спадом частотной характеристики, в отличие от цифровых фильтров, сложны и дороги, поэтому применяется «выборка с запасом»: частота дискретизации берется намного выше, например, fт = 8f* . Благодаря этому
даже при использовании простого аналогового фильтра наложения частот не происходит. Дискретизированный сигнал пропускают через цифровой фильтр, ограничивающий полосу сигнала частотой f* , а затем дискретизируют с частотой 2f* .
S(f)
f1 |
f* |
f2 fт=2f* |
f |
|
|
|
Рис.32 |
Аналоговый сигнал с большим динамическим диапазоном, например звуковой сигнал, квантуют неравномерно: шаг квантования слабых сигналов увеличивают, чтобы улучшить отношение сигнал-шум. Для этого исходный сигнал пропускают через усилитель с нелинейной характеристикой - компрессор (рис.33а), который «сжимает» сигнал, уменьшая диапазон выходного сигнала по сравнению с входным. В приемнике компандер осуществляет обратное преобразование (рис.33б) - расширение. Всю процедуру называют компандированием. Отношение сигнал-шум не зависит от уровня сигнала, если компрессор обладает логарифмической характеристикой. Стандартизованы два вида характеристик сжатия, аппроксимирующих логарифмическую функцию: µ - закон (США, Япония) и А - закон (Европа).
|
канал |
а |
б |
|
Рис.33 |
После дискретизации и квантования получаются "отсчеты", представляющие абсолютную величину аналогового сигнала в цифровом коде. Этот этап аналого-цифрового преобразования называют импульснокодовой модуляцией (ИКМ). Избыточность кодирования сигналов с ИКМ можно уменьшить, если формировать передаваемый код с учетом его предыдущих значений. Подобные методы получили общее название дифференциальной ИКМ. Частный случай дифференциальной ИКМ - дельтамодуляция. В зависимости от знака разности значений текущего и предыдущего отсчетов выдается только один бит 1 или 0, соответственно принятый сигнал на каждом такте изменяется на один "квант" ±Δ. Если при
обычной ИКМ сигнал телефонного канала дискретизируется с частотой 8 кГц и представляется 8-битовым двоичным кодом, т.е. результирующая частота бит составляет 64 кГц, при дельта-модуляции оказывается достаточной тактовая частота 32 кГц.
Широко применяется дифференциальная ИКМ с предсказанием значения очередного отсчета в виде линейной комбинации N предыдущих
xn = a1xn−1 + a2 xn−2 + ...+ aN xn−N . |
(24) |
Такой предсказатель называют N- отводным. Идентичные устройства предсказания имеются в передатчике и приемнике. Передается только разность между реальным сигналом и его предсказанным в передатчике значением. Эта разность суммируется со значением, предсказанным в приемнике.
Доказано, что среднеквадратичная ошибка предсказания минимальна, если рассчитать коэффициенты в (24), используя знание функции автокорреляции передаваемого сигнала. В кодерах с адаптивной дифференциальной ИКМ передается ошибка предсказания и параметры предсказателя, переменные во времени (спектральные характеристики речи сохраняются 20 -50 мс). Этот метод настолько эффективен, что в некоторых системах ошибка предсказания не передается, т. к. она оказывается пренебрежимо малой. На практике применяется большое число весьма сложных алгоритмов и кодеров, уменьшающих избыточность при кодировании речи и изображения.
5.2. Код Хэмминга как пример помехоустойчивого кода
Дадим определение некоторых понятий помехоустойчивого кодирования.
Кодовое (хэмминговое) расстояние - число несовпадающих разрядов двух кодовых комбинаций.
Минимальное расстояние, взятое по всем парам разрешенных кодовых комбинаций, называется минимальным кодовым расстоянием (d).
Кратность ошибки (r) - число искаженных символов кодовой комбинации.
Вес кодовой комбинации - число единиц в двоичной кодовой комбинации
Блоковый (n, k) код - код, содержащий 2к разрешенных комбинаций из 2n возможных ( n - общее число разрядов, к -число информационных разрядов).
Относительная избыточность кода (n-k)/k , кодовая скорость - k/n . Вектор ошибки - двоичный код, содержащий 1 в искаженных разря-
дах и 0 в остальных.

Разделимый блоковый код - код, в котором часть символов совпадает с информационными символами, остальные символы добавлены как проверочные. В неразделимом коде исходная кодовая комбинация преобразуется так, что невозможно определить, какие символы информационные, а какие проверочные.
