

1. Основные признаки структуры данных: 1. возможные множество допустимых значений; 2. характер отношений м/у данными; 3. операции над данными. Математически структуру данных можно определить S= (D,R), где D - множество данных, R –множество отношений. Типы отношений: -одного к одному; -отношения одного ко многому; -отношения многих ко многим. Основные операции: -поиск; -вставка; -удаление. Структуры данных - совокупность элементов данных, м/у которыми существуют определенные отношения, причем элементами данных может быть, как простые данные, так и структуры данных. Различают: - логические и физические. Логические - структуры данных без учета представления их в памяти. Физические – отражает способ физического представления данных машиной и осуществляется с помощью функции адресации. Дескриптор (заголовок) – существует для запоминания структуры и ее параметра. Алгоритм, необходимо: 21. знать с какой структурой работает алгоритм; 2. качество. Сложность алгоритма: временная и емкостная; n – количество данных; Типы сложности алгоритма: 1. логарифмическая O(log (n)); 2. линейная O(n); 3. полиномиальная O( a n ) a=const; 4. экспоненциальная O( n a ). Классификация структур данных: 1) – оперативные (для оперативной памяти); – внешние (для внешней памяти); 2) В зависимости от наличия заданных связей: - несвязанные (векторы, массивы, строки); - связанные (связанные списки); 3) изменчивость структуры в процессе выполнения программ: - статические (размеры и взаимоотношения структуры не меняются); - полустатические (меняются только размеры); - динамические (меняются и размеры и связи м/у элементами); 4) По характеру упорядоченности: - линейные; - нелинейные (связыв. различные куски памяти с помощью указателя).
2 .
Абстрактный
тип данных
- это множество абстрактных объектов,
представляющих элементы данных, и
определенные на нем наборы операций,
которые могут быть выполнены над
элементами этого множества. Абстрактные
структуры данных предназначены для
удобного хранения и доступа к информации.
Они предоставляют удобный интерфейс
для типичных операций с хранимыми
объектами, скрывая детали реализации
от пользователя. Конечно, это весьма
удобно и позволяет добиться большей
модульности программы. Пример. Для
автоматизированного управления
температурой в различных комнатах
большого здания полезным АТД был бы
ТЕРМОСТАТ. В программе может быть много
переменных типа ТЕРМОСТАТ, соответствующих
реальным термостатам в различных
помещениях здания. АТД может быть описан
своим именем, множеством значений и
допустимыми операциями так же, как и
любой другой тип данных. АТД
— это способ определения некоторого
понятия в виде класса объектов с
некоторыми свойствами и операциями. В
языке программирования такое определение
оформляется как специальная синтаксическая
конструкция, называемая в разных языках
капсулой, модулем, кластером, классом,
пакетом, формой и т.д. Эта конструкция
в самой развитой форме содержит:
спецификацию типа данных, включающую
описание интерфейса (имя определяемого
типа, имена операций с указанием их
профилей) и абстрактное описание операций
и объектов, с которыми они работают,
некоторыми средствами спецификации;
реализацию типа данных, включающую
конкретное описание тех же операций и
объектов. Реализация АТД включает
конкретное описание объектов определяемого
типа и реализацию операций этого типа.
.
Абстрактный
тип данных
- это множество абстрактных объектов,
представляющих элементы данных, и
определенные на нем наборы операций,
которые могут быть выполнены над
элементами этого множества. Абстрактные
структуры данных предназначены для
удобного хранения и доступа к информации.
Они предоставляют удобный интерфейс
для типичных операций с хранимыми
объектами, скрывая детали реализации
от пользователя. Конечно, это весьма
удобно и позволяет добиться большей
модульности программы. Пример. Для
автоматизированного управления
температурой в различных комнатах
большого здания полезным АТД был бы
ТЕРМОСТАТ. В программе может быть много
переменных типа ТЕРМОСТАТ, соответствующих
реальным термостатам в различных
помещениях здания. АТД может быть описан
своим именем, множеством значений и
допустимыми операциями так же, как и
любой другой тип данных. АТД
— это способ определения некоторого
понятия в виде класса объектов с
некоторыми свойствами и операциями. В
языке программирования такое определение
оформляется как специальная синтаксическая
конструкция, называемая в разных языках
капсулой, модулем, кластером, классом,
пакетом, формой и т.д. Эта конструкция
в самой развитой форме содержит:
спецификацию типа данных, включающую
описание интерфейса (имя определяемого
типа, имена операций с указанием их
профилей) и абстрактное описание операций
и объектов, с которыми они работают,
некоторыми средствами спецификации;
реализацию типа данных, включающую
конкретное описание тех же операций и
объектов. Реализация АТД включает
конкретное описание объектов определяемого
типа и реализацию операций этого типа.
3. Статические структуры включают: векторы, массивы, записи, таблицы. Вектор, одномерный массив – конечное упорядоченное множество структур данных одного и того же типа. Физическая структура вектора представляется в машинной памяти последовательностью одинаковых по длине участков памяти, называемых полями или слотами, каждый из которых предназначен для хранения одного элемента вектора. Слот может иметь размер минимальной адресуемой ячейки памяти или соответствовать целой группе последовательных ячеек памяти. Операции над структурами: - доступ к элементу; - определение размера структур; - описание типов элемента. Массив – вектор, каждый элемент которого вектор. В свою очередь элементы вектора тоже могут быть векторами (многомерные массивы). Преобразование логической структуры массива в физическую структуру может быть выполнено многими способами. Однако, на практике, обычно используют только два способа: отображение строками и отображение столбцами. Частный случай массива – разреженный массив, большинство элементов – 0. В этом случае - хранить только ненулевые элементы в виде связного списка. Запись - конечное упорядоченное множество элементов с различным типом данных, т.е. обобщение вектора (не требуется однотипность или однородность). Запись: - простая; - многоуровневая. Элементы записи - поля. Доступ к любому элементу записи осуществляется с помощью имени, которое должно задаваться для каждого элемента на этапе описания логической структуры записи. Дескриптор записи может содержать имя записи, число входящих элементов, имена и типы элементов, длины соответствующих полей, указатели значений элементов. Таблица - конечное множество записей, имеющих одну и ту же организацию. Запись, входящая в таблицу – элемент таблицы. Таблица представляет собой такое обобщение понятия двухмерного массива, в котором свойство однотипности элементов массива требуется лишь для элементов, расположенных в одном и том же столбце. Доступ к каждому элементу таблицы осуществляется не с помощью индексов, а с помощью ключа, причем целью служит не отдельное данное, а целая запись. Операции: включение данных о новом элементе, поиск заданного элемента и исключение заданного элемента из таблицы. Св-ва статических структур: 1. постоянство структуры в течении всего времени ее существования; 2. смежность элементов и непрерывность области памяти, отводимой сразу для всех элементов структуры; 3. простота и постоянство отношений между элементами структуры, позволяющие исключить информацию об этих отношениях и хранить ее в компактной форме в дескрипторах.
4. Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняется только с одной стороны списка по принципу “последним пришел, первым ушел”. Очередь- это такой последовательный список с переменной длиной, включение элементов в который происходит с одной стороны, а исключение с другой стороны списка. Дек - это последовательный список, в котором как включение, так и исключение элементов может осуществляться с любого из двух концов списка. Списком называется линейно-упорядоченная последовательность элементов данных E(1), E(2), ..., E(n), где n>0, причем каждый элемент характеризуется одним и тем же набором полей. Такой список называют линейным вследствие линейной упорядоченности его элементов.
5![]() .
Связный
список -
это такая структура, элементами которой
служат записи с одним и тем же форматом,
связанные друг с другом с помощью
указателей хранящихся в самих элементах.
