

676_Noskova_N.V._Izuchenie_funktsionirovanija_setej_
.pdfдлинный двоичный код. Биты в каждом кодовом слове передаются по каналу посредствам ФМ или, возможно, ЧМ.
Рисунок 2.4 - Структурная схема каскадной схемы кодирования
Также необходимо сказать, что минимальное расстояние для каскадного кода равно dmin Dmin , где Dmin – это минимальное расстояние для внешнего кода, a dmin – минимальное расстояние для внутреннего кода. Далее,
Kk
скорость каскадного кода равна Nn , что равно произведению скоростей
двух кодов.
Декодер жёстких решений для каскадного кода удобно разделить на внутренний декодер и внешний декодер. Внутренний декодер выполняет жёсткое решение по каждой группе из п бит, соответствующие кодовому слову внутреннего кода, и выносит решение о k информационных битах, основываясь на алгоритме максимального правдоподобия (минимума расстояния). Эти k бит представляют один символ внешнего кода. Когда принят блок из N k -битовых символов от внутреннего декодера, внешний декодер принимает жёсткое решение по К k -битовым информационным символам, основываясь на декодирование по правилу максимального правдоподобия.
При каскадном кодировании возможно и декодирование мягких решений. Обычно оно выполняется по внутреннему коду, если он выбран так, что имеет немного кодовых слов, т е. 2k не очень велико. Внешний код обычно декодируется посредствам декодера жёстких решений, особенно если длина блока велика и имеется много кодовых слов. С другой стороны, можно достичь достаточный выигрыш в качестве при использовании декодирования мягких решений по внутреннему и внешнему кодам, чтобы оправдать дополнительную сложность декодирования.
31
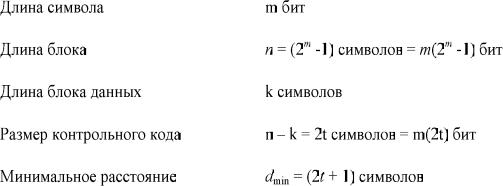
Внутренний код связан с модулятором (демодулятором) и каналом; он, как правило, настраивается для исправления большинства канальных ошибок. Внешний код, чаще всего с низкой избыточностью, снижает вероятность появления ошибок до заданного значения. Основной причиной использования каскадного кодирования являются низкая избыточность (высокая скорость) кодирования и меньшая сложность реализации, которая потребовалась бы для осуществления с какой-то одной ступенью кодирования. На рисунке 2.4 между двумя этапами кодирования располагается устройство перемежения. Делается это для того, чтобы разнести пакеты ошибок, которые могут возникать в результате внутреннего декодирования [8].
2.2.1 Коды Рида-Соломона
Коды Рида-Соломона (Reed-Solomon codes – RS codes) – это широко используемый подкласс недвоичных кодов БЧХ [2, 8, 10, 11].
При использовании кодов Рида-Соломона данные обрабатываются порциями по m бит, именуемыми символами. Код (n, k) характеризуется следующими параметрами.
Таким образом, алгоритм кодирования расширяет блок k символов до размера n , добавляя (n – k) избыточных контрольных символов. Как правило, m > 1 является степенью 2, широко используется значение m = 8.
Коды Рида-Соломона удобны для исправления пакетов ошибок. Данный тип кодов характеризуется высокоэффективным использованием избыточности, длина блоков и размеры символов могут легко приспосабливаться под сообщения разных размеров. Кроме того, для таких кодов существуют эффективные методы кодирования.
Коды Рида-Соломона (n, k) определены на m-битовых символах при всех n и k , для которых
0 k n 2m 2, |
(2.10) |
где k число информационных бито, подлежащих кодированию, n – число бит в закодированном блоке.
32
Для большинства кодов Рида-Соломона (n, k) |
|
(n,k) (2m 1,2m 1 2t), |
(2.11) |
где t – количество ошибочных бит в символе, которые может исправить код,
n –k = 2t – число контрольных символов.
Расширенный код Рида-Соломона можно получить только при n = 2m
или n = 2m + 1.
