

7. Язык программирования с – основные конструкции и особенности.
Структура программы на С:
команды препроцессора
описание типов
заголовки ф-ий
глобальные переменные
описание ф-ий.
Типы данных: char, int, unsignedint, long int, float, double, long double.
В Си все подпрограммы рассматриваются как функции.
Описание ф-ии:
<тип> <имя ф-ии> (<тип> <имя>, формальные параметры.)
{тело ф-ии}
Увеличение (положительное приращение) (++) и уменьшение (отрицательное приращение) (--) могут располагаться до и после имени переменной. Если оператор расположен до переменной, то она увеличивается (уменьшается), перед вычислением выражения; если после, то сначала вычисляется выражение, а затем изменяется значение.
. Основной командой является printf. Она имеет формат:
printf(<форматная строка>, <перем.>, <перем.>...); где <форматная строка> - это строка символов или символьная переменная, а <перем.> - переменная или выражение, которые выводятся в соответствии с командами форматирования, форматной строки. Для перехода на новую строку надо вставить символ \n в конец форматной строки.
Другие два оператора вывода Си - это puts и putchar. puts получает строку в качестве аргумента и выводит ее, автоматически добавляя символ перехода на новую строку.
Команда putсhar (вывести символ) - выводит всего один символ. Например: putchar(ch).
В Си присвоение (=) - оператор, который может использоваться в выражениях.
Ввод. В Турбо Си главная функция, используемая для ввода с клавиатуры - scanf имеет формат:
scanf (<форматная строка>, <адр1>, <адр2>,...);
где <форматная строка> - строка, содержащая опции форматирования, (аналогично printf), а каждый <адр> - адрес, по которому scanf размещает вводимые данные. Это значит, что необходимо будет использовать оператор адреса (&). Есть также другие общеиспользуемые команды: gets, которая читает входную строку до тех пор, пока вы не нажмете Ввод, и getch, которая читает символ прямо с клавиатуры.
В С вы должны ставить точку с запятой за последним оператором.
В Си имеются подпрограммы: только функции. Можно объявить функцию типа void, что позволит ей не возвращать никакого значения; можно также игнорировать значение, выдаваемое функцией.
В Си оператор return используется для возвращения значения функции.
В Си параметры передаются только по значению.
Массивы в Си могут иметь целый, символьный или перечислимый тип индексов, в то время как в Паскале используется любой перечислимый тип. Все области индексов начинаются от 0 и идут до n-1 (где n - размер массива). В Си массив индексируется согласно арифметике ссылок.
C |
A=выражение a=b=c=выражение |
If (<выражение>) <оператор>; [else<оператор>] If (a==b) |
{ } |
Switch ( ) { 1: ; break; 2: Default } |
While (выражение) { } |
Do { } while (выражение) |
For (в1; в2; в3) <оператор> |
8. Сравнительный анализ языков c и Pascal.
Соответствие типов.
PASCAL |
C |
Byte, shortint, Boolean, char |
Char |
Integer, word |
Int, unsigned int |
longint |
Long int |
real |
- |
Single, double, extended |
Float, double, long double |
Операторная часть языка.
PASCAL |
C |
a:= выражение |
A=выражение a=b=c=выражение |
If <логическое выражение> then <оператор> [else <оператор>] If a=b |
If (<выражение>) <оператор>; [else<оператор>] If (a==b) |
Begin end; |
{ } |
Case <имя> of 1: 2: Else end |
Switch ( ) { 1: ; break; 2: Default } |
While do |
While (выражение) { } |
Repeat Until |
Do { } while (выражение) |
Цикл for |
For (в1; в2; в3) <оператор> |
В ы в о д. Основные команды вывода Турбо Паскаля это - Write и Writeln. Турбо Си имеет множество команд, позволяющих выполнять точно то, что вы хотите. Основной командой является printf. Она имеет формат:
printf(<форматная строка>, <перем.>, <перем.>...);
где <форматная строка> - это строка символов или символьная переменная, а <перем.> - переменная или выражение, которые выводятся в соответствии с командами форматирования, форматной строки. Для перехода на новую строку (по аналогии с Writeln) надо вставить символ \n в конец форматной строки.