Простейшими связными являются линейные
односвязные и двусвязные списки. В
односвязном списке каждый элемент
состоит из двух различных по назначению
полей: содержательного поля и поля
указателя. Линейный
двусвязный список
отличается
от односвязного списка тем, что его
элемент содержит два указателя, один
из которых (прямой указатель) адресует,
как в односвязном списке, следующий
элемент, а другой указатель ( обратный
) адресует предыдущий элемент списка.
В структуру двусвязного списка добавлен
указатель конца списка. Наличие двух
указателей в каждом элементе заметно
усложняет список и приводит к дополнительным
затратам памяти, но обеспечивает более
эффективное выполнение операций над
списком.
.
Связный
список -
это такая структура, элементами которой
служат записи с одним и тем же форматом,
связанные друг с другом с помощью
указателей хранящихся в самих элементах.
Простейшими связными являются линейные
односвязные и двусвязные списки. В
односвязном списке каждый элемент
состоит из двух различных по назначению
полей: содержательного поля и поля
указателя. Линейный
двусвязный список
отличается
от односвязного списка тем, что его
элемент содержит два указателя, один
из которых (прямой указатель) адресует,
как в односвязном списке, следующий
элемент, а другой указатель ( обратный
) адресует предыдущий элемент списка.
В структуру двусвязного списка добавлен
указатель конца списка. Наличие двух
указателей в каждом элементе заметно
усложняет список и приводит к дополнительным
затратам памяти, но обеспечивает более
эффективное выполнение операций над
списком.
6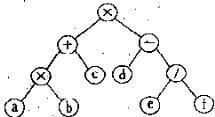 .
Деревом
наз-ся граф к-рый: - связен; - не содержит
ни одного цикла. Св-ва: 1. сущ-ет единственный
элемент/узел, на к-рый не ссылается
никакой др элемент(корень); 2. начиная с
корня и следуя по определенной цепочке
указателей, содерж. в элем-ах, можно
осуществить доступ к люб. Элементу
стр-ры; 3. на кажд. элем, кроме корня,
имеется единственная ссылка(адресуется
единственным указателем). Формы
представления: 1.графическая; 2.символьная;
3.представление с помощью массива и
списка (ломанная последовательность,
линейная: десятичная, код Прюфера).
Линейная
форма дерева
- это
последовательность узлов дерева,
перечисленная в прямом порядке, с
указанием для каждого узла номера
уровня. Одной из разновидностей линейной
формы представления дерева является
десятичная
система обозначений Дьюи,
в которой для каждого узла через
разделитель-точку указываются все
номера уровней узлов, расположенных на
пути от корня к заданному узлу.
Представление деревьев с использованием
списка
сыновей: А->Б->В. Инверсная
форма представления дерева:
отношение между узлами обратно обычным
отношениям, т.е. каждый узел ссылается
на своего предшественника.
.
Деревом
наз-ся граф к-рый: - связен; - не содержит
ни одного цикла. Св-ва: 1. сущ-ет единственный
элемент/узел, на к-рый не ссылается
никакой др элемент(корень); 2. начиная с
корня и следуя по определенной цепочке
указателей, содерж. в элем-ах, можно
осуществить доступ к люб. Элементу
стр-ры; 3. на кажд. элем, кроме корня,
имеется единственная ссылка(адресуется
единственным указателем). Формы
представления: 1.графическая; 2.символьная;
3.представление с помощью массива и
списка (ломанная последовательность,
линейная: десятичная, код Прюфера).
Линейная
форма дерева
- это
последовательность узлов дерева,
перечисленная в прямом порядке, с
указанием для каждого узла номера
уровня. Одной из разновидностей линейной
формы представления дерева является
десятичная
система обозначений Дьюи,
в которой для каждого узла через
разделитель-точку указываются все
номера уровней узлов, расположенных на
пути от корня к заданному узлу.
Представление деревьев с использованием
списка
сыновей: А->Б->В. Инверсная
форма представления дерева:
отношение между узлами обратно обычным
отношениям, т.е. каждый узел ссылается
на своего предшественника.
7. Наиболее общий вид многосвязной структуры - многосвязная структура, которая характеризуется след. свойствами:
1. каждый элемент структуры содержит произвольное число направленных связей с другими элементами(или ссылок на другие элементы); 2. с каждым элементом может связываться произвольное число других элементов (т.е. каждый элемент может быть объектом ссылки произвольного числа других элементов); 3. каждая связь в структуре имеет не только направление, но и вес. Такую многосвязную структуру называют сетевой структурой или сетью. Логически сеть эквивалентна взвешенному ориентированному графу, и поэтому вместо термина "сеть" часто употребляются термин "графовая структура", или просто "граф".
8. Под обходом дерева понимают просмотр в некотором регулярном порядке каждого его узла. Существует несколько принципиально разных способов обхода дерева:
![]()
1. Обход в прямом порядке (КЛП) ABECFGDHIJ. Каждый узел посещается до того, как посещены его потомки(посетить узел; обойти левое поддерево; обойти правое поддерево). Пример использования – сортировка Фон Неймана, быстрая сортировка, умножение длинных чисел.
2. Симметричный обход (ЛКП) EBAFCGHDIJ Алгоритм: левое поддерево; узел; правое поддерево.
3. Обратный обход (ЛПК) EBFGCHIJDA. Узлы посещаются 'снизу вверх' (обойти левое поддерево; обойти правое поддерево; посетить узел). Применение: динамическое программирование, анализ игр с полной инфой.
4 .
Обход в ширину ABCDEFGHIJ. При обходе в ширину
узлы посещаются уровень за уровнем(N-й
уровень
дерева -
множество узлов с высотой N). Каждый
уровень обходится слева направо. Для
реализации используется структура
queue - очередь с методами: enqueue - поставить
в очередь; dequeue - взять из очереди; empty -
возвращает TRUE, если очередь пуста, иначе
– FALSE.
.
Обход в ширину ABCDEFGHIJ. При обходе в ширину
узлы посещаются уровень за уровнем(N-й
уровень
дерева -
множество узлов с высотой N). Каждый
уровень обходится слева направо. Для
реализации используется структура
queue - очередь с методами: enqueue - поставить
в очередь; dequeue - взять из очереди; empty -
возвращает TRUE, если очередь пуста, иначе
– FALSE.
Р азличные
обходы бинарного дерева, дают следующие
формы записи
исходного выражения: 1) *+*аЬс - d/е f -
префиксная
форма (прямой
порядок обхода); 2) (a*b+c)*(d-e/f) - инфиксная
форма, в
которой приоритет выполнения операций
задается структурой дерева (симметричный
порядок обхода); 3) a b*c+def/- * - постфиксная
форма (обратный
порядок обхода).
азличные
обходы бинарного дерева, дают следующие
формы записи
исходного выражения: 1) *+*аЬс - d/е f -
префиксная
форма (прямой
порядок обхода); 2) (a*b+c)*(d-e/f) - инфиксная
форма, в
которой приоритет выполнения операций
задается структурой дерева (симметричный
порядок обхода); 3) a b*c+def/- * - постфиксная
форма (обратный
порядок обхода).
9. Корневые: 1. n-арные: а)случайные(Patricia), б)синтаксические, в)цифрового поиска, г)Trie(нагруженные); 2. бинарные: а)случайные, б)сбалансированные(красно-черные, идеальносбалансированные, АВЛ, ВВ); 3. деревья решений; 4. сильноветвящиеся: а)2-3, б)2-3-4, в)В(В, В*, В+, В++, SB, В с префиксом); 5. многомерные: R, K-D, приоритетного поиска, многомерные В.
10. Любое дерево может быть единственным образом представлено бинарным деревом. На первом этапе для каждой вершины уничтожаются все исходящие из нее ребра кроме самого левого ребра. Вместо них рисуются ребра, каждое из которых соединяет некоторую вершину с вершиной, расположенной справа от нее на том же ярусе, что и рассматриваемая. После этого для каждой вершины дерева осуществляется выбор ее левого и правого сыновей по следующему правилу. Левым сыном является вершина расположенная непосредственно ниже данной вершины, а правым сыном - вершина, расположенная непосредственно справа от данной и на одном ярусе с ней.