Код Рида-Соломона обладает наибольшим минимальным расстоянием, возможным для линейного кода с одинаковой длиной входных и выходных блоков кодера. Для недвоичных кодов расстояние между двумя кодовыми словами определяется (по аналогии с расстоянием Хэмминга) как число символов, которыми отличаются последовательности. Для кодов РидаСоломона минимальное расстояние определяется следующим образом
dmin n k 1. |
(2.12) |
Код, который исправляет все искаженные символы, содержащие ошибки в t или меньшем числе бит, t можно выразить следующим образом
t |
d |
min |
1 |
|
n k |
|
||||
|
|
|
|
|
|
|
. |
(2.13) |
||
|
2 |
|
2 |
|||||||
|
|
|
|
|
|
|
|
|||
Здесь x означает наибольшее целое, не превышающее х. Из (2.13)
видно, что коды Рида-Соломона, исправляющие t символьных ошибок, требуют не более 2t контрольных символов. Следовательно, декодер имеет n – k «используемых» избыточных символов, количество которых вдвое превышает количество исправляемых ошибок. Для каждой ошибки один избыточный символ используется для обнаружения ошибки и один для определения правильного значения.
Преимущества недвоичных кодов, подобных кодам Рида-Соломона, можно показать следующим образом. Рассмотрим двоичный код (n, k) = (7, 3). Полное количество кодовых слов в нем равно 2n = 27 = 128, из которых 2k = 23 = 8 (или 1/16 часть всех кодовых слов) являются разрешенными кодовыми словами.
Теперь рассмотрим недвоичный код (n, k) = (7,3), где каждый символ состоит из m =3 бит. Полное количество кодовых слов в таком коде равно 2nm = 221 = 2 097 152 , из которых 2km =29 = 512 (или 1/4096 часть всех кодовых слов, т.е. очень небольшая часть) являются разрешенными кодовыми словами.
Из сравнения двоичных и недвоичных кодов следует, что в последних используется только незначительная часть полного количества кодовых слов, и это дает возможность достичь большего значения dmin.
33
Рассмотрим на примере способность кода Рида-Соломона исправлять пакеты ошибок, которые могут быть вызваны либо импульсными помехами, либо глубокими замираниями сигнала в радиотракте [8, 11].
Возьмем для примера код (n, k) = (255,247), в котором каждый символ состоит из т = 8 бит (такие символы принято называть байтами). Поскольку п – k = 8, из уравнений (3.12) и (3.13) можно видеть, что этот код может исправлять любые 4-символьные ошибки в блоке длиной до 255 символов.
2.2.2 Свёрточные коды
Сверточный код задается тремя параметрами: п, k и К. Код (п, k, К) обрабатывает входящие данные порциями по k бит и генерирует выходную последовательность, состоящую из п бит для каждых k бит входа. До этого момента принципы работы сверточных и блочных кодов не отличаются. Для сверточных кодов п и k, как правило, являются очень малыми числами. Разница между двумя типами кодов состоит в том, что сверточные коды используют память, которая характеризуется длиной кодового ограничения К. По сути, текущая п – битовая входная последовательность кода (п, k, К) зависит не только от значений текущего входного блока, состоящего из k бит, но также и от предыдущих (К -1) k - битовых блоков. Следовательно, текущая выходная п-битовая последовательность является функцией последних (K k) входных битов.
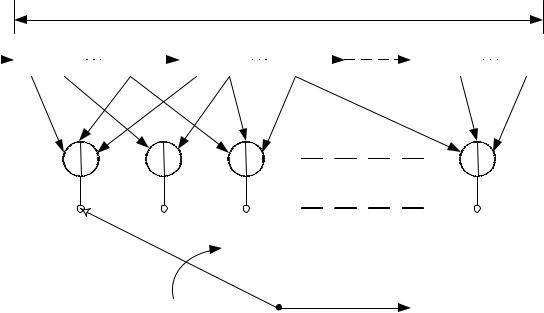
Свёрточный код создаётся прохождением передаваемой информационной последовательности через линейный сдвиговый регистр с конечным числом состояний. В общем случае регистр сдвига состоит из К (k - битовых) ячеек и линейного преобразователя, состоящего из п функциональных генераторов и выполняющего алгебраические функции как показано на рисунке
2.5 [8].
Входные данные к кодеру, которые считаются двоичными, продвигаются вдоль регистра сдвига по k бит за раз. Число выходных битов для каждой k - битовой входной последовательности равно п. Следовательно, кодовая скорость, определённая как Rc = k/n, согласуется с определением скорости блочного кода. Параметр К называется длиной кодового ограничения (или кодовым ограничением) свёрточного кода и указывает число разрядов в регистре сдвига.
Чтобы иметь возможность описывать сверточный код, необходимо определить кодирующую функцию G(m) так, чтобы по данной входной последовательности m можно было быстро вычислить выходную последовательность U. Для реализации сверточного кодирования используется несколько методов; наиболее распространенными из них являются графическая связь, векторы, полиномы связи, диаграмма состояния, древовидная и решетчатая диаграммы [2, 8].
34
Kk ячеек
|
|
|
1 |
2 |
|
|
k |
|
|
1 |
2 |
|
|
k |
|
|
1 |
2 |
|
|
k |
|||||
|
k |
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
информаци |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
онных бит |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
n |
Кодированная последовательность
Рисунок 2.5 - Сверточный кодер
При обсуждении сверточных кодеров в качестве модели будем использовать сверточный кодер, показанный на рисунке 2.6. На этом рисунке изображен сверточный кодер (2, 1, 3) с длиной кодового ограничения К = 3. В нем имеется п =2 сумматора по модулю 2; следовательно, скорость кодирования кода k/n равна 1/2. При каждом поступлении входной бит помещается в крайний левый разряд, а биты регистра смещаются на одну позицию вправо. Затем коммутатор на выходе дискретизирует выходы всех сумматоров по модулю 2 (т.е. сначала верхний сумматор, затем нижний), в результате чего формируются пары кодовых символов, образующих кодовое слово, связанное с только что поступившим битом. Это выполняется для каждого входного бита.
Выбор связи между сумматорами и разрядами регистра влияет на характеристики кода. Всякое изменение в выборе связей приводит в результате к различным кодам. Связь, конечно же, выбирается и изменяется не произвольным образом. Задача выбора связей, дающая оптимальные дистанционные свойства, сложна и в общем случае не решается; однако для всех значений длины кодового ограничения, меньших 20, с помощью компьютеров были найдены хорошие коды.
В отличие от блочных кодов, имеющих фиксированную длину слова п, в сверточных кодах нет определенного размера блока.
Прореживание. Как было уже сказано, скорость внутреннего кода, или отношение числа символов в информационном кадре к общему числу символов, передаваемых в одном кодовом кадре, может изменяться в соответствии с условиями передачи данных в канале связи и требованиями к скорости передачи данных. Чем выше скорость кода, тем меньше его избыточность и тем меньше его способность исправлять ошибки в канале связи.
35
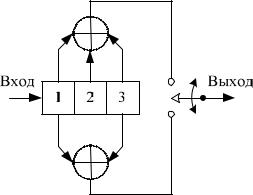
Рисунок 2.6 - Сверточный кодер с параметрами (2, 1, 3)
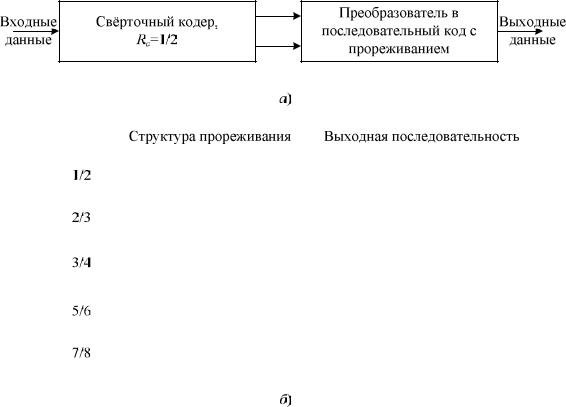
Как правило, внутреннее кодирование с изменяемой скоростью строится с использованием базового кодирования со скоростью 1/2. Основу базового кодера представляют собой два цифровых фильтра с конечной импульсной характеристикой, выходные сигналы которых X и Y формируются путем сложения по модулю двух сигналов, снятых с разных точек линии задержки в виде регистра сдвига из шести триггеров (рисунок 3.7). Входные данные последовательно вводятся в регистр сдвига, а из выходных сигналов фильтров после преобразования в последовательную форму создается цифровой поток, в котором биты следуют друг за другом в два раза чаще, чем на входе (скорость такого кода равна 1/2, так как на каждый входной бит приходится два выходных).