Другие два оператора вывода Си - это puts и putchar. puts получает строку в качестве аргумента и выводит ее, автоматически добавляя символ перехода на новую строку. Например, следующие команды эквивалентны:
Writeln(Name); puts(Name);
Writeln('Hi, there!');Writeln; puts("Hi, there!\n");
Команда putсhar (вывести символ) - выводит всего один символ. Например:
write(Ch); putchar(ch).
Основным отличием между этими двумя языками является использование операции присвоения. В Паскале, присвоение (:=) является оператором. В Си присвоение (=) - оператор, который может использоваться в выражениях.
Ввод. Опять же в Турбо Паскале имеется одна базовая команда ввода Read() с некоторыми вариантами (Readln(), Read(f), ...). В Турбо Си главная функция, используемая для ввода с клавиатуры - scanf имеет формат:
scanf (<форматная строка>, <адр1>, <адр2>,...);
где <форматная строка> - строка, содержащая опции форматирования, (аналогично printf), а каждый <адр> - адрес, по которому scanf размещает вводимые данные. Это значит, что необходимо будет использовать оператор адреса (&). Есть также другие общеиспользуемые команды: gets, которая читает входную строку до тех пор, пока вы не нажмете Ввод, и getch, которая читает символ прямо с клавиатуры.
В Паскале вы не должны ставить точку с запятой за последним оператором, а в Си должны. И в Паскале и Си имеются подпрограммы; Паскаль имеет процедуры и функции, в то время как Си имеет только функции. Однако, можно объявить функцию типа void, что позволит ей не возвращать никакого значения; можно также игнорировать значение, выдаваемое функцией.
В Си оператор return используется для возвращения значения функции, в то время как в Паскале это достигается присвоением значения имени функции.
B Паскале имеется 2 типа параметров:var (передача по адресу) и value (по значению). В Си параметры передаются только по значению.
Массивы в Си могут иметь целый, символьный или перечислимый тип индексов, в то время как в Паскале используется любой перечислимый тип. Все области индексов начинаются от 0 и идут до n-1 (где n - размер массива). Это сильно отличается от Паскаля, где вы устанавливаете границы индекса, как вам удобно. В Си массив индексируется согласно арифметике ссылок.
40.Сущность функционального программирования и языки, реализующие его. LISP-машина и ее организация.
Функциональное программирование - программа представляет собой набор описаний функций: функций-констант, системных ф-ий и ф-ий, определяемых пользователем.
Существенным плюсом функционального программирования является составление программ, в которых единственным действием является вызов ф-ий, а прог-ма разбивается на части введением имен ф-ий.
Первым функциональным языком был LISP. LISP не использовал фон-Неймановский принцип. Цель: организация удобства обработки символьной инф-ии. Особенности: все выражения в виде списков. Элементами списка являются атомы.
Точечная пара А.В реализуется в памяти в виде ссылочной конструкции (самая популярная конструкция - список):
|
|
-LISP-ячейка А В
Список: (А В С) А.(В.(С.NIL))
|
|
A
|
|
B
|
|
C NIL
Элементами списка могут быть разные конструкции.
Автовыполнение выражений.
/( ) – все, что идет после / понимать буквально.
CAR – в качестве аргумента берет список и возвращает голову этого списка (результат – не всегда список).
CDR – возвращает хвост списка (результат – всегда список).
LIST – из головы и хвоста списка формирует новый список.
Функции:
списочные (для работы со списками)
Пр: (NTH (LST) 5) – взять 5-ый элемент списка
SETQ – формирует точечную пару.
Пр: (SETQ (A) B) → A.B
предикаты (анализирует то, с чем будет работать ф-ия)
LISTP – проверяет, является ли переданный элемент списком.
NUMBERP – проверяет, является ли элемент числом.
функции, реализующие вычислительный процесс.EVAL – вычисляет значение списка.
функционал (позволяет применить функцию ко всем остальным)
MAP – вызов функционала.
9.Логическое программирование. Язык пролог и его роль а развитии искусственного интеллекта.Пролог (Prolog) — язык логического программирования, представляющей собой подмножество логики предикатов первого порядка.
