

8
def IsolationForestOutfitDetectionRes(df, col_name):
#Удалим пустые ячейки входного датафрейма
#т.к. метод IsolationForest не работает с NaN значениями df = df.dropna()
#outliers_fraction определяет чувствительность алгоритма#
к аномальным значениям
outliers_fraction = float(.015) #Изменять в пределах до 0,01 до 0,05#
Применяем предобработчик и формируем новый датафрейм np_scaled = scaler.fit_transform(df[col_name].values.reshape(-1, 1)) data = pd.DataFrame(np_scaled)
#Передаем в алгоритм IsolationForest пемеренную чувствительности model = IsolationForest(contamination=outliers_fraction)
#Обучаем модель
model.fit(data)
#Создаем во входном дата фрейме новую колонку в которой
#буду записаны прогнозные метки тех значений МПЧ, которые# алгоритм посчитал выбросами
df['Anomaly'] = model.predict(data)
# Вынесем в отдельный дата фрейм только выбросы (аномалии) anomaly = df.loc[df['Anomaly'] == -1, [col_name]] #anomaly
return anomaly, df
Интерполяция
Функция интерполяции в данном случае используется для апроксимации аномальных значений. На вход функции AnomalyInterpolationи() передается датафрейм с аномалиями и исходный. Далее данные аномальные значения удаляются из исходного датафрейма, а образованные пропуски интерполируются встроенным методом pandas interpolate(). Для интерполяции гармонических временных рядов подойдет полином второй степени.
def AnomalyInterpolation(anomaly_df, df, col_name):
# Конвертируем интерполируемую колонку в числовой формат df[col_name] = pd.to_numeric(df[col_name], errors='coerce')#
Конвертируем индексы в формат DatetimeIndex df.index = pd.DatetimeIndex(df.index)
#Присваеваем индексы аномальных значений ряда indexes = anomaly_df[col_name].index
#Находим с сиходном датафрейме значения, по "аномальному" индексу# и заменяем их на NaN для дальнейшей интерполяции df.loc[indexes.values, col_name] = np.NaN
#Сохраняем только целевую колонку
df = df[col_name]
df2 = pd.DataFrame()
# Методов interpolate выполняем интерполяцию# полиномом второй степени
df2[col_name] = df.interpolate(method='polynomial', order=2)
return df2
Визуализация аномалий
Для визуализации аномальных значений ряда создадим функцию, которая принимаетна вход метки выбросов и обрабатываемый датафрейм.
def PlotAnomaly(a, df):
#Инициализируем график - объект fig = go.Figure()
#Добавим ряд временного хода МПЧ
9
fig.add_trace(go.Scatter( x=df.index, y=df['muf'], hoverinfo="text", marker=dict(
color="blue"
), showlegend=True, name = 'df_original'
))
# Добавим ряд аномалий, которые будут отображены точками (параметр mode='markers')
fig.add_trace(go.Scatter( x=a.index, y=a['muf'], hoverinfo="text", marker=dict(
color="red"
), mode='markers', showlegend=True, name = 'anomalies'
))
fig.show()
Применим функцию детектирования аномалий без интерполяции, только для аизуализации продетектированных выбросов
col_name = 'muf'
#Сделаем копию исходного датафрейма для дальнейшего# графического сравнения
original_df = df.copy()
#Применим функцию поиска аномалий
anomaly_df, df1 = IsolationForestOutfitDetectionRes(df, col_name)
# Построим графки
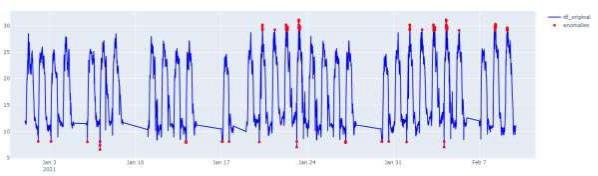
PlotAnomaly(anomaly_df, df)
Рисунок 3. Временной ход МПЧ с выделенными выбросами, которые были обнаружены средствами алгоритма МО.