11. Усовершенствованный метод представления бин дерева поиска, содержащего n узлов, с помощью массива, размер которого равен n единицам памяти вместо 2n-1, .используется в методе пирам-ной сортировки. Для деревьев определены следующие основные операции: 1) операции доступа: доступ к произвольному узлу дерева, доступ к предшественнику (преемнику) определенного узла, просмотр всех узлов дерева в определенном порядке; 2) поиск заданного элемента (по ключу); 3) операции редактирования на уровне элемента модели (узла): включение, исключение произвольного узла дерева; 4) операции редактирования на уровне модели памяти (дерева): удаление поддерева, замена листа деревом.
1![]() 2.
Бинарное
дерево называется сбалансированным,
если высота левого поддерева каждого
узла отличается от высоты правого
поддерева не более чем на 1. Полностью
сбалансированные деревья являются
частным случаем «сбалансированных
деревьев» и среди сбалансированных
деревьев они являются деревьями с
минимальной высотой при заданном числе
узлов. АВЛ-дерево высоты h есть дерево
с наименьшим числом узлов n,
высота которого почти равна log2n.
(показатель сбалансированности узла)
== (высота правого поддерева этого
узла)—(высота левого поддерева этого
узла). АВЛ-дерево представляет собой
стр-py, для которой любая операция: поиск,
вставка и удаление ключа имеет временную
сложность O(log2n).
2.
Бинарное
дерево называется сбалансированным,
если высота левого поддерева каждого
узла отличается от высоты правого
поддерева не более чем на 1. Полностью
сбалансированные деревья являются
частным случаем «сбалансированных
деревьев» и среди сбалансированных
деревьев они являются деревьями с
минимальной высотой при заданном числе
узлов. АВЛ-дерево высоты h есть дерево
с наименьшим числом узлов n,
высота которого почти равна log2n.
(показатель сбалансированности узла)
== (высота правого поддерева этого
узла)—(высота левого поддерева этого
узла). АВЛ-дерево представляет собой
стр-py, для которой любая операция: поиск,
вставка и удаление ключа имеет временную
сложность O(log2n).
1 3.
Упорядоченное
дерево, каждый узел которого содержит
2 или 3 связи, а все листья расположены
на одном уровне, называется (2—3)-деревом.
Из определения следует, что узел
(2—3)-дерева может содержать один или
два ключа. Поскольку (2—3)-деревья имеют
большую свободу узлов, чем АВЛ-деревья,
изменение структуры затрагивают меньшую
часть дерева и расщепления узлов
выполняются проще, чем балансировка.
3.
Упорядоченное
дерево, каждый узел которого содержит
2 или 3 связи, а все листья расположены
на одном уровне, называется (2—3)-деревом.
Из определения следует, что узел
(2—3)-дерева может содержать один или
два ключа. Поскольку (2—3)-деревья имеют
большую свободу узлов, чем АВЛ-деревья,
изменение структуры затрагивают меньшую
часть дерева и расщепления узлов
выполняются проще, чем балансировка.
14. Обычно в узлах дерева поиска хранятся значения ключей, но в случае, когда ключами яв-ся дост. короткие слова, можно рас-ть каждый ключ как список букв, а все списки вместе—как дерево поиска, структура которого несколько отличается от рассмотренных ранее. В этой структуре узлу (l+1)-го уровня ставится в соответствие 1-я буква слова, так что каждый узел содержит только один символ. Методы поиска по такому дереву часто весьма экономичны как по памяти, так и по времени.
15. При выборе способа машинного представления дерева используется понятие “прошивания” дерева. Этот способ обладает эффективностью как с точки зрения уменьшения объема памяти, так и с точки зрения увеличения быстродействия. Дерево “прошивается” с учетом определенного способа обхода. В этом случае легко разработать алгоритмы обработки дерева и обход осуществляется быстрее, т. к. вместо стека имеется прошивка. Однако включение новой вершины в прошитое дерево занимает больше времени, чем включение ее в непрошитое дерево. При представлении бинарного дерева в стандартной форме листья имеют нулевые значения в полях ссылок. Эти поля ссылок используются для хранения дополнительных связей, упрощающих обход дерева в модели памяти, получившей название прошитого дерева. В прошитом дереве для каждого узла, не имеющего левого преемника, в поле ссылки на левого преемника помещается указатель-нить на узел дерева, который является непосредственным предшественником этого узла при симметричном (прямом, обратном) обходе дерева. Аналогично, в поле ссылки на правого преемника записывается указатель на узел дерева, являющийся непосредственным преемником рассматриваемого узла при симметричном (прямом, обратном) обходе дерева. Для того чтобы различать обычные указатели и указатели-нити, в каждый узел дерева вводятся два дополнительных поля ltag и rtag, в которые записываются единица для обычных указателей и нуль для указателей нитей. Преимущество прошитых деревьев перед обычными бинарными деревьями заключается не только в более эффективном использовании памяти, но и в том , что алгоритмы обхода такого дерева не требуют стека для реализации возврата.
16. Они представляют попытку объединить выгоды от АВЛ-дерева с простым случайным двоичным деревом поиска. Дерево расширений не хранит значение высоты; вместо этого каждый раз, когда мы имеем доступ к узлу, мы перемещаем этот узел к корню, используя АВЛ-вращения. Практически это приводит к хорошо сбалансированным деревьям с быстрым временем доступа. Фактически средняя сложность алгоритма - O(lоg n). Редактирование: узлы, к которым часто обращаются, будут очень близко к корню. Алгоритм формирования и редактирования деревьев расширений состоит в том, что вначале выполняются операции над деревом как над обычным бинарным деревом, а затем рассматриваемый узел с помощью соответствующих последовательных вращений перемещается в корень дерева. Процедуры левого и правого вращений аналогичны вращениям, применяемым в АВЛ-деревьях и в красно-черных деревьях. Отличие состоит в том, как применяются эти вращения.
17. Алгоритм Хаффмана. 1) сортируем все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте; 2) последовательно объединяем 2 символа с наименьшими вероятностями появления; 3) Прослеживаем путь к каждому месту, помечаем направление (налево-«0», направо-«1»), получаем код Хаффмана. Альтернативы коду Хаффмана является коды Фано-Шеннона. Сообщение ABACCDA, коды: A - 0 (частота 3), B - 110 (частота 1), C - 10 (частота 2), D - 111 (частота 1). Тогда наше сообщение закодируется как 0110010101110 (13 бит).
18. Алгоритм Фано-Шеннона. 1) Сортируем символы в порядке возрастания появления их тексте; 2) Делим множество символов на 2 подмножества, так, чтобы сумма вероятностей появления символов одного подмножества = сумме вероятностей появления другого подмножества; 3) Для правого подмножества приписываем «1», для левого-«0»; 4) Разбиение продолжается до тех пор, пока подмножество не будет состоять из одного элемента.
