

Целые числа
Арифметический сопроцессор наряду с вещественными числами способен обрабатывать и целые числа. Он имеет команды, выполняющие преобразования целых чисел в вещественные и обратно.
Возможно четыре формата целых чисел:
целое число;
короткое целое число;
длинное целое число;
упакованное десятичное число.
Целое число занимает 2 байта. Его формат полностью соответствует используемому центральным процессором. Для представления отрицательных чисел используется дополнительный код. Короткое целое и длинное целое имеют аналогичные форматы, но занимают, соответственно, 4 и 8 байт.
Упакованное десятичное число занимает 10 байт. Это число содержит 18 десятичных цифр, расположенных по две в каждом байте. Знак упакованного десятичного числа находится в старшем бите самого левого байта. Остальные биты старшего байта должны быть равны 0.
Существуют команды сопроцессора, которые преобразуют числа в формат упакованных десятичных чисел из внутреннего представления в расширенном вещественном формате. Если программа делает попытку преобразования в упакованный формат ненормализованных чисел, нечисел, бесконечности и тому подобных, в результате получается неопределенность. Неопределенность в упакованном формате представляет из себя число, в котором два старших байта содержат единицы во всех разрядах. Содержимое остальных восьми байтов произвольно. При попытке использовать такое упакованное число в операциях фиксируется ошибка.
Для вещественных чисел для представления отрицательных чисел используется специальный знаковый бит. Для целых чисел используется дополнительный код.
В дополнительном коде положительные числа содержат нуль в самом старшем бите числа: 0XXX XXXX XXXX XXXX
Для получения отрицательного числа в дополнительном коде из положительного надо инвертировать каждый бит числа и затем прибавить к числу единицу.
Например, число +5 в дополнительном коде выглядит следующим образом:
0000 0000 0000 0101 = +5
Для получения числа -5 вначале инвертируем значение каждого бита:
1111 1111 1111 1010
Теперь прибавим к полученному числу +1: 1111 1111 1111 1011 = -5
На рис. 3 приведены все возможные варианты представления целых чисел.
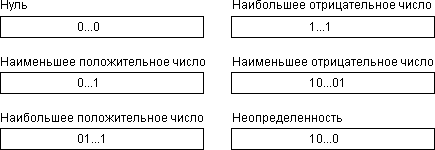
Рис. 3. Возможные представления целых чисел
Формат упакованного десятичного числа показан на рис. 4.
![]()
Рис. 4. Формат упакованного десятичного числа
На этом рисунке n0...n17 означают разряды десятичного числа. Они могут изменяться в пределах от 0000 до 1001, то есть от 0 до 9 в десятичной системе счисления.
Символьная информация
Для кодирования символьной или текстовой информации применяются различные системы: при вводе информации с клавиатуры кодирование происходит при нажатии клавиши, на которой изображен требуемый символ, при этом в клавиатуре вырабатывается так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши.
Номер нажатой клавиши никак не связан с формой символа, нанесенного на клавише. Опознание символа и присвоение ему внутреннего кода ЭВМ производятся специальной программой по специальным таблицам: КОИ-8, ASCII и др.
Кодировка ASCII
Существует множество кодировочных таблиц. Рассмотрим сначала кодировочную таблицу ASCII (ASCII - American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Эта кодировка является наиболее известной. На практике обычно не бывает проблем с кодированием англоязычных текстов, поскольку первая половина кодировки стандартизована, но, к сожалению, для кодировки русских букв существует несколько кодировочных таблиц, что иногда создает проблемы при работе с текстами.
Всего с помощью таблицы кодирования ASCII можно закодировать 256 различных символов. Эта таблица разделена на две части: основную (с кодами от OOh до 7Fh) и дополнительную (от 80h до FFh). Для кодировки одного символа из таблицы отводится 8 бит. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов. Например, слово hello! будет закодировано следующим образом:
h e l l o !
Код двоичный: 01001000 01100101 01101100 01101100 01101111 00100001
Код десятичный: 72 101 108 108 111 33
На рис. 5 представлены символы, входящие в стандартную (английскую) и расширенную (русскую) кодировку ASCII.
Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 00h до 20h и 77h). Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Здесь же размещаются знаки пунктуации и математические знаки: 2lh - !, 26h - &, 28h - (, 2Bh -+,..., большие и малые латинские буквы: 41h - A, 61h - а,...
Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы - управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур.
Монитор по каждому коду символа должен вывести на экран изображение символа - не просто цифровой код, а соответствующую ему картинку, так как каждый символ имеет свою форму. Описание формы каждого символа хранится в специальной памяти монитора - знакогенераторе. Высвечивание символа на экране осуществляется с помощью точек, образующих символьную матрицу. Каждый пиксел в такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой 0, светлая (яркая) - 1. Если изображать в матричном поле знака темные пикселы точкой, а светлые - звездочкой, то можно графически изобразить форму символа.

