

Баньян-сети
Эти коммутаторы строятся на базе прямоугольных коммутаторов а х b таким образом, что существует только один путь от каждого входа к каждому выходу .
Важным подклассом баньян-сетей служат дельта-сети, введенные Пателом (Patel) в 1981 году
Дельта-сеть формируется из коммутаторов а х b, входы и выходы которых помечены 0,1,..., а-1 и 0,1,..., b-1, соответственно. Каждый вход соединяется с выходом с номером d, если этот вход управляется числом d, где d - число по основанию b.
Дельта-сеть является n каскадным коммутатором с а" входами и b" выходами.
Составляющие коммутаторы соединены так, что образуется единственный путь одинаковой длины для соединения любого входа с любым выходом.
Пусть
Sqc обозначает q-тасовку qc объектов.
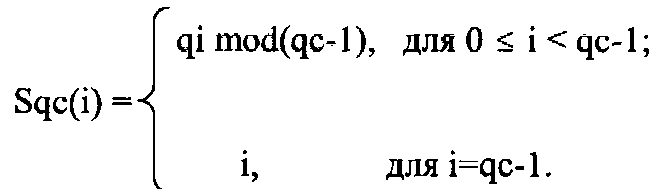
Например, для q=4 и с=3 имеем: S(0)=0, S(1)=4, S(2)=8, S(3)=1,...,S(9)=3, S(10)=7, S(11)= 11.
При построении а" х b" дельта-сети межкаскадные соединения выполняются в соответствии с а-тасовкой.
Если выход d дельта-сети выражается в системе счисления с основанием b последовательностью d(n-l), d(n-2), ..., d(l), d(0), то d(i) управляет составляющим коммутатором (n-i) каскада.
На рис. 2.4 показана дельта-сеть с п каскадами и а" входами и b выходами.
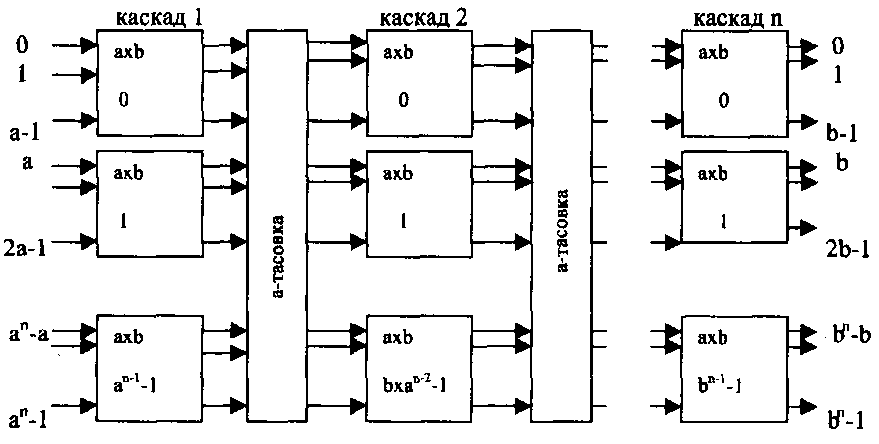
Рис. 2.4.
Каскады перенумерованы числами 1,2,...,п. Первый каскад состоит из " а х а "' коммутаторов и имеет " bха "1 выходов, что равно, соответственно, числу входов второго каскада. Второй каскад состоит из " bха "2 коммутаторов. Вообще, i-й каскад состоит из " " b1x а "' 1коммутаторов.
На рис. 2.5. показан 23 х 23 коммутатор.
Функционирование " 2х 2" коммутаторов, состоящих из коммутаторов 2х2, происходит следующим образом.
Все источники одновременно выставляют запросы, устанавливая 1 на соответствующие линии. Если появляется сигнал занятости, источник должен убрать свой запрос, чтобы повторить его в дальнейшем. Соединения выполняются в течение фиксированного промежутка времени. Возможна также асинхронная реализация коммутатора
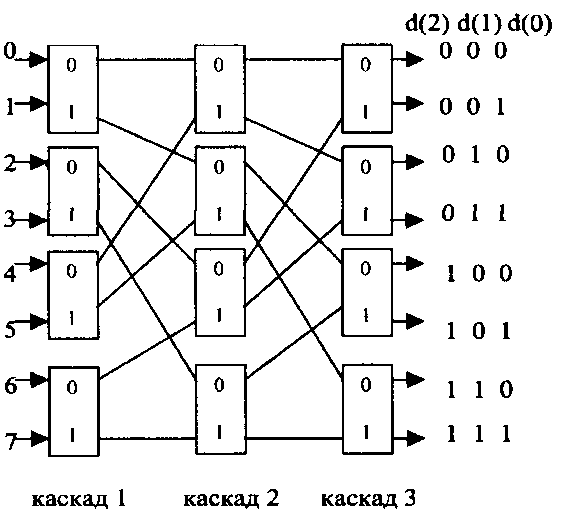
Рис. 2.5. 23 х 23 коммутатор
.
Другим подклассом баньян-сетей являются омега-сети.
Однако строятся и многокристальные вычислительные модули. Например, ВМ вычислительной системы МВС-100 [36] использует в качестве вычислителя микропроцессор i860, а в качестве коммутатора — транспьютер.