Систематический код - код, в котором проверочные символы добавляются после информационных (а не размещаются где-то между информационными символами).
Линейный код - код, в котором значения проверочных символов являются результатом линейных операций над информационными символами.
Непрерывный код: введение контрольных символов в информационную последовательность производится непрерывно, без разделения ее на отдельные блоки.
Ошибка кратности r может быть обнаружена при условии d ≥ r + 1, ошибка кратности s может быть исправлена при условии d ≥ 2s + 1. Если выполняется условие d ≥ r + s + 1 (r ≥ s), то может быть обнаружена ошибка кратности r и, одновременно, исправлена ошибка кратности s. Исправление ошибки производится заменой запрещенной кодовой комбинации на "ближайшую" разрешенную. Такое декодирование называют декодированием по методу максимального правдоподобия.
Оценим долю обнаруживаемых ошибок. Общее число вариантов передачи кода 2к 2n : при передаче любой разрешенной кодовой комбинации может быть получена любая из 2n возможных кодовых комбинаций. Число правильных вариантов передачи 2k. Число вариантов не обнаруживаемых ошибок 2k(2k- 1): при передаче любой разрешенной кодовой комбинации может быть получена любая другая разрешенная комбинация. Число вариантов передачи, когда ошибка обнаруживается, равна 2k(2n-2k) , а их доля по отношению к общему количеству вариантов 1 - 2k-n .
Простейшим способом обнаружения ошибки кратности 1 является добавление одного избыточного разряда - бита четности к каждой кодовой комбинации. Если составить матрицу из строк - информационных кодовых комбинаций и добавить биты контроля четности к каждой строке и к каждому столбцу, то контроль по строкам и столбцам позволяет обнаружить ошибки кратности r >1.
Если ставится задача исправления ошибки, контрольная кодовая комбинация должна указывать место ошибки. Следовательно, число различных контрольных кодовых комбинаций должно быть не менее количества различных ошибок. При s = 1 должно выполняться условие
2n-k-1 > n = Cn1 |
(25) |
(число различных ошибок кратности 1 равно n , число различных контрольных кодовых комбинаций 2n-k-1), при s = 2 - условие
2n-k-1 > Cn1+ Cn2
и т.д. Если s =1 и к=4; 7; 12, из условия (25) получим n=7, 11, 17, а относительная избыточность (n-k)/n=0,43; 0,36; 0,29 соответственно. Из этого примера видно, что с ростом n относительная избыточность уменьшается, а доля обнаруживаемых ошибок увеличивается.
Векторы ошибок |
синдром |
|
|
а1+а3+а5+а7=0 |
|
|
|
||||||||
а7 |
а6 |
а5 а4 а3 а2 а1 |
|
|
б) |
а2+а3+а6+а7=0 |
д) |
|
111 |
||||||
|
|
|
|||||||||||||
0 |
0 |
0 |
0 |
0 |
0 |
1 |
001 |
= 1 |
|
|
а4+а5+а6+а7=0 |
|
|
110 |
|
0 |
0 |
0 |
0 |
0 |
1 |
0 |
010 |
= 2 |
|
|
|
|
|
|
101 |
а) 0 |
0 |
0 |
0 |
1 |
0 |
0 |
011 = 3 |
|
|
а1=а3+а5+а7 |
H= |
|
011 |
||
0 |
0 |
0 |
1 |
0 |
0 |
0 |
100 = 4 |
в) |
|
а2=а3+а6+а7 |
|
|
100 |
||
0 |
0 |
1 |
0 |
0 |
0 |
0 |
101 = 5 |
|
|
а4=а5+а6+а7 |
|
|
010 |
||
0 |
1 |
0 |
0 |
0 |
0 |
0 |
110 = 6 |
|
|
|
|
|
|
001 |
|
|
|
|
|
|
|
||||||||||
1 |
0 |
0 |
0 |
0 |
0 |
0 |
111= 7 |
|
|
|
|
|
|
||
|
|
1000 111 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
0100 110 |
|
|
|
|
|
|
|
|
|
г) |
Mn,k = Ik, Pk, n-k = |
|
0010 101 |
|
|
|
|
|||
|
|
|
|
|
|
|
Рис.34 |
|
|
0001 011 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Методику выявления и исправления ошибки поясним на примере кода Хэмминга (7, 4), исправляющего ошибку кратности 1. Поставим условие: двоичное число в контрольных разрядах, называемое синдромом, должно быть равно номеру исправляемого разряда. На рис. 34а указаны все возможные векторы ошибок и соответствующие им кодовые комбинации в контрольных разрядах. Ошибка может произойти в любом разряде (а1…а7), как в информационном, так и в контрольном. Как следует из рис 34, единица в младшем (правом) разряде синдрома означает, что ошибка произошла в каком-то одном из разрядов а1, а 3, а 5 ,а7, единица в следующем разряде - что ошибка в одном из разрядов а2, а3 , а6, а7, единица в старшем разряде - что ошибка в одном из разрядов a4, a5, a6, a7. Среди указанных разрядов есть контрольные. Следовательно, их значения должны быть заданы так, чтобы при отсутствии ошибок выполнялись проверочные равенства рис.34б. Для того, чтобы каждый контрольный разряд вычислялся независимо от остальных только по информационным разрядам, в каждое проверочное равенство должен входить только один контрольный разряд. Этому условию удовлетворяют разряды a1, a2, a4. Правила определения значений контрольных разрядов приведены на рис. 34 в.
Процесс исправления ошибки поясним на примере. Допустим, что значение информационной части кодовой комбинации, записанной в разрядах а7 а6 а5 а3 , равно 6=011- 0 - - . Значения контрольных разрядов а1=а3 + а5 + а7 = 0+1+0=1,
а2 = а3 + а6 + а7 = 0+1+0=1, а4=а5+а6+а7=1+1+0=0. Получили кодовую комбинацию 0110011. Внесем ошибку в разряд 6: 0010011. Проверочные равенства дадут следующий результат: а1+а3+а5+а7=1+0+1+0=0, а2+а3+а6+а7=1+0+0+0=1, а4+а5+а6+а7=0+1+0+0=1. Синдром 110=6 указывает номер искаженного разряда.
При построении более сложных кодов используют аппарат алгебры, в частности, теорию полей Галуа, и машинные алгоритмы. Одним из способов построения кодов является использование порождающей матрицы кода. Все разрешенные кодовые комбинации образуются суммированием некоторого количества строк этой матрицы. Порождающая матрица может быть задана неоднозначно, в наиболее удобной форме она состоит из единичной матрицы Ik, к которой "приписана" матрица дополнения - Pk. n-k. Порождающая матрица Мn,k вышерассмотренного кода Хэмминга (7,4) приведена на рис. 34г. Разрешенную кодовую комбинацию получают умножением информационной кодовой комбинации на порождающую матрицу. Чтобы проверить принятый код, его надо умножить на проверочную матрицу H, у которой первые к строк - это строки матрицы Pk. n-k, остальные n-к строк - строки единичной матрицы (рис.34д).
5.3. Циклические коды
Почти все применяемые в настоящее время блоковые коды (в том числе код Хэмминга) являются циклическими. У них в качестве образующей матрицы можно взять матрицу со строками, полученными циклическим сдвигом одной строки - образующей кодовой комбинации. Двоичную кодовую комбинацию можно представить в виде многочлена относительно фиктивной переменной х: кодовой комбинации 001011 будет соответствовать многочлен g(x)=x3+x1+x0. Циклическому сдвигу, т.е. сдвигу с переносом единицы переполнения в младший разряд, соответствует умножение многочлена g(x) на х с операцией "приведения" по модулю хn+1. В результате такого сдвига получается многочлен g(x)x - xn +1 = g(x)x +xn+1. Если g(x) – многочлен, представляющий образующую кодовую комбинацию, разрешенной кодовой комбинации соответствует многочлен вида
∑ g(x)xi + c(xn +1), c = 0, 1, i
который делится без остатка на g(x), если (xn+1) делится на g(x). Многочлен g(x) выбирается так, чтобы последнее условие удовлетворялось. Если принятая кодовая комбинация не делится на образующий многочлен, она ошибочна. Некоторые коды только обнаруживают ошибку, некоторые исправляют ее, анализируя величину остатка от деления на образующий многочлен. Для коррекции ошибок важно, чтобы число различных остат-
ков было как можно больше. Этому требованию удовлетворяют неприводимые образующие многочлены g(x), не разлагающиеся на множители. Кодирование и декодирование циклических кодов основано на операциях умножения и деления многочленов, выполняемых с использованием сдвиговых регистров с обратными связями.
