

Лабораторная работа № 6 «изучение атд «словарь», «файл» и «нагруженное дерево»»
Цель работы: исследовать и изучить АТД «словарь», «файл» и «нагруженное дерево».
Задача работы: овладеть навыками составления структур АТД «словарь», «файл», «нагруженное дерево» и написания программ по исследованию этих структур на любом языке программирования.
Порядок работы:
изучить описание лабораторной работы;
по заданию, данному преподавателем, разработать одну из структур: АТД «словарь», «файл» или «нагруженное дерево»;
написать программу;
отладить программу;
решить задачу;
оформить отчет.
Краткая теория
Словарь
Словарь – это абстрактный тип множеств. Эти множества хранят текущие объекты с периодической вставкой или удалением некоторых из них. Временами так же возникает необходимость проверки присутствия элемента в этом множестве.
Словарь можно реализовать тремя способами:
1)посредством сортированных или не сортированных связанных списков;
2)при помощи двоичных векторов, если элементы данного множества целые числа;
3)используя массив фиксированной длины с указателем на последнюю заполненную ячейку этого массива, если размер множества не превышает заданную длину массива, в противном случае используются связанные списки.
Нагруженное дерево
Нагруженное дерево – это символьное множество и оно имеет такую структуру, которая позволяет использовать его для хранения, поиска, вставки или удаления символьных строк (слов). Каждый узел такого дерева – это префикс из слов множества, т.е. одна буква из слова. Каждый путь от корня к листу соответствует одному слову из множества. Чтобы избежать коллизий слов вводится специальный маркер конца – это символ $, который указывает на окончание любого слова.
Приводим ниже пример такого дерева для слов сад, сан, санки, сок, сокол, сор, сорока (рис. 5.2).
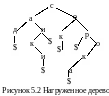
Такая структура необходима для организации поиска заданного слова среди множества слов. Если ранее искалось слово среди последовательно расположенных друг за другом слов (исчерпывающий поиск), то теперь с такой структурой достаточно пройти по ветви дерева от корня до листа, чтобы проверить есть ли в данном множестве такое слово или нет (метод ветвей и границ).
Нагруженное дерево можно реализовать двумя способами:
1)через массив указателей на узлы такого же типа;
2)посредством связанных списков.
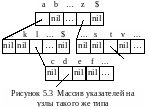
Самая простая реализация нагруженного дерева – это массив указателей на узлы такого же типа.
Узлы дерева – это то же массивы указателей такого же типа. Структура динамическая и может иметь любую степень исхода узла и высоту дерева. Индексами в массиве являются элементы множества {A, B, ..., Z, $} (рис. 5.3).
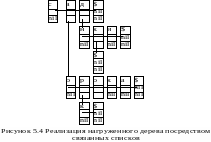
Нагруженное дерево может использоваться так же и для реализации «словаря». В этом случае узлы нагруженного дерева представляются посредством связанных списков (рис. 5.4). Такое представление «словаря» эффективнее, чем его обычная структура, реализованная через связанные списки.
Файл
Файл – это последовательность записей, причём каждая запись состоит из одной и той же совокупности полей. Поля могут иметь фиксированную длину – это когда заранее определённо количество байт, или переменную. Файлы с записями фиксированной длины широко используются в системах управления базами данных для хранения данных со сложной структурой. Файлы с записями переменной длины используются для хранения текстовой информации (в Pascal такие файлы не предусмотрены).
Сам «файл» может храниться в виде массива или списка. А различные способы реализации «файла» – это структура быстрого доступа к элементам «файла», т.е. надстройка для удобного поиска среди множества элементов «файла».
Способы доступа к элементам «файла»:
1) через разряженный индекс;
2) через B-дерево.
«Файл», реализованный через разреженный индекс, формируют в отсортированном по значениям ключей порядке (рис. 5.5). При такой организации файл рассматривается как обычный словарь или телефонный справочник, если мы просматриваем лишь заглавные слова или фамилии на каждой странице, т.е. это последовательно расположенные по возрастанию или убыванию данные, хранящиеся в массиве или в списке. Для облегчения поиска можно создать второй файл, который называется разреженным индексом, состоящий из пар (element1, next), где element1 – это значение ключа, а next – это физический адрес блока, в котором значение ключа первой записи равняется element1. Этот разряженный индекс отсортирован по значениям ключей (рис. 5.5).

Можно составить тип для такого способа доступа к «файлу»: