

1. Барьерная синхронизация - mpi_Barrier (comm)
IN comm коммуникатор (дескриптор)
Функция MPI_Barrier блокирует вызывающий ее процесс, пока все процессы группы не вызовут ее. В каждом процессе управление возвращается только тогда, когда все процессы в группе вызовут эту процедуру.
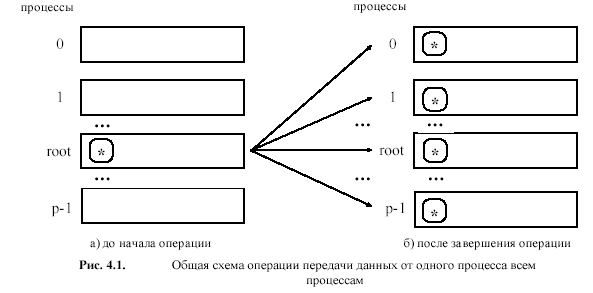
2. Широковещательная передача
Функция MPI_Bcast посылает сообщение из одного процесса всем процессам группы, включая себя.
MPI_Bcast(buffer, count, datatype, root, comm )
IN/OUT buffer адрес начала буфера
IN count количество записей в буфере (целое)
IN datatype тип данных в буфере
IN root номер корневого процесса (целое)
IN comm коммуникатор
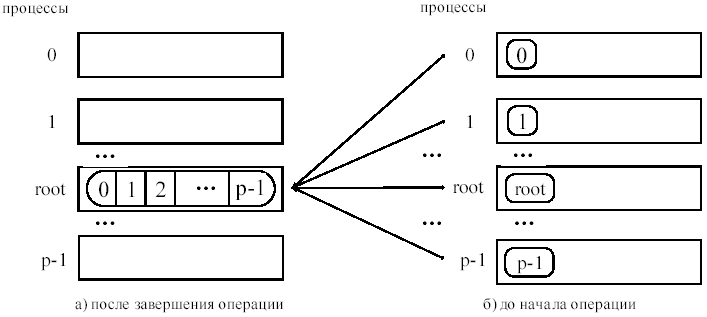
3. Сбор данных
MPI_Gather(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, int root, comm);
IN sendbuf начальный адрес буфера передачи сообщения
IN sendcount количество элементов в отсылаемом сообщении (целое)
IN sendtype тип элементов в отсылаемом сообщении
OUT recvbuf начальный адрес буфера сборки данных (исп-ся только корневым проц.)
IN recvcount колич. элем-ов в принимаемом сообщении (исп-ся только корневым проц.)
IN recvtype тип элементов в получаемом сообщения на процессе-получателе
IN root номер процесса-получателя (целое)
IN comm коммуникатор (дескриптор)
При выполнении операции сборки данных MPI_Gather каждый процесс, включая корневой, посылает содержимое своего буфера в корневой процесс. Корневой процесс получает сообщения и располагает их в порядке возрастания номеров процессов.
Выполнение MPI_Gather будет давать такой же результат, как если бы каждый из n процессов группы (включая корневой процесс) выполнил вызов MPI_Send (sendbuf, sendcount, sendtype, root, …), а принимающий процесс выполнил n вызовов MPI_Recv(recvbuf + i * recvcount * extent(recvtype), recvcount, recvtype, i, …)
Количество посланных и полученных данных должно совпадать, т.е. sendcount== recvcount. Аргумент recvcount в главном процессе показывает количество элементов, которые он получил от каждого процесса, а не общее количество полученных элементов.
В корневом процессе используются все аргументы функции, на остальных процессах используются только аргументы sendbuf, sendcount, sendtype, root, comm. Аргументы comm и root должны иметь одинаковые значения во всех процессах.
MPI_Gatherv(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm)
IN sendbuf начальный адрес буфера отправителя
IN sendcount количество элементов в отсылаемом сообщении (целое)
IN sendtype тип элементов в отсылаемом сообщении
OUT recvbuf адрес буфера процесса сборки данных (существ-но для корневого процесса)
IN recvcounts массив цел. чисел (gsize), содержит количество элементов, полученных от каждого процесса (используется корневым процессом)
IN displs массив целых чисел (gsize). Эл-нт i определяет смещение относит. recvbuf, в котором размещаются данные из процесса i (исп-ся корневым процессом)
IN recvtype тип данных элементов в буфере процесса-получателя
IN root номер процесса-получателя (целое)
IN comm коммуникатор
MPI_Gatherv имеет аналогичные параметры, за исключением int* recvcounts и int*displs – это массивы целых чисел, размеры которых равны размеру группы (числу процессов).
В отличие от MPI_Gather при использовании функции MPI_Gatherv разрешается принимать от каждого процесса переменное число элементов данных, поэтому в функции MPI_Gatherv аргумент recvcounts является массивом. Если Вы выполняете операцию вне ветки какого-либо процесса, значение sendcount будет одно для всех процессов в группе. Для того, чтобы процессы могли выполнить операцию с различным sendcount функцию надо вызывать в каждой ветке, определяющей код процесса, правильно определяя значения элементов массива recvcounts на корневом процессе.
Выполнение MPI_Gatherv будет давать такой же результат, как если бы каждый процесс, включая корневой, посылал корневому процессу сообщение: MPI_Send(sendbuf, sendcount, sendtype, root, …), а принимающий процесс выполнил n операций приема: MPI_Recv(recvbuf+displs[i]*extern(recvtype), recvcounts[i], recvtype, i, …).
Сообщения помещаются в буфер принимающего процесса в порядке возрастания номеров процессов, от которых они приходят, то есть данные, посланные процессом i, помещаются в i-ю часть принимающего буфера recvbuf на корневом процессе. i-я часть recvbuf начинается со смещения displs[i].
В принимающем процессе используются все аргументы функции MPI_Gatherv, а на всех других процессах используются только аргументы sendbuf, sendcount, sendtype, root, comm. Переменные comm и root должны иметь одинаковые значения во всех процессах.