

4 Нахождение коэффициента корреляции
В качестве входного диапазона выделяем столбцы с логарифмами. Получим:
-
ln x
ln y
ln x
1
ln y
-0,89272
1
Коэффициент
корреляции
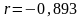 ,
что свидетельствует о наличии достаточной
линейной зависимости между ln
x
и ln
y.
Знак «-» означает, что связь обратная.
,
что свидетельствует о наличии достаточной
линейной зависимости между ln
x
и ln
y.
Знак «-» означает, что связь обратная.
5 Нахождение параметров линейной регрессии
Чтобы найти параметры регрессии, выбираем пункт меню Сервис – Анализ данных – Регрессия. Здесь задаем диапазоны отдельно для ln y, отдельно – для ln x , устанавливаем флажок в окошке «Метки», «Остатки», «График подбора», «Выходной диапазон» – на новый лист. Ок.
Результат получаем в виде нескольких таблиц (таблицы 1.20 – 1.23) и графика подбора (рисунок 1.7).
Таблица 1.20 – Регрессионная статистика
-
Множественный R
0,892723765
R-квадрат
0,796955721
Нормированный R-квадрат
0,781336931
Стандартная ошибка
0,037116526
Наблюдения
15
Здесь R-квадрат = 0,7969 (79,69%) – значит, общее качество модели хорошее; стандартная ошибка = 0,0371.
Таблица 1.21 – Дисперсионный анализ
-
df
SS
MS
F
Значимость F
Регрессия
1
0,070294515
0,070295
51,02544
0,0000076
Остаток
13
0,017909275
0,001378
Итого
14
0,08820379
Значимость
F = 0,0000076,
что означает, что полученная модель
адекватна исходным данным по критерию
Фишера с уровнем доверия
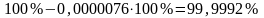 .
Все дальнейшие расчеты выполняются
только при условии адекватности модели.
.
Все дальнейшие расчеты выполняются
только при условии адекватности модели.
Таблица 1.22 – Коэффициенты модели
|
Коэффициен-ты |
Стандартная ошибка |
t-статистика |
P-Значе-ние |
Нижние 95% |
Верхние 95% |
Y-пересечение |
4,770082187 |
0,143001901 |
33,35677 |
5,56E-14 |
4,4611454 |
5,079019 |
ln x |
-0,122402417 |
0,017135493 |
-7,14321 |
7,55E-06 |
-0,159421 |
-0,08538 |
Здесь
коэффициенты линейной модели
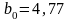 ,
,
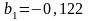 .
Оба коэффициента статистически значимы
по критерию Стьюдента, т. к. для
P-Значение
=
.
Оба коэффициента статистически значимы
по критерию Стьюдента, т. к. для
P-Значение
=
 и для
P-Значение
=
и для
P-Значение
=
 .
.
Полученная
модель
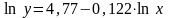 .
.
Пересчитываем
коэффициенты, чтобы записать степенную
модель.
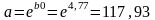 ,
,
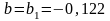 .
Полученная степенная модель
.
Полученная степенная модель
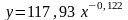 .
.
Таблица 1.23 – Вывод остатка
Наблюдение |
Предсказанное ln y |
Остатки |
1 |
3,66203 |
-0,01554 |
2 |
3,79377 |
0,00598 |
3 |
3,69302 |
-0,01925 |
4 |
3,66272 |
-0,00096 |
5 |
3,79419 |
0,05511 |
6 |
3,71791 |
-0,04212 |
7 |
3,84471 |
-0,01498 |
8 |
3,80907 |
-0,03631 |
9 |
3,77052 |
0,06051 |
10 |
3,82050 |
-0,06419 |
11 |
3,68776 |
0,00486 |
12 |
3,67517 |
0,02465 |
13 |
3,86810 |
0,03911 |
14 |
3,78131 |
-0,02034 |
15 |
3,68252 |
0,02347 |
Рисунок 1.7 – График подбора
6 Расчет доверительного интервала для прогноза
Доверительный
интервал для прогнозируемого отклика
вначале записывается в виде:
 ,
затем перечитывается для отклика y
по формулам
,
затем перечитывается для отклика y
по формулам
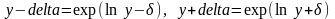 .