19. К-Ч Д - это бинарное дерево со следующими свойствами: 1. каждый узел покрашен либо в черный, либо в красный цвет. 2. листьями объявляются NIL-узлы (т.е. "виртуальные" узлы, наследники узлов, которые обычно называют листьями; на них "указывают" NULL указатели). Листья покрашены в черный цвет. 3. Если узел красный, то оба его потомка черны. 4. На всех ветвях дерева, ведущих от его корня к листьям, число черных узлов одинаково. Количество черных узлов на ветви от корня до листа наз-ся черной высотой дерева. Перечисленные свойства гарантируют, что самая длинная ветвь от корня к листу не более чем вдвое длиннее любой другой ветви от корня к листу. Вставка: Новый узел всегда добавляется как лист, поэтому оба его потомка являются NIL-узлами и предполагаются черными. После вставки красим узел в красный цвет. После этого смотрим на предка и проверяем, не нарушается ли красно-черное свойство. Если необходимо, мы перекрашиваем узел и производим поворот, чтобы сбалансировать дерево. Если предок нового узла красный возм. 2 случ.: 1) красный предок, красный дядя(перекрашиваем предка и дядю, дед-если черн.=> красный, корень - черн.); 2) красн. предок, черн. дядя(вращения для корректировки, в этом месте алгоритм может остановиться из-за отсутствия красно-красных конфликтов и вершина дерева окрашивается в черный цвет, если новый узел вначале был правым потомком, то первым примениться левое вращение, к-рое делает этот узел левым).
20. Упорядоченные деревья, имеющие степень не менее 3, называются сильно ветвящимися деревьями. Если считать, что степень некоторого узла равна n, то он должен содержать n-1 ключей и п указателей.
![]()
Св-ва: 1)Степень может меняться в зависимости от узла. Если все узлы имеют одинаковую степень n, структура называется n-арным деревом. 2) Ключ вышерасположенного узла может совпадать с ключом нижерасположенного узла (например, с наибольшим). Сложность (n+1)lognN. Сильно ветвящиеся деревья очень удобны для поиска во внешней памяти.
21. В-деревом порядка п называется сильно ветвящееся дерево степени 2n+1, обладающее след. св-ми: 1) каждый узел, за исключением корня, содержит не менее п и не более 2n ключей; 2) корень содержит не менее одного и не более 2п ключей; 3) все листья расположены на одном уровне. Те узлы, которые не ссылаются на другие узлы дерева, называются листьями; 4) каждый нелистовой узел содержит число указателей на единицу больше числа ключей; 5) каждый нелистовой узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответствующий ему список указателей (для листовых узлов список указателей отсутствует). Вставка: 1) убедиться в том, что аргумент поиска не совпадает ни с одним из уже имеющихся в дереве ключей(необходимо (начиная с корня) последовательно просматривать узлы дерева, пока не будет достигнут соответствующий лист (неудачный поиск всегда заканчивается в листовом узле)). 2) если лист заполнен не полностью, произвести вставку аргумента в соответствующее место списка ключей и на этом завершить операцию вставки. 3) если в этом листе свободного места нет, то в результате вставки число ключей станет равным 2n+1 и возникнет ситуация переполнения((n + 1)-й ключ/средний ключ удалить из узла; создать новый узел (лист) и переместить в него n ключей списка из узла, в котором возникло переполнение; удаленный ключ вставить в узел-корень переполненного узла, т.е. при переполнении происходит расщепление узла: образуются два новых вместо одного старого и ключ переноса.). 4) если в результате вставки ключа переноса внутренний узел окажется переполненным, он тоже расщепляется (при этом половина списка ключей и списка указателей помешается в новый узел). 5) если ключ переноса достигнет корня и корень после вставки также окажется переполненным, его тоже расщепляют, что приводит к увеличению высоты дерева на единицу и созданию нового корня, куда и помещается ключ переноса. Получившиеся в результате расщепления два узла становятся корнями поддеревьев нового корня.
22. В+ - В, в к-ром истинные значения ключей содержатся только в листьях (концевых узлах). Во внутренних узлах - ключи - разделители, задающие диапазон изменения ключей для поддеревьев. Во многих случаях они совпадают с истинными значениями ключей или их частью, но это вовсе не обязательно. Поскольку все ключи расположены на одном уровне - в листьях, если связать их указателями, то последовательный доступ станет особенно прост при высокой скорости доступа по дереву. При расщеплении листа в результате вставки ключ из листа не удаляется, а в качестве ключа переноса используется его копия. Операция удаления из В+ имеет то преимущество, что удаление всегда производится из листа. Необх-ть в Δ ключа-разделителя возникает только в случае нехватки, когда потребуются перестановка ключей и установление новых связей при балансировке. Все другие операции, помимо рассмотренных выше, выполняются аналогично операциям над В. Таким образом, В+ во многом превосходят В, ступают же они В в том, что требуют несколько больше памяти для представления.
В++ отлич. от В+ расщеплением, объединением. Все ключи в листьях объединяются, а затем почти поровну делятся между листьями.
В* для В - каждый узел должен быть заполнен ключами не < чем на 0.5 для В* - требуется, чтобы каждый узел был заполнен ключами не < чем на 2/3.
Использование: словари, б. д., виртуальная память.
23. Многомерный объект может представлять собой: – некоторую точку в пространстве; – сложный, сос-ий из тысяч полигонов / мн-ва атрибутов объект. Св-ва стр-р: комплексность, динамичность, адаптация к большим размерам, поддержка нестандартных операций, независимость стр-ры индекса от последоват. построения, расшир-ть, произв-ть, пространст. эффек-ть. Применение: ГИС, компьютерная графика, медицина.
24. Методы доступа: Точечные Методы Доступа –ТМД(Point Access Methods – PAM); Пространственные Методы Доступа – ПМД(Spatial Access Methods – SAM); Пространственно-Временных Методов Доступа – ПВМД(Spatio-Temporal Access Methods – STAM); Метрические Методы Доступа – ММД(Metric Access Methods – MAM). Виды запросов: поиск по точному совпадению (Exact Match Query); поиск объекта, содержащего точку (Point Query); поиск по области (Range Query); поиск покрывающих объектов (Overlap Query); поиск вмещающего объекта (Enclosure Query); поиск вхождений (Containment Query); поиск соседей (Adjacency Query); поиск ближайшего соседа (Nearest Neighbor Query); запрос всех пар элементов, удовлетворяющих условию (Spatial Join). Расстояние м/у многомерными объек.: расст. м/у объектами в пространстве признаков наз-сяся такая величина Dist(P,P′), к-рая удовлетворяет след. аксиомам:
– Dist(P,P′) > 0 – неотрицат. расстояние; – Dist(P,P′) = Dist(P′,P) – симметрия; – Dist(P,P″) + Dist(P″,P′) > Dist(P,P′) – неравенство треугольника; – если Dist(P,P′) ≠ 0, то P ≠ P′ – различимость нетождественных объектов.
25. Представление MBR: – сохраняются координаты двух угловых точек прямоугольника, расположенных на главной диагонали; – в вершине дерева хранятся корд. верхней левой точки и инфа о размере прямоугольника по всем измерениям (длина и ширина); – в вершине дерева размещается корд. геометрического центра прямоугольника (пересеч. диаг.) и инфа о размерах прямоугольника по всем измерениям, поделенная пополам. MBR для группы объектов: иногда в один описывающий прямоугольник помещают не один объект, а целую группу близко расположенных к друг другу объектов. Технология вычисления MBR для группы объектов принципиально ничем не отличается. MBR для групп объектов: минимальную описывающую область формируют путем указания центра этой области и расстояния, на котором должны находиться объекты. Все объекты, попавшие в эту область, объединяются в один элемент (узел или поддерево). Для таких MBR специально разработаны алгоритмы, значительно увеличивающие скорость поиска ближайших соседей в многомерном пространстве. Среди стр-р, оперирующих такими MBR: SS- и SR-деревья.
26. В большинстве иерархических методов доступа предусмотрено объединение рядом находящихся точек в одну общую область. Точки такой области сохраняются в одной дисковой странице, на которую ссылается некоторый лист дерева. Внутренние узлы дерева (индексные узлы) предназначены только для разбиения пространства на подпространства и соответственно уменьшения области поиска. Причем вся область разбивается рекурсивно от корня к листу.