5.4. Непрерывные коды и коды с чередованием
Среди непрерывных кодов наиболее простыми по технической реализации являются сверточные коды. Принцип сверточного кодирования поясняет рис.35а. Кодер содержит сдвиговый регистр из Кк триггеров, n сумматоров и коммутатор. Биты входной информационной последовательности вводятся в регистр группами по к разрядов. Чаще всего принимают к = 1. На каждый такт сдвига, т.е. на каждые к входных битов, коммутатор снимает с сумматоров и выдает на выход кодера n битов, так что кодовая скорость (степень кодирования) равна k/n. Каждый бит входной последовательности находится в регистре в течение К сдвигов, оказывая влияние на биты выходной последовательности. Параметр К называют
длиной кодового ограничения. |
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
кК триггеров |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
к |
|
|
к |
|
к |
|
|
g1 |
|
|
|
|
|
вход |
1 |
||||||||
|
|
|
|
|||||||||||||||||||||||
вход |
|
|
к |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
к |
|
|
|
|
|
к |
|
|
|
|
|
|
|
|
|
|
выход 111011 |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
------------------------ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
вход |
1 0 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
g2 |
|
|
|
|
11 10 11 |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
1 |
|
|
|
|
|
|
|
|
|
|
|
n |
|
00 0000 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
выход |
____ |
_ ___ 111011 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
g1 = 7 = 111 = x2 + x + 1 |
выход |
11 10 001011 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
g2 = 5 = 101 = x2 + 1 |
|
|
||||||||||
|
|
|
|
|
|
|
а |
|
|
|
|
|
|
|
|
б |
|
в |
||||||||
Рис.35
Способы описания сверточного кода рассмотрим на примере, показанном на рис 35б (n = 2, кодовая скорость 0,5, К = 3). Один из способов описания кода - задание порождающих векторов, или порождающих многочленов gi , определяющих вид связей регистра с сумматорами, а следовательно и характеристики кода. Другой способ - задание импульсной характеристики кодера: выходной битовой последовательности, формируемой при подаче на вход кодера одной единицы. Реакцию на любую входную последовательность можно получить, суммируя по модулю 2 смещенные импульсные характеристики. Как видно из примера рис. 35в, на один входной бит кодер выдает 6 выходных битов, а не 2 согласно кодовой скорости. Лишние 4 битовых позиции занимает "очистка" кодера, т.е.
приведение регистра в исходное состояние после прохождения информационной последовательности битов. В некоторых системах сверточный код искусственно делят на блоки. В этом случае после прохождения каждого блока необходимо добавить биты для очистки кодера.
Работа кодера может описываться диаграммой состояний, изображенной в виде направленного графа (рис.36). Кодер, показанный на рис 35б, может находиться в одном из четырех состояний, зависящих от содержания двух триггеров регистра (состояние первого триггера определяется входным битом). Стрелки на графе указывают возможные изменения состояний при поступлении на вход кодера единицы (показаны сплошной линией) или нуля (пунктирные линии). Каждый переход помечен кодовой комбинацией, появляющейся на выходе кодера при этом переходе.
00 |
|
|
|
|
t1 00 t2 00 t3 |
00 t4 |
00 t5 состояния |
|
|
|
|
|
|
|
|||
|
|
000 00 |
|
|
|
|
00 |
|
11 |
11 |
11 |
11 |
|
||||
|
|
|
|
01 |
||||
|
10 |
|
|
11 |
00 |
|||
10 |
|
01 |
|
|||||
|
|
|
|
|
||||
|
|
|
|
10 |
|
|
||
|
00 |
|
|
|
10 |
|||
|
|
|
|
|
||||
01 |
|
|
01 |
|
|
|||
|
|
|
|
01 |
||||
|
|
11 |
|
|
|
|
||
|
|
|
01 |
|
01 |
|||
|
|
|
|
|
|
|
||
10 |
|
|
|
|
|
11 |
||
|
|
|
|
|
||||
|
|
|
|
10 |
10 |
|||
|
|
|
|
|
|
|
||
|
|
Рис.36 |
|
|
Рис.37 |
|
|
|
По диаграмме состояний рис.36 построена "решетчатая" диаграмма рис.37, представляющая процесс изменения состояний кодера во времени при поступлении на вход любой битовой последовательности. Начальное состояние - 00. Как видно из диаграммы, после К переходов (К=3) картина переходов повторяется.