Одно из направлений развития языка (в том числе и в России) реализует концепцию интеллектуальных агентов
Унификацией называется операция сравнения (отождествления) нескольких формул, связывающая переменные в составе формул сопоставленными с ними подформулами.
Унификация термов осуществляется в ходе исполнения вызовов предикатов, в момент создания значений недоопределённых множеств, а также во время глобальных операций с общими переменными. Кроме того, унификация термов может быть вызвана явно с помощью встроенного предиката "унифицировать термы":
L == R.
Унификация (unification) - операция сравнения (отождествления) нескольких формул, связывающая переменные в составе формул сопоставленными с ними подформулами. Унификация различных (несвязанных) переменных приводит к сцеплению этих переменных.
Пролог построен на основе исчисления предиката первого порядка. Пролог машина умеет проверять только истинность высказывания. Механизмы: унификация, переборный механизм (скрытый механизм откатки). Пролог появился из языка LISP (функциональная парадигма), т.е. используются методы работы языка LISP, но пролог ближе к схеме логических рассуждений. Пролог наиболее близок к организации логических рассуждений.
Унифицировать, '==' (unify) - предопределённый предикат языка, вызывающий унификацию заданных аргументов.
10.Структара программы на языке PROLOG. Механизмы унификации и откатки. Центральным понятием языка является понятие отношения. Язык характеризуется: 1. высокий уровень; 2. строгая ориентация на символические вычисления; 3. возможность инверсных вычислений, т.е. переменные в процедурах не делятся на входные\выходные. Вычисления осуществляются методом проб и ошибок, поисками с возвратом на предыдущий шаг. Терм- минимальная значащая единица. 1. атомы или константы числа; 2. переменные; 3. функции (предикаты). Логические операции: -конъюнгция Т1, Т2 “и”; -дизъюнгция Т1, Т2 “или”; -отрицание not T; Встроенные функции: -true –возвращает “истину”; -fail –возвращает “ложь”; -read(x) –считывает некоторые значения и переменные становятся унифицированные с этим значением; -get(x) –считывает символ; -write(x) –вывести значение; -put(x) –вывести символ; -nl –переход на новую строку; -tab(N) , N=const -вставляет табуляцию. Основные механизмы пролог- машины: Унификация – встроенная возможность распознавания терминов; Откатка – возможность возвращаться на несколько шагов назад; Отсечение – используется для остановки откатки. Работа со списками: [ ] – список; [HIT] – первый условный разделитель списка; Н – первый элемент (может быть не списком а атомом); Т – всегда список. Проверка на принадлежность элемента списку: elem(x, [x |_]) elem(x, [_|Y]):-elem(x,y) ?elem(x, [1,2,3]), write(x), fail x=1 откатка y=[2,3] elem(x,[2,3])
11.Объектно ориентированное программирование и его основные черты. Реализация ООП: С++ основана на 5 компонентах: 1. Объект- совокупность данных и методов; 2. Класс- шаблон написания структур; 3. Сообщение- объекты взаимод. с др. др. сообщениями, на которые у каждого объекта есть реакция; 4. наследование- механизм связи между объектами иерархической структуры; 5. метод. Для реализации объекта необходимо: -абстрагироване; -инкапсуляция; - наследование; -полиморфизм. Абстрагирование- объект, который мы хотим реализовать. Позволяет вызвать некоторую структуру данных, которую описывает объект. Инкапсуляция- объединение в одно целое пассивных характеристик и активных хар-к, конкретного объекта и его поведения. Наследование- механизм создания иерархии объекта с передачей объекту свойств и метдов и возможность перекрытия ненужных методов перекрытием их новыми. Полиморфизм- возможность единообразной обработки родственых объектов. Позволяет переносить алгоритм с одного объекта на другой
13.Понятие
цепочки. Операции над цепочками. Алфавит.
Некоторая цепочка y является цепочкой
в
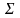
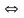 когда она удовлетворяет след усл: 1.
е-является цепочкой в
;
2. если х- цепочка в
,
когда она удовлетворяет след усл: 1.
е-является цепочкой в
;
2. если х- цепочка в
,
 ,
а- символ, =>
,
а- символ, =>
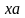 -
цепочка в
.
