

Пороговые значения r и r2 при 90 % уровне доверия
n |
r |
r2 |
n |
r |
r2 |
10 |
0,46 |
0,21 |
60 |
0,20 |
0,04 |
15 |
0,39 |
0,15 |
70 |
0,19 |
0,04 |
20 |
0,34 |
0,12 |
80 |
0,18 |
0,03 |
25 |
0,31 |
0,10 |
90 |
0,16 |
0,03 |
4. Окончательный выбор функции тренда.
Первый способ на основе анализа показателей точности прогноза. Составляется табл. 5, куда заносятся значения показателей точности прогнозаSy, МАРЕ и МРЕ.
Среднеквадратическое отклонение или стандартная ошибка уравнения
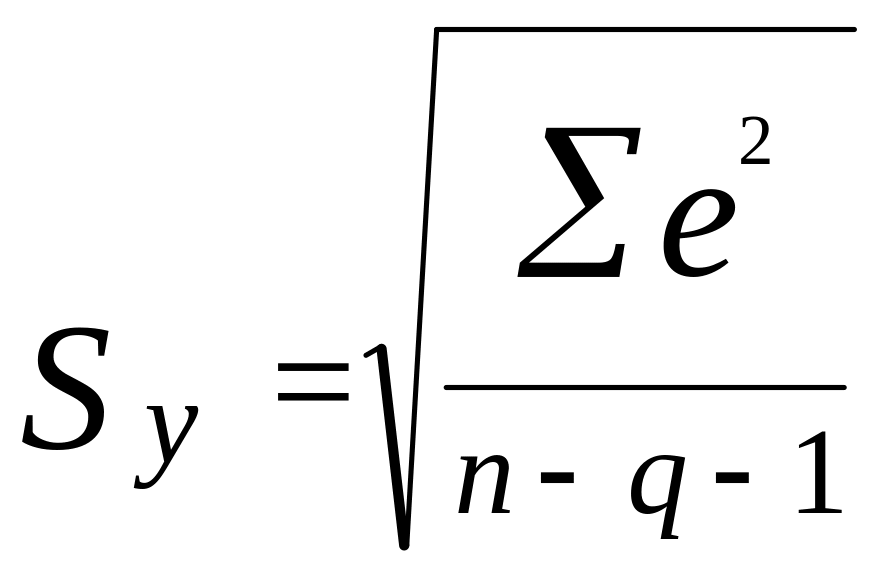 , (11)
, (11)
где n - объем наблюдений,
q - число параметров модели (не включая свободный член).
Средняя абсолютная процентная ошибка
МАРЕ
=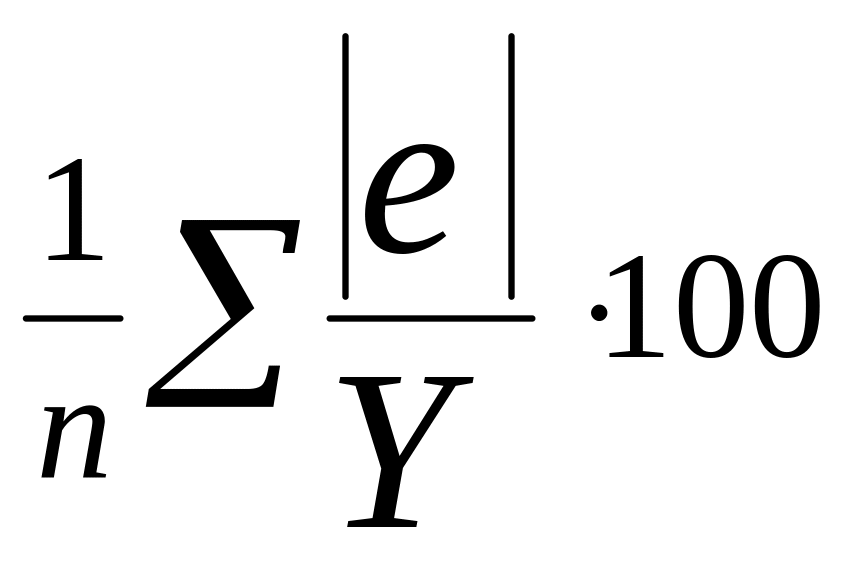 , (12)
, (12)
где: е = YYпр ошибка прогноза.
Если МАРЕ меньше 5%, то это значит, что модель дает высокую точность прогноза.
Средняя процентная ошибка прогноза МРЕ определяет смещенность прогноза:
МРЕ
=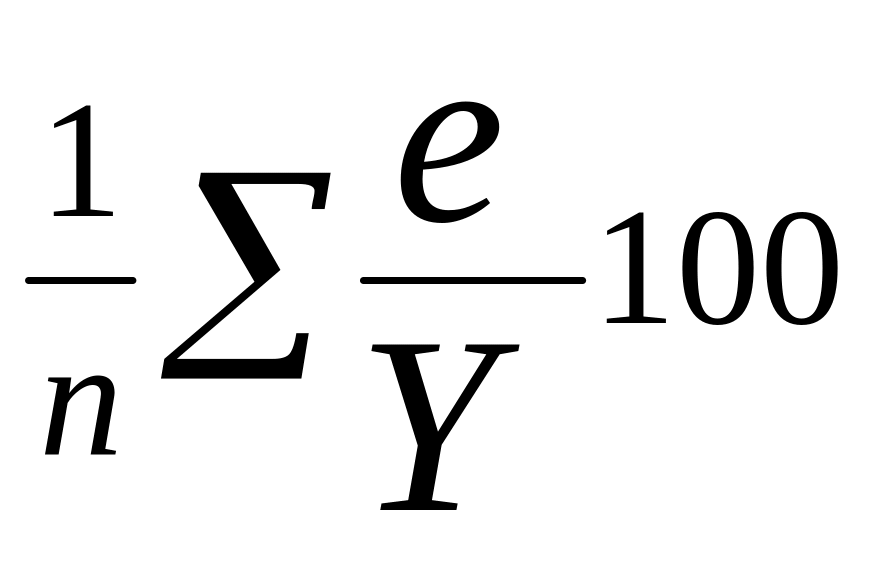 . (13)
. (13)
Если значение МРЕ меньше 5 %, что является пограничным, то это значит, что прогноз дает несмещенную оценку.