Каждому переходу соответствует двухбитовая (n=2) кодовая комбинация, вырабатываемая кодером при этом переходе. Эти дибиты составляют "правильную" кодовую комбинацию, соответствующую конкретному пути в решетке. Один из алгоритмов декодирования (алгоритм Витерби, или алгоритм максимального правдоподобия) сравнивает принятую декодером кодовую комбинацию с правильными, соответствующими различным путям в решетке, и заменяет на ту, которая по кодовому расстоянию ближе всех к принятой. Число различных путей в решетке очень велико. Объем вычислений минимизируется соответствующим построением алгоритма. Как видно из рис.37, в каждое состояние, начиная с t4, ведут 2 пути. Для каждого пути t1-t4 определяется метрика - кодовое расстояние между принятой кодовой комбинацией и кодовой комбинацией, соответствующей данному пути. Из всех путей, ведущих в данное состояние, вы-
бирается один путь с минимальным кодовым расстоянием, остальные пути отбрасываются как "тупиковые". После просмотра путей, ведущих в состояния ti , просматриваются и отбрасываются тупиковые пути, ведущие в состояния ti+1 и т.д. Начиная с некоторого ti , начальный участок у всех "выживших" путей оказывается одним и тем же. Соответствующая этому участку кодовая комбинация считается достоверной. По мере роста номера i длина общего участка, а следовательно и скорректированной части принятой кодовой последовательности, увеличивается. Сверточные коды получили широкое применение, т.к. оказались во многих случаях лучше блоковых при сопоставимой сложности аппаратной реализации кодера и декодера.
Исходная последовательность
a1a2..anb1b2…bnc1c2…cnd1d2…dne1e2…enf1f2…fn после чередования (c пакетом ошибок)
a1b1c1d1e1f1a2b2c2d2e2f2a3b3c3d3e3f3….
х х х х х
после процедуры, обратной чередованию: a1a2a3…anb1b2b3…bnc1c2c3…cnd1d2…dne1e2…enf1f2…fn
x x x x x ошибочные биты разнесены по времени
рис.38
Для коррекции пакетов ошибок применяются коды с чередованием (перемешиванием). Биты исходной информационной последовательности располагаются после перемешивания в другом порядке, например, как показано на рис.38. Если появляется пакет ошибок, то после процедуры, обратной чередованию, ошибочные биты распределяются по одному в различные кодовые комбинации. Благодаря этому коррекция ошибок упрощается.
В современных системах помехоустойчивое кодирование осуществляется в несколько этапов разными методами, включая блочное и сверточное кодирование, чередование. На каждом этапе, в свою очередь, используется несколько помехоустойчивых кодов, выявляющих различные виды ошибок (каскадные коды, турбокоды и т.д.).
6. Сигналы с расширенным спектром (сложные)
Спектр сигнала расширяют: а) модуляцией псевдослучайной импульсной последовательностью (прямое расширение спектра), б) скачкообразной перестройкой частоты по случайному закону, в) случайной перестановкой пакетов сообщений, г) линейной частотной модуляцией и ком-
бинацией перечисленных методов. Прямое расширение спектра поясняет рис. 39. Сигнал s(t) с шириной спектра Пс , после одного из этапов формирования, модулируется псевдослучайной последовательностью (ПСП) разнополярных импульсов. В результате модуляции спектр сигнала переносится в высокочастотную область и занимает полосу Пшс. В приемнике сигнал вместе с помехой модулируется той же самой ПСП, синхронизованной с ПСП передатчика. При этом вид сигнала и его спектр восстанавливаются, а спектр помехи расширяется, занимая полосу Пшс. Мощность помехи распределяется по всей полосе. Восстановленный демодулятором сигнал (вместе с помехой) пропускается через фильтр с полосой Пс.
ПСП=g(t)
S(t) |
t |
|
S(t) g(t)
Рис.39
Мощность помехи после фильтра уменьшается в П шс / Пс раз, а мощность сигнала сохраняется прежней. Следовательно, отношение сигнал-шум увеличивается, благодаря расширению спектра, в Gp = П шс/ Пс раз. Это отношение называют коэффициентом расширения спектра. Улучшение отношения сигнал-шум происходит только при ограниченном спектре помехи. В случае белого шума расширение спектра не эффективно.
При прямом расширении спектра используют квадратурную модуляцию или модуляцию 2ФМ, при этом один символ сообщения представлен ПСП, содержащей N элементарных символов. Т.к. Пс ≈ Rs , Пшс ≈ Rэс , где Rs и Rэс - скорости передачи символов сообщения и элементарных символов ПСП, то Gp =Rэс /Rs=N. Технические ограничения на длительность элементарных символов ПСП ставят предел увеличению Gp при прямом расширении спектра.
При расширении спектра методом скачкообразной перестройки частоты применяют М-арную частотную манипуляцию. М символам соответствуют М частот, разнесенных друг от друга на интервал f. Центральная
частота f0 этого диапазона изменяется скачками под управлением ПСП в полосе перестройки Пh. Применяют быструю перестройку с несколькими скачками частоты за время передачи одного символа сообщения и медленную, когда скачок частоты происходит с интервалом, равным длительности нескольких символов. Из-за скачков частоты трудно сохранить когерентность сигнала. Поэтому демодуляция обычно некогерентная. Для обеспечения ортогональности сигналов расстояние между соседними частотами должно удовлетворять условию f = 1/ Ts. Полосу сигнала после расширения спектра можно считать равной Пh, т.к. в сигнале может присутствовать любая частота из полосы перестройки. Ширина спектра до расширения определяется длительностью символа Тs – интервалом времени, в течение которого частота сигнала остается постоянной (Пс=1/Ts). Следовательно, коэффициент расширения частоты Gp = Ts Пh = Пh / f. Его значение может быть значительно больше, чем при прямом расширении спектра.
Системы с расширением спектра обеспечивают конфиденциальность сообщения: сигнал нельзя принять, не зная ПСП. На одной частоте, используя разные ПСП, можно одновременно передавать несколько различных сообщений. Эта возможность используется в многоканальных системах с кодовым разделением каналов.
Преимуществом систем с расширением спектра является возможность уменьшения мощности сигнала за счет увеличения его длительности. Благодаря этому ослабляется взаимное влияние разных каналов, работающих в одном частотном диапазоне. Затрудняется обнаружение и перехват сигнала, что особенно важно для военных систем.
Увеличение длительности сложного сигнала не ухудшает разрешающей способности системы по времени. Два накладывающихся по времени сигнала будут приняты как различные, если задержка одного сигнала относительно другого превышает длительность элементарного символа ПСП. Эта возможность используется в системах с многолучевым распространением сигнала. Из сигналов, пришедших разными путями, т.е. с разными временными задержками, принимается только один независимо от остальных. Несколько сдвинутых по времени сигналов можно принять разными устройствами, а затем суммировать и тем самым увеличить энергию принятого сигнала. На этом принципе основана работа RAKE - приемника.
Псевдослучайная кодовая комбинация в начале текста сообщения может выполнять роль синхропосылки, позволяя найти начало сообщения и синхронизовать приемник. Эта возможность используется, в частности, в многоканальных системах с разделением каналов по времени.
6.1. Псевдослучайные последовательности
Для формирования сигналов с расширенным спектром используются псевдослучайные последовательности - кодовые комбинации, в которых нельзя обнаружить какой-либо закономерности в появлении символов 1 и 0. Конкретную ПСП необходимо безошибочно обнаруживать в принятой последовательности символов и точно определять ее начало. Это возможно при "хороших" корреляционных свойствах ПСП. Не должно быть корреляции между различными ПСП и автокорреляции ПСП с любой своей сдвинутой копией.
Корреляционные свойства описываются функциями автокорреляции (ФАК) и взаимной корреляции (ФВК), периодическими и апериодическими. Корреляционные функции вычисляются как суммы поразрядных произведений двух двоичных кодовых комбинаций. При перемножении символы 0 и 1 представляются как -1 и +1 соответственно. Таким образом, корреляционная функция равна разности между числом совпадающих и не совпадающих разрядов двух кодовых комбинаций. В процессе вычисления функции корреляции одна из кодовых комбинаций сдвигается. Если сдвиг циклический (рис.40а), вычисляется периодическая функция корреляции, если сдвиг простой (рис.40б) - апериодическая функция корреляции. Значения отсутствующих разрядов принимаются равными 0, а не ±1. ФВК называется смешанно-периодической, если двоичная комбинация сравнивается с последовательностью, состоящей из различных кодовых комбинаций (рис.40в).