Осовные операции над цепочками-
конкатенация и декомпозиция. Если x,y,z
– цепочка, то х- префикс; у- подцепочка;
z- суффикс, l(x)- длина цепочки. Языком L в
алфавите
называется некоторое множество цепочек
в этом алфавите. Обозначается
-
цепочка в
.
Осовные операции над цепочками-
конкатенация и декомпозиция. Если x,y,z
– цепочка, то х- префикс; у- подцепочка;
z- суффикс, l(x)- длина цепочки. Языком L в
алфавите
называется некоторое множество цепочек
в этом алфавите. Обозначается
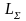 или
или
 .
Если
-
алфавит, то
.
Если
-
алфавит, то
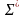 множество
всех цепочек в этом алфавите
множество
всех цепочек в этом алфавите
 .
+
множество всех непустых цепочек в
алфавите. Операции
конкатенации языков выглядят так:
.
+
множество всех непустых цепочек в
алфавите. Операции
конкатенации языков выглядят так:
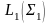 и
и
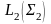 т.е.
после операции получим язык
т.е.
после операции получим язык
 ,
каждая цепочка которого есть ху, где
,
каждая цепочка которого есть ху, где
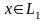 ,
,
 .
Итерация
языка:
1.
.
Итерация
языка:
1.
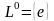 ;
2.
;
2.
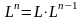 ,
,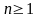 ;
3.
;
3.
 .
Гомоморфизм-
отображение
h: исходный алфавит
.
Гомоморфизм-
отображение
h: исходный алфавит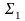 переходит в множество цепочек над
алфавитом
переходит в множество цепочек над
алфавитом
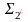 ,
которую можно рас-вать до h* :
,
которую можно рас-вать до h* :
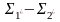 ,
если h удовл след усл: 1. h*(e)=e; 2. h*(ха)=h*(x)
.
h*(a). Алфавитом можно называть упорядоченное
конечное множество знаков, терминальных
символов.
,
если h удовл след усл: 1. h*(e)=e; 2. h*(ха)=h*(x)
.
h*(a). Алфавитом можно называть упорядоченное
конечное множество знаков, терминальных
символов.
противном
случае заменить каждое правило вида
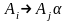 ,
где j>i, правилами
,
где j>i, правилами ,
где
,
где
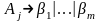 -все Аj-правила.
(4) Положить i=i-1 и вернуться к шагу (3).
(5)Сейчас правая часть каждого правила
(кроме, возможно,
-все Аj-правила.
(4) Положить i=i-1 и вернуться к шагу (3).
(5)Сейчас правая часть каждого правила
(кроме, возможно,
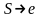 )
начинается терминалом. В каждом правиле
)
начинается терминалом. В каждом правиле
 заменить
заменить
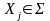 новым терминалом Хj’.
(6) Для новых нетерминалов Хj’,
введённых на шаге 5, добавить правила
новым терминалом Хj’.
(6) Для новых нетерминалов Хj’,
введённых на шаге 5, добавить правила
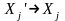 .
.
14.
Грамматика как способ определния языка.
Операции над грамматиками. Виды грамматик.
Назовем N – множество нетерминальных
символов;
-
множество нетерминальных символов
(алфавит) Р – множество продукций. Каждая
продукция – это правило отображающее
некоторую цепочку
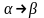 оба множества конечные S – начальный
нетерминальный символ G = (N,
,P,S)
– грамматика. Выводимая цепочка в
грамматике G, если 1. S – вывод в G; 2. если
цепочка
оба множества конечные S – начальный
нетерминальный символ G = (N,
,P,S)
– грамматика. Выводимая цепочка в
грамматике G, если 1. S – вывод в G; 2. если
цепочка
 выводима в G и продукция
выводима в G и продукция
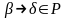
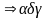 выводимы в G. L(G) – язык, множества все
возможных тер-ых. Пример: 1.
выводимы в G. L(G) – язык, множества все
возможных тер-ых. Пример: 1.
 2.
2.
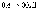 3.
3.
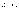

 …… тогда L(G)={
…… тогда L(G)={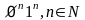 }.
}.