Рис. 5. Таблица кодировки текстовой информации ASCII.
Люди в разных странах используют символы для записи слов их родных зыков. В наши дни большинство приложений, включая системы электронной почты и вэб-браузеры, являются чисто 8-битными, то есть они могут показывать и корректно воспринимать лишь 8-битные символы, согласно стандарту ISO-8859-1.
Существует более 256 символов в мире (если учесть кириллицу, арабский, китайский, японский, корейский и тайский языки), а также появляются все новые и новые символы. И это создает следующие пробелы для многих пользователей:
1. Невозможно использовать символы различных наборов кодировок в одном и том же документе. Так как каждый текстовый документ использует свой собственный набор кодировок, то возникают большие трудности с автоматическим распознаванием текста.
2. Появляются новые символы (например: Евро), вследствие чего ISO разрабатывает новый стандарт ISO-8859-15, который весьма схож со стандартом ISO-8859-1. Разница состоит в следующем: из таблицы кодировки старого стандарта ISO-8859-1 были убраны символы обозначения старых валют, которые не используются в настоящее время, для того, чтобы освободить место под вновь появившиеся символы (такие, как Евро). В результате у пользователей на дисках могут лежать одни и те же документы, но в разных кодировках.
Решением этих проблем является принятие единого международного набора кодировок, который называется универсальным кодированием или Unicode.
Кодировка Unicode
Данная кодировка решает пользовательские проблемы (см. выше), но создает новые, технические проблемы: как пересылать символы в формате Unicode, используя 1 байт. 8-битные единицы являются наименьшими передаваемыми единицами в большинстве компьютеров, а также являющимися минимальными единицами, используемыми при сетевых соединениях на основе протокола TCP/IP. Использование 1-го байта для представления 1-го символа стало эпизодом истории (факт появления такой кодировки обусловлен тем, что компьютеры зародились в Европе и США, где долгое время обходились 96 символами).
Существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.
Получается, что 8 бит используются для кодирования европейских языков, а для китайского, японского и корейского языков много больше. Это может повлиять на объем занимаемого дискового пространства и на скорость передачи по сети. Для основных кодировок картина следующая (К (%) - увеличение дискового пространства и снижение скорости передачи по сети):
UTF-8: никаких изменений для американской ASCII, незначительное ухудшение (К = несколько %) для ISO-8859-1, К=50% для китайского, японского, корейского и К=100% для греческого и кириллицы.
UCS-2 и UTF-16: никаких изменений для китайского, японского, корейского; К=100% для американской ASCII, ISO-8859-1, греческого и кириллицы.
UCS-4: К=100% для китайского, японского, корейского; К=300% для американской ASCII, ISO-8859-1, греческого и кириллицы.
В итоге получается, что UTF-8 кодировка занимает меньше дискового пространства и позволяется передавать данные по сети с большей скоростью.
Unicode 3.0
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 7- и 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
соответствующее числовое значение (для цифровых символов).
Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0.
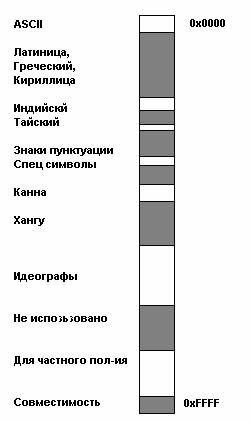
Рис. 6. Кодировка Unicode 3.0.
Формат UTF-8: Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.
Диапазон Unicode Двоичный код символа Байты UTF-8 (двоичные)
0000 - 007F 00000000 0zzzzzzz 0zzzzzzzz
0080 - 07FF 00000yyy yyzzzzzz 110yyyyy 10zzzzzz
0800 - FFFF xxxxyyyy yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции.
Формат UTF-16: Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 - 1FFFF, 20000 - 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16. Для базовой языковой плоскости, т.е. для символов с кодами от 0000 до FFFF, он совпадает с Unicode.
КОИ-8
КОИ-8 (код обмена информацией, 8 битов), KOI8 — восьмибитовая ASCII-совместимая кодовая страница, разработанная для кодирования букв кириллических алфавитов.
Существует также семибитовая версия кодировки, не полностью совместимая с ASCII — КОИ-7. КОИ-7 и КОИ-8 описаны в ГОСТ 19768-74 (сейчас недействителен).
Разработчики КОИ-8 поместили символы русского алфавита в верхней части кодовой таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читабельный» текст, хотя он и написан латинскими символами. Например, слова «Русский Текст» превратились бы в «rUSSKIJ tEKST». Как побочное следствие, символы кириллицы оказались расположены не в алфавитном порядке.
Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский — в KOI8-U.
KOI8-R стал фактически стандартом для русской кириллицы в юникс-подобных операционных системах и электронной почте.
В Microsoft Windows KOI8-R присвоен код страницы 20866, KOI8-U — 21866.
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII.
В приведённых таблицах числа под буквами обозначают шестнадцатеричный код буквы в Юникоде.
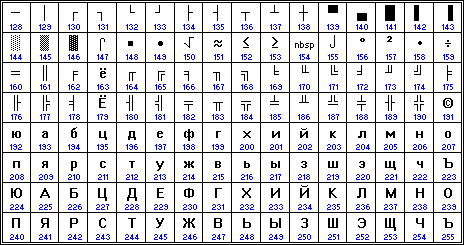
Рис. 7. КОИ8-R

Рис. 8. КОИ8-U