В идеальном случае ФАК имеет один максимум, равный N - числу элементарных символов в ПСП, и не превышает ±1 при любом сдвиге ПСП. Идеальной ФАК, периодической и апериодической, обладают только коды Баркера. Они существуют при N= 3, 4, 5, 7, 11 и 13. Это коды 6, D, 1D, 72, 712, 1F35 (в 16-ричном представлении).
Одним из классов ПСП являются двоичные последовательности, генерируемые сдвиговым регистром с обратными связями. Выходы с некоторых разрядов регистра, выбранные в соответствии с порождающим многочленом, поступают на вход сумматора по модулю 2. Выход сумматора соединен с входом регистра. Если задать любой начальный код регистра, кроме нулевого, и подать на регистр тактовые импульсы, код регистра начинает меняться с каждым тактом. Коды регистра будут повторяться с периодом Т. Если порождающий многочлен неприводимый, период имеет максимально возможное значение Т = 2n -1, где n - число разрядов регистра. Поэтому соответствующую ПСП, снимаемую с выхода сумматора, на-
зывают m- последовательностью, или последовательностью максимальной длины. ПСП, снятые с любого разряда и при любых начальных кодах регистра, имеют одинаковую длину и образуются одна из другой циклическим сдвигом. Все m - последовательности длины N, генерируемые при различных порождающих многочленах, могут быть получены из любой одной последовательности путем децимации - выбора из данной последовательности каждого q-го символа. Значение q должно удовлетворять оп-
ределенным условиям. |
|
|
|
|
||
|
ФАК |
а) периодические |
ФВК |
|||
|
|
|
|
|
|
|
ПСП 1 |
|
|
|
ПСП 1 |
|
|
|
|
|
|
|
|
|
ПСП 1 |
|
|
|
ПСП 2 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
б) апериодические |
|
|
|
|
|
|
|
|
|
|
ПСП 1 |
|
|
|
ПСП 1 |
|
|
|
|
|
|
|
|
|
ПСП 1 |
|
|
|
ПСП 2 |
|
|
|
|
|
|
|
||
в) смешанно-периодическая ФВК
ПСП 1
ПСП 2 

 ПСП 3
ПСП 3
Рис.40
ФВК и апериодическая ФАК у m- последовательностей не идеальные. Для многоканальных систем с кодовым разделением каналов необходимо иметь большое число ПСП заданной длины с возможно меньшими значениями боковых максимумов ФАК и ФВК, периодических и апериодических. Только некоторые из m- последовательностей удовлетворяют этим требованиям. К настоящему времени разработаны достаточно большие ансамбли ПСП других типов, в том числе формируемые с использованием m- последовательностей, в частности, последовательности Голда и Касами.
6.2. Понятие согласованного фильтра
Задачей приемного устройства может быть обнаружение сигнала, т.е. установление факта приема сигнала определенной, известной заранее формы. Вероятность обнаружения сигнала на фоне помех повышается при
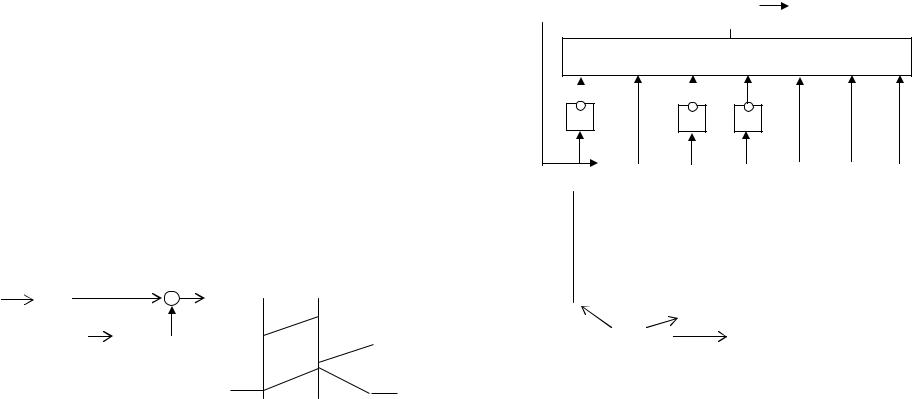
использовании согласованного фильтра. Такой фильтр собирает всю распределенную по времени энергию сигнала к моменту его окончания и в этом смысле является оптимальным. Отношение пикового значения сигнала на выходе фильтра к уровню помех существенно повышается.