В режимах с большей скоростью кодирования передается лишь часть генерируемых сигналов X и Y (передаваемые сигналы и их порядок приведены в таблице рисунка 3.7). Например, при скорости 2/3 двум входным битам ставятся в соответствие и передаются в последовательной форме три выходных сигнала (X1, Y1, Y2), а X2 вычеркивается. При максимальной скорости внутреннего кода, равной 7/8, семи входным битам соответствуют восемь выходных (X1, Y1, Y2, Y3, Y4, X5, Y6, X7).
2.3Перемежение битов
Вдополнение к помехоустойчивому кодированию в беспроводных системах используют операцию перемежения [2, 8].
Изменение по определенному правилу естественного порядка следования символов в некоторой кодовой последовательности называют процедуру перемежением (Interleaving), обратную перемежению, принято называть деперемежением (deinterleaving). В результате выполнения процедуры
деперемежения |
восстанавливается естественный |
порядок следования |
символов. |
|
|
Методы |
перемежения-деперемежения обычно |
используются для |
разрушения пакетов ошибок, вызванных замираниями уровня принимаемого сигнала, и, следовательно, уменьшения степени группирования ошибок в последовательности символов, поступающих на вход канального декодера.
36
При перемежении передаваемое кодовое слово формируется из символов различных кодовых слов.
X
Y
Rc |
|
|
|
|
|
|
|
|
|
|
X :1 |
X1 |
Y1 |
|
|
|
|
|
|
|
Y :1 |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
X :10 |
X YY |
|
|
|
|
|
||
|
Y :11 |
1 |
1 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
X :101 |
X YY X |
3 |
|
|
|
|||
|
Y :110 |
1 |
1 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
X :10101 |
X YY X Y X |
5 |
|
|||||
|
Y :11010 |
1 |
1 |
2 |
|
3 |
4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
X :1000101 |
X YY YY X Y X |
|
||||||
|
Y :1111010 |
7 |
|||||||
|
1 |
1 |
2 |
3 |
4 |
5 |
6 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рисунок 2.7 - Свёрточное кодирование: а – кодирование с прореживанием; б – таблица прореживания
Поэтому при деперемежении возникающий пакет ошибок разбивается на отдельные ошибки, принадлежащие различным кодовым словам. Иначе говоря, при деперемежении пакет ошибок трансформируется в последовательность независимых ошибок, для исправления которых, как правило, можно использовать менее мощный код. С увеличением глубины перемежения можно ожидать улучшения характеристик помехоустойчивости, поскольку при этом происходит ослабление корреляции ошибок. Но при этом возрастает задержка в доставке сообщения, связанная с выполнением процедур перемежениядеперемежения. Поэтому приходится принимать компромиссное решение между степенью улучшения характеристик помехоустойчивости и возможной задержкой. Рассмотрим некоторые эффективные методы перемежения.
2.3.1 Блоковое перемежение
При блоковом перемежении кодовые слова длиной п символов записываются в виде таблицы шириной W и глубиной D символов (рисунок 2.8) [2, 8].
Предположим, что W=n. Тогда строки таблицы представляют собой кодовые слова, содержащие к информационных символов и (п-к) проверочных
37
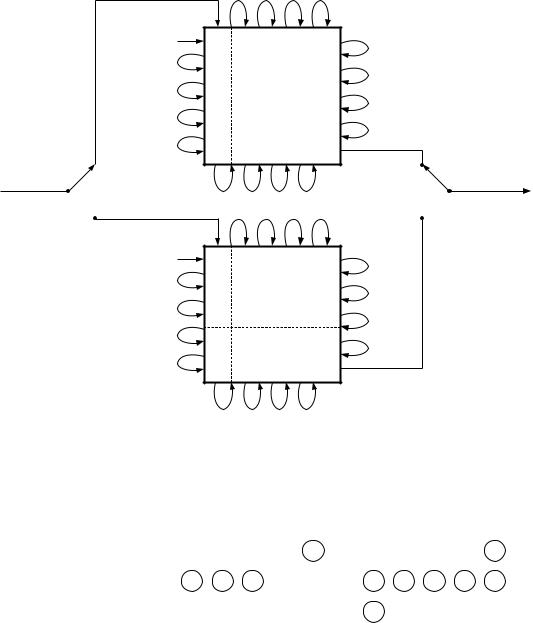
символов. После заполнения таблицы осуществляется последовательное считывание символов по столбцам и их передача по каналу связи. В приемнике устройство восстановления выполняет обратные операции; оно принимает символы из демодулятора, восстанавливает исходный порядок битов и передает их на декодер. Символы поступают в массив устройства восстановления по строкам, а считываются по столбцам. На рисунке 2.9, а приведен пример устройства чередования с М = 5 строками и N = 5 столбцами.
Перемежитель 1
Входные
биты
|
|
Запись |
|
|
|
|
|
|
|
Считы |
1 |
6 |
11 |
16 |
21 |
|
|
|
вание |
|
||||||
|
|
|
|
|
|
|
||
|
|
|
2 |
7 |
12 |
17 |
22 |
|
|
1÷25, |
|
3 |
8 |
13 |
18 |
23 |
|
|
51÷75, |
|
4 |
9 |
14 |
19 |
24 |
|
|
101÷125, |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
и т.д. |
|
5 |
10 |
15 |
20 |
25 |
Выходные |
|
1 |
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
биты |
П1 |
2 |
|
|
|
|
|
2 |
П2 |
26÷50, |
Запись |
|
|
|
|
|
||
|
|
|
|
|
|
|||
76÷100, Считы |
26 |
31 |
36 |
41 |
46 |
|
||
126÷150, вание |
|
|||||||
|
|
|
|
|
|
|||
|
и т.д. |
|
27 |
32 |
37 |
42 |
47 |
|
|
|
|
28 |
33 |
38 |
43 |
48 |
|
|
|
|
29 |
34 |
39 |
44 |
49 |
|
|
|
|
30 |
35 |
40 |
45 |
50 |
|
Перемежитель 2
Рисунок 2.8 - Пояснение принципа работы блочного перемежителя
N=5 столбцов
|
A1 |
B1 |
C1 |
D1 |
E1 |
|
A1 |
B1 |
C1 |
D1 |
E1 |
|
A1 |
B1 |
C1 |
D1 |
E1 |
|
A2 |
B2 |
C2 |
D2 |
E2 |
|
A2 |
B2 |
C2 |
D2 |
E2 |
|
A2 |
B2 |
C2 |
D2 |
E2 |
M=5 |
A3 |
B3 |
c3 |
D3 |
E3 |
|
A3 |
B3 |
С3 |
D3 |
E3 |
|
A3 |
B3 |
С3 |
D3 |
E3 |
строк |
|
|
|||||||||||||||
|
A4 |
B4 |
C4 |
D4 |
E4 |
|
A4 |
B4 |
C4 |
D4 |
E4 |
|
A4 |
B4 |
C4 |
D4 |
E4 |
|
A5 |
B5 |
C5 |
D5 |
E5 |
|
A5 |
B5 |
C5 |
D5 |
E5 |
|
A5 |
B5 |
C5 |
D5 |
E5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
а) |
|
|
|
|
|
б) |
|
|
|
|
|
в) |
|
|
Рисунок 2.9 - Блочное устройство чередования: а) устройство размером
M×N; б) четырёхсимвольный пакет ошибок; в) семисимвольный пакет ошибок.
38
2.3.2 Сверточное перемежение
Помимо блочных устройств перемежения, используются сверточные устройства перемежения. Схема одного из таких устройств представлена на рисунке 2.10 [8].