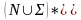 -
множество продукций, задает некоторое
отличие
G
быть непосредственно выводимым. Пара
цепочек
-
множество продукций, задает некоторое
отличие
G
быть непосредственно выводимым. Пара
цепочек
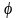 и
и
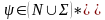 связаны отношением
связаны отношением
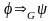 ,
если выполняется следующее условие:
Пусть
,
если выполняется следующее условие:
Пусть
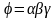 и в мн-ве Р
и в мн-ве Р
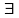
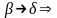 если
если

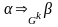 т.е.
т.е.
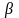 находится в к-ой степени отрицания быть
непосредственно выводимой. Если
находится в к-ой степени отрицания быть
непосредственно выводимой. Если
 :
: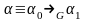
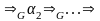
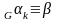 .
.
Способы
определения языка.
1. Грамматика языка позволяет генерировать
цепочки языка. Даны 2 непересекающ
множ-ва N-мн-во нетерминальных символов
- алфавит. Определим набор правил(
продукция).
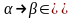 Р
Р
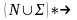 S- нач нетормин символ. Язяк L порожденый
грамматикой Г есть множество всех
терминальных цепочек этой гр. Грам-ка
на мн-ве всех выводимых цепочек опред-ет
бинарные отнош-я. 2. Предикаты- анализирует
то, с чем будет работать ф-я 3. Функции,
реализующие вычислительные процесы.
4. Фуекционалы- фуекции от функций, т.е.
они позволяют применить функцию ко всем
остальным.
S- нач нетормин символ. Язяк L порожденый
грамматикой Г есть множество всех
терминальных цепочек этой гр. Грам-ка
на мн-ве всех выводимых цепочек опред-ет
бинарные отнош-я. 2. Предикаты- анализирует
то, с чем будет работать ф-я 3. Функции,
реализующие вычислительные процесы.
4. Фуекционалы- фуекции от функций, т.е.
они позволяют применить функцию ко всем
остальным.
Классификация грамматик по сложности соответствующих программ- распознавателей называется иерархией Хомского. В ней выделены 4 класса грамматик (в порядке возрастания сложности): а) регулярные (или автоматные) или праволинейные.. Правила имеют вид: A : xB или A : x, где x - цепочка терминалов или e б) контекстно-свободные (или КС). Правила имеют вид: A : y, где y - цепочка из терминалов и нетерминалов в) контекстно-зависимые (неукорачивающие). Правила имеют вид : z : y, где z и y - цепочки из терминалов и нетерминалов, z содержит нетерминал, |z| <= |y| г) без ограничений Класс языка определяется классом самой простой (в смысле иерархии Хомского) из описывающих его грамматик. Следующие вложения для классов языков очевидны, если не рассматривать КС-грамматики, содержащие так называемые e-правила - правила с пустой правой частью.
16.Алгоритм
устранения бесполезных и недостижимых
символов в КС-грамматиках.
Символ
 называется бесполезным в КС-гр Г,если
в этой грамматике не существует вывод
вида
называется бесполезным в КС-гр Г,если
в этой грамматике не существует вывод
вида
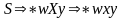 ,
,
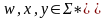 Символ
называется недостижимым в КС-гр Г или
x не появляется ни в одной выводимой
цепочке. Рассмотрим 3 алгоритма:
1.Проверяет не пуст ли алгоритм 2.устраняет
недостижимые символы 3.устраняет
бесполезные символы.1)Ni,
i=0,1,… I.N0=0;
II.Ni=
Символ
называется недостижимым в КС-гр Г или
x не появляется ни в одной выводимой
цепочке. Рассмотрим 3 алгоритма:
1.Проверяет не пуст ли алгоритм 2.устраняет
недостижимые символы 3.устраняет
бесполезные символы.1)Ni,
i=0,1,… I.N0=0;
II.Ni=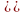
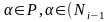
 ;
III.Условие окончания цикла
;
III.Условие окончания цикла
 ;
IV.Если
;
IV.Если
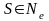 ,
то L(Г) не пуст. 2)Устранение
недостижимых символов. I.
,
то L(Г) не пуст. 2)Устранение
недостижимых символов. I.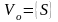 ;
II.
;
II.
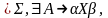
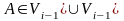 ; III.
; III.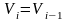 ;
IV.
