

Лекція №6. Тема 4 : Аналіз контекстних умов.
LL(1) та LR(1)-граматики не охоплюють контексту. Контекстні умови – це все те, що не охоплено. Розрізняють декілька класів контекстних умов:
Пов’язані з правилами опису об’єктів. Наприклад, Pascal та його правила:
змінна не може бути описана більш ніж один раз;
об’єкт не може бути описаний більш ніж один раз.
Пов’язані з правилами відповідності опису:
ідентифікатор повинен бути описаний (в процедурі, в формальних чи фактичних параметрах).
Пов’язані з відповідністю типів:
у виразі операнди одного типу;
відповідність типів формальних та фактичних параметрів;
в опису VAR не може бути виразу.
Пов’язаний з реалізацією мови програмування. Модула-2:
модуль даних обмежений – 64 Кб;
в матрицях обмежена кількість індексів.
Аналіз контекстних умов за допомогою програмних граматик.
За допомогою програмних граматик можна робити аналіз синтаксису та всіх контекстних умов. Позначення:
Gp={Vт,Vн, Ps, I, S},
де Gp – програмна граматика;
Vт – множина терміналів;
Vн – множина нетерміналів;
Ps – аксіома;
I – множина міток;
S – множина правил виводу.
Кожне правило має вигляд множини міток:
![]()
де r – мітка;
![]() - основне правило;
- основне правило;
W1|W2 – множина правил при прийнятті даного правила. Можемо далі користатися лише правилами з мітками W1, а якщо заміна не відбулася – користуємося правилами з мітками W2.
Особливість:
присутність модернізованих нетерміналів
(нетермінал проводить лише один деякий
термінал, позначається як
![]() і т.п.). Їх використання дозволяє робити
перевірки на відповідність, не
відповідність, перевірку кількості).Розбір
виконується:
і т.п.). Їх використання дозволяє робити
перевірки на відповідність, не
відповідність, перевірку кількості).Розбір
виконується:
з аксіоми отримуємо деяку частину;
виконується вивід програми.
Розглянемо
декілька прикладів. Приклад 1: Перевіримо
кількість формальних та фактичних
параметрів. Побудуємо граматику:
![]() ,
де
,
де![]() - ланцюг терміналів/ чи нетерміналів;
- ланцюг терміналів/ чи нетерміналів;![]() ;
;![]() .
.

Приклад 2: Перевірити розбіжності. Маємо граматику:

![]()
Приклад 3: Перевірити, щоб всі ідентифікатори не містили двох однакових ланцюгів.

Маємо граматику:
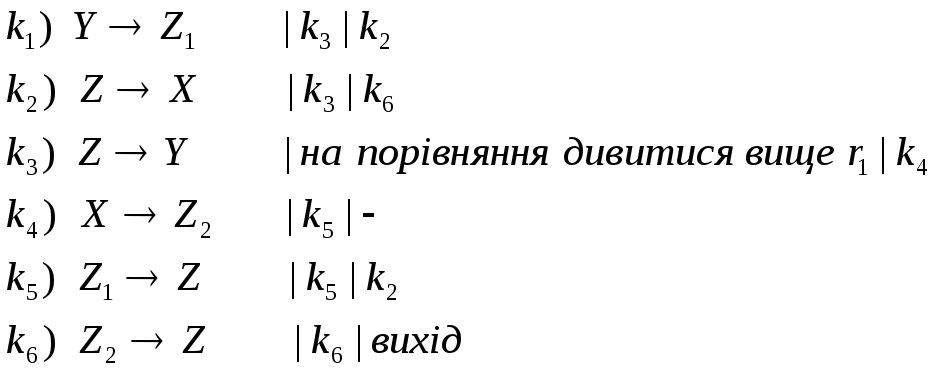
Класифікація програмних граматик:
LL(1);
Контекстно-вільна;
Контекстно-залежна;
Рекурсивна зліва;
Рекурсивна справа;
Можна чітко формалізувати всю мову з урахуванням контекстних умов.
Лекція №7. Граматики Ван Вейнгаарда.
Особливості:
Gv={Gm,Gst},
де Gm – метаграматика;
Gst – сувора граматика.
Gm={Vmт, Vmн, Sm},
де Vmт – множина терміналів;
Vmн – множина нетерміналів;
Sm – множина правил.
Gst={Vstт, F, I, Sst},
де Vstт – множина терміналів;
F – множина форм (ланцюгів із нетерміналів і терміналів метаграматики);
I – початкова форма (форма із терміналів метаграматики);
Sst – множина схем правил виводу.
Розглянемо
приклад граматики Ван Вейнгаарда, яка![]() породжує мову {
породжує мову {![]() }
:
}
:
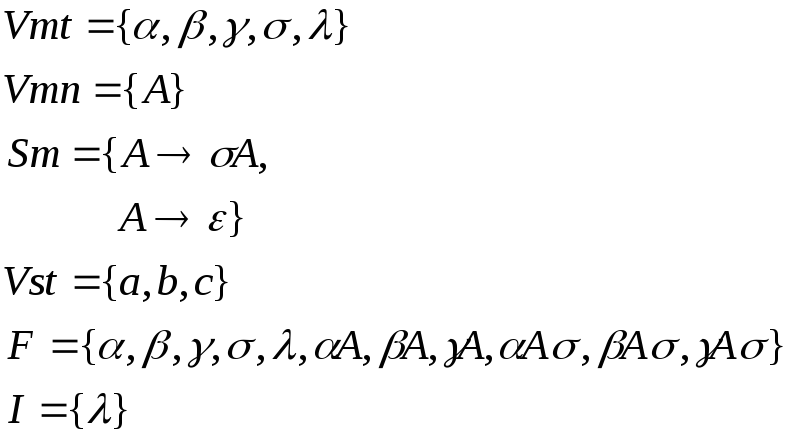

Для отримання правил виводу змінюються всі форми одночасно, згідно правилам метаграматики, та ці форми підставляються в схеми виводу суворої граматики:
Застосуємо правило
 тоді
маємо:
тоді
маємо:
а)
![]()
б)

![]()
Застосуємо правила:
 ,маємо:
,маємо:
а)![]()
б)

Застосуємо :
 ,
маємо:
,
маємо:
а)![]()
б)

Отримали нескінчену множину
допустимих форм (ланцюгів цієї граматики)
та перебудуємо форми відповідно змінам.
Необхідно ланцюг ‘aaabbbccc’ згорнути до
початкового терміналу:![]()
![]()
![]()

Ця граматика застосовується в програмах для перевірки кількісної відповідності.