K-D дерево в K измерениях, в зависимости от размерности представляемого пространства имеет вид: 1-d-дерево (в одномерном пространстве) - обычное бинарное дерево поиска; 2-d-дерево (двухмерное дерево, напр., для представления объектов на плоскости), но ветвление в узлах происходит уже по двум направлениям (напр., на нечетных уровнях ветвление происходит по координате x, а на четных – y). В общем случае K-D имеет узлы с k корд., и ветвление на каждом уровне баз-ся на сравнении одной из координат. Разновидности: адаптивные K-D; Bibtree; BSP; LSD и hB. Применение: пространственная индексация, определение скрытых поверхностей, метод быстрого многополюсника, трассировка лучей, квантование цвета.
27. Quad-дерево предназначено для индексирования и поиска данных в оперативной памяти. В настоящее время разработано большое множество различных вариантов Quad, позволяющих использовать данную структуру не только для хранения точечных объектов, но и пространственных областей, графических данных с разной точностью детализации, сложных форм и изменяющихся во времени объектов. Разновидности: оптимальное точечное Quad-дерево, Quad-деревья областей (Region Quad-tree), MX Quad-дерево (MX Quad-tree), PR Quad-дерево (PR Quad-tree), Псевдо Quad-дерево (pseudo Quad-tree). Применение: кодирование изображений.
28. LSD-дерево(Local Split Decision tree). В нем отражена мысль, что пространство в каждой вершине дерева делится локально, независимо от остального дерева, причем деление это бинарное. LSD-дерево можно считать адаптивным K-D, приспособленным для внешней памяти. Оно содержит в себе механизмы выгрузки части узлов во внешнюю память.
29. Классификация методов многомерного хеширования: Схемы хеширования с каталогом – функция хеширования использует дополнительные данные, сохраненные на диске (Файл-решетка, EXCELL). Схемы хеширования без каталога – функция хеширования основана только на математических вычислениях, без использования дополнительных данных (MOLHPE, PLOP). Файл-решетка Основной принцип – решеточное деление пространства. Принципы файла-решётки: Принцип двух дисковых запросов. Запрос на точное совпадение по всем ключам должен вернуть запись или флаг ее отсутствия в индексе за два обращения к внешней памяти. Эффективные диапазонные запросы. Структура данных должна сохранять порядок, определенный для каждого ключевого диапазона (записи, имеющие близкие значения какого-либо ключа, должны располагаться в близких участках памяти). Пример каталога файла-решётки:
Шкалы: [x0,
x1,
x2] [y0,
y1,
y2]![]()
Массив решетки:
![]()
Алгоритмы файла-решётки: поиск по точному совпадению, поиск по области (диапазонный запрос), добавление объекта, расщепление внешнего блока, расщепление решетки, удаление объекта. Структура каталога файла-решётки: k одномерных массивов, называемых линейными шкалами по осям. Задача этих массивов заключается в хранении координат плоскостей, которые разбивают пространство на решетку. k-мерный массив сопоставления ячеек решетки и блоков внешней памяти, называемый массивом решетки. Двухуровневый файл-решётка
![]()
Двойной файл-решётка
![]()
30. EXCELL. Ключевым отличием файлов-решеток от EXCELL является то, что при переполнении некоторой ячейки в первых происходит деление только одного интервала на две части (вставка одного значения в линейную шкалу и добавление одного столбца или строки в массив решетки), в то время как в EXCELL происходит деление всех интервалов по соответствующему направлению и удвоение директории. Недостатки: размер каталога растет сверхлинейно по отношению к росту хранимых данных даже при равномерном распределении данных; если же данные распределяются неравномерно, то во многих вариантах файлов-решеток рост размера каталога может стать экспоненциальным.
MOLHPE – многомерное линейное хеширование с частичными расширениями (Multidimensional Orderpreserving Linear Hashing with Partial Expansions). MOLHPE была предложена в 1986 году Г. Крейгилом и Б. Сигиром. Одна из первых схем хеширования без каталога. Принципы MOLHPE: в общих чертах хеширование MOLHPE похоже на файлы-решетки: все пространство поиска разбивается некоторой решеткой на ячейки; с каждой ячейкой связывается некоторый внешний блок, в котором и сохраняются все объекты, попавшие в эту ячейку. Однако алгоритмы, выполняющие эти действия, отличаются от рассмотренных ранее. Главное отличие – стр-ра ф-ции хеширования, к-рая не использует шкал и массива решетки. Вместо этого все вычисления производятся с помощью специальных математ. ф-ций. Алгоритмы MOLHPE: поиск, добавление объекта, расширение, удаление объекта. Замена массива решетки в MOLHPE. Индексы подставляют в некоторую функцию заполнения пространства G, которая и возвращает номер внешнего блока. Таким образом, вместо массива-решетки используется математическая функция G. Замена линейных шкал в MOLHPE. Вместо линейных шкал для вычисления положение ячейки используют функцию Hi – линейное хеширования для i-го измерения.
О![]() бъект
поиска:
бъект
поиска:
O = (K0, K1)
Определение индекса в решетке:
l0 = H0(K0)
l1 = H1(K1)
К![]() оллизии
в MOLHPE. В
файле решетки при коллизии (переполнении)
происходило изменение (расщепление)
решетки. Таким образом модифицировалась
функция хеширования и обрабатывались
коллизии. В MOLHPE используется принцип
цепочек для обработки коллизий.
оллизии
в MOLHPE. В
файле решетки при коллизии (переполнении)
происходило изменение (расщепление)
решетки. Таким образом модифицировалась
функция хеширования и обрабатывались
коллизии. В MOLHPE используется принцип
цепочек для обработки коллизий.
P![]() LOP
– Piecewise Order Preserving hashing. Разработан
в 1988 г. Г. Кригелом и Б. Сигером. Является
синтезом файл-решеток и MOLHPE. Авторы
попытались устранить недостатки обоих
схем.
LOP
– Piecewise Order Preserving hashing. Разработан
в 1988 г. Г. Кригелом и Б. Сигером. Является
синтезом файл-решеток и MOLHPE. Авторы
попытались устранить недостатки обоих
схем.
Адресная функция PLOP. Точно такая же, как и у MOLHPE. В адресную функцию подставляются индексы, полученные из иерархических шкал.
31. Граф - совокупность точек и линий, в которой каждая линия соединяет две точки. Точки называются вершинами, или узлами, графа, линии - ребрами графа. Если ребро соединят две вершины, то говорят, что оно им инцидентно; вершины, соединенные ребром называются смежными. Две вершины, соединенные ребром, могут совпадать; такое ребро называется петлей. Число ребер, инцидентных вершине, называется степенью вершины. Если два ребра инцидентны одной и той же паре вершин, они называются кратными; граф, содержащий кратные ребра, наз-ся мультиграфом. Ребро, соединяющее две вершины, может иметь направление от одной вершины к другой; в этом случае оно наз-ся направленным, или ориентированным, и изображается стрелкой. Граф, в котором все ребра ориентир-ные, наз-ся ориентированным графом (орграфом); ребра орграфа часто называют дугами. Дуги именуются кратными, если они не только имеют общие вершины, но и совпадают по направлению. Иногда нужно рассматривать не весь граф, а его часть (часть вершин и часть ребер). Часть вершин и все инцидентные им ребраназываются подграфом; все вершины и часть инцидентных им ребер называются суграфом. Циклом называется замкнутая цепь вершин. Деревом называется граф без циклов. Остовным деревом называется связанный суграф графа, не имеющий циклов. Для неориентированного ребра порядок, в котором указанны соединяемые им вершины, не важен. Для ориентированного ребра важно: первой указывается вершина, из которой выходит ребро. Маршрут, или путь - это послед-ть ребер в неориентированном графе, в котором конец каждого ребра совпадает с началом следующего ребра. Число ребер маршрута называется его длинной.