Та функция, у которой названные выше ошибки окажутся наименьшими, и будет принята в качестве функции прогноза. Расчет необходимых сумм для вычисления перечисленных ошибок приведен в табл. 2 и 3.
Таблица 5
Показатели точности прогноза
Показатели точности прогноза |
Вид функции |
|
|
Yt = a + b t |
Yt = a + b t + c t2 |
1. Среднеквадратическое отклонение |
|
|
2. Средняя абсолютная процентная ошибка МАРЕ |
|
|
3. Средняя процентная ошибка МРЕ |
|
|
Второй способ с помощью дисперсионного анализа.
Общую вариацию исследуемого ряда можно представить как сумму двух слагаемых: вариации тенденции Vф и случайной вариации Vост:
V = Vф + Vост. (14)
Общую вариацию определяют из табл. 2, как
![]() (15)
(15)
где Yt (n) средний уровень ряда динамики.
Остаточную (случайную) вариацию, которую нельзя объяснить влиянием данного фактора, вычисляют по формуле:
![]() , (16)
, (16)
где е2 берется для каждой функции отдельно из табл.2 и 3.
Вариацию, объясняемую фактором t, находят с помощью формулы:
Vф = V Vост. Она будет разная у рассматриваемых функций.
Зная значения вариаций для каждой функции, можно рассчитать дисперсии и критерий Фишера, который определяется как
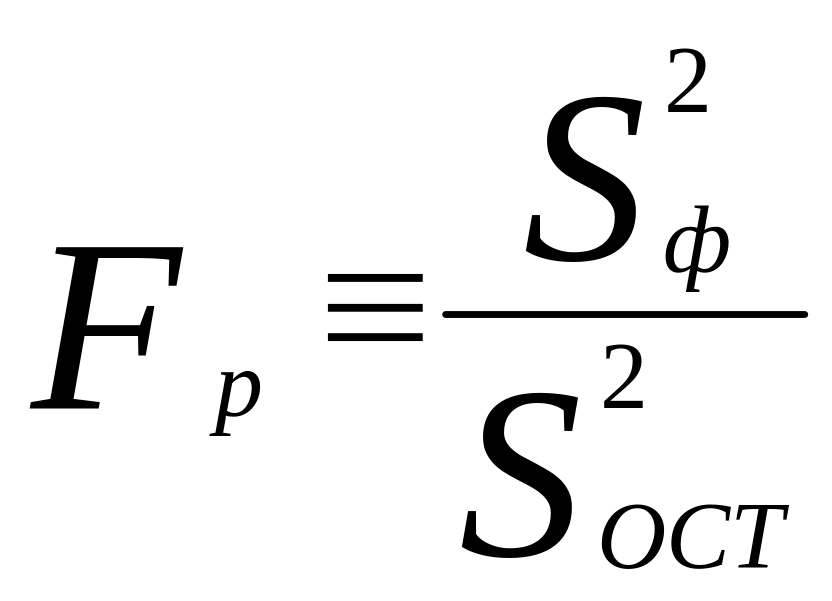 , (17)
, (17)
где
![]() и
и
![]()
дисперсии на одну степень свободы,
которые вычисляются по следующим
формулам:
дисперсии на одну степень свободы,
которые вычисляются по следующим
формулам:
![]() =
Vф
/
q; (18)
=
Vф
/
q; (18)
=
![]() ; (19)
; (19)
для линейной модели q = 1, для параболы q =2.
Имеются специальные таблицы (табл. А 3), где для заданного уровня значимости и числа степеней свободы (К) затабулированы пограничные значения критерия Фишера Fтабл. Например, если = 0,05, число степеней свободы для большей дисперсии Кф= 1, для меньшей - Кост = 14 (n -1 = 15 1 = 14 при n = 15), Fтабл = 4,6. Расчет делается для каждой функции отдельно. Если Fp > Fтабл, то модель можно использовать и фактор времени (t) влияет на спрос.
Сделать окончательный вывод и записать выбранную функцию тренда в явном виде (то есть с численными значениями параметров).
5. Метод серий и медианы для определения составляющих прогнозной модели.
Составляется табл. 6, в нее заносятся значения ошибок e для выбранной функции тренда. Из этих ошибок составляется вариационный ряд, то есть значения предыдущего столбика (et), записываются в порядке возрастания. В вариационном ряду выбираем срединное его значение eM (е8), с которым сравниваем исходный ряд (кол. 2). Если число в исходном ряду больше, то ставим знак плюс в кол. 4, если меньше, то минус. По данным кол. 4 определяем Кмах максимальная протяженность серии (количество минусов или плюсов) и V(n) общее число серий (ноль не считают).
Выборка считается случайной, если для 5 % уровня значимости справедливы неравенства:
Кмах < 3,3 (lоg n +1), (20)
V(n)
> 1/2
(n +1
1,96![]() ). (21)
). (21)
Cкобки означают, что берется целая часть. Если хотя бы одно неравенство нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается, и прогноз делается по двум составляющим: детерминированной и случайной. Если неравенства не нарушаются, то прогноз делается только по детерминированной составляющей, по выбранному тренду.
Записать окончательный вид прогнозной модели.
Таблица 6