Прием цифрового сигнала можно рассматривать как задачу обнаружения. При М-арном кодировании приемник содержит М фильтров. Каждый фильтр «настроен» на сигнал определенного вида, соответствующий одному из М символов (согласован с сигналом). При согласованном фильтре максимальное значение сигнала на выходе фильтра зависит только от энергии сигнала и не зависит от его формы. Частотные характеристики фильтра должны удовлетворять следующим требованиям. Чтобы увеличить пиковое значение сигнала на выходе фильтра, все спектральные составляющие сигнала надо совместить по фазе, т.е. к фазовому сдви-
гу спектральной составляющей |
ϕ с (ω) добавить фазовый сдвиг ϕ k (ω) |
|
так, чтобы выполнялось условие ϕ с+ ϕ k=-τ ω, где |
τ - постоянный коэф- |
|
фициент (задержка сигнала по |
времени). Кроме |
того, амплитудно- |
частотная характеристика фильтра должна быть пропорциональна спектральной плотности принимаемого сигнала: гармоники с большим отношением сигнал-шум надо усилить, с малым - ослабить.
Оптимальный согласованный фильтр физически осуществим не для любого сигнала. Фильтр для прямоугольного импульса , содержащий
Uвх |
T |
U1 |
+ |
|
|
|
|
Uвых |
Uвх |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|||||||||
|
∫ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
- |
U1 |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
T |
|
|
|
|
U2 |
|
|
|
|
|
|
|
|
|
|
|
U2 |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Uвых
Рис. 41
интегратор, цепь задержки и вычитающее устройство, показан на рис.41. К моменту окончания импульса сигнал на выходе интегратора равен площади импульса, т.е. его энергии. После снятия отсчета интегратор, вообще говоря, можно сбросить, так что аналогичный результат будет получен при использовании одного интегратора со сбросом (если момент сброса известен).
На рис. 42 показан фильтр, согласованный с псевдослучайной последовательностью видеоимпульсов, описываемой кодом Баркера 1110010. В ней символам 1 и 0 соответствуют прямоугольные импульсы с длительностью Тs и амплитудой +1 и -1 соответственно. Сигнал проходит через це-
почку элементов задержки на Тs , выходы которых подключены к сумматору непосредственно или через инверторы. Место установки инверторов
0100111 |
СФИ |
|
|
Сумматор
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Σ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-1 |
1- |
1+ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|||
1- |
1+ |
|
|
|
|
|
1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-1 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
0+ |
1+ |
|
|
|
|
|
1- |
|
|
|
|
|
1- |
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
0+ |
0- |
|
|
|
|
|
1- |
|
|
|
|
|
1- |
1+ |
|
|
|
|
|
|
|
|
|
-1 |
||||||
1- |
0- |
|
|
|
|
|
0+ |
|
|
|
|
|
1- |
1+ |
1+ |
|
|
|
|
|
0 |
|||||||||
0+ |
1+ |
|
|
|
|
|
0+ |
|
|
|
|
|
0+ |
1+ |
1+ |
1+ +7 |
||||||||||||||
|
0- |
|
|
|
|
|
1- |
|
|
|
|
|
0+ |
0- |
1+ |
1+ |
0 |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
0+ |
|
|
|
|
|
1- |
0- |
0- |
1+ |
-1 |
||||||||||
инвертируются |
|
|
|
|
|
|
|
|
0+ |
1+ |
0- |
0- |
0 |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0- |
1+ |
0- |
-1 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0- |
1+ |
0 |
|||||||
|
|
|
|
|
|
|
|
|
|
Рис.42 |
|
|
|
|
|
|
|
|
|
0- |
0 |
|||||||||
определяется расположением символов 0 в коде Баркера. Выходной сигнал сумматора - прямоугольный импульс амплитуды 7 на такте №7, в остальное время выходной сигнал равен 0 или -1. СФИ – это фильтр, согласованный с прямоугольным импульсом (рис. 41). На выходе СФИ формируется треугольный импульс с максимумом в момент окончания такта №7, пропорциональным общей энергии входного сигнала. Фактически согласованный фильтр вычисляет функцию автокорреляции входного сигнала.
В системе с прямым расширением спектра двоичные символы ПСП обычно передаются фазоманипулированным сигналом, например 2ФМ. Согласованный фильтр аналогичен показанному на рис.42, только интегратор в СФИ заменяется высокодобротным колебательным контуром для