Поиск в ширину. По анологии с принципом Гюйгенса(каждая посещенная вершина становится источником новой волны). Для реализации: 1) матрица m[1..n, 1..n] - матрица смежности графа; 2) вспомогательный массив queue[1..n], в котором будет формироваться очередь, т.е. тип данных первый вошел – первый вышел (FIFO). Размер его достаточен, так как мы не посещаем вершины дважды. С массивом queue связаны; 3) две переменные - head и tail. В переменной head будет находиться номер текущей вершины, из которой идет волна, а при помощи переменной tail новые вершины помещаются в "хвост" очереди queue; 4) вспомогательный массив visited[1..n], который нужен для того, чтобы отмечать уже пройденные вершины (visited[i]=TRUE <=> вершина i пройдена); 5) вспомогательный массив prev[1..n] для хранения пройденных вершин. В этом массиве и будет сформирован искомый путь; 6) переменная f, которая примет значение TRUE, когда путь будет найден. Кроме того, введутся несколько вспомогательных переменных, при организации циклов.
Поиск в глубину. Идея поиска в глубину проста: отправляясь от текущей вершины, мы находим новую (еще не пройденную) смежную с ней вершину, которую помечаем как пройденную и объявляем текущей. После этого процесс возобновляется. Если новой смежной вершины нет (тупик), возвращаемся к той вершине, из которой попали в текущую, и делаем следующую попытку. Если попадем в вершину B, печатаем путь. Если все вершины исчерпаны - такого пути нет. Для реализации: 1) матрица m[1..n, 1..n] - матрица смежности графа; 2) вспомогательный массив visited[1..n], который мы будем для того, чтобы отмечать уже пройденные вершины (visited[i]=TRUE <=> вершина i пройдена); 3) переменная f, которая примет значение TRUE, когда путь будет найден.
Эйлеровы циклы. Требуется найти цикл, проходящий по каждой дуге ровно один раз. Условия для существования в графе эйлерова цикла: во-первых, граф должен быть связанным: для любых двух вершин должен существовать путь, их соединяющий; во-вторых, для неориентированных графов число ребер в каждой вершине должно быть четным. На самом деле этого оказывается достаточно. Теорема: Чтобы в связанном графе существовал эйлеров цикл, необходимо и достаточно, чтобы число ребер в каждой вершине было четным.
Задача Прима-Краскала. Дана плоская страна и в ней n городов. Нужно соединить все города телефонной связью так, чтобы общая длинна телефонных линий была минимальной. Или в терминах теории графов: Дан граф с n вершинами; длины ребер заданы матрицей. Найти остовное дерево минимальной длины. В задаче Прима–Краскала, которая не кажется особенно простой, жадный алгоритм дает точное оптимальное решение. Древо с n вершинами имеет n-1 ребер. Оказывается, каждое ребро нужно выбирать жадно (лишь бы не возникали циклы). То есть n-1 раз выбирать самое короткое ребро из еще не выбранное ребро при условии, что оно не образует цикла с уже выбранными. До построения дерева каждая вершина i окрашивается в отличный от других цвет i. При выборе очередного ребра, например (i, j), где i и j имеют разные цвета, вершина j и все, окрашенные в ее цвет (т.е. ранее с ней соединенные) перекрашиваются в цвет i. Таким образом, выбор вершин разного цвета обеспечивает отсутствие циклов. После выбора n-1 ребер все вершины получают один цвет. Теорема: Алгоритм Прима–Краскала получает минимальное остовное дерево.
Алгоритм Дейкстры. Задача: дана дорожная сеть, где города и развилки будут вершинами, а дороги – ребрами. Требуется найти кратчайший путь между двумя вершинами. С точки зрения графов: в ориентированной, неориентированной или смешанной сети найти кратчайший путь из заданной вершины во все остальные вершины. Для реализации: 1) массив Visited содержит метки с двумя значениями: False (вершина еще не рассмотрена) и True (вершина уже рассмотрена); 2) массив Len содержит расстояния: текущие кратчайшие расстояния от начальной до соответствующей вершины; 3) массив C содержит номера вершин – k-ый элемент C есть номер предпоследней вершины на текущем кратчайшем пути из начальной вершины в k-ю; 4) Matrix – матрица расстояний. Алгоритм:
1 (инициал.). В цикле от 1 до n заполнить значением False массив Visited; заполнить числом i массив C (i–номер стартовой вершины); перенести i-ю строку матрицы Matrix в массив Len; Visited[i]:=True; C[i]:=0;
2 (общий шаг). Найти минимум среди неотмеченных (т.е. тех к, для которых Visitid[k]=False); пусть минимум достигается на индексе j, т.е. Len[j] Len[k]; Затем выполнять следующие операции: Visited[i]:=True;
если Len[k] > Len[j] + Matrix[j, k], то (Len[k]:=Len[j]+Matrix[j, k]; C[k]:=j) {Если все Visited[k] отмечены, то длина пути от vi до vk равна C[k]. Теперь надо перечислить вершины, входящие в кратчайший путь}.
3 (выдача ответа). {Путь от vi до vk выдается в обратном порядке следующей процедурой:}
3.1 z:=C[k];
3.2 Выдать z
3.3 z:=C[z]. Если z =0, то конец,
иначе перейти к 3.2.
Теорема: Алгоритм Дейкстры – корректен.
3![]() 2.
Граф, содержащий только ребра, называется
неориентированным; граф, содержащий
только дуги, - ориентированным или
орграфом. Вершины, соединенные ребром,
называются смежными. Ребра, имеющие
общую вершину, также называются смежными.
Ребро и любая из его двух вершин называются
инцидентными. Каждый граф можно
представить на плоскости множеством
точек, соответствующих вершинам, которые
соединены линиями, соответствующими
ребрам. В трехмерном пространстве любой
граф можно представить, таким образом,
что линии (ребра) не будут пересекаться.
При решении задач используются следующие
четыре основных способа описания графа:
матрица инциденций; матрица смежности:
списки связи и перечни ребер. Матрица
инциденции - это двумерный массив
размерности N×M.
2.
Граф, содержащий только ребра, называется
неориентированным; граф, содержащий
только дуги, - ориентированным или
орграфом. Вершины, соединенные ребром,
называются смежными. Ребра, имеющие
общую вершину, также называются смежными.
Ребро и любая из его двух вершин называются
инцидентными. Каждый граф можно
представить на плоскости множеством
точек, соответствующих вершинам, которые
соединены линиями, соответствующими
ребрам. В трехмерном пространстве любой
граф можно представить, таким образом,
что линии (ребра) не будут пересекаться.
При решении задач используются следующие
четыре основных способа описания графа:
матрица инциденций; матрица смежности:
списки связи и перечни ребер. Матрица
инциденции - это двумерный массив
размерности N×M.
вершина с номером i инцидента ребру с номером j
вершина с номером i не инцидентна ребру с номером j
Н едостатки
матрицы инцидентности:
матрица прямоугольная, трудно
редактировать. Плюсы:
запись в матричной форме, сразу можно
найти связи, можно сразу работать с
ориентированными графами. Такие матрицы
применяются редко.
едостатки
матрицы инцидентности:
матрица прямоугольная, трудно
редактировать. Плюсы:
запись в матричной форме, сразу можно
найти связи, можно сразу работать с
ориентированными графами. Такие матрицы
применяются редко.

М атрица смежности - это двумерный массив размерности N×N.
если вершины с номерами i и j смежны
в ершины
с номерами i и j не смежны
ершины
с номерами i и j не смежны
Число элементов в i- ой строке, значение которых 1, равно полустепени исхода вершин Vi . Аналогично, число элементов равных 1 в j-ом столбце равно полустепени захода вершин Vj. Матрица смежности полностью определяет орграф. Недостатки: много нулевых элементов. Плюсы: очень легко реализуются операции над графами.