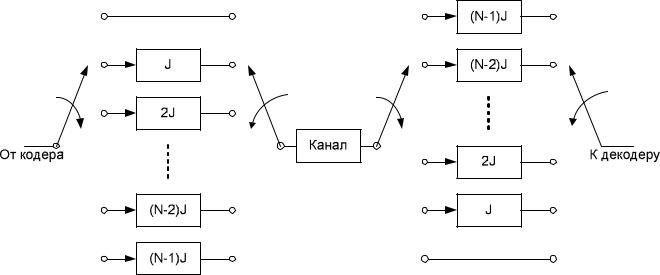
Рисунок 2.10 - Структурная схема сверточного перемежителя -
деперемежителя
Кодовые символы последовательно подаются в блок из N регистров; причем каждый последующий регистр может хранить на J символов больше, чем предыдущий. Нулевой регистр не предназначен для хранения (символ сразу же передается).
С каждым новым кодовым символом коммутатор переключается на новый регистр, и кодовый символ подается на него до тех пор, пока наиболее старый кодовый символ в регистре не будет передан на модулятор передатчика канала. После (N – 1) регистра коммутатор возвращается к нулевому регистру и цикл снова повторяется. После демодулятора приемника канала все операции повторяются в обратном порядке. И вход, и выход устройств перемежения и деперемежения должны быть синхронизированы.
На рисунке 2.11 показан пример простого сверточного четырехрегистрового (J = 1) устройства перемежения/деперемежения, загруженного последовательностью кодовых символов.
При этом последовательности имеют вид:
на входе перемежителя
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, и т.д.;
на выходе перемежителя
39
1, x, x, x, 5, 2, x, x, 9, 6, 3, x, 13, 10, 7, 4, 17, 14, 11, 8, и т.д.;
на выходе деперемежителя
x, x, x, x, x, x, x, x, x, x, x, x, 1, 2, 3, 4, 5, 6, 7, 8, 9, и т. д,
где знак «х» – означает неопределенное состояние.
Одновременно на этом же рисунке представлено синхронизированное устройство восстановления, которое передает обработанные символы на декодер. На рисунке 2.12, а показана загрузка символов 1 – 4; знак "х" означает неизвестное состояние. На рисунке 2.12, б представлены первые четыре символа, подаваемые в регистры, и показана передача символов 5-8 на выход устройства перемежения. На рисунке 2.12, в показаны поступающие в устройство символы 9 – 12. Теперь устройство восстановления заполнено символами сообщения, но еще не способно ничего передавать на декодер. И, наконец, на рисунке 2.12, г показаны символы 13 – 16, поступившие в устройство чередования, и символы 1 – 4, переданные на декодер. Процесс продолжается, таким образом, до тех пор, пока полная последовательность кодового слова не будет передана на декодер в своей исходной форме.
Рабочие характеристики сверточного устройства перемежения сходны с параметрами блочного устройства перемежения. Важным преимуществом сверточного устройства перемежения перед блочным устройством перемежения является то, что при сверточном перемежении прямая задержка составляет M(N-1) символов при М = NJ, а требуемые объемы памяти – M(N-1)/2 на обоих концах канала.
Очевидно, что требования к памяти и время задержки снижаются вдвое по сравнению с блочным чередованием. Для свёрточного перемежителя (рисунок 2.12) число строк равно N и число столбцов равно NJ. Длина блока перемежаемых данных составляет N× NJ, а глубина перемежения равна
NJ.
Помимо рассмотренных выше регулярных блочного и сверточного перемежения может быть использовано случайное перемежение с использованием на приеме и передаче псевдослучайной последовательности для управления работой коммутаторов.
При передаче отсчетов речевого сигнала восьмиразрядными кодовыми комбинациями перемежение бит позволяет исключить появление при восстановлении сигнала в ЦАП нескольких подряд следующих ошибочных отсчетов, т.е преобразовать пакеты ошибочных отсчетов в одиночные ошибочные отсчеты. А одиночные ошибочно принятые отсчеты могут быть исправлены методом маскирования.
40