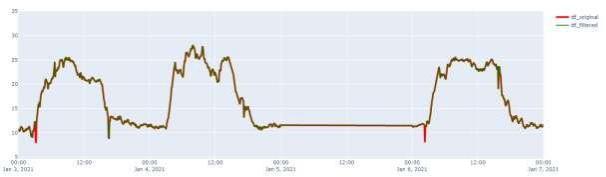
Далее проведем апроксимацию аномалий функцией AnomalyInterpolation() и построим график для сравнения результатов апроксимации и оригинального ряда (рис. 4)
10
df_filtered = AnomalyInterpolation(anomaly_df, df1, col_name)
fig = go.Figure()
fig.add_trace(go.Scatter( x=original_df.index, y=original_df['muf'], line=dict(color='red', width=4), hoverinfo="text", marker=dict(
color="blue"
),
showlegend=True, name = 'df_original'
))
fig.add_trace(go.Scatter( x=df_filtered.index, y=df_filtered['muf'], hoverinfo="text", marker=dict(
color="green"
),
showlegend=True, name = 'df_filtered'
))
fig.update_xaxes(range=['2021-01-03', '2021-01-07'])
fig.show()
Рисунок 4. Сравнение оригинального временного хода МПЧ и с корректировкой аномалий.
Выделим, напрмер, диапазон с 3 по 7 января, заметна корректировка ряда в начале дня 03.01 и 06.01. Операцию обоработкт аномалий можно запускать повторно, для более глубокой очистки, выполним еще цикл.
anomaly_df, df_filtered = IsolationForestOutfitDetectionRes(df_filtered, col_name) PlotAnomaly(anomaly_df, df_filtered)
11
Рисунок 5. Временной ход МПЧ с выделенными выбросами, которые были обнаружены средствами алгоритма МО, вторая итерация.
Сглаживание временного ряда
Далее средствами библиотеки statsmodels создадим сглаженную копию скорректированного временного хода. statsmodels — это модуль Python, который предоставляет классы и функции для оценки множества различных статистических моделей, а также для проведения статистических тестов и исследования статистических данных. Для каждого оценщика доступен обширный список статистики результатов. Напрмиер, данная библиотека, имеет возможность использовать Фильтр Ходрика-Прескотта. Данный фильтр представляет собой математический инструмент, используемый в макроэкономике, особенно
втеории реального делового цикла, для удаления циклического компонента временного ряда из необработанных данных. Он используется для получения представления временного ряда
ввиде сглаженной кривой, которая более чувствительна к долгосрочным, чем к краткосрочным колебаниям. Вызвать данный фильтр можно командой statsmodels.tsa.filters.hp_filter.hpfilter(x, lamb=1600), где x
- временной ряда, а lamb - параметр сглаживания. import statsmodels.api as sm
# Корректируем аномалии
df_filtered = AnomalyInterpolation(anomaly_df, df_filtered, col_name)
# Выполняем сглаживание оригинального ряда и ряда с корректировкой аномалий gdp_cycle, df_trend_filtered = sm.tsa.filters.hpfilter(df_filtered, 100)
gdp_cycle, df_trend = sm.tsa.filters.hpfilter(original_df, 100)
fig = go.Figure()
fig.add_trace(go.Scatter( x=original_df.index, y=original_df['muf'],
# hovertext=df['A_info'], hoverinfo="text", marker=dict(
color="blue"
),
showlegend=True, name = 'df_original'
))
fig.add_trace(go.Scatter( x=df_trend_filtered.index, y=df_trend_filtered,
# hovertext=df['B_info'],
12
line=dict( width=6), hoverinfo="text", marker=dict(
color="green"
), showlegend=True,
name = 'df_trend_filtered'
))
fig.add_trace(go.Scatter( x=df_trend.index, y=df_trend,
line=dict(color='red', width=2),# hovertext=df['B_info'], hoverinfo="text",
marker=dict( color="green"
), showlegend=True, name = 'df_trend'
))
fig.update_xaxes(range=['2021-01-03', '2021-01-07'])
fig.show()
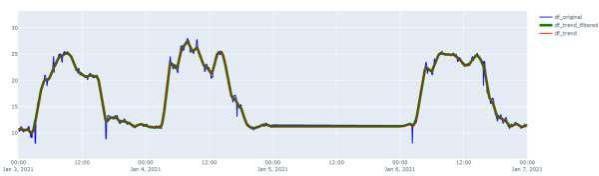
Рисунок 6. Сравнение оригинального временного ряда, сгаженного оригинального временного ряда и рядв с корректировкой аномалий и сглаживанием
На рисунке 6 в начале и конце дня 03.02 четко видны сглаженные отрезки. Функция сглаживания хорошо апроксимирует аномальные значения. Применение фильтрации выбросов позволило произвести более точное сглаживание аномальных участков.
ПРАКТИЧЕСКАЯ ЧАСТЬ Задание на лабораторную работу
Произвести детектирование аномалий и сглаживание временного ряда полного электронного содержания. Сделать вывод о необходимой чувствительности алгоритма IsolationForest и параметров сглаживащей функции.