33. Суть: выбирается самое дешевое ребро, затем к нему добавляется самое дешевое из оставшихся и т.д. При этом окончательная подсеть должна содержать: все вершины; должна быть связанной; не должна содержать циклов; иметь min возможный вес.
∞ |
11 |
9 |
7 |
8 |
11 |
∞ |
15 |
14 |
13 |
9 |
15 |
∞ |
12 |
14 |
7 |
14 |
12 |
∞ |
6 |
8 |
13 |
14 |
6 |
∞ |


34. Идея метода. Поиск начинается с некоторой фиксированной вершины v. Просматриваются все вершины связанные с ним, и если такая существует, рекурсивно продолжаем поиск, начиная с нее. Если же не существует, то мы возвращаемся назад, чтобы найти новый поиск вершины. Поиск продолжается до тех пор, пока мы рекурсивно не вернемся в исходную точку. Сложность: О(n+m), n- количество вершин, m-количество ребер. Для уверенности в том, что поиск не зацикливается, необходимо предусматривать остановку на определенной глубине. Рекомендуется начинать поиск с глубины равную расстоянию по прямой от старта до цели. Он является оптимальным и по времени и по памяти. В больших задачах целесообразно применять алгоритм последовательных приближений, т.е. найти путь до какой-то промежуточной точки, затем найти путь от промежуточной точки до цели.
![]()
35. Является алгоритмом для поиска остовного дерева. Суть (в сжатой формулировке) заключается в том, чтобы paccмотреть все вершины, связанные с текущей. Принцип выбора следующей вершины - выбирается та, которая была раньше рассмотрена. Для реализации данного принципа необходима структура данных "очередь". Пример:


Граф и его описание
Вычислит. сложность поиска в ширину имеет порядок т+n, каждая вершина помещается в очередь и удаляется из очереди один раз.
Имеется проблема: поиск идет равномерно во всех направлениях, вместо того, чтобы быть направленным в сторону цели.
Улучшения: двунаправленный поиск в ширину.
запускаются два одновременных поиска в ширину из стартового и конечного узлов и останавливается, когда узел из одного фронта поиска находит соседний узел из другого фронта. Улучшает простой поиск в ширину (обычно в 2 раза).
36. 1. Выбираем некоторую вершину, остальные n-1 вершины отмечаются как невыбранные.
2. Определяем вес между выбранной вершиной и остальными невыбранными вершинами.
3. Выбирают вершину с наименьшим весом для нее и фиксируют выбранное ребро и вес.
4. Выбранную вершину исключаем из перечня невыбранных, число невыбранных вершин уменьшаем на 1.
1-4 повторяем до тех пор, пока не будут выбраны все вершины, n-1 раз.

![]()

37. Не требует прохода по всем вершинам для нахождения ребра min веса.
1. Начать с полностью несвязного графа из n вершин.
2. Упорядочить ребра графа в порядке возрастания их весов.
3. Начав с 1 ребра в этом перечне, добавлять ребра, соблюдая условие: добавление
не должно приводить к появлению циклов.
4. Повторять 3 пункт до тех пор, пока число ребер не станет равным n-1.

38. Формулировка задачи: определить максимальный поток, протекающий от некоторой вершины S графа (источника) к некоторой вершине T (стоку). При этом каждой дуге (граф ориентированный) (i,j) приписана некоторая пропускная способность С(i,j), определяющая максимальное значение потока, который может протекать по данной дуге.
Области приложения потоковых алгоритмов:
комбинаторные задачи:
о допустимых назначениях на должности (иначе, о представителях подмножеств);
о назначениях на должности с максимальной суммарной эффективностью;
о назначениях, оптимальных по минимаксу;
о минимальных множествах ребер или вершин сети, удаление которых нарушает ее связность.
каноническая область приложений:
задачи о потоках в сетях (электрических, гидравлических и т.д.);
составлении расписаний;
нахождении оптимальных планов перевозок.
Разрез - множество дуг, удаление кот. из сети приводит к "разрыву" всех путей, ведущих из s в t. Пропуск. способность разреза - это суммарная пропускная способность дуг, его составляющих.
Мин.разрез - с мин. пропускной способностью.
Теорема (Форд и Фалкерсон). Величина каждого потока из s в t не превосходит пропускной способности минимального разреза, разделяющего s и t, причем существует поток, достигающий этого значения.
Грубый подход определения макс. Потока:
генерация всех возможных подмножеств дуг;
для каждого подмножества дуг проверяем, является ли оно разрезом.
если является, то вычисляем его пропускную способность и сравниваем ее с минимальным значением.
при положительном результате сравнения запоминаем разрез и изменяем значение минимума.
39. Суть алгоритма- последовательное (итерационное) построение макс. потока путем поиска на каждом шаге пути (последовательности дуг), поток по которому можно увеличить. При этом узлы (вершины графа) специальным образом помечаются. Базируется на "Технике меток" Форда и Фалкерсона:
На каждой итерации вершина сети может находиться в одном из трёх состояний:
1.вершина не имеет метки 2. вершине присвоена метка и она не просмотрена (не все смежные вершины обработаны) 3. вершине присвоена метка и она просмотрена
На каждой итерации мы выбираем помеченные, но не просмотренные вершины и ищем вершину смежную с ней, которую можно пометить.
Помеченные вершины образуют множество вершин в сети, достиж. из вершины источника. Если среди этих вершин окажется вершина сток, то это означает успешный результат поиска, который позволяет увеличить поток. Если поток нельзя увеличить, то процесс прекращается.
40. Сортировка – процесс целенаправленного перемещения элементов заданной конечной послед-ти, результатом которой является послед-ть, в кот. элементы расположены в порядке возраст. (или убывания) их значений.
Сортировка устойчива, если записи с одинаковыми ключами остаются в прежнем порядке.
Факторы, влияющие на производ-ть (параметры сорт-ки): 1) Число и размер сортируемой записи.
2) Тип и размер ключа. 3) Характер исходной упорядоченности – почти отсортированная последовательность, почти отсортированная наоборот, случайная последовательность. 4)Повторяемость значения ключа. 5) Используемые размеры памяти.
1.Время выполнения (T), характеризует скорость сортировки. 2. Количество сравнений ключей (C) и количество перестановок элементов(P). 3. Использование памяти в процессе сортировки (M). 4. Использование рекурсии(R). Большинство классических сортировок имеют временные затраты, которые варьируются от 0(nlogn) до 0(n2).
Классификация:
1) Внутренняя (сортируемые записи находятся в оперативной памяти):
а)сортировка вставками: простые вставки, бинарные и двухпутевые вставки, вставки в список, сортировка с вычислением адреса
б) обменная сорт.: метод пузырька, параллельная сорт. Бетчера, быстрая сорт., обменная поразрядная
сорт. в) сорт. выбором, простой выбор, выбор из дерева, пирамидальная сорт. г) Сортировки подсчетом (Каждый элемент сравнивается со всеми остальными; окончательное положение элемента определяется подсчетом числа меньших ключей)
2) Внешняя (некот. из сорт. записей находятся во вспомогательной памяти.): алг-тм сорт. выбора, многофазное слияние, каскадное слияние, осциллирующие сорт., внешняя поразрядная сорт…. См. 49
41. Простые вставки (n2/4): исходный массив разбивается на две части: A[1], A[2], ..., A[k-1] - отсортированную часть, A[k], ...,A[n] - не отсортированную часть. На k - м шаге элемент A[k] включается в отсортированную часть, на соответствующее место. При этом часть элементов, больших A[k], (если таковые есть) сдвигаются на одну позицию правее, чтобы освободить место для элемента A[k]. Прежде чем производить сдвиг элементов A[k] сохр. во временной переменной. Поиск подходящ. места для очередного элемента входной послед-ти осущ-ся путем послед-х сравнений с элементом, стоящим перед ним. В завис-ти от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется. В процессе вставки мы "просеиваем" элемент x к началу массива, останавливаясь в случае, когда
1. Hайден элемент, меньший x. 2. Достигнуто начало последовательности.
Бинарные вставки: при поиске места, на которое надо вставить элемент ai в уже упорядоченную совокупность a0 , ..., ai-1 , определяется алгоритмом деления пополам Недостаток – много времени на смещение элементов. Сложность – O(n*log n).