;
IV.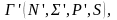
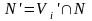 ,
,
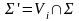 P’-продукция из Vi.
3)Устранение
бесп символов. I.Применить алг.1).,
Ne
и построить Г1(Ne,
,P1,S);
II.Применить к Г1
алг 2).
Пример:
P’-продукция из Vi.
3)Устранение
бесп символов. I.Применить алг.1).,
Ne
и построить Г1(Ne,
,P1,S);
II.Применить к Г1
алг 2).
Пример:
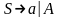
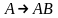
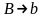 Алг1)
Алг1)
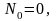
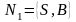
 алг2)
алг2)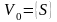
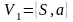
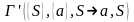
17.Приведенные
грамматики. Алгоритмы устранения
е-правил и цепных правил. Алгоритм
устранения е-правил. Е-павила-это
правила вида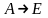 ,где А-терминальный символ. КС-гр. Г
называется
грамматикой
без е-правил ,если выполнено 1 из 2-х
условий: 1. множ-во продукции не содержит
ни одного е-правила; 2. существует
единственное е-правило
,где А-терминальный символ. КС-гр. Г
называется
грамматикой
без е-правил ,если выполнено 1 из 2-х
условий: 1. множ-во продукции не содержит
ни одного е-правила; 2. существует
единственное е-правило
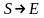 ,
при этом нетерминал S не встречается в
правых частях стальных продукций. 1)Nе=
,
при этом нетерминал S не встречается в
правых частях стальных продукций. 1)Nе=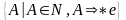 ; 2)
; 2) удовл 2-му усл. Пусть в исходном множестве
продукции существует продукция вида
удовл 2-му усл. Пусть в исходном множестве
продукции существует продукция вида
 ,
где Bi
–нетерминалы
,
где Bi
–нетерминалы
 ,
,
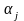 -цепочки
несодержащие ни одного символа,
приводящего к пустой цепочке. Тогда в
новое множество P’ включить правило
вида
-цепочки
несодержащие ни одного символа,
приводящего к пустой цепочке. Тогда в
новое множество P’ включить правило
вида
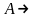
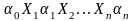 ,
где
,
где
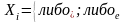 если
если
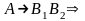 если
если
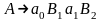

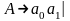


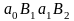 .
Если
добавим нетерминальный символ S’ и
определим продукцию
.
Если
добавим нетерминальный символ S’ и
определим продукцию
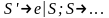 }P’
. Мы получим G’(N
}P’
. Мы получим G’(N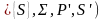 .
Пример: S
.
Пример: S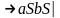
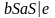
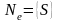
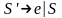

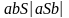
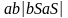
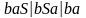 .
.
Алгоритм
устранения цепных правил. Для
любой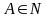 ,
,
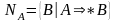 .
Если существуют
.
Если существуют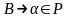 и она не является правилом переписывания,
то в Р’ включить правило вида
и она не является правилом переписывания,
то в Р’ включить правило вида
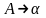 для всех А,
для всех А,
 .
Пример:
.
Пример:
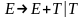
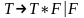
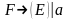
 ,
,



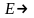
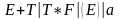 .
Граматика Г наз-ся приведенной
грамматикой, если она является грамм-ой
без циклов, без е-правил, и без полезных
символов.
.
Граматика Г наз-ся приведенной
грамматикой, если она является грамм-ой
без циклов, без е-правил, и без полезных
символов.
18.Алгоритм
устранения левой рекурсии. Нормальная
форма Грейбах. Определние.
Нетермиал А КС- грамматики G=(N, ,P,S)
называется рекурсивным, если
,P,S)
называется рекурсивным, если
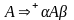 для некоторых
для некоторых
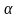 и
.
Если
и
.
Если
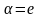 ,
то А называется леворекурсивным.
Грамматика, имеющая хотя бы один
леворекурсивный нетерминал, называется
леворекурсивной. Устранение
левой рекурсии. Вход.
Приведенная
КС-граматика G=(N,
,P,S).
Выход.
Эквивалентная
КС-грамматика G’ без левой рекурсии.
Метод.
(1) Пусть
N={A1,..An}.
Преобразуем G так, чтобы в правиле
,
то А называется леворекурсивным.
