

2.. Модели организациии данных
Ядро любой БД – модель данных.
Модель данных – набор принципов, определяющих организацию логической структуры хранения данных в базе. Модели БД определяются тремя компонентами:
Допустимой организацией данных;
Ограничениями целостности;
Множеством допустимых операций.
В теории БД выделяют три основных типа моделей:
иерархическую;
сетевую;
реляционную.
2.1. Иерархическая модель данных
В иерархической модели все записи, агрегаты и атрибуты БД образуют иерархически организованный набор, т.е. такую структуру, в которой все элементы связаны отношениями подчиненности, при этом любой элемент может подчиняться только одному какому- нибудь другому элементу. Эту форму зависимости удобно отображать с помощью древовидного графа (схемы, состоящей из точек, стрелок, которые связаны и не имеют циклов).
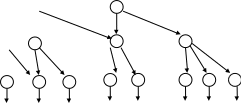
Рис. 3 Схема иерархической модели данных
Типичный представитель семейства БД, основанных на иерархической модели – Information Management System (IMS) фирмы IBM, первая версия которой появилась в 1968 г.
2.2. Сетевая модель данных
Концепция сетевой модели данных связана с именем Ч. Бахмана. Сетевой подход организации данных является расширением иерархического. В иерархических структурах запись – потомок должна иметь в точности одного предка, в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей заданных типов (из допустимого набора типов) и набора связей между ними из заданного набора типов связей.
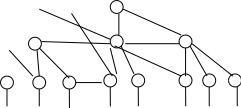
Рис. 4 Схема сетевой модели данных
Пример системы управления данными с сетевой организацией – Integreted Database Management System (IDMS) компании Cullinet Software Inc., разработанная в середине 1970-х гг. Она предназначалась для использования на «больших» вычислительных машинах. Архитектура системы основана на предложениях Data Base Task Group (DBTG), Conference on Data Systems Languages (CODASYL), организации, ответственной за определение стандартов языка программирования Кобол.
Среди достоинств систем управления данными, основанных на иерархической или сетевой модели можно назвать их компактность и, как правило, высокое быстродействие, а среди недостатков – неуниверсальность, высокая степень зависимости от конкретных данных
2.3. Реляционная модель данных
Понятие реляционный (англ.relation - отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда.
В реляционной модели объекты и соотношения между ними представляются в виде таблиц, строки которых соответствуют записям, а столбцы – атрибутам отношений (полям).
Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
каждый элемент таблицы - один элемент данных;
все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
каждый столбец имеет уникальное имя;
одинаковые строки в таблице отсутствуют;
порядок следования строк и столбцов может быть произвольным.
В реляционной БД каждая таблица должна иметь первичный ключ- поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице. Если записи однозначно определяются значениями нескольких полей, то такая БД имеет составной ключ.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
Таблица 1 |
|||
Поле 1.1 |
Поле 1.2 |
Поле 1.3 |
Поле 1.4 |
|
|
|
|
|
|
|
|
Таблица 2 |
|||
Поле 2.1 |
Поле 2.2 |
Поле 2.3 |
П |
|
|
|
|
|
|
|
|
 оле
2.4
оле
2.4
Таблица 3 |
|||
Поле 3.1 |
Поле 3.2 |
Поле 3.3 |
Поле 3.4 |
|
|
|
|
|
|
|
|

Рис. 5 Схема реляционной модели данных
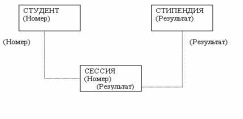
Рис.6 Пример реляционной модели, построенной на основе отношений: СТУДЕНТ, СЕССИЯ, СТИПЕНДИЯ
Таблицы СТУДЕНТ И СЕССИЯ имеют совпадающие ключи (Номер), что дает возможность легко организовать связь между ними. Таблица СЕССИЯ имеет первичный ключ Номер и содержит внешний ключ Результат, который обеспечивает ее связь с таблицей СТИПЕНДИЯ.
3. ТИПЫ СВЯЗЕЙ В БАЗАХ ДАННЫХ
Все информационные объекты предметной области связаны между собой. Различаются связи нескольких типов, для которых введены соответствующие обозначения.
3.1. Связь «один к одному»
Связь о один к одному (1:1) - в каждый момент времени одному экземпляру информационного объекта А соответствует не более одного экземпляра информационного объекта В и наоборот.

3.2. Связь «один ко многим»
Связь один ко многим (1:М) одному экземпляру информационного объекта А соответствует 0, 1 или более экземпляров объекта В, но каждый экземпляр объекта В связан не более чем с 1 экземпляром объекта А.

3.3. Связь «многие ко многим»
Связь многие ко многим (М:М) - в каждый момент времени одному экземпляру информационного объекта А соответствует 0, 1 или более экземпляров объекта В и наоборот.

4.НОРМАЛИЗАЦИЯ ОТНОШЕНИЙ В БАЗАХ ДАННЫХ
Важнейшей проблемой, решаемой при проектировании БД, является создание такой их структуры, которая обеспечивала бы минимальное дублирование информации и упрощала процедуру их обработки и обновления данных. Набор формальных требований универсального характера к организации данных, который эффективно решает вышеперечисленные задачи, получили название нормальных форм.
Первоначально были сформулированы 3 нормальные формы, затем число их возросло, но они являются труднодостижимыми и не получили широкого распространения.
Нормализация – это пошаговый процесс разбиения исходных таблиц на более простые, которые должны отвечать двум основным требованиям:
Между полями таблицы не должно быть нежелательных функциональных зависимостей;
Группировка полей должна обеспечивать минимальное дублирование данных, эффективный (без трудностей) поиск, обработку и обновление данных.