Распределенные составные коммутаторы
В распределенных вычислительных системах ресурсы разделяются между задачами, каждая из которых исполняется на своем подмножестве процессоров. В связи с этим возникает понятие близости процессоров, которая является важной для активно взаимодействующих процессоров. Обычно близость процессоров выражается в различной каскадности соединений, различных расстояниях между ними.
Один из вариантов создания составных коммутаторов заключается в объединении прямоугольных коммутаторов
(v+1 x v+1), v > 1, таким образом, что один вход и один выход каждого составляющего коммутатора служат входом и выходом составного коммутатора.
К каждому внутреннему коммутатору подсоединяются процессор и память, образуя вычислительный модуль с v каналами для соединения с другими вычислительными модулями. Свободные v входов и v выходов каждого вычислительного модуля соединяются линиями “точка-точка” с входами и выходами других коммутаторов, образуя граф межмодульных связей.
Наиболее эффективным графом межмодульных связей с точки зрения организации обмена данными между вычислительными модулями является полный граф. В этом случае между каждой парой вычислительных модулей существует прямое соединение. При этом возможны одновременные соединения между произвольными вычислительными модулями.
Однако обычно создать полный граф межмодульных связей невозможно по различным причинам. Обмен данными приходится производить через цепочки транзитных модулей. Из-за этого увеличиваются задержки, и ограничивается возможность установления одновременных соединений. Таким образом, эффективный граф межмодульных связей должен минимизировать время межмодульных обменов и максимизировать количество одновременно активизированных соединений. Кроме того, на выбор графа межмодульных связей влияет учет отказов и восстановлений вычислительных модулей и линий связи.
Система SP-2 фирмы IBM ] строится на основе коммутаторов 4х4. Коммутатор 16х16 реализуется как коммутационная плата. Для построения необходимого коммутатора набирается соответствующее число плат. Например, коммутатор 64х64 состоит из 4 плат и имеет структуру, показанную на рис. 2.6 Двунаправленные линии , соединяющие коммутаторы 4х4 , имеют пропускную способность 40 Мбайт/с в каждом направлении.
В связи с этим появляется понятие "близости" процессоров. Желательно, чтобы близость выражалась в различных расстояниях (различной каскадности соединений) между ними. Альтернативный предложенному выше способ построения составных коммутаторов заключается в следующем . Составной коммутатор строится из коммутаторов с v+1 входом и v+1 выходом, v>2. При этом один вход и один выход каждого составляющего коммутатора служат входом и выходом составного коммутатора. Этот способ построения составных коммутаторов предусматривает, что к каждому составляющему коммутатору подключается процессор и память, образуя в совокупности вычислительный модуль (ВМ) с v каналами для соединения с себе подобными.
Свободные v входов и v выходов каждого вычислительного модуля соединяются линиями "точка-точка" с входами и выходами других коммутаторов, образуя граф межмодульных связей.
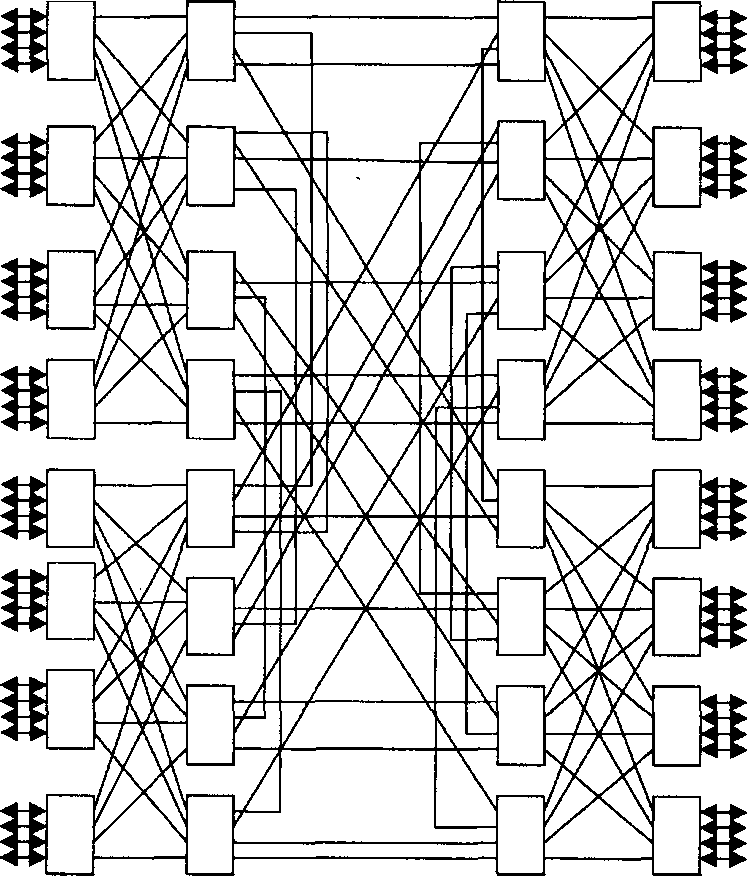
Рис. 2.6 Система SP-2 фирмы IBM
При реализации вычислительного модуля на СБИС большой объем оборудования СБИС используется для построения процессора, внутри-кристальной памяти и каналов ввода/вывода, а выводы СБИС служат для образования v входов и v выходов модуля, а также интерфейса с внешней памятью. Классическим однокристальным вычислительным модулем является транспьютер [18].