

Алгоритм, использующий z-буфер
Этот алгоритм более простой, работает в пространстве изображения и использует буфер глубины (Z-буфер).
Для его реализации требуется не только буфер регенерации, в котором запоминаются значения яркости каждого пикселя, но и Z-буфер, в который помещается информация о Z-координате для каждого пикселя.
Шаги алгоритма:
Сначала в Z-буфер заносятся максимально возможные значения Z, а буфер регенерации заполняется значениями пикселей, описывающих фон.
Затем каждый многоугольник преобразуется в растровую форму, и при разложении в растр для каждой точки (x,y) выполняются следующие действия:
Вычисление глубины многоугольника z(x,y) в точке (x,y).
Если значение z(x,y) меньше, чем значение Z-буфера в позиции (x,y), то:
z(x,y) заносится в элемент (x,y) Z-буфера;
значение пикселя (яркость), которое имеет многоугольник в рассматриваемой точке (x,y), помещается в элемент буфера регенерации (x,y).
Если условие шага 2) выполняется, то считается, что точка многоугольника расположена ближе к наблюдателю, чем точка, значение яркости которой находится в данный момент в позиции (x,y) буфера регенерации. Поэтому в позицию (x,y) Z-буфера записывается новое значение глубины, а в позицию (x,y) буфера регенерации – новое значение яркости.
Таким
образом, весь процесс представляет
собой поиск минимального
 для заданных x и y
среди множества пар {
для заданных x и y
среди множества пар {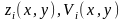 },
где V – яркость. При
успешном поиске минимальное значение
z помещается в Z-буфер
для каждой позиции (x,y).
Очередность появления объектов на
экране определяется порядком обработки
многоугольников.
},
где V – яркость. При
успешном поиске минимальное значение
z помещается в Z-буфер
для каждой позиции (x,y).
Очередность появления объектов на
экране определяется порядком обработки
многоугольников.
Алгоритм построчного сканирования
Этот алгоритм работает в пространстве изображения.
Основная идея заключается в том, чтобы в каждый момент времени проходить и заполнять лишь одну строку развертки, то есть образ фигуры генерируется построчно.
Далее изложен общий подход к реализации алгоритмов построчного сканирования.
Шаг 1.
Создается таблица ребер (ТР), содержащая все негоризонтальные ребра многоугольников. Элементы ТР отсортированы по группам по меньшей y-координате каждого ребра, а внутри групп – в зависимости от тангенса угла наклона.
Эти элементы содержат:
x-координату конечной точки ребра с меньшей y-координатой;
y-координту другой конечной точки ребра;
приращение Δx координаты x, используемое для перехода от каждой сканирующей строки к следующей (Δx обратно тангенсу угла наклона ребра);
идентификатор многоугольника, которому принадлежит ребро.
Шаг 2.
Создается таблица многоугольников (ТМ), которая содержи следующие данные о каждом многоугольнике:
коэффициенты уравнения плоскости;
информация о закраске или цвете многоугольника;
ф
 лаг
(логическая переменная), определяющая
положение «вне/внутри» многоугольника
(исходное значение – false).
лаг
(логическая переменная), определяющая
положение «вне/внутри» многоугольника
(исходное значение – false).
На рисунке выше показаны 2 треугольника в проекции на плоскость xy, один из которых частично закрывает другой.
Отсортированная ТР содержит элементы для AB, AC, FD, FE, CB, DE.
ТМ содержит элементы для ABC и DEF.
Шаг 3.
Создается таблица активных ребер (ТАР) – ребер, которыя пересекает сканирующая строка.
Эта таблица всегда упорядочена по возрастанию x-координаты (ребра рассматриваются слева направо).
Когда алгоритм дойдет до строки
 ,
ТАР будет содержать АВ и АС.
,
ТАР будет содержать АВ и АС.
Приступая к обработке АВ, инвертируем флаг «вне/внутри» (= true), и так как мы находимся внутри только одного треугольника, то он виден и на интервале от АВ до АС будет вестись закраска, требуемая для треугольника АВС.
При прохождении ребра АС флаг = false, и мы не находимся внутри ни одного из треугольников. Так как АС – последнее ребро в ТАР, обработка сканирующей строки завершается. В ТАР вносятся изменения из ТР, она снова упорядочивается по x и выполняется обработка следующей сканирующей строки.
Примечание.
При переходе к следующей сканирующей
строке новые значения x-координат
точек пересечения вычисляются с помощью
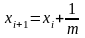 ,
где m – тангенс угла
наклона. Все новые ребра, пересекаемые
сканирующей строкой, добавляются в ТАР,
а те ребра, которые содержатся в ТАР, но
не пересекаются – удаляются.
,
где m – тангенс угла
наклона. Все новые ребра, пересекаемые
сканирующей строкой, добавляются в ТАР,
а те ребра, которые содержатся в ТАР, но
не пересекаются – удаляются.
Когда встретится строка
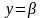 ,
ТАР будет содержать AB,
AC, FD,
FE.
,
ТАР будет содержать AB,
AC, FD,
FE.
Со сканирующей строкой пересекаются два треугольника, но в каждый момент мы будем находиться внутри только одного из них. Поэтому последовательность обработки будет такой же, что и в случае .
Когда встретится строка
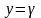 ,
ТАР будет содержать AB,
DE, CB,
FE.
,
ТАР будет содержать AB,
DE, CB,
FE.
При входе в ABC флагАВС = true. На интервале от точки входа до DE ведется закраска, требуемая для треугольника ABC. В точке пересечения с DE флагDEF также = true, и мы находимся внутри сразу двух многоугольников. Теперь возникает задача, какой из треугольников ближе к наблюдателю. Определение производится путем вычисления значений z из уравнений плоскости для обоих треугольников при и при х-координате точки пересечения и DE. Эта величина х уже содержится в ТАР для DE.
В нашем случае
нашем случае
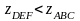 ,
и поэтому мы видим DEF
и правило закраски DEF
действует на всем интервале до пересечения
с BC, где флагАВС
= false, после чего
интервал снова будет внутри одного
треугольника DEF.
Поэтому правило закраски DEF
действует до пересечения с FE.
,
и поэтому мы видим DEF
и правило закраски DEF
действует на всем интервале до пересечения
с BC, где флагАВС
= false, после чего
интервал снова будет внутри одного
треугольника DEF.
Поэтому правило закраски DEF
действует до пересечения с FE.
Описанная выше последовательность действий представляет собой основу для реализации алгоритмов построчного сканирования.
В общем случае существует множество частных особенностей, требующих отдельного анализа.