Грамматика, имеющая хотя бы один
леворекурсивный нетерминал, называется
леворекурсивной. Устранение
левой рекурсии. Вход.
Приведенная
КС-граматика G=(N,
,P,S).
Выход.
Эквивалентная
КС-грамматика G’ без левой рекурсии.
Метод.
(1) Пусть
N={A1,..An}.
Преобразуем G так, чтобы в правиле
 цепочка
начиналась либо с терминала, либо с
такого
цепочка
начиналась либо с терминала, либо с
такого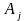 ,
что j>i. С этой целью положим i=1. (2)
Пусть
множество Аi-правил
-это
,
что j>i. С этой целью положим i=1. (2)
Пусть
множество Аi-правил
-это
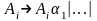
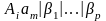 ,
где ни одна из цепочек
,
где ни одна из цепочек
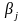 не начинается с Ак,
если
не начинается с Ак,
если
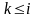 .
(это всегда можно сделать.) Заменим
Аi-правила
правилами
.
(это всегда можно сделать.) Заменим
Аi-правила
правилами
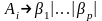 .
.
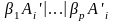 ,
,
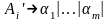 .
.
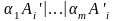 ,
где Аi’-новый
нетерминал. Правые части всех Аi-правил
начинается теперь с терминала или с Ак
для некоторого k>i.
(3) Если i=n
,полученную грамматику G’ считать
результатом и остановиться. В противном
случае положить i=i+1
и j=1.
(4) Заменить каждое правило вида
правилами
,
где
-все Аj-правила.
Так как правая часть каждого Аj-правила
начинается уже с терминала или с Аk
для k>j, то и правая часть каждого
Аi-правила
будет теперь обладать этим свойством.
(5) Если j=i-1,
перейти к шагу(2). В противном случае
положить j=j+1
и перейти к шагу (4).
,
где Аi’-новый
нетерминал. Правые части всех Аi-правил
начинается теперь с терминала или с Ак
для некоторого k>i.
(3) Если i=n
,полученную грамматику G’ считать
результатом и остановиться. В противном
случае положить i=i+1
и j=1.
(4) Заменить каждое правило вида
правилами
,
где
-все Аj-правила.
Так как правая часть каждого Аj-правила
начинается уже с терминала или с Аk
для k>j, то и правая часть каждого
Аi-правила
будет теперь обладать этим свойством.
(5) Если j=i-1,
перейти к шагу(2). В противном случае
положить j=j+1
и перейти к шагу (4).
Нормальная
форма Грейбах.
КС-граматика G=(N,
,P,S)
называтся грамматикой в нормальной
форме Грейбах, если в ней нет е-правил
и каждое правило из Р, отличное от
,
имеет вид
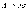 ,
где
,
где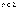 и
и
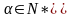 .
Пусть
G=(N,
,P,S)
-не
леворекурсивная грамматика. Существует
такой линейный порядок<на N , что если
.
Пусть
G=(N,
,P,S)
-не
леворекурсивная грамматика. Существует
такой линейный порядок<на N , что если
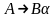 принадлежит Р, то А<B. Преобразование
к нормальной форме Грейбах. Вход.
не леворекурсивная приведенная
КС-грамматика
G=(N,
,P,S).
Выход.
Эквивалентная
грамматика G’ в нормальной форме Грейбах.
Метод.
(1) Построить такой линейный порядок <
на N ,что каждое А-правило начинается
либо с терминала ,либо с такого нетерминала
В, что А<B . Упорядочить
принадлежит Р, то А<B. Преобразование
к нормальной форме Грейбах. Вход.
не леворекурсивная приведенная
КС-грамматика
G=(N,
,P,S).
Выход.
Эквивалентная
грамматика G’ в нормальной форме Грейбах.
Метод.
(1) Построить такой линейный порядок <
на N ,что каждое А-правило начинается
либо с терминала ,либо с такого нетерминала
В, что А<B . Упорядочить так, что А1<A2<…<An.
(2) Положить i=n-1. (3)Если i=0, перейти к шагу
5. В
так, что А1<A2<…<An.
(2) Положить i=n-1. (3)Если i=0, перейти к шагу
5. В