

8.6.1. Критерий согласия 2 (критерий Пирсона)
Этот критерий является важнейшим из , применяемых на практике. Предположим, что, как это изложено в п.8.2. , построены выборочные гистограммы плотности вероятности и кроме того имеется график плотности вероятности гипотетического распределения. Обозначим: pi - вероятность попадания случайного числа X в i-й класс; ni - выборочная частота попадания случайной величины X в i-й класс. Предполагается, что величины pi взяты из данных для гипотетического распределения. Таким образом p1+p2+. . .+pk =1 и n1+n2+. . .+nk= n . Здесь k - число классов (столбцов) гистограммы; n - размер выборки. Теоретическая частота попадания случайной величины в i-й класс очевидно равна pi.n. В качестве меры отклонения распределения выборки от гипотетического можно принять следующую случайную величину (статистику):
![]() .
.
Данная статистика асимптотически (т.е. при n ) имеет распределение 2 с (k-1) степенью свободы, и не зависит от гипотетического распределения. Это утверждение доказано К. Пирсоном.
Критерий применяется следующим образом. Делается n наблюдений случайной величины X . Область полученных значений X разбивается на классы необязательно одинаковой ширины таким образом, чтобы число наблюдений в каждом классе ni было достаточно велико. В литературе имеются различающиеся рекомендации по минимальному числу таких наблюдений от 4 до 10. Если же некоторые ni слишком малы, то перед применением критерия целесообразно объединить такие классы. Если же выборка очень мала, то критерием пользоваться не следует. Строится выборочная функция плотности распределения. Принимается гипотетическая функция плотности. Далее выбирается уровень значимости , подсчитывается величина X2 и сравнивается с квантилью 2(1-), k-1. Если X2 > 2(1-), k-1 , то гипотетическое распределение отвергается.
Приведенная выше формула для X2 обладает одной особенностью. Дело в том, что она требует, чтобы гипотетическая функция плотности распределения была полностью известна. На практике чаще бывает известен лишь общий вид этой функции, а параметры от которых она зависит как правило неизвестны и могут быть получены лишь на основе выборочных данных. Например, если в качестве гипотетической функции взять функцию плотности нормального распределения , то ее параметры - математическое ожидание и стандартное отклонение могут быть неизвестны заранее и оценены лишь про результатам статистической обработки выборки.
Р.Фишер показал, что в случае r неизвестных параметров гипотетического распределения можно воспользоваться их статистическими оценками для определения pi в формуле для X2 , но полученное таким образом значение X2 будет подчиняться ХИ-квадрат распределению с f=k - r -1 степенями свободы. Таким образом число степеней свободы распределения X2 уменьшается на число r неизвестных параметров гипотетического распределения. При этом r < k, а статистические оценки параметров должны быть получены методом максимального правдоподобия.
Примечание. Суть метода максимального правдоподобия заключается в том, что в качестве оценки для параметра , выбирается такая величина, которая доставляет функции правдоподобия максимум. Рассмотрим x1, x2,... xn выборочные n значений случайной величины X с плотностью вероятности f(x,), зависящей от неизвестного параметра . Указанную выборку следует рассматривать как многомерную случайную величину c взаимно независимыми компонентами x1, x2,... xn. Функцией правдоподобия называется плотность распределения этой многомерной случайной величины.
L(x1, x2,... xn,)=f(x1,) f(x2,)... f(xn,).
Для нахождения параметра нужно решить уравнение dL/d=0.
Пример 8.7. Рассмотрим для условий примера 8.2 сходство полученного в нем эмпирического распределения с гипотетическим нормальным распределением. При этом используем выборочные значения среднего равное 3,85, которое совпадает с оценкой максимального правдоподобия. Для дисперсии оценка максимального правдоподобия будет отличаться от полученной в примере 8.2. Ее можно получить, если в формуле для дисперсии использовать в качестве знаменателя общую длину выборки n=50. Полученное в результате стандартное отклонение равно 1,126.
Учитывая, что в первом и седьмом классах гистограммы число наблюдаемых величин мало мы объединим их с соседними и в результате получим пять классов и соответственно число степеней свободы для ХИ-квадрат распределения будет равно f=5-2-1=2. Для вычисления гипотетических вероятностей попадания случайных величин в классы воспользуемся таблицами вероятности нормального распределения. Результаты представим в табл.8.6.
Таблица 8.6.
-
Классы
Частота попа-
дания в класс ni
Гипотетическая
вероятность pi
n.pi=50.pi
(ni - n.pi)2
n.pi
0,512,51
5
0,117
5,85
0,123
2,513,51
14
0,265
13,25
0,042
3,514,51
18
0,339
16,95
0,065
4,515,51
10
0,209
10,45
0,019
5,517,51
3
0,069
3,45
0,059
Суммируя данные последнего столбца получим X2 = 0,308. По таблице ХИ-квадрат распределения для двух степеней свободы и уровня значимости 0,2 находим квантиль 20,8; 2= 3,22. Это означает, что с доверительной вероятностью 0,8 эмпирическое распределение согласуется с нормальным. На нижеследующем рисунке изображены гистограммы выборочной (сплошная линия) и гипотетической (штриховая линия) плотности распределения.
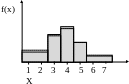
Рис.8.3. Гистограмма плотности вероятности