.
7 Построение доверительной области для прогноза
Доверительная область – совокупность доверительных интервалов.
Строят точечную диаграмму: по оси абсцисс – значения фактора х, по оси ординат – значения отклика y, расчетных значений y(x) и границ доверительных интервалов , . Получают диаграмму:
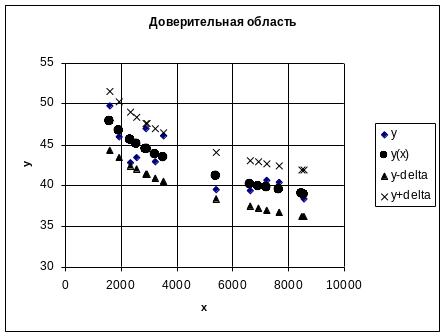
8 Расчет максимального % ошибки прогнозирования
Максимальный % ошибки прогнозирования рассчитывается по формуле:
.
9 Выводы по работе
В результате статистического анализа данных получено, что между фактором x и откликом y существует достаточная линейная зависимость, т. к. коэффициент корреляции , и эта зависимость обратная.
Среднее значение фактора , среднее значение отклика .
Полученная модель связи между фактором x и откликом y:
.
Модель адекватна исходным данным по критерию Фишера с уровнем доверия более 95%. Оба коэффициента статистически значимы по критерию Стьюдента.
Максимальный % ошибки прогнозирования составляет порядка 3%.
Листы Excel с расчетами приведены на рисунках 1.8, 1.9.
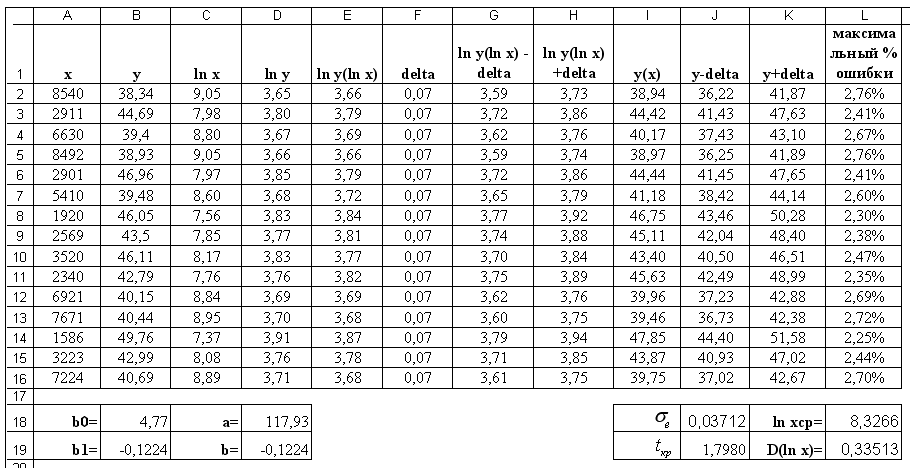
Рисунок 1.8 – Лист с расчетами степенной функции в Excel
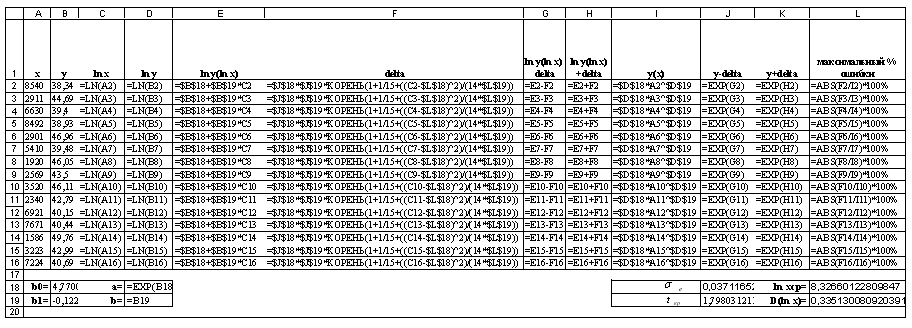
Рисунок 1. 9 – Лист с формулами в Excel