Двухп. вставки –1-ый элемент вставляется в середину послед-ти, а место для последующих элементов освобождается при помощи сдвига влево или вправо.
Вставки в список: находится мин элемент (сорт. только указатели) и вставляется в начало.
Дост.: чтобы вставить k-ый элемент организуем прохождение списка до тех пор, пока не будет найдена нужная позиция для k-го элемента или конец списка; вставка осуществляется переадресацией, без сдвига эл-тов послед-ти. Это уменьшает время вставки, но не время поиска. Недостаток – доп. память для указателей.
42. Пузырек: состоит в проходе снизу вверх по массиву. По пути просматр. пары соседних элементов. Если элементы некот. пары находятся в неправ. порядке, то меняем их местами. После нулевого прохода по массиву "вверху" оказывается самый "легкий". Просмотр
до тех пор, пока перестановок больше нет.
Улучшения: 1) Т.к. все эл-ты в позициях >=(n-i+1) уже на своих местах, нет надобности их сравнивать. О(1/2*n2). 2) Черед-е в прямом и обратном направ. (Шейкер-сорт) 3) Для исключения ненужных просмотров (послед-ть уже отсортирована) надо сохранять инфу об
обмене, в случае отсутствия обмена – сорт-ка прекращается.
Быстрая сорт-ка: эффективна для больших послед-тей. Цель каждого шага – помещение очередного элемента на его конечную позицию внутри последовательности. В результате все предшествующие эл-ты будут иметь меньшие значения, а последующие – большие. В результате последовательность делится на 2 части относительно значения первого эл-та, который в данном алгоритме становиться медианой. Аналогичный процесс применяется к каждой из этих частей (рекурсивно), пока все эл-ты не встанут на свои места.
43. Сорт. Шелла. Исходная последовательность разбивается на части. Каждая часть сортируется отдельно (обычно при помощи метода простых вставок). Количество частей k называется шагом. Затем выбирается меньший шаг и алгоритм повторяется. Обычно количество частей должно быть взаимно простыми числами. Последняя сортировка выполняется с шагом 1. Несмотря на большое число циклов, суммарное число перестановок будет меньше. Преимущество достигается за счет того, что части представляют из себя почти упорядоченные последовательности, и в этом случае эффективен алгоритм простых вставок. Сложность – O(n*(log n)*(logn)).
Сорт с вычислением адреса. Связанная последовательность разбивается на части в соответствии с функцией хеширования. В каждую часть включаются элементы меньшие или равные элементам другой части. При этом помещаемые
элементы каждой части сортируются (методом вставки). После этого все части соединяются в 1 послед-ть. Тратится время на выбор ф-ции хеширования и разбиение послед-ти в соответствии с ней. Требуется память для указателей. Сложность:O(n) – в лучшем случае, O(n*n) – в худшем случае.
44. Обменная поразрядная сорт. Идея – двоичное представление ключей и сравнение отдельных битов. 1)Послед-ть сортируется по старшему значащему биту так, чтобы все ключи начинающиеся с 0, оказались перед всеми ключами, начинающимися с 1. Для этого надо найти самый левый ключ k[i], начинающийся с 1, и самый правый k[j], начинающийся с 0. После этого i и j элементы меняются местами, и процесс повторяется, пока i не станет больше j.
До сортировки необходимо знать два параметра: k и m, где k - количество разрядов в самом длинном ключе, а m - разрядность данных: количество возможных значений разряда ключа.
Схема сортировки Бэтчера напоминает сортировку Шелла, но сравнения выполняются по-новому, так что распростр-е обменов не обязательно. Так как в алгоритме Бэтчера, происходит слияние пар отсорт. подпослед-ей, то его можно назвать “обменной сортировкой со слиянием”. Идея – происходит слияние пар отсортированной подпослед-ей. Проблема – как формировать эти пары.
45. Простой выбор. На каждом шаге из последовательности выбирается минимальный элемент и переносится в конец выходной последовательности. Характерным остается наличие двух независимых частей: упорядоченной и неупорядоченной. При исключении выбранного элемента из массива на его место может быть записано очень большое число. Выбранный элемент может удаляться путем сдвига остальной части. Минимальный элемент может меняться местами с очередным. Трудоемкость по количеству сравнений равна n*n/2.
Для нахождения наименьшего элемента из n+1 рассматримаемых алгоритм совершает n сравнений. С учетом того, что количество рассматриваемых на очередном шаге элементов уменьшается на единицу, общее количество операций:
n + (n-1) + (n-2) + (n-3) + ... + 1 = 1/2 * ( n2+n ) = O(n*n). Таким образом, так как число обменов всегда будет меньше числа сравнений, время сортировки растет квадратично относительно количества элементов. Алгоритм не использует дополнительной памяти: все операции происходят "на месте". Квадратичный выбор: разбиение последовательности на две части.
Выбор из дерева:
каждому первоначальному элементу приписывается некоторый узел (лист) в некотором бинарном дереве;
Затем выбираются два узла (листа). Наибольшее значение из них присваивается узлу – отцу. Этот процесс повторяется до тех пор пока не останется один лист или ни одного. Если остается один лист, то этот узел надо переместить вверх на следующий уровень.
Затем аналогичный процесс с заново созданными узлами надо повторить до тех пор, пока самое большое число не будет помещено в корень бинарного дерева.
Узел являющийся листом со значением корня заменяется минимальным числом. Содержимое всех предков до корня этого листа повторно вычисляется.
Этот процесс повторяется до тех пор, пока не будут выведены все листья первоначального дерева.
46. Куча это последовательность с определенными свойствами упорядоченности. Она похожа на дерево, но по свойствам существенно от него отличается. Если для двоичного дерева выполняется: ключ родителя больше или равен ключу левого сына и меньше или равен значению правого, то для двоичной кучи справедливо: ключ сына меньше или равен ключу родителя key[ parent[x] ] >= key[x]. Можно сделать вывод, что наибольшее число поддерева находится в его корне. Еще одно отличие двоичной кучи от дерева - поля left, right и parent не нужны. Они восстанавливаются однозначно по номеру вершины x: left[x] = 2*x; right[x] = 2*x + 1; parent[x] = x div 2;
Это означает, что куча занимает непрерывный участок памяти. Вершина, у которой нет родителя, называется корнем дерева (root). Для любой кучи это всегда элемент с номером 1. Для нее: parent[1] = 1 div 2 = 0, т.е. не существует. Но для того, чтобы понять, что вершина x - лист и случайно не ссылаться на не существующий элемент, введем понятие размер кучи - это количество вершин в ней.
Высотой вершины равна числу ребер в самом длинном пути от этой вершины к листу. Высота дерева равна высоте его корня.
Пирамидальная сортировка.
максимальный элемент массива теперь находится в корне дерева (A[1]). Его следует поменять с А[n], уменьшить размер кучи на 1 и восстановить основное свойство в корневой вершине (поскольку поддеревья с корнями left(i) и right(i) не утратили основного свойства кучи, это можно сделать с помощью процедуры savek). После этого в корне будет находиться максимальный из оставшихся элементов.
Так делается до тех пор, пока в куче не останется всего один элемент.
Время выполнения сортировки составляет O(n log n), т.к. первая часть (построение кучи) требует времени O(n), а каждое из (n−1) выполнений цикла for занимает O(logn).