

2.2. Реализация стеков
2.2.1. Непрерывная реализация стека с помощью массива
Если максимально возможное количество элементов в стеке реально ограничено каким-либо значением, можно предложить самый простой способ реализации — массив. В этом случае для стека выделяется непрерывная область памяти ограниченных размеров. Фактическое количество элементов в стеке в произвольный момент времени может быть намного меньше заданного граничного значения, но ни в коем случае не может быть больше. Поэтому при добавлении элементов в стек обязательно следует предусмотреть обработку аварийной ситуации, связанной с его переполнением.
Рис. 2.1. поясняет работу со стеком на основе массива из maxlength элементов. Идея проста — достаточно завести дополнительный указатель top на вершину стека (или индекс элемента, который в данный момент является вершиной). Заметим, что в реализации на языке С при работе с массивами удобно использовать указатели, при этом имя массива, на основе которого реализован стек, является указателем на самый первый элемент стека («дно» стека). Нулевое значение указателя top соответствует пустому стеку. В случае использования индексов, а не указателей, признаком пустого стека может быть любое предопределенное значение, например отрицательное число.
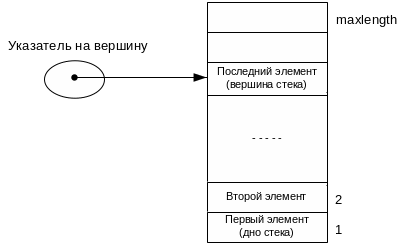
Рис.2.1. Представление стека с помощью массива
Алгоритмы для реализации операций удаления и вставки элементов просты и сводятся к изменению значения указателя top на единицу. При этом, конечно, нельзя забыть о крайних случаях, связанных с добавлением элемента в переполненный стек или попыткой извлечения элемента из пустого стека. В этом случае необходимо обработать аварийную ситуацию любым способом, допустимым в языке программирования.
В листинге 2.1. приведена реализация функций для работы со стеком. При этом стек оформлен в виде структуры языка С++ (struct stack), функции для работы со стеком также входят в состав данной структуры как ее методы, что разрешено правилами языка. Таким образом реализуем объектно-ориентированный подход в простейшем виде, не вникая в многочисленные нюансы. Для наших целей этого вполне достаточно.
Стек может содержать данные любого типа (но обязательно одного и того же). В языке С++ имеется два способа сделать описание структуры независимым от типа элементов— оператор typedef и шаблоны (template). В примерах будут продемонстрированы оба подхода. Так, в листинге 2.1 с помощью оператора typedef определяем тип type_of_data (для примера взят тип char). Изменить тип элементов очень легко — достаточно поменять только этот оператор typedef.(можно вообще поместить этот оператор в отдельный файл, который подключать с помощью директивы #include). Шаблоны — это еще более кардинальное средство сделать код независимым от типа данных, поскольку на основе шаблона можно определять стеки, содержащие данные любого типа без всяких изменений в описании самого стека.
Обработка аварийных ситуаций также может выполняться по-разному. В примерах реализован самый простой способ — сообщение об ошибке посылается в стандартный выходной поток cerr и выполнение программы прекращается. Можно предложить и другие варианты, например, использование исключительных ситуаций, самое главное — не допустить неправильной работы функций в подобных крайних случаях.
Последнее замечание. Операция создания пустого стека (в спецификации Create) реализована как конструктор — специальный метод, который автоматически выполняется при создании структуры stack. В языке С++ это обычная практика, которой будем пользоваться и в дальнейшем. Заметим, что память под массив, на основе которого создан стек, можно захватить динамически в конструкторе, при этом появится возможность управлять максимальными размерами стека (в языке С++ разрешены конструкторы с параметрами, поэтому значение maxlength может быть параметром). Оставим это для самостоятельной реализации. В листинге добавлена еще одна полезная функция makenull — удаление из стека всех элементов, в данном примере она, также как и конструктор, содержит всего один оператор top=NULL;.
Листинг 2.1. Реализация стека с помощью массива
#include <stdlib.h>
#include <iostream.h>
const int maxlength=100; // максимально возможный размер //стека (может быть любым)
typedef char type_of_data; // тип элементов(может быть любым, //char только пример)
struct stack
{ type_of_data data[maxlength]; // массив данных, на основе //которого создан стек
type_of_data *top; // указатель на вершину
// прототипы функций для работы со стеком
stack() {top=NULL;} //конструктор, выпоняется автоматически //при создании стека
void push (type_of_data x); // поместить значение x в стек
type_of_data pop(); // извлечь элемент с вершины стека
bool isnull() {return top==NULL;}//проверить, пуст ли стек
void makenull() {top=NULL;}; // сделать стек пустым
};
//реализация функций, знак :: обозначает принадлежность
// структуре stack
void stack::push (type_of_data x)
{ if (isnull()) { top=data; *top=x;} //стек был пуст
else
if (top-data<maxlength-1) { top++; *top=x;} // стек //заполнен не полностью
else
{ cerr << "Стек полон\n"; exit(2); // аварийная ситуация
}
}
type_of_data stack::pop ()
{ type_of_data temp=*top; // запомнили последний элемент
if (isnull()) {cerr << "Стек пуст \n"; exit(1);} // //аварийная ситуация
if (top==data) makenull(); else top--; // удалили элемент
return temp; // функция возвращает удаленный элемент
}