

Laboratory work 2.1 a study of parallelism in algorithmic structure
Aim of the work: The work is aimed at gaining practical experience in software development for analysis of algorithmic structures realized in parallel computing systems.
Basic Principles
 The
algorithmic structure is a graphic representation of any algorithm in
terms of a set of operator nodes and arcs which connect these nodes
(Fig. 2.4).
The
algorithmic structure is a graphic representation of any algorithm in
terms of a set of operator nodes and arcs which connect these nodes
(Fig. 2.4).
Each such structure represents an algorithm of any calculation which may be realized via a sequential, parallel-sequential, or parallel structure.
The following description-coding system may be used for realization of the above mentioned processing types. A binary algorithm (with binary or unary operations) may be described via a model with the following rules: the algorithm may contain binary or unary operations; the operands may be as follows: input data, output data and the result of the previous operation, output data and the result of the operation performed not less than for two previous operation cycles, result of the previous operation, two results of the previous or earlier operations. Let us introduce such a coding for model description: a is an input data; ( is an opening parenthesis; ) is a closing parenthesis; t is an operation; F is an operation result. According to the rules of model description and the chosen coding, let us define a set of variants which are possible when analyzing the algorithm:
1. (Aiaktf); 2. (Fiaktf); 3. (FiFktf); 4. )aitk); 5. )ti); 6. )Fitk).
Variants from 4 to 6 are so-called open blocks since the operand for performing the operation tf is determined immediately in the previous operation cycle. Variants from 1 to 3 are closed blocks since they have direct information about the operands obtained in the appropriate operations. Variant 1 determines operands for the operation tf, these operands are input data, so this block is performed regardless of data, i.e. without time delays.
Let us make up a description of the algorithm, presented in Fig. 2.4, using the coding F, a, t, (, and ):
R(aiajti)(akaltj)(amaktk)avtm)(FiFjtl)actn)Fmtc).
This description is sufficient for scheduling the execution of operations. Being data-dependent, none of the operations can be performed before all the necessary operands are determined. For example, the operation tl may not be performed before the operations ti and tj are completed, and the operation tc may not be performed before the operations tn and tm are completed. Thus, the algorithmic structure defines the order of execution of operations, and this order can be automatically analyzed by means of a computer.
Let the coding of description elements be chosen as follows:
ai is 1000+i,
( is 2000,
) is 3000,
ti is 4000+i,
Fi is 5000+i,
where i is the current number of input data, the numbers of operations, and the numbers of operations in which the result F has been determined.
The coded description of the algorithm, depicted in Fig. 2.4, is as follows:
2000 100i 100j 400i 3000 2000 100k 100l 400j 3000 2000 100m 100n 400k 3000 100v 400m 3000 2000 500i 500j 400l 3000 100c 400n 3000 500m 400c 3000.
The operation of the analysis program begins with searching the first operation in the description. This operation is 400i. Having read the two previous cells, the program finds that the operands for this operation are input data, that’s why the priority of this operation is 1 (Pr1). The same priority (Pr1) is defined for the operations 400j and 400k. While defining priority for the operation 400m the following rule is used: the highest priority of the operands is incremented by one. For the operation 400m, one of the operands is input data, and the other is the result of the operation 400k with the priority Pr1. That’s why its priority is Pr2. The next operation 400l has the same priority Pr2 since its operands are the results of the operations 400i and 400j with the priority Pr1. The operation 400n has the priority Pr3, and the operation 400c has the priority Pr4.
The schedule of operations executed by the cycles of data transformation is as follows (Table 2.2).
Table 2.2
Data transformation cycle |
Operation number |
1 |
titjtk |
2 |
tltm |
3 |
tn |
4 |
tc |
Seven cycles of data transformation is necessary for sequential execution, and only four cycles - for sequential-parallel execution.
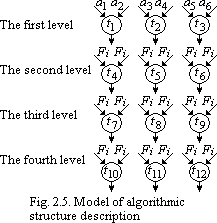 We
shall use the described method of description-coding and analysis for
a multi-level structure in which the first level transforms input
data and the connections in the next levels are defined with the help
of a random number generator. The structure is shown in Fig. 2.5 in
which the first level transforms only input data, the second level
transforms data after the first level of transformation; the third
level transforms data after the first and second levels; and the
fourth level transforms data after the first, second, and third
levels.
We
shall use the described method of description-coding and analysis for
a multi-level structure in which the first level transforms input
data and the connections in the next levels are defined with the help
of a random number generator. The structure is shown in Fig. 2.5 in
which the first level transforms only input data, the second level
transforms data after the first level of transformation; the third
level transforms data after the first and second levels; and the
fourth level transforms data after the first, second, and third
levels.
The concrete connections are given with the help of the random numbers generator. With the help of these values x(i), the codes for Fi of the second level are formed as 4000+x(i). The codes for Fi of the third and fourth levels are formed analogously given the above mentioned conditions.
A fragment of the algorithmic structure description (see Fig. 2.5) may be as follows:
2000 1001 1002 4001 3000 2000 1003 1004 4002 3000 2000 1005 1006 4003 3000 2000 50** 50 ** 4004 3000 2000 50** 50** 4005 3000 …, where ** are values of the random number generator x(i); x(i) = 1